
基于分类加权边信息的DVCS重建算法
2017-06-05 14:15戴越越曹雪情曹雪虹
计算机技术与发展 2017年5期
戴越越,曹雪情,陈 瑞,杨 洁,曹雪虹
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京工程学院 通信工程学院,江苏 南京 211167)
基于分类加权边信息的DVCS重建算法
戴越越1,曹雪情1,陈 瑞2,杨 洁2,曹雪虹2
(1.南京邮电大学 通信与信息工程学院,江苏 南京 210003;2.南京工程学院 通信工程学院,江苏 南京 211167)
现有的分块视频压缩感知在获取边信息时,通常对所有图像块均采用固定权值边信息合成方法,该方法忽略了不同图像块之间相关度不同的问题。针对这一问题,根据贝叶斯压缩感知和运动估计理论,提出了一种基于块的分类加权边信息生成方案的分布式视频解码方法。在解码端利用相邻关键帧中不同块的相关度差异,对相邻关键帧进行基于块的分类加权运动估计,生成边信息,进而完成非关键帧的重构。考虑到加权系数的大小取决于相邻关键帧对应块的相关度,所采用的重建算法是基于TSW-CS模型的贝叶斯压缩感知重构算法。分别采用固定权值边信息生成方法和分类加权边信息生成方法对不同视频序列进行了实验对比,实验结果表明,采用分类加权边信息方法生成的视频重建PSNR值比固定权值边信息生成方法平均提高了0.2~0.5 dB,所采用的解码方法可有效地提高视频压缩感知重构质量。
边信息;运动估计;贝叶斯压缩感知;小波树;分布式视频编码
0 引 言
近年来,为了解决大数据量的图像视频类多媒体信号在无线网络中的实时传输问题,分布式视频编码(Distributed Video Coding,DVC)[1-3]受到了普遍关注。它在编码端对信源进行独立编码,在解码端利用视频序列的相关性进行联合解码,将编码的运算复杂度从编码端移到解码端。目前,这种低复杂度视频编码已经适用于一些新兴的应用,例如视频会议、移动设备和无线传感器网络(Wireless Sensor Network,WSN)[4]等。传统的分布式视频编码是基于信道编码的,对于单幅图像的编码仍需要大量计算。近年来,压缩感知(Compressed Sensing,CS)理论的提出打破了Nyquist采样定理的瓶颈,将采样和压缩合并处理,在接收端通过最优化算法重构原信号,可以极大地降低编码端的复杂度[4-5]。因此,将压缩感知理论引入分布式视频编码中,形成了一些新的分布式视频压缩感知(Distributed Video Compressed Sensing,DVCS)编解码方案[6-12]。这些方案主要分为两类,第一类方案的特点是将视频分为关键帧和CS帧,关键帧采用传统视频编解码方案,而非关键帧采用压缩感知的方法,简化了编码端的复杂度。并且在解码过程中,非关键帧的重建利用了关键帧重建之后的图片来训练字典。典型的框架有Thong T. Do等提出的一种分布式视频压缩感知结[6]和Josep Prades-Nebot等提出的基于压缩感知的框架[7]。相比第一类方案,第二类方案在其基础上进行改进,与第一类方案不同的是,该类方案在对关键帧编码时也采用压缩感知方法,相比非关键帧,关键帧采用更高的采样率进行采样,然后进行稀疏重建。这样可以减少关键帧的数据传输,也进一步简化了编码端的复杂度。比较典型的框架有Kang L W等提出的分布式视频压缩感知框架[8]。在此基础上,又出现了许多改进框架。例如,文献[9]在边信息生成方面进行了改进,利用边信息生成了字典,再利用字典去重建非关键帧,取得了不错的重建效果,但是没有充分利用视频序列的相关性。文献[10]提出了更高效的重建算法:基于块平滑投影的Landweber迭代重构算法。文献[11]在文献[8]的基础上提出根据视频非局部相似性生成正则化项,并以此正则项作为边信息,融合到重建算法中。此方法能够有效去除边缘与纹理区域的模糊以及块效应现象。文献[12]对字典学习进行了研究,提出了子空间解析字典学习算法。文献[8]提出的框架几乎将所有的计算负担都转移到了解码端,在解码端再结合压缩感知重构算法与连续帧之间的统计相关性来重建视频数据。
虽然文献[8]提出的框架在解码端利用了帧间相关性提升重构质量,但没有考虑到视频序列相邻关键帧的不同区域内帧间相关性的不同的问题。鉴于该框架对帧间相关性的利用不足,提出了一种基于块的分类加权边信息生成(Classified Weighted Side Information,CWSI)方案的分布式视频解码方法。与文献[8]提出的框架相比,该方法更充分地利用了相邻关键帧的帧间相关性,提升了视频帧的重构质量。
1 基于块的分布式视频压缩感知
由于一次处理一幅图像的运算量较大,为了降低运算强度,通常采用基于块的分布式压缩感知视频编码框架。在此框架中,视频序列首先被拆成关键帧和非关键帧,然后分别对关键帧和非关键帧进行稀疏表示,接着进行基于块的压缩感知测量。其中,关键帧采用较高的采样率,非关键帧采用较低的采样率。DVCS框架中的主要模块包括稀疏表示、测量矩阵的设计和重建算法三部分。
1.1 稀疏表示
信号的稀疏表示是压缩感知处理过程的必要条件,否则就无法对采样后的信号进行重建。稀疏表示可采用的稀疏基有很多,常见的有离散余弦变换基、快速傅里叶变换基、离散小波变换基、Curvelet基、冗余字典等。由于离散小波变换(Discrete Wavelet Transform,DWT)在图像压缩领域的广泛应用,压缩感知领域普遍采用小波基进行稀疏表示。小波变换系数不但具有稀疏性,且各层系数之间以及每一层内都有较强的相关性。在小波树结构中,左上角为低频尺度系数;其他部分为高频系数。低频系数为显著系数,包含图像的绝大部分信息且值较大。而高频系数大多幅值很小,包含的是与图像细节相关的信息。
文献[13]中提出了贪婪树和最优树两种小波树,并在非线性逼近中应用它们。其中,贪婪树的核心是若父系数较大,则可以得出其子系数也较大,因此在选择较大的系数时也包括了其所有父系数。当小波系数符合由树根向下依次递减时,贪婪数逼近可以快速找到准确的估计值。若不满足依次递减时,当选择了离根部较远的某个孤立的大系数时,同样选择了其所有父系数,然而这些父系数可能较小,因此逼近误差就会较大,此时就可采用最优树逼近方法。最优树逼近是借助最优算法找到最优的子树,然后将最优子树中的系数放入估计值中的一种方法。通过小波基的树结构特性和层级间相关性可以定义稀疏度为K的树结构稀疏信号,如式(1)所示:

(1)
1.2 重构算法
压缩感知理论中最核心的内容是重构算法。重构算法的核心是怎样从低维信号中最大程度地恢复出理想的高维信号。传统的压缩感知重构算法只利用了一维信号或图像在某些正交基下可以实现稀疏的特性,然而它们通过小波分解得到的系数除稀疏性之外,还存在着一些互相关联的结构。所采用的CS重构算法就是一种基于小波树结构特性的贝叶斯压缩感知重构(TSW-BCS)算法[14]。实验表明,该重构算法可以有效利用小波系数之间的关联性和结构特征,提升信号的压缩度和重构精度。在小波系数中,低频系数的值基本较大,包含了图像的绝大部分能量,而且相邻的系数间包含较高的相关性;而高频系数值大多较小,但因为其代表图像细节的相关信息,若直接舍弃会导致图像重构后细节信息的缺失。针对上述小波系数不同部位的特征不同,采用不同的CS重构算法对低频系数和高频系数进行处理。其中,对小波变换的低频系数通过求解式(2)所示的目标函数实现尺度系数的恢复:
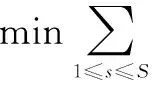
s.t. ‖ΦLXL‖≤ξ
(2)
其中,XL和YL分别为小波尺度系数和测量值;ξ为噪声分量;ΦL为测量矩阵;S为4×4系数块的数量;R[·]为在方向模型基础上进行层内系数预测的残差。
对于高频系数的重建,结合CS理论和贝叶斯模型,提出一种基于回归模型的方法,将确定的先验分布赋予未知的权值参数,从而限制小波系数的稀疏性。
假设XL∈R,L为小波稀疏的层数。在考虑噪声的情况下,压缩采样数据可以表示为:
YL=φLXL+ωL
(3)
为了限制XL的稀疏性,假设其由高斯混合密度函数产生,则XL满足如下分布:
(4)
其中,R(s)为协方差矩阵,且有高斯混合参数s构成的随机向量s=[s1,s2,…,sn]确定。

(5)
上述方法可以获得未知参数的一个高概率模型,进而实现MMSE意义下的小波系数的恢复。然后利用求解得到的尺度系数和高频系数进行小波反变换实现图像的精确重构。
2 基于CWSI的DCVS框架
2.1 框架描述
上述DCVS框架中,为了提高解码端非关键帧的恢复质量,在重建非关键帧时加入了边信息。对于边信息的获取,可以利用KSVD训练字典生成边信息或对已解码的关键帧做运动估计,进行时域内插求取边信息。因此,需要研究通过运动估计获取边信息的方法。传统方法是对前后两个关键帧的重构值分别作前向运动估计和后向运动估计,然后按某一固定权值相加(通常为1/2)合成边信息重构非关键帧。然而视频中不同的运动目标可能以不同的方式运动,因此不同区域的帧间相关性并不相同。当前后帧的帧间相关性较差时,前向运动估计结果与当前帧有较大差异,无法准确预测当前帧,此时后向运动估计预测结果更适合生成边信息。而普通的边信息生成方案只是按照固定权值合成边信息,没有充分利用帧间相关性。因此,根据视频帧不同块间的帧间相关性的不同,提出一种基于不同块的分类加权边信息分布式视频编码框架(Classified Weighted Side Information for DVCS,CWSI-DVCS),如图1所示。

图1 基于块的分类加权边信息DVCS框架
首先在编码端分别对前后两个关键帧和当前非关键帧做小波基稀疏和基于块的采样测量,关键帧进行高采样,非关键帧进行低采样。然后在解码端先对前后两个关键帧采用TSW-BCS重构算法进行重构。接着利用前后两帧对应块之间的差值能量将当前帧的块分为3类:近似不变块、缓慢变化块、快速变化块。最后对相邻两个关键帧的对应块分别作前向和后向运动估计,再根据该块所属类别采用不同的加权方案生成边信息,从而对当前帧块进行重构。
2.2 分类判决准则

(6)
但是,不同种类视频的亮度和对比度都有较大差异,从而导致对应的残差能量也存在较大差别,以此作为分类判决准则导致阈值的选择会过于依赖视频本身,从而影响分类判决算法的通用性,因此考虑采用残差与前一关键帧的参考块的能量比值作为判决准则。
(7)

2.3 非关键帧重构
非关键帧的重构利用分类加权运动估计获取边信息,然后利用边信息和当前帧测量值对当前帧进行残差重构,最后合并边信息和残差重构结果获得当前帧重构结果。


(8)
如果当前帧的预测值和当前帧的实际值越相近,两者的残差也就越小、越稀疏,其在非关键帧测量矩阵下的采样也越小,因此残差的重建效果也越好。非关键帧最终的重建结果为:
(9)
其中,xrec为非关键帧的重建结果;rrec为残差的重建结果。

(10)
其中,α为权值。

如图1所示,非关键帧重建的主要流程为,首先对相邻的两个关键帧的重建结果进行分类判决,然后分别对相邻关键帧做前向和后向运动估计,再根据式(10)得到非关键帧的参考边信息(SI)。根据SI和非关键帧的采样信息,进行非关键帧的残差解码。非关键帧的重建算法如下所述:
输入:y,ΦS,xt-1,xt+1

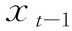
(2)根据xt-1和xt+1的分类判决结果,由式(10)得到非关键帧的预测边信息;
(3)计算测量值y和SI在测量域的残差:
r=y-TSW_CS_Encoder(SI,Φs)
(4)对残差r进行基于TSW-CS的重建:
计算关键帧的重建结果:
3 实验结果及分析
采用MHFP软件包中的3组标准视频序列(Foreman,News,Akiyo)测试分类加权边信息方法的性能。实验中对分类加权边信息生成方法和固定权值边信息生成方法进行了对比。重构算法则采用TSW-BCS算法(基于小波树结构的贝叶斯压缩感知重构算法)。实验中对关键帧和非关键帧的测量和重构都是基于块的(16×16)。并将第一帧作为参考帧,其中,关键帧和非关键帧的采样率分别为0.7和0.3。分类判据阈值分别为:T1=0.003,T2=0.015。
对上述视频序列截取前120帧分别进行仿真实验,不同序列非关键帧重建后的PSNR曲线见图2。

(a)Akio序列

(b)News序列

(c)Foreman序列
从图2可以看出,在其他条件相同的情况下,基于块的分类加权自适应边信息生成方法比固定权值边信息生成方法的PSNR值平均提高0.2~0.5dB。对于Akio、News序列,其视频序列运动强度较低,相邻帧之间相关性较强,从图2(a)、(b)可以看出提升效果较明显,而对于Foreman序列,其视频序列的运动强度相对较高,相邻帧之间的帧间相关性较弱,虽然采用后向运动估计的加权系数较高,但提升效果仍然相对稍差,甚至有一些帧的PSNR值要略低于固定权值边信息生成方法。另外由于实验中采用的是分块采样、分块重建,所以重建后的视频帧会有块效应。这种块效应可以通过滤波和后处理来消除。
表1列出了CS帧采样率从0.1到0.5时不同实验视频序列重建后的平均PSNR值。
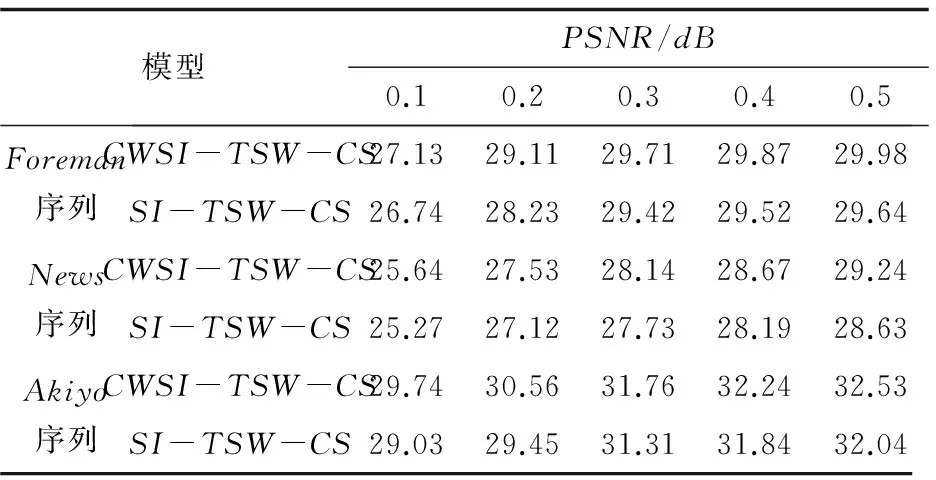
表1 视频序列重建质量PSNR值
从表1可以看到,CWSI-TSW-CS算法相比于SI-TSW-CS算法,视频重建质量提高了0.2~0.5dB。当采样率达到0.3后,提高采样率对重建后的PSNR值的改善作用不明显。这是由于在残差重建中,最后视频的重建效果是由边信息和重建的残差两者之和决定的,而在低采样率时残差重建的效果相对较差,因此边信息的好坏对最后的重建结果影响相对较大。实际采样时,建议把CS帧采样率设置为0.3,就可以满足一般需求,而且需要传输的数据比较少。
4 结束语
为了解决现有视频压缩感知方法在解码端获取边信息时不同图像块之间的相关度不同的问题,在分析重构过程中的运动估计边信息提取方法的基础上,提出了一种基于块的分类加权自适应边信息生成方案。将视频帧分块,根据不同块间的前后两帧的帧间相关性的不同采用不同的边信息生成方案。根据不同视频场景自适应地调整边信息生成方案,比固定权值边信息生成方法提高了非关键帧重构质量。实验结果表明,该算法可以根据不同的视频场景自适应调整边信息生成方法,进一步提升了视频帧的帧间相关性的利用率,从而实现了更高的重构质量。如果要在实时传输的场景下应用,还需要改进重建算法或者设计相应的硬件。
[1]LeiTCW,TsengFS.Studyfordistributedvideocodingarchitectures[C]//Internationalsymposiumoncomputer,consumerandcontrol.[s.l.]:IEEE,2014:380-383.
[2]VijayanagarKR,KimJ,LeeY,etal.Lowcomplexitydistributedvideocoding[J].JournalofVisualCommunicationandImageRepresentation,2014,25(2):361-372.
[3]SkorupaJ,SlowackJ,MysS,etal.Efficientlow-delaydistributedvideocoding[J].IEEETransactionsonCircuitsandSystemsforVideoTechnology,2012,22(4):530-544.
[4]FornasierM,RauhutH.Compressivesensing[M]//Handbookofmathematicalmethodsinimaging.[s.l.]:Springer,2011.
[5] 焦李成,杨淑媛,刘 芳,等.压缩感知回顾与展望[J].电子学报,2011,39(7):1651-1662.
[6]DoTT,ChenY,NguyenDT,etal.Distributedcompressedvideosensing[C]//16thIEEEinternationalconferenceonimageprocessing.[s.l.]:IEEE,2009:1393-1396.
[7]Prades-NebotJ,MaY,HuangT.Distributedvideocodingusingcompressivesampling[C]//Picturecodingsymposium.[s.l.]:IEEE,2009:1-4.
[8]KangLW,LuCS.Distributedcompressivevideosensing[C]//Internationalconferenceonacoustics,speechandsignalprocessing.[s.l.]:IEEE,2009:1169-1172.
[9]ChenHW,KangLW,LuCS.Dictionarylearning-baseddistributedcompressivevideosensing[C]//Picturecodingsymposium.[s.l.]:IEEE,2010:210-213.
[10]MunS,FowlerJE.Blockcompressedsensingofimagesusingdirectionaltransforms[C]//16thIEEEinternationalconferenceonimageprocessing.[s.l.]:IEEE,2009:3021-3024.
[11] 武明虎,李 然,陈 瑞,等.利用视频非局部相似性的分布式压缩感知重构[J].信号处理,2015,31(2):136-144.
[12] 练秋生,王小娜,石保顺,等.基于多重解析字典学习和观测矩阵优化的压缩感知[J].计算机学报,2015,38(6):1162-1171.
[13]YoninaCE,HelmutB.Block-sparsity:coherenceandefficientrecovery[C]//IEEEinternationalconferenceonacoustics,speechandsignalprocessing.Taipei,China:IEEE,2009:2885-2888.
[14]HeLH,CarinL.ExploitingstructureinwaveletbasedBayesiancompressivesensing[J].IEEETransactionsonSignalProcessing,2009,57(9):3488-3497.
[15] 练秋生,田 天,陈书贞,等.基于变采样率的多假设预测分块视频压缩感知[J].电子与信息学报,2013,35(1):203-208.
[16] 刘艳红.分布式视频编码中基于块的运动补偿插值边信息估计算法研究[D].西安:西安电子科技大学,2010.
Reconstruction Algorithm with Classified Weighted Side Information forDistributed Video Compressive Sensing
DAI Yue-yue1,CAO Xue-qing1,CHEN Rui2,YANG Jie2,CAO Xue-hong2
(1.College of Telecommunications and Information Engineering,Nanjing University of Posts and Telecommunications,Nanjing 210003,China;2.College of Communication Engineering,Nanjing Institute of Technology,Nanjing 211167,China)
For most of those existing block-based compressed sensing of video,the fixed weight side information generation method is usually utilized for all blocks,which underestimates the problem of the difference of correlation between different blocks.To address this issue,a classified weighted side information generation method with block for distributed video decoding has been proposed according to the Bayesian compressive sensing and motion estimation theory.In the decoding side,the different correlations of neighboring key-frames has been used to generate side information by taking classified weighted motion estimation with block to different block of key-frame,then the reconstruction of the non-key-frame is completed.Considering that weighting coefficient depends on the size of the adjacent frames relevance,the Bayesian compressive sensing reconstruction algorithm is adopted based on TSW-CS model.Fixed weight side information generation method and the proposed method are used in experiments for comparison with various video sequences.The experimental results show that the PSNR of reconstructed video of proposed side information generation method has been averagely improved 0.2~0.5 dB,higher than fixed weight method.The restructure quality of video compression sensing has been effectively improved by proposed algorithm.
side information;motion estimation;Bayesian compressive sensing;wavelet tree;distributed video coding
2016-06-08
2016-09-22 网络出版时间:2017-03-13
国家自然科学基金资助项目(61471162);江苏省自然科学基金(BK20141389);南京工程学院科研基金(QKJA201304)
戴越越(1992-),男,硕士研究生,研究方向为分布式视频编码;陈 瑞,博士,副教授,研究方向为无线多媒体通信;杨 洁,硕士,副教授,研究方向为无线通信;曹雪虹,博士生导师,研究方向为无线通信中的智能信号处理。
http://kns.cnki.net/kcms/detail/61.1450.tp.20170313.1546.048.html
TP919.81
A
1673-629X(2017)05-0087-05
10.3969/j.issn.1673-629X.2017.05.019
猜你喜欢
中国石油石化(2022年12期)2022-07-16
网络安全与数据管理(2022年3期)2022-05-23
现代计算机(2022年4期)2022-04-24
微型电脑应用(2020年12期)2020-12-25
北京航空航天大学学报(2020年10期)2020-11-14
中国外汇(2019年19期)2019-11-26
自动化学报(2019年6期)2019-07-23
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
图学学报(2018年3期)2018-07-12
