
基于Spark框架的并行聚类算法
2017-06-05 14:15李淋淋倪建成于苹苹姚彬修
计算机技术与发展 2017年5期
李淋淋,倪建成,曹 博,于苹苹,姚彬修
(1.曲阜师范大学 信息科学与工程学院,山东 日照 276826;2.曲阜师范大学 软件学院,山东 曲阜 273100)
基于Spark框架的并行聚类算法
李淋淋1,倪建成2,曹 博1,于苹苹1,姚彬修1
(1.曲阜师范大学 信息科学与工程学院,山东 日照 276826;2.曲阜师范大学 软件学院,山东 曲阜 273100)
针对传统K-means算法在处理海量数据时存在距离计算瓶颈及因迭代计算次数增加导致内存不足的问题,提出了一种基于Spark框架的SBTICK-means(SparkBasedTriangleInequalityCanopy-K-means)并行聚类算法。为了更好地解决K值选取的盲目性和随机性的问题,该算法利用Canopy进行预处理得到初始聚类中心点和K值;在K-means迭代计算过程中进一步利用距离三角不等式定理减少冗余计算、加快聚类速度,结合Spark框架实现算法的并行化,充分利用Spark的内存计算优势提高数据的处理速度,缩减算法的整体运行时间。实验结果表明,SBTICK-means算法在保证准确率的同时大大提高了聚类效率,与传统的K-means算法、Canopy-K-means算法和基于MapReduce框架下的该算法相比,在加速比、扩展比以及运行速率上都有一定的提高,从而更适合应用于海量数据的聚类研究。
K-means;Spark;大数据;Hadoop;MapReduce
0 引 言
K-means聚类算法因其执行简单、快速、易于并行化,并可以提供直观结果等优点而成为数据挖掘和非监督式学习中的流行算法[1],但它也存在以下问题[2]:K值(簇数)是人为确定的,在对数据不了解的情况下很难给出合理的K值;初始中心点的选择是随机的,若选择到较为孤立的点,会严重影响聚类结果;算法在每次迭代时都需要进行大量的距离计算来确定新的聚类中心,然而其中许多计算都是冗余的;传统的串行K-means算法在处理大规模数据集时运行效率非常低。
针对以上问题,学者们不断地进行研究和优化。例如,张石磊等[3]提出使用Hadoop平台下的MapReduce框架实现K-means的分布式聚类,提高了聚类速度;衣治安等[4]提出在MapReduce框架的基础上利用Canopy算法进行优化,提高了聚类的准确率;王永贵等[5]提出基于MapReduce的随机抽样K-means算法,通过对数据集进行多次随机采样,优化初始聚类中心,增强了聚类的稳定性;毛典辉[6]提出了一种基于MapReduce的Canopy-K-means优化算法,采用“最大最小原则”对该算法进行改进,避免了Canopy算法选取的盲目性,进一步提高了聚类的准确率和“抗噪”的能力。
为了进一步减少数据聚类迭代过程中的冗余计算,加快聚类速度,提高聚类准确率,故综合以上聚类优化算法的各种优点,结合Spark计算框架,提出了SBTICK-means并行聚类算法。通过Spark框架的内存迭代计算优势[7]提高了数据处理的速度,利用Canopy算法解决了K-means算法初始中心点的预选取和孤立点处理问题,利用距离三角不等式定理[8-9]解决了聚类过程中距离冗余计算的问题。以UCI标准数据集进行测试,并与MapReduce框架[10]下的结果进行比较、分析,以此验证SBTICK-means算法具有较好的聚类质量和较快的聚类速度,更适合应用于海量数据的聚类分析中。
1 相关工作
1.1 Spark框架
Spark是一套开源的、基于内存的,可以运行在分布式集群上的并行计算框架[11-12],与MapReduce相比,有以下几点优势[13]:
(1)中间结果不输出到磁盘上,而是使用有向无环图将各阶段的任务串联起来或者并行执行。
(2)使用RDD作为分布式索引来对数据进行分区和处理。
(3)MapReduce在数据Shuffle时每次都花费大量时间来排序,而Spark任务在Shuffle中不是所有情况都需要排序。
1.2 基本概念
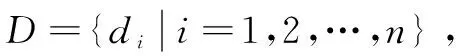



定理1(三角不等式定理):假设空间中任意三个数据点x,y,z,如果d(y,z)≥2d(x,y),则d(x,z)≥d(x,y)。
推论1:由定理1可以得出,对于数据点x,数据聚类中心点Q1,Q2,如果d(Q1,Q2)≥2d(x,Q1),则数据点x被标记到Q1所属的类中。

2 SBTICK-means并行聚类算法
2.1 算法思想
该算法首先利用Canopy算法对K-means算法进行优化,得到初始聚类中心点和K值,然后在K-means聚类过程中引入三角不等式定理进行“精”聚类,最后使用Spark框架实现该算法的并行化。因此,基于Spark框架的SBTICK-means算法主要分为两个阶段,其流程如图1所示。

图1 SBTICK-means并行聚类算法流程
阶段一为Canopy算法在Spark框架中的执行过程:
(1)从分布式文件系统HDFS[14-15]上读取原始数据集D生成RDD,并通过map操作将数据集格式化为向量。
(2)在每个子节点分别map计算数据点与Canopy中心点间的欧氏距离。
(3)根据Canopy算法规则对每个数据点进行标记,直到数据集D为空时结束,得出局部Canopy中心点。
(4)将各子节点得出的Canopy中心点通过reduce汇总得出全局的Canopy中心点。
阶段二为基于三角不等式定理的K-means聚类算法在Spark框架中的执行过程:
(1)将第一阶段计算得出的Canopy中心点作为初始聚类中心。
(2)启动各子节点的map任务,分别计算各数据点与聚类中心点的距离、各聚类中心点彼此间的距离。
(3)按照三角不等式定理对每个满足条件的数据点进行相应簇的划分,对不满足条件的数据点按照最短距离原则进行相应簇的划分。
(4)由Combine合并中间结果,并通过Reduce进行局部聚类中心点的更新和汇总。
(5)判断结果是否收敛,若收敛则算法结束,否则返回步骤(2)。
2.2 基于Spark框架的SBTICK-means算法并行化实现
2.2.1 Canopy算法的并行化实现
由于K-means算法中的K值选取具有一定的盲目性和随机性,因此使用Canopy算法对其进行优化,以确定K-means的初始聚类中心点和K值。该算法可以高效地将数据划分为几个可重叠子集(即canopy),从而避免聚类过程中局部最优的出现,有效提高了大规模数据的处理效率。该阶段主要实现Canopy算法的并行化,其具体实现的伪代码如下所示:
Input:待处理数据集D(d1,d2,…,dn),参数T1,T2(T1>T2,采用交叉检验方式获得)
Output:Canopy中心点集合Q(Q1,Q2,…,Qn)
1)If(Q=Null)
2)任选一数据点作为Canopy中心点,并从D中删除
3)While(D!=Null)
4)遍历D,计算每个数据点到Q中点的距离
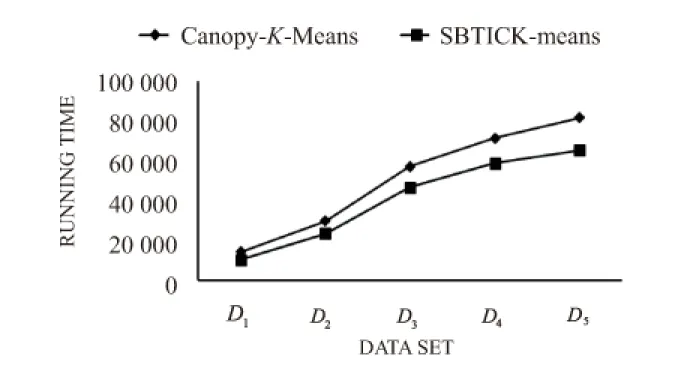
5)If(dist[i] 6)ElseIf(dist[i]>T1) 将该点加入Q中,并从D中删除 7)Else将该点加入Q中此点所属的Canopy 8)EndIf 9)EndWhile 2.2.2 基于三角不等式定理的K-means算法并行化实现 该阶段主要实现K-means算法的并行化,利用预处理得到的Canopy中心点作为初始中心点完成“精”聚类。此外,为进一步加快聚类速度,引入三角不等式定理。由推论可知,通过三角不等式定理的判定,可以有效减少迭代过程中不必要的距离计算,将各数据点快速划入所属簇中,从而大大加快了聚类速度。其具体实现的伪代码如下所示: Map函数: Input:Canopy中心点集合List(c1,c2,…,cn),K值,数据集D(d1,d2,…,dn) Output:聚类中心点集合W' 1)While(W!=List) 2)计算List任意两点间的距离d(c,c') 3)将最短距离S(c)=min(d(c,c'))保存到数组Array1 4)依次计算D中每一个数据点到List中各点的距离dist'[i] 5)If2dist'[i]≤S记录此点属于第i个Canopy中心点的簇,然后从D中删掉此点,并对不满足条件的数据点,将其到该中心点的距离保存到数组Array2 6)EndIf 7)If(D!=Null) 8)将上述不满足条件的数据点,根据计算的点到中心点的距离,将其划分给距离最小的簇心并进行标记 9)EndIf 10)重新计算所有被标记点的新簇心W' 11)IfW=W'Break 12)Else返回2) 13)EndWhile Combine函数: Input:D中数据点所对应下标key,key值所属 Output:D中数据点所对应下标key,每个簇中已被标记的所有数据点的各维累加值,key值所属 解析各维坐标值,求出各维累加值和,并保存到对应列表中 Reduce函数: Input:D中数据点所对应下标key,key值所属 Output:D中数据点所属簇的下标key,最终簇心W' 1)While(D.hasNext()) 2)初始化num=0记录所属簇内数据点的数目 3)解析D.next()中的各维下标值,计算num 4)计算各维下标值累加和并存储到对应列表中 5)num++ 6)EndWhile 7)汇总得出最终簇心W',并返回生成全局结果 在每一次Reduce执行完成后,比较新簇心与前一次的簇心,如果不发生变化(即收敛)则算法结束,否则继续执行上述过程直到收敛。最后集群上每个节点的数据点都被划分到对应的簇中,主节点汇总信息得出最终聚类结果。 SBTICK-means并行聚类算法在保持较高聚类准确率的前提下,不仅解决了聚类中心预选取和减少迭代冗余计算的问题,而且将其成功应用于Spark框架中,充分利用其内存计算优势,大大提高了聚类速度。与基于MapReduce的框架相比,该算法在处理海量数据时,运行时间更短,因此所提出的SBTICK-means算法更适合应用于大数据的聚类分析中。 3.1 实验环境、测试数据集及评价指标 实验平台是在Hadoop2.6.0的YARN基础上部署Spark框架,在Vcenter中创建6台虚拟机,包含1个Master节点和5个Slave节点。操作系统版本均为Ubuntu 14.04.3-Server-amd64,Hadoop版本为2.6.0,Spark版本为1.4.0,Java开发包版本为jdk1.7.0_79,程序开发工具为Eclipse Mars.1 Release (4.5.1),算法使用Java实现。 实验测试数据集利用UCI数据集下的Iris(数据对象150,属性4)、Wine(数据对象178,属性13)及Balance Scale(数据对象625,属性4)来验证算法的有效性。同时将数据集Poker-hand-testing(数据对象1025010,属性11)按照数据集的形式随机生成大小不同的5个数据样本,D1(100万个样本点)、D2(200万个样本点)、D3(500万个样本点)、D4(800万个样本点)、D5(1 000万个样本点),来验证算法加速比和扩展比,并与MapReduce框架下的结果进行比较。 为了测试SBTICK-means算法的整体性能,采用以下几个评价指标:准确率、Sizeup、Scaleup以及与MapReduce框架下的运行时间比。 3.2 实验结果及分析 为了验证SBTICK-means算法的有效性,使用实验平台中的3个节点,利用UCI数据集,对K-means算法[7]、Canopy-K-means算法[4]与SBTICK-means算法的有效性(准确率%)进行比较,结果如表1所示。 由表1结果可以看出,SBTICK-means算法、Canopy-K-means算法分别与K-means算法相比,在准确率上都有一定的提高,说明使用Canopy算法进行预处理可以有效提高聚类的准确率,同时也验证了SBTICK-means算法的聚类有效性。 另一方面,为了验证SBTICK-means算法的可扩展性,测试不同大小的数据集D1、D2、D3、D4、D5在不同节点数下的加速比和扩展比,实验结果如图2、图3所示。 由图2、图3可知,该算法在处理少量数据时,随着节点数的增加,加速比呈线性增长。但当节点数增加到3个后,加速比曲线趋向平缓或逐渐下降,扩展比也随之下降。这是因为当数据集的规模较小时,随着子节点数目的增加,集群运行时间、任务调度时间、数据通信时间的增加,降低了计算速度。而D5数据样本的加速比基本呈线性增长,并在6个节点时达到最大值5.6,扩展比变化趋势也较平缓,在5个节点时才稍有下降。这说明,样本规模越大,SBTICK-means算法的处理效率越高,聚类效果越明显。 表1 不同算法20次随机实验的测试结果平均值 图2 SBTICK-means算法的加速比 图3 SBTICK-means算法的扩展比 为进一步验证该算法的性能优势以及在Spark框架的计算优势,利用实验平台中的6个节点,测试在不同大小的数据样本下,SBTICK-means算法与Canopy-K-means算法的平均运行时间(ms),结果如图4所示。 由图4可以看出,两种算法对不同大小的数据样本的执行时间是不同的,SBTICK-means算法具有更短的运行时间,与Canopy-K-means算法相比平均可缩短18%,并且数据样本越大,优势越明显。原因是在迭代计算过程中引入三角不等式原理,减少了迭代计算次数,从而加快了聚类速度。 图4 两种算法运行时间的对比 另外还测试了在处理相同大小的数据样本D5时,该算法分别在Spark框架和MapReduce框架下的运行时间(ms),结果如图5所示。 图5 两种框架运行时间的对比 由图5可以看出,Spark的性能要优于MapReduce,在6个节点时运行效率最高可提高1.261倍。这是因为Spark使用RDD进行迭代计算的特点,不需要将中间数据存在磁盘中,从而大大减少了运行时间,提高了聚类速度。 针对传统K-means算法在处理海量数据时存在距离计算瓶颈及因迭代计算次数增加导致内存不足的问题,对传统K-means算法进行了改进,将其与Canopy算法、三角形不等式定理相结合,并应用于Spark框架中,提出了一种优化的SBTICK-means算法,提高了原算法的整体性能。实验结果表明,该算法具有较高的聚类准确率和较快的聚类速度,并且在加速比、扩展比上都有所提高,更适合应用于大数据的聚类研究中。 [1]JainAK.Dataclustering:areview[J].ACMComputingSurveys,1999,31(3):264-323. [2] 孙吉贵,刘 杰,赵连宇.聚类算法研究[J].软件学报,2008,19(1):48-61. [3] 张石磊,武 装.一种基于Hadoop云计算平台的聚类算法优化的研究[J].计算机科学,2012,39(S2):115-118. [4] 衣治安,王 月.基于MapReduce的K-means并行算法及改进[J].计算机系统应用,2015,24(6):188-192. [5] 王永贵,武 超,戴 伟,等.基于MapReduce的随机抽样K-means算法[J].计算机工程与应用,2016,52(8):74-79. [6] 毛典辉.基于MapReduce的Canopy-Kmeans改进算法[J].计算机工程与应用,2012,48(27):22-26. [7] 梁 彦.基于分布式平台Spark和YARN的数据挖掘算法的并行化研究[D].广州:中山大学,2014. [8] 张顺龙,库 涛,周 浩.针对多聚类中心大数据集的加速K-means聚类算法[J].计算机应用研究,2016,33(2):413-416. [9]ElkanC.Usingthetriangleinequalitytoacceleratek-means[C]//ICML.[s.l.]:[s.n.],2003:147-153. [10] 孟海东,任敬佩.基于云计算平台的聚类算法[J].计算机工程与设计,2015,36(11):2990-2994. [11]MengX,BradleyJ,YuvazB,etal.MLlib:machinelearninginapachespark[J].JMLR,2016,17(34):1-7. [12]ArmbrustM,DasT,DavidsonA,etal.Scalingsparkintherealworld:performanceandusability[J].ProceedingsoftheVLDBEndowment,2015,8(12):1840-1843. [13]ArmbrustM,XinRS,LianC,etal.Sparksql:relationaldataprocessinginspark[C]//Proceedingsofthe2015ACMSIGMODinternationalconferenceonmanagementofdata.[s.l.]:ACM,2015:1383-1394. [14] 廖 彬,于 炯,张 陶,等.基于分布式文件系统HDFS的节能算法[J].计算机学报,2013,36(5):1047-1064. [15]WuJ,HongB.Multicast-basedreplicationforHadoopHDFS[C]//IEEE/ACISinternationalconferenceonsoftwareengineering,artificialintelligence,networkingandparallel/distributedcomputing.[s.l.]:IEEE,2015:1-6. 勘 误 我刊于2017年第27卷第4期刊载张明辉的论文《基于FCM的无检测器交叉口短时交通流量预测》因作者人数有误,现更正为:张明辉,宗智嵩,王夏黎。特此更正。 Parallel Clustering Algorithm with Spark Framework LI Lin-lin1,NI Jian-cheng2,CAO Bo1,YU Ping-ping1,YAO Bin-xiu1 (1.College of Information Science and Engineering,Qufu Normal University,Rizhao 276826,China;2.College of Software,Qufu Normal University,Qufu 273100,China) In view of the issues that when processing massive data,traditionalK-meansalgorithmhasthebottlenecksofdistancecomputationandcausesmemoryoverflowduetoincreaseofiterativecalculation,theSBTICK-means(SparkBasedTriangleInequalityCanopy-K-means)parallelclusteringalgorithmbasedonSparkframeworkhasbeenproposed.InordertobettersolvetheproblemofblindnessandrandomnessaboutKvalue’sselection,initialclustercentersandKvaluehavebeenpreprocessedbyCanopy.DuringK-meansiterativecalculation,redundantcomputationhasbeenreducedandclusteringspeedhasbeenacceleratedbythetriangleinequalitytheorem.CombinedwithSparkframeworkandmadefulluseofmemorycomputingadvantages,thedataprocessingspeedhasbeenimprovedandtheoverallrunningtimeofthisalgorithmhasbeendecreased.Experimentalresultsshowthattheproposedalgorithmhasimprovedclusteringefficiencywhileensuringtheaccuracyrate,andthatatthesametime,thesize-uprate,scale-uprateandoperatingspeedhavebeenimprovedcomparedwiththetraditionalK-meansalgorithmandCanopy-K-meansandthisalgorithmbasedonMapReduceframework.Thereforeitcanbemoresuitableforclusteringresearchofmassivedata. K-means;Spark;bigdata;Hadoop;MapReduce 2016-06-29 2016-10-12 网络出版时间:2017-03-07 国家自然科学基金(青年基金)(61402258);山东省本科高校教学改革研究项目(2015M102);校级教学改革研究项目(jg05021*) 李淋淋(1991-),女,硕士研究生,CCF会员,研究方向为并行与分布式计算、数据挖掘;倪建成,博士,教授,CCF会员,研究方向为分布式计算、机器学习。 http://kns.cnki.net/kcms/detail/61.1450.TP.20170307.0922.096.html TP A 1673-629X(2017)05-0097-05 10.3969/j.issn.1673-629X.2017.05.0213 实 验




4 结束语
猜你喜欢
中等数学(2022年6期)2022-08-29
黑龙江大学自然科学学报(2022年1期)2022-03-29
小资CHIC!ELEGANCE(2022年1期)2022-01-11
中学生数理化(高中版.高考数学)(2021年11期)2021-12-21
数学物理学报(2021年1期)2021-03-29
计算机技术与发展(2020年8期)2020-08-12
电脑报(2020年12期)2020-06-30
校园英语·上旬(2019年6期)2019-10-09
电脑报(2019年4期)2019-09-10
燕山大学学报(2015年4期)2015-12-25
