
一种改进的支持向量机参数寻优方法∗
2017-08-01 13:49吕金锐
计算机与数字工程 2017年7期
吕金锐
(太原城市职业技术学院太原030027)
一种改进的支持向量机参数寻优方法∗
吕金锐
(太原城市职业技术学院太原030027)
误差惩罚参数和核参数是决定SVM泛化能力的主要因素,对这两种参数的优化是SVM应用中需要解决的关键问题之一。论文在研究支持向量机理论的基础上,利用一些标准的测试数据集研究了均匀设计方法在RBF核参数优化问题上的表现。通过对比寻优精度,发现和传统均方设计方法相比,采用论文的方法能进一步提高精度。
SVM;均方设计;RBF核参数
Class NumberTP18
1 引言
支持向量机(SVM)是Vapnik等在COLT-92提出的一种新型的机器学习方法,其主要理论基础为统计学习,并依据风险最小化原理推导而出。SVM在有限的样本空间中进行统计分析,在模型的复杂性和机器的学习能力之间寻找最优路径,从而得到最好的推广能力[1~2]。与传统的人工神经网络、决策树分类及Kmeans聚类等算法相比,不仅数据模型结构简单,而且泛化推广能力更高。
Vapnik及其合作者在统计研究中发现,SVM的核函数主要有四种,不同的核函数可以构造不同的SVM,但对SVM的分类结果影响极其有限,然而核函数参数的选择却是影响SVM性能的关键,也是影响其实用化的主要障碍之一。如何获得最优的参数,必须借助相关的参数优化算法。本文在传统的均方设计方法的基础上设计了一种改进的算法,通过实验分析表明,采用改进后的参数优化方法在寻优精度上有了提高。
2 支持向量机基本原理
支持向量机最初的设计是为解决线性(Linear)可分情况的。对两类线性可分情况而言,需要找到一条最佳分类线,该分类线不仅要将两类样本数据无错误的分割开,而且必须满足两类样本的分类间隔最大。
假设线性可分样本集为{(xi,yi),i=1,2,3,…,n},xi∈Rd,yi∈{+1,-1},其中d代表d维空间,其线性(Linear)判别函数的表达式为g(x)=w·x+b,其分类面方程就是w·x+b=0。将判别函数进行归一化处理,使两类样本都满足||g(x)≥1的条件,由于任意点xi到H的距离为:这样分类间隔。从表达式可以推导出,‖‖w最小,分类间隔最大。要求分类面将两类样本全部正确的分割,必须满足:yi(w·xi+b)-1≥0,i=1,2,3,…,n。
计算支持向量机的过程就是求最佳分类面的过程。因此可以通过求解下面的二次优化问题获得:
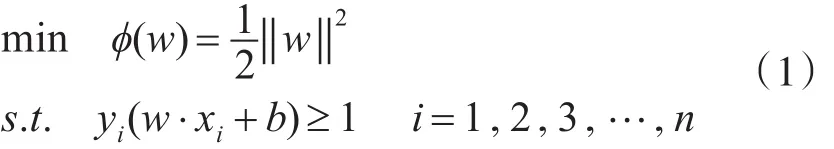
满足yi(w·xi+b)=1的训练样本叫做支持向量。式(1)为在约束条件下求极值的过程,可以通过Lagrange优化方法将其转化为对偶问题。具体过程是先求出原问题的Lagrange函数:,其中αi≥0为Lagrange乘子,再对式中的w和b求偏导并令其等于0。将得到的等式代回原Lagrange函数,从而得到对偶目标函数。
若α*i为最优解,则该分类面的权向量和偏移量分别为和b*=yi-w*·xi,这是一个二次规划问题,存在唯一的解,即全局最优解。从表达式中可以推导出,α*i=0的样本对w*不起作用,只有不等于0的样本对w*起作用,从而影响分类结果。α*i≠0的样本被定义为SV,因为它们支撑了整个最优分类面,所以叫支持向量。最终的决策函数为
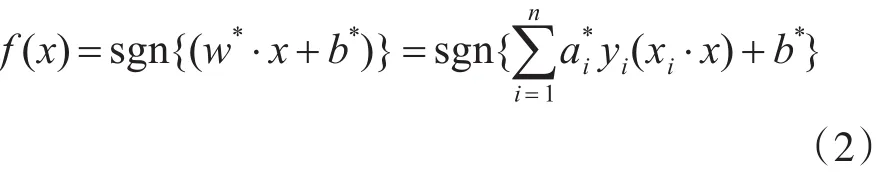
首先提取待分类样本的特征向量,将特征向量输入决策函数,输出即为该样本的分类结果。
考虑线性不可分的情况,可引入核函数的概念。其基本原理是在当前维度无法分割的样本点映射到高纬度空间进行分割。在特征空间中构造最优分类超平面时,假设非线性映射为ϕ,其训练算法仅使用空间中的点积ϕ(xi)·ϕ(xj)。根据泛函的相关理论,只要某一函数K(xi,xj)满足Mercer条件,即该函数为半正定函数,那么它就可以作为核函数,并且对应某一变换空间中的内积。因此选择合适的核函数可实现空间变换后的线性分类,但模型的复杂度不变,此时的目标函数函数变换为
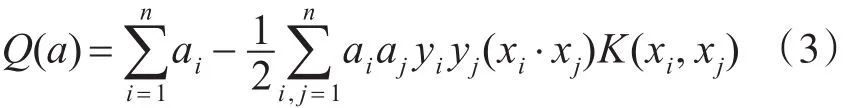
相应的决策函数为
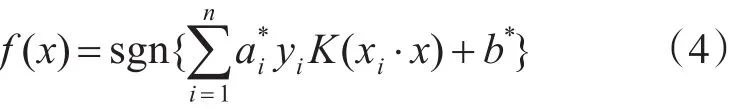
采用不同的内积函数将推导出不同的SVM表达形式,其内积函数也称之为核函数,常用的核函数有线性核函数(linear)、多项式核函数(polynomi⁃al)、径向基核函数(RBF)以及二层神经网络核函数(Sigmoid tanh)等。
核函数K(xi,xj)、映射函数ϕ(x)以及高维特征空间F是一一对应的,核函数直接影响支持向量机样本点投影到高维空间的分布。支持向量机为了构造最优分类超平面,获得较高的推广性能,需要样本数据点在高维特征空间有良好的分布。很多实验结果表明,在没有任何先验知识的数据情况下,选择RBF核进行支持向量机学习往往可以取得很好的分类效果;同时,目前针对RBF核SVM的研究比较多,各种实验结果也较多,便于和本文的结果进行比较[4]。
3 支持向量机参数优化问题
在机器学习中,学习现有的规律进行总结并对未知的知识进行判断决策,这样的能力称之为推广性能。在SVM中,核参数λ和误差惩罚参数C是影响其推广性能的主要影响因素。核参数λ的改变可以影响映射函数,从而改变样本在高维特征空间的分布,而对于支持向量机问题来说,在高维特征空间构造最优分类超平面直接影响其推广性能,所以核参数λ对支持向量机的推广性能影响巨大。误差惩罚参数C的作用是确定针对出现误差的容忍度[5~6],C越大,越不能容忍出现的误差。
因此可以得出结论,选择合适的参数,并对参数进行优化,是保证支持向量机进行机器学习并获得优良推广能力的前提条件。
常用的优化算法有网格搜索、均方设计方法、遗传算法、核校准算法和双线性搜索方法等。本文主要是通过研究均方设计方法,在此基础上做了进一步改进。
均匀设计方法是在20世纪80年代由方开泰,王元等提出的指导试验设计的方法。其目的是在多个影响因素,每个因素又有多个水平的情况下,通过在试验范围内挑选具有代表性的试验点,以尽量少的试验次数,达到最优效果。均匀设计思想的本质是在一个参数空间,挑选一些点,使其均匀分布在参数空间,这些均匀设计点可以代表整个参数空间的分布
要获得均匀设计点,需要运用均匀设计表。均匀设计表取决于参数的因素数和水平数;在参数优化过程中,影响结果的参数即为因素;水平指每个因素在试验允许范围内选取的具有代表性的几个取值。本文所要优化的参数是误差惩罚参数和核参数,即因素数为2;参数搜索的区间为[2-15,215],水平数为31[7]。
均匀设计的实验方法是:每个影响因素的每个水平线上只进行一次试验;任何两个影响因素的试验点在平面方格的交叉点上,每一行每一列有且仅有一个试验(交叉)点;其目的是保证实验样本在实验范围内的均匀分布。当影响因素的水平数增加时,试验次数按照水平数的增加量而增加。
在支持向量机参数优化中执行均匀设计的算法步骤主要是:
1)根据参数和参数搜索区域,确定均方设计因素为2,水平数为31;
2)利用均方设计软件,根据因素数和水平数生成均方设计表格;
3)根据均方设计表格,在参数空间选取31个均方设计点;
4)在均方设计点上涌支持向量机回归(SVR)拟合曲面,以代表整个参数空间上的正确率情况;
5)计算生成曲面上每个参数点的5重交叉检验正确率,从而找出最佳的参数组。
在本文支持向量机参数优化实验中,利用均匀设计方法,选出31个均匀设计点,计算5重交叉检验正确率,计算量为31×5,相比较网格搜索,均匀设计计算量大大减少,效率有很大的提高。
由于均匀设计方法是在均匀设计点上拟合曲面来代表整个参数区域上面的正确率分布情况,所以当均匀设计点取得过少时,有可能曲面的拟合精度不够,所以针对这一问题,提出了一种改进的方法,如图1所示。
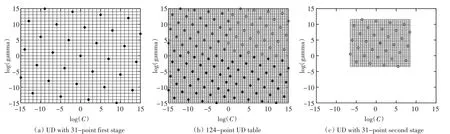
图1SVM参数优化均匀设计改进方法
首先将原来的参数区间划分为四个相同小区间,在每个区间上分别取31个均匀设计点。分别用四个区间中的点进行支持向量机(SVM)拟合曲面,在曲面上找出正确率最大的点,即得到局部最优点。
然后在这些局部最优点周围建立一个小的搜索区间,对这四个小区间进行更精确地搜索,从而找出最优参数,即“嵌套式”均匀设计方法[8]。
本文通过调用标准数据集对该方法进行了验证。标准数据集主要包括训练数据和测试数据两部分。训练数据主要用于训练生成支持向量机的模型;测试数据用来预测支持向量机的推广性能。每一个数据点包括两部分,样本和标签,对于两类分类问题,数据点的标签均为[-1,+1]。
本文中,采用以下标准数据集[9],这些数据集的输入维数从2~60,训练数据个数从140~1000,测试数据个数从75~7000均不等,且跨越范围很大,使得本文更有说服力。
4 实验结果分析
在实现优化算法的过程中,本文利用Matlab编程。本文试验都是在配置为2.0GHz双核处理器,1GB内存的计算机上进行。为了对比算法的精度,编程输出支持向量机最优参数的5重交叉检验正确率。
由图2可以发现,传统均匀设计方法与改进后的优化方法所获得的正确率差别不大,但是在小范围内提高了正确率。由图3可以看出均匀设计方法和改进方法在参数空间拟合的曲面正确率变化趋势[10],在最优参数点附近都是基本相同的,而且均匀设计点有良好的空间覆盖性,并且可以很好地代表空间的特性,可见改进后的方法是可行的。

图2支持向量机最优参数的5重交叉检验正确率
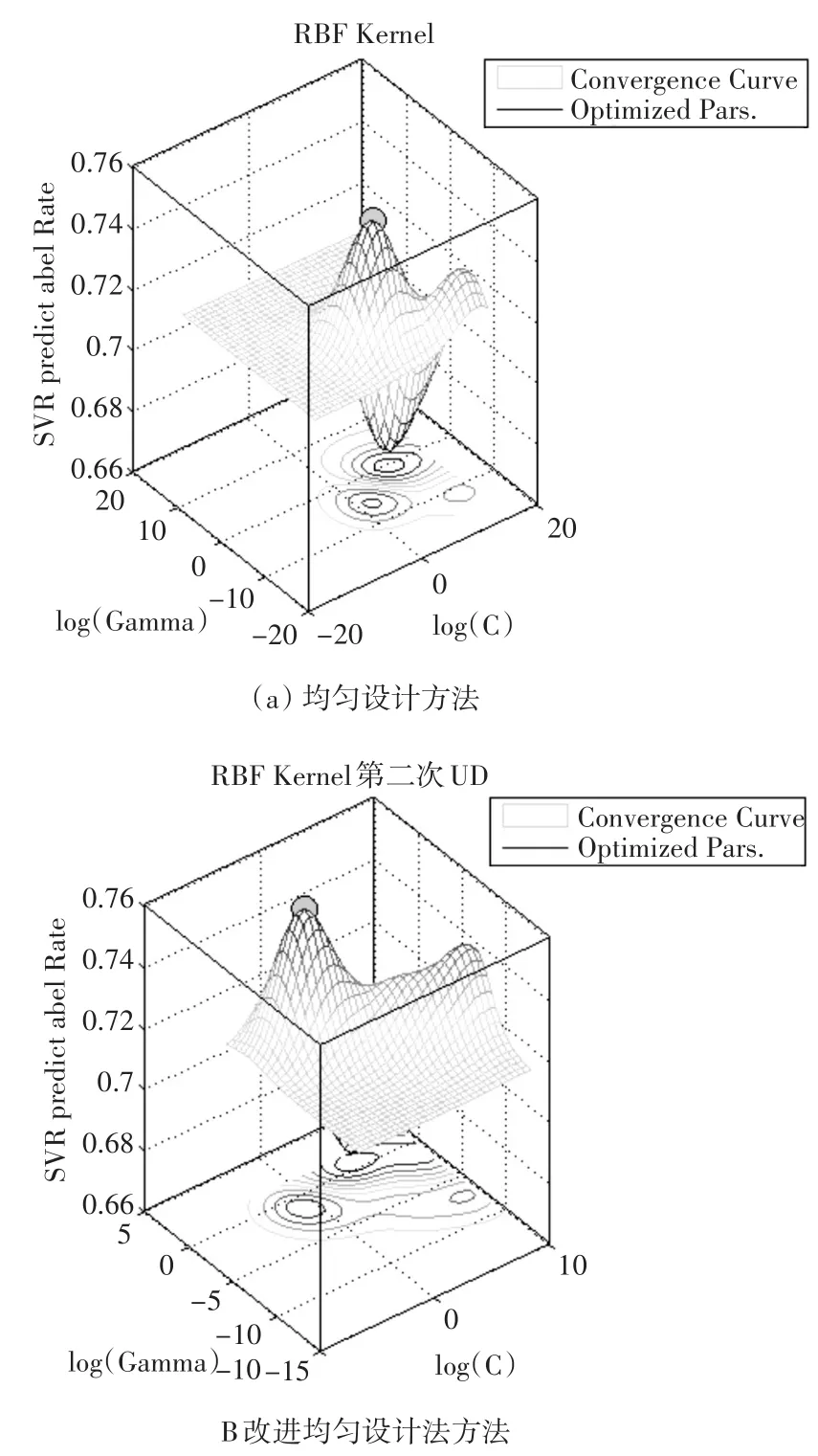
图3数据集breast-cancer均匀设计方法比较
利用本文的方法对惩罚因子进行最优查找,采用本文的方法获得最优惩罚因子为0.5,而传统的均方设计方法获得的最优惩罚因子为1。将获得的惩罚因子进行支持向量机的图像分割,由实验结果可以发现,采用本文的方法能进一步提高分割精度,如图4所示。

图4惩罚因子寻优结果比较
通过分类示意图,发现采用改进后的均方设计方法能小幅减少支持向量的个数,从而提高分类的精度,如图5所示。

图5分类示意图
从图5中可以发现,(a)为传统均方设计方法,其支持向量的个数为24个,分类错误率为13.04%,采用改进的方法其支持向量的个数为21个,分类错误率为6.52%。
5 结语
惩罚因子C越大,对错分样本的惩罚度越大,错分样本数将减少,分类间隔将逐渐减小,分类器的维数越来越高,分类器的泛化性能将变差;反之,随着惩罚因子C值的减小,对错分样本的惩罚度减小,错分样本数将增多,分类间隔逐渐增大,分类器的维数将逐渐减小,分类器的泛化性能也逐渐变差,因此需要在参数空间中进行最优查询,而采用本文的参数寻优方法是可行的。
[1]邓乃阳.数据挖掘中的新方法-支持向量机[M].北京:科学出版社,2003:63-64. DENG Naiyang.New method in data mining-support vec⁃tor machine[M].Beijing:Science Press,2003:63-64.
[2]Vapnik V.N.The Nature of Statistical Learning Theory[M].New York:Springer,2000:171-176.
[3]丁世飞,齐丙娟,谭红艳.支持向量机理论与算法研究综述[J].电子科技大学学报,2011(1):3-4. DING Shifei,QI Bingjuan,TAN Hongyan.An Overview on Theory and Algorithm of Support Vector Machines[J]. Journal of University of Electronic Science and Technolo⁃gy of China,2011(1):3-4.
[4]李俊飞.一种支持向量机在线学习分类算法[J].伊犁师范学院学报(自然科学版),2015(4):56-57. LI Junfei.An Online Learning Algorithm for Classifica⁃tion of Support Vector Machine[J].Journal of Yili Normal University(Natural Science Edition),2015(4):56-57.
[5]闫国华.支持向量机回归的参数选择方法[J].计算机工程,2009,35(13):218-220. YAN Guohua,ZHU Yongsheng.Parameters Selection Method for Support Vector Machine Regression[J].Com⁃puter Engineering,2009,35(13):218-220.
[6]Liu Yu-Hsin.Global maximum likelihood estimation pro⁃cedure multinomial probit(MNP)model parameters[J]. Transportation Research Part B:Methodological,2008,34(5):419-449.
[7]栗志意,张卫强,何亮,等.基于核函数的IVEC-SVM说话人识别系统研究[J].自动化学报,2014(4):780:782. LI Zhiyi,ZHANG Weiqiang,HE Liang.Speaker Recogni⁃tion with Kernel Based IVEC-SVM[J].Acta Automatica Sinica,2014(4):780:782.
[8]梁亮,杨敏华,李英芳.基于ICA与SVM算法的高光谱遥感影像分类[J].光谱学与光谱分析,2010,10(30):2724-2726. LIANG Liang,YANG Minhua,LI Yingfang.Hyperspectral Remote Sensing Image Classification Based on ICA and SVM[J].Algorithm.Spectroscopy and Spectral Analysis,2010,10(30):2724-2726.
[9]Hyvarinen.A.Fast and robust fixed-point algorithms for independent component analysis[J].IEEE Transactions on Neural Networks,1999,4:895-896.
[10]张倩,杨耀权.基于支持向量机核函数的研究[J].电力科学与工程,2012,5(28):42-43. ZHANG Qian,YANG Yaoquan.Research on the Kernel Function of Support Vector Machine[J].Electric Power Science and Engineering,2012,5(28):42-43.
An Improvement of Support Vector Machine Parameter Optimization Method
LV Jinrui
(Taiyuan City Vocational College,Taiyuan030027)
The penalty parameter and the kernel parameter are the main factors to determine SVMs'generalization perfor⁃mance and the optimization of these two parameters is one of the key issues,which needs to be solved in the application of SVM. Based on the research of SVM theory,through programming,the paper uses some standard test data sets to compare the perfor⁃mance of uniform design method in the RBF kernel SVM parameter optimization problems.Through the comparison of accuracy,it is showed that the further precision can be obtained compared with the traditional method.
SVM,uniform design,RBF kerne
TP18
10.3969/j.issn.1672-9722.2017.07.017
2017年1月3日,
2017年2月27日
吕金锐,男,硕士,研究方向:计算机网络技术、数字图像处理。
猜你喜欢
太原科技大学学报(2022年4期)2022-08-18
广西民族大学学报(自然科学版)(2022年1期)2022-05-18
新高考·高一数学(2022年3期)2022-04-28
医学食疗与健康(2022年3期)2022-04-23
科技风(2021年19期)2021-09-07
中学生数理化(高中版.高考数学)(2021年1期)2021-03-19
软件(2018年1期)2018-02-05
家教世界·创新阅读(2016年11期)2016-12-27
哈尔滨理工大学学报(2016年3期)2016-11-05
故事会(2016年15期)2016-08-23
