
基于爬虫技术的征信系统实现方案
2017-09-06 04:11余洋军
科学与财富 2017年24期
关键词:网络爬虫
余洋军
摘 要: 建立大数据征信系统,能消除信息不对称,提供更快、更精准的信用决策。可以通过对实时交易数据的大数据分析,分析用户是否有异常贷款、借新还旧、信用恶化等实时评估并进行预警。根据人口属性、社会交往、行为偏好等信息构建用户消费画像。为互金、大数据、支付、银行、保险、电商等各领域提供决策依据。本文将介绍基于爬虫技术如何在征信系统中的应用和实现。
关键词: 社会信用体系;信用平台系统;网络爬虫
一、征信系统的现状与发展
(一)社会信用体系建设的意义
社会信用体系是一个庞大的系统,主要涉及三个方面:一是规范、约束信用行为的法律体系;二是促进企业自覺履行承诺的诚信体系;三是帮助债权方判别交易对象信用状况、违约风险、降低信用交易成本的征信体系。建立和完善社会信用体系是我国社会主义市场经济不断走向成熟的重要标志之一。信用是市场经济的通行证。现代市场经济是建立在法制基础上的信用经济。没有信用,就没有秩序,市场经济就不能健康发展。在市场经济尚不完善的我国,虽然实现了经济的腾飞,但是相应的社会信用体系建设依然滞后。当前,信用状况差是我国社会主义市场经济发展的一个薄弱环节,已成为影响和制约经济发展的突出因素。由于缺乏足够的信用,直接导致不少企业陷入危机。面对目前这种情况,建立健全现代市场经济的社会信用体系尤为迫切。
(二)征信系统现状
近些年随着消费金融的不断深入发展,征信行业逐步得到大家的重视。目前国内征信只是初步建立了完整产业体系,其在各个环节尚存在不同问题。相比美国成熟征信市场来说,目前中国仍处于数据源争夺战中,各家征信机构仍将数据资源视为核心竞争力。目前国内与“征信服务”相关的公司有2000多家,其中完成备案的企业征信机构约135家左右。相对于企业征信较容易获取牌照,央行尚未完全放开个人征信牌照,目前仅以芝麻信用、前海征信、腾讯征信、拉卡拉征信、中智诚征信、中诚信征信、鹏元征信和华道征信等八家作为个人征信试点机构。除这八家试点之外,还有很多创业平台为机构客户提供个人信用服务,如算话征信、新颜征信、立木征信、探知数据、聚信立等等。这类平台作为大数据出身,在数据采集、数据处理方面具有丰富经验,并且并不局限于金融行业,同时在切入征信时,大多会选择从营销入手,再向信用延展。例如大数据公司集奥聚合,其数据优势体现在运营商和互联网方面,目前其不仅为客户提供精准营销等服务,还提供信用评估产品,涉足征信行业。目前征信机构在整合多维度数据源后,才能建设模型并提供具体征信服务。例如新颜征信结合自身海量互联网金融数据,建立起庞大的反欺诈库,同时通过授权数据和政府公开数据进行有效地交叉验证。目前不同征信机构在数据源方面,都形成了自己的差异化优势。在场景应用上,目前大多数征信机构还是集中于金融领域,而不少机构已经开始积极拓展金融以外的信用应用场景,比如个人租房,上下游企业交易,甚至谈恋爱等等。征信就像在陌生企业和陌生人群交易之间的建立起了无形的信用中介,对交易的顺利进行和风险控制有很大的帮助。例如芝麻信用近期与OFO单车及蘑菇租房等进行深度跨界合作,将信用产品应用于出行和租房领域。
然而目前国内各家征信机构仍处于数据源争夺战中,仍将数据资源视为核心竞争力,同时还存在各种问题,例如:采集场景是互相割裂、数据源不全面、数据质量不高、盈利模式单一、法律保障体系不完善等。
(三)征信系统未来方向
相关数据显示,我国每年因为诚信缺失造成的经济损失约为数千亿元。所以征信市场空间较大,产业资本及金融资本出于风控、完善生态体系目的,加紧布局征信。未来征信一定会采用大数据等技术降低征信成本,而且征信市场最终会形成高集中度等特征。大数征信的技术关键在于数据整合、数据挖掘和评级模型。数据整合体现为将出现在多个数据源中个人信息甄别同一个人,并整合成完整的个体信息。伴随着政策的放开,我国征信市场发展迅速,初步形成政府背景下信用信息机构、社会征信机构、评级公司等机构的多元化征信市场。征信系统的未来发展趋势,预计制度保障层面将更为完善,行业层面将细分化,数据等基础资源供给将趋于优化,机构在场景方面将更加广泛。就目前形势来看征信业存在极为明显的规模经济,随着数据库规模的扩大和查询量的增加,业务成本逐步降低,并且随着数据数量和质量的提升,在激烈的市场竞争下,会出现一批非常优秀的征信公司和产品。
二、爬虫技术分类及工作原理
爬虫是一种按照一定的规则,自动地抓取网页信息的程序或者脚本,可以自动采集所有其能够访问到的页面内容,以获取或更新这些网站的内容和检索方式。其按照系统结构和实现技术,大致可以分为以下几种类型:通用网络爬虫、聚焦网络爬虫、增量式网络爬虫、深层网络爬虫。 在实际应用中通常根据实际需要将几种爬虫技术相结合来使用。在爬虫系统框架中,主要过程由采集器,解析器,数据存取三部分组成。采集器的主要工作是负责给多线程中的各个爬虫线程分配工作任务。解析器的主要工作是对已经采集下来网页资源,对关心的数据进行解析处理。数据存取是对已经解析好网页资源,进行数据结构化整理,生成可用的数据资源,最终实现数据落地入库。
Robots协议(也称为爬虫协议、机器人协议等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎哪些页面可以抓取,哪些页面不能抓取。由于每个爬虫实现机制的不同,需要根据实现情况来关注Robots协议。
三、征信系统中爬虫系统设计与实现
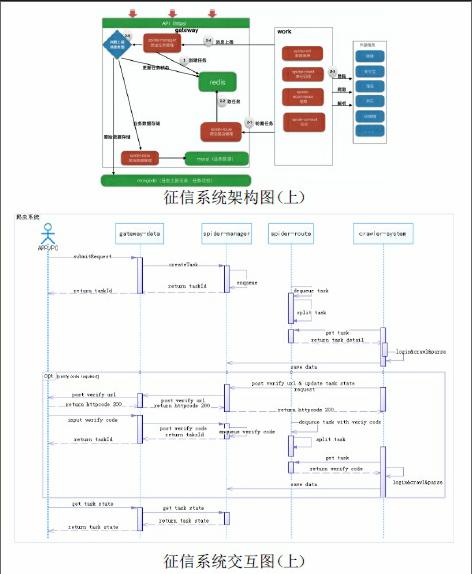
(一)征信系统整体设计架构
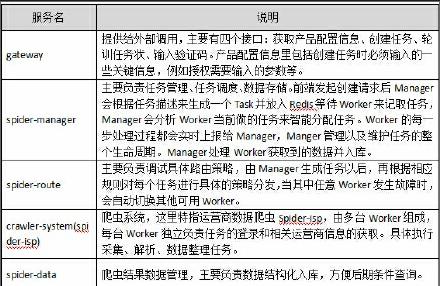
(二)征信系统(运营商爬虫)各服务组件
征信系统爬虫由多个具体模块组成,现以运营商爬虫为例介绍具体实现方案。运营商爬虫模块由用户授权(API输入用户名、密码和短信验证)进行登陆相应运营商网站,来获取该用户相关信息。由于国内运营商(中国联通是统一的官网除外)是每个省份独立维护的,其登陆、验证及数据获取都是相对独立的,必须针对中国电信、中国移动的每个省份单独处理。征信系统爬虫模块各服务组成如右:endprint
(三)征信系统(运营商爬虫)具体实现
运营商爬虫开发选取Java语言开发,整个上采用Sping-boot、WebClient、Selenium 等技术。整体流程为主线程循环请求spider-route服务,通过指定任务类型(ISP)获取运营商数据攫取任务请求。通过前置条件检验后,再根据外部服务(www.ip138.com)网站获取所需要运营商类型(中国联通、移动和电信)和省份,自动分配对应的爬虫处理器来完成具体工作。一般情况下,分布式的多线程爬虫处理器被调用后,会根据具体运营商情况来进行登陆前准备工作:将需要的图片验证码发回给spider-manager,处理任务结束线程,由spider-manager提供验证码入口并生成新任务。此时分布式的多线程爬虫处理器又被调用,并且保证在正确的处理节点完成登陆工作。由于采用授权方式获取数据,在获取用户相关个人信息时,处理器会调用运营商官网接口发授权短信,通过同上操作步骤,让用户输入正确的短信验证码。在验证短信授权后,通知spider-manager登陆状态,同时对用户的基础信息、通话、短信、网络、账单、缴费等信息爬取后,保存到缓存中后将运营商登出。系统再根据缓存中的运营信结果信息自动寻找相对应的解析器,将缓存中信息解析成JSON格式,并将数据发送给spider-manager进行存储并调用spider-data进行数据结构化处理。由于处理器和解析器都为分布式多线程任务,对登陆、爬取、解析通过spider-manager进行统一调度,登陆后采取Cookies传递保证访问的路径都处于已经授权状态。
(四)系统性能要求
1.稳定性:整个系统的处理能力在40万任务/天以上(30台Worker),峰值处理能力在4万任务/小时,关键服务都是主从配置。可通过简单增加worker数量来进行无限很想扩容。
2.扩展性:可以根据业务的扩展需求进行动态、快速的扩展,扩展期间不影响现有系统的正常工作。(硬件资源需提前准备好)
3.安全性:服务间调用都以SSL为加强对数据的安全性保护。用户账户密码等身份信息都做了加密处理。
4.维护性:Gatewary、Manager、Router、Worker等所有服务都可以全自動部署。部署过程中对系统的稳定性不受影像论文什么的都需要公司盖章,这个找哪位响。■endprint
猜你喜欢
电脑知识与技术(2017年1期)2017-03-24
电脑知识与技术(2017年1期)2017-03-24
计算机时代(2017年2期)2017-03-06
中国新技术新产品(2017年4期)2017-03-04
中国新通信(2016年21期)2017-01-06
电脑知识与技术(2016年20期)2016-08-19
电脑知识与技术(2016年17期)2016-07-23
中国市场(2016年23期)2016-07-05
科技经济市场(2016年2期)2016-06-16
电脑知识与技术(2016年7期)2016-05-19
