
基于关联规则的学生成绩分析
2017-10-21 17:16杨春光
电脑知识与技术 2017年20期
关键词:关联规则
杨春光

摘要:在当今社会中,“大数据”这个名词的出现,越来越影响着我们的生活,在教育领域中“大数据”的应用更是逐渐被重视,该文正是将“大数据”的处理融入教育中,通过功能需求、技术需求及数据需求进行深入分析和整合,然后再根据规则权重的不同分为消极类型和积极类型,与此同时按照分类规则设计公式分配不同的最小置信度和最小支持度,对其中的关联规则进行设计及分析,避免因为数据不充足而造成不平衡等问题。
关键词:关联规则;学业预警;成绩分析;成绩预测
1概述
大数据时代的到来标志着社会的发展来到了新的阶段,各行各业在不同的领域当中都在积极的适应并改变以往的传统模式,对相关数据进行收集、整理、分析用以寻求各自的发展。在教育领域也不例外。教育领域的数据收集主要包括学生学习成绩、日常表现、对任课教师的评价以及对相关课程的评价等。通过作用度、支持度、可信度、期望可信度等来表达其属性。
2需求分析
2.1功能需求
本研究实现的功能有以下几点:
(1)成绩预测
通过对大一新生的相关数据收集,在分析和预测过程中一旦发现,有考试不通过的可能性,就会提前对相应的同学进行通知,提醒其要在最后复习阶段要更加努力学习,以免在期末考试中无法通过。
(2)提前预警
在国内的各大高校当中,都会有考试不及格的同学,这些同学面临课程重修。在重修的过程当中,不仅加大了任课教师的教学负担,同时学生也会造成一些经济上没必要的损失。通过本文的数据收集、分析利用数据挖掘技术和关联规则技术帮助同学们提前准确定位到有可能出现重修的同学,让该类同学提早做好复习和学习准备,让任课教师也着重提前关注和警示此类学生,做到预测、提醒以及帮助。
(3)学生成绩分析
教育教学过程中,最重要最广泛被看中的就是考试分数,分数可以反映出学生学习努力的多少,教师授课的水平等。因此对于学生成绩的数据收集和整理分析更加尤为重要。以往并不是没有对学生成绩进行分析,只是以往的数据分析过于简单,直接,仅仅包括成绩的增长、下降和排名等,无法满足目前的教学需要。
2.2数据需求
数据来自于不同的來源,当谈论不同类型的数据,考虑每个变量的测量水平。
(1)区间变量的均值是有意义的,如平均成绩。
(2)分类:由一组水平的变量,如性别、成绩划分。
2.3技术需求
通过使用预测建模技术,我们就可以验证并肯定输入变量在进行预测结果变量是正确、有效并且是可用的。如果高校管理机构想尝试预测学生是否可以通过新学年期末考试,那么其可以通过确定学生的往年期末成绩和平时课堂成绩来进行评估和测定,这样有利于预测期末成绩的通过情况。输入变量和结果变量的区分,可用设定角色的方法为数据集进行确定。设定的模型角色的性子包括姓名,性别,地址,及其他所需要素的情况。若使用时出现多余要素的情况,便可排除多余要素,需要使用设定的角色模型确定可用变量的作用。识别结果变量可使用目标模型识别,输入变量可用输入模式识别。
3使用关联规则挖掘有重修风险的学生
3.1设计目标
为薄弱学生选择重修风险较大的课程,从我们的经验和实验发现,得分方法是更合适的,不是给每个学生分配一个明确的类,评分模型分配一个概率估计每个学生表达的可能性并做出预警。
3.2关联规则设计
(1)关系表
关联规则挖掘的数据,需要每个数值属性离散化后间隔关联规则挖掘。离散化后,可以将每个数据集作为一组对和一个类标签。每一个数据成为一个事务,现有的关联规则挖掘算法可以应用于数据集。对于得分,我们有一个固定的两类属性。
(2)使用关联规则用于学生得分
由于每个规则有附加的支持度和置信度,因此容易设计一个模式用于得分数据。当出现无数据的情况下,则不适合利用关联规则做设计。分配高分的前提要求是,有众多符合置信度规则的积极类数据。相反,消极类则分配低分。因此,通过加权平均的方式我们得到以下公式(如图1,分数s值在0与1之间)。
POS积极类项集,NEG消极类项集,con:原始的积极类规则置信度。w积极类规则i的权重,w消极类规则j的权重,con消极类规则i转换为积极类规则的置信度。
3.3关联规则分析
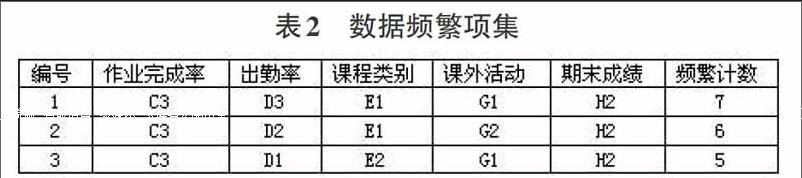
从记录中随机选择50条左右,选择的属性有性别、高中成绩、作业完成率、出勤率、课程类别、职务、课外活动、期末成绩共八类。
(1)离散化数据
A.性别属性离散化:A1(男)、A2(女)
B.高中成绩数据离散:B1(优异)、B2(良好)、B3(普通)
C.作业完成率离散化:c1(较好)、C2(一般)、C3(较差)
D.出勤率离散化:D1(较好)、D2(一般)、D3(较差)
E.课程类别离散化:E1(专业课)、E2(公共基础课)、E3(选修课)
F.职务离散化:F1(学生会及社团)、F2(班级干部)、F3(学生)
G.课外活动:G1(网络游戏)、G2(网络聊天、电影、购物等休闲)、G3(户外活动)
H.期末成绩:重修风险的学生分数点为45分,因此分为两类H1(≥45)、H2(<45)
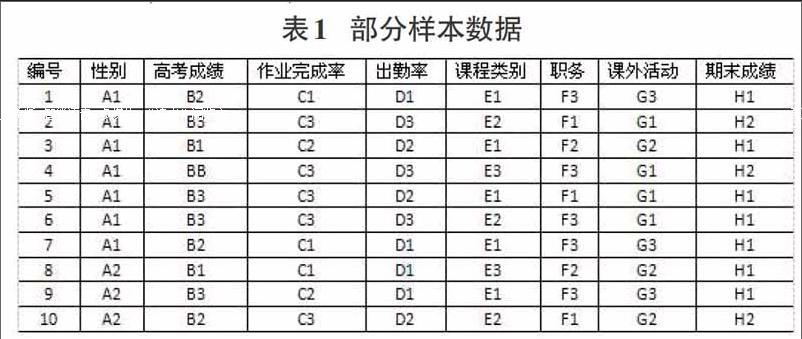
为使得数据挖掘获得有益的信息,设定的最小支持度为14%,最小置信度为80%,根据上述计算,最小频繁计数为7,获得的频繁项集如表2所示。
找出大于最小支持度的频繁项集计算该频繁项集的最小置信度,公式如下:
如果该值大于设置的最小置信度,则视为强关联规则。以期末成绩为目标属性,得到的关联规则为:
C3AD3AE1AGl=>H2.colffidence=7/7=100%
C3AD2AE1AG2=>H2.confidence=6/7=85.7%
C3ADlAE2AGl=>H2.confidence=5/7=71.4%
满足条件的前两条规则为:
(1)规则1:作业完成率C3(较差)、出勤率D3(较差)、课程类别E1(专业课)、课外活动G1(网络游戏),这些学生的期末成绩H2(低于45分)。通过数据分析得出以下结论,重修风险较大的学生有着以下共同特点,出勤率较低、完成作业情况不好、同时酷爱网络游戏,将大量时间和精力都放在玩上面,没有努力学习,因此影响到考试成绩,存在重大的重修风险,通过数据分析量化出来。
(21规则2:作业完成率c3(较差)、出勤率D2(一般)、课程类别E1(专业课)、课外活动G2(网络休闲类),这些学生的期末成绩H2(低于45分)。除了规则1中已经分析过的原因之外,发现出勤率提高一些对整体成绩帮助并不大,没有一个好的出勤率必然无法保证作业的完成率,也必然会由于专业课的难度而无法深入的理解内容,因此课程重修的风险较大。
4结论
此次研究通过筛选出一些有重修风险的学生,通过使用数据挖掘技术对数据进行分析,不仅可以提前对此类学生进行警示和帮助,也同时为广大教师减轻了后期的教学负担,针对于此类学生可以提早做出相应的准备和给予帮助,对于学校的教育教学提供了有力支持。endprint
