
图像情感语义分类及检索研究
2017-11-04 03:45王华秋胡立松
重庆理工大学学报(自然科学) 2017年10期
王华秋,胡立松
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
图像情感语义分类及检索研究
王华秋,胡立松
(重庆理工大学 计算机科学与工程学院, 重庆 400054)
提高情感语义映射和检索的准确率是图像检索的研究主题。在情感语义映射模型中,将图像的形状七阶矩和颜色矩作为模糊神经网络的输入,对网络的权值和阈值进行二进制编码,作为遗传算法的染色体串,通过遗传算法寻优得到情感语义映射效率最高的个体编码。在检索模型中,用遗传算法对图像匹配算法进行优化,直接找到最适合匹配的子模板坐标。相比传统的序贯相似检测算法,模型大大提高了图像匹配的效率。通过查全率与查准率的对比结果可知,经遗传算法优化后,图像情感映射和检索的性能均得到了明显提升。
情感语义分类; 图像检索; 遗传算法;模糊神经网络;颜色矩;形状七阶矩
数字影像在互联网的普及应用在一定程度上促进了数字图像的实时检索和处理技术的发展,各种检索技术相继问世。图像的低层特征往往被用来匹配图像的内容,目前在不同的应用中,对图像的搜索需求度越来越大。本文对图像情感语义进行探讨,通过提取低层特征来搜索图像,以期达到大众预想的结果。不同的图像可以激起人类不同的情感,冯特最早提出情感的三维说,罗素则提出了情感分类的环状模式。在当前的心理学界,使用最多的是PAD情感模型,该模型提出了关于情感空间的理论概念,适用于情感检测,因此PAD模型被广泛应用在心理学和产品满意度等研究领域[1-2]。
关于低层特征,本文研究图像中的颜色和形状。颜色特征具有对图像依赖小的特性,相比其他特征更加稳定可靠[3]。形状七阶矩特征是对区域进行相关描述的方法[4-5],使用该方法时无需关注外部情况(诸如移动等各种外部变换),只需对其内部特征进行了解即可,内部情况才是影响描述区域的真正因素。
作为分类算法的模糊神经网络(FNN)是结合了模糊近似推理算法得到的一种较前沿的神经网络[6]。遗传算法(GA)的核心算子是从大的解决方案的空间中随机选择一条染色体[7],包括编码、选择、交叉以及突变等过程[8]。在GA中,基因分布在染色体上,是GA中的最小单位,一个染色体代表了一个可行方案,由多个染色体在一起就形成了一个群体[9-10],即为一组解决问题的方案。
本文首先通过相关算法得到图像的底层特征,对于可能激起人类不同情绪变化的图片分别打上不同的标签,作为预测输出;在模糊神经网络的训练过程中不断调整输出误差,使结果能与预测输出得到最大程度上的近似。为了得到更好的图像分类效果,本文中还加入了遗传算法对网络进行优化,进一步得到最优解。
1 底层特征提取
1.1 颜色矩特征
本文提取的R、G、B的颜色矩各有三维,分别代表均值、方差、协方差。该方法的最大优势在于不需要再对提取出来的特征进行量化,其表示形式如下:
(1)

(2)

(3)
式中:μi为均值,μi越小,则图像越暗;σi表示方差,σi越小,则对应的颜色分布越窄;si表示协方差,当si>0时,图像为正偏;si<0时,图像为负偏;si=0时,图像的颜色分布是对称的。
1.2 形状特征提取
对于已给的数字图像函数f(x,y)的(p,q)阶矩,定义为:

(4)
质心为
xc=m10/m00,yc=m01m00
(5)
则(p,q)阶中心矩为

(6)
在数字图像中,上述积分可以采用以下形式:
(7)
标准化后的中心矩为
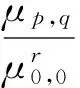
(8)

由此可以得到7个不变矩:
m1=η2,0+η0,2
(9)
(10)
m3=(η3,0-η1,2)2+(3η2,1+η0,3)2
(11)
m4=(η3,0+η1,2)2+(3η2,1+η0,3)2
(12)
m5=(η3,0-3η1,2)(3η3,0+η1,2)·
[(η3,0+η1,2)2-(3η3,0+η1,2)2]+
(3η2,1-3η3,0)(η0,3+η2,1)·
[3(η3,0+η1,2)2-(η0,3+η2,1)2]
(13)
m6=(η2,0-η0,2)[(η3,0+η1,2)2-
(η0,3+η2,1)2]+4η1,1·
(η3,0+η1,2)(η0,3+η2,1)
(14)
m7=(3η2,1-η0,3)(η3,0+η1,2)·
[(η3,0+η1,2)2-(3η2,1+η3,0)2]+
(3η1,2-3η3,0)(η0,3+η2,1)·
[3(η3,0+η1,2)2-(η1,2+η0,3)2]
(15)
1.3 特征归一化
形状与颜色作为不同的特征,在提取完成之后需要进行相应的处理才能作为本文中神经网络的输入量,这里对形状和颜色做线性放缩处理,即归一化,如式(16)所示:
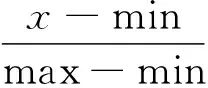
(16)
2 模糊神经网络
模糊神经网络结构见图1,其中:C1,C2,…,Ci表示颜色特征输入量,S1,S2,…,Sj表示形状特征输入量,Y1,Y2,…,Yn表示图像的情感语义。
FNN的第1层将输入量进行模糊化,设第i个输入xi模糊化后的隶属度为μi(xi),则:

(17)
其中:b>0,表示xi的标准方差;a为均值。
第2层完成输入到输出的映射,采用的函数为:

(18)
第3层输出模糊值,第4层实现解模糊。

图1 模糊神经网络模型
3 遗传算法
3.1 二进制编码
GA的基础是编码,本文将模糊神经网络(FNN)的阈值以及各层之间相互连接的权重连接起来形成编码。
本文采用二进制编码,与其他编码方式相比更加快捷。对种群进行一一编码时,种群中的每个个体都是1个由0和1组成的二进制串。首先将FNN的权值阈值用二进制串表示,若权值实际取值变化范围为[X1,X2],则采用二进制编码,表示值Xij与实际值的关系为

(19)
binrep是用L位字符串表示的二进制整数,同理求出对应的阈值编码θij,此后将所有的权值阈值编码连接起来形成一个个体编码串。
在编码完成之后求适应度值。每个个体对应的FNN的权重和阈值都不尽相同,通过训练集中的数据起到训练网络模型的作用。在本文中,用式(20)(21)求适应度值:
Fi=1/MSR
(20)
(21)

本文中的最大遗传代数为50,产生最好预测结果的FNN参数对应于GA的最优解决方案。
3.2 选择
选择过程中将染色体单位的适应度高低值作为评定标准。大部分情况下,值高的染色体生存的机会也更大,相对而言,值低的将面临被排除。对于染色体i,若Fi是相应的适应度值,则选择过程比较的指标如式(22)(23)所示:

(22)

(23)
其中:c为系数;n为个体数量,本文中取n=80。
3.3 交叉
交叉发生在成对的染色体个体之间,两两之间进行任意性的交叉,设个体的长度为L,定义一个1~(L-1)范围的任意的正整数作为交叉点,随后让2个染色体进行交叉,从而得到新的个体。在j位置处,个体ak和al进行实数交叉的公式如式(24)(25)所示:
(24)
(25)

f(g)=r2(1-g/Gmax)
(26)
(27)
式中各参数意义见表1。

表1 参数意义
4 检索系统的实现
4.1 情感语义映射
本文采用的自然图像库中有1 000张图片,分为古朴、和谐、清爽、自然、妩媚、生机、巍峨、鲜艳、希望、活跃10类。作为高层语义输出,每类选取80张图片作为训练集,20张图片作为测试集。本文中将颜色矩加上7阶不变矩共16维向量作为神经网络的输入,即输入节点为16个,图像情感分为10类。其中,训练集的输入是图像的低层特征,在网络训练完成之后加入测试集对构建好的学习模型进行测试。
图像的情感指的是一幅图片给人的最直观的感受。例如:蓝色大海的沙滩边度假的图片往往给人一种很清爽的感觉,微小的生命如蝴蝶的起舞展示出了勃勃生机的情感,远古建筑投射出一股庄严古朴的气息,常见的风景图描述了自然界的风光,色彩感很强的图片(如绿色)凸显了活跃的氛围,生物界动物的日常作息彰显了万物与自然环境的和谐共处,娇艳的花朵给观赏者的最直接感受是妩媚,日出时天边的绯红代表了生生不息的希望,雄伟高大的山峰展现了巍峨的身姿,色彩缤纷的食品外观看起来十分鲜艳。本文依据人对图片最直接的情感划分进行图像检索,将情感类别分为10类,具体研究内容如下文所述。
本文有语义映射和图像检索两大部分,其中情感语义映射采用语义映射的准确率即precise来判断优劣,其公式如式(28)所示:

(28)
precise指图像情感语义被正确映射的数量与总的需要被映射的图片数量的比值,通过使用优化前后的模糊神经网络分别进行映射过程,即FNN和GA-FNN,用平均值作为映射的结果。
任意选择5组语义进行映射,得到FNN和GA-FNN的数据统计,见表2。
从表2可以得知:采用GA优化后的FNN的准确率相比传统的FNN提高了7.6%,起到了较好的优化作用,提高了系统的准确度。
在进行情感语义映射的过程中,任选一种情感的图片进行映射,结果以直方图的形式展示出来。
本文将GA优化后的FNN与未优化的FNN进行对比。例如,清爽类图片使用FNN进行情感语义映射的系统展示见图2。使用GA优化后的FNN语义映射展示见图3。对比映射结果可知:GA-FNN的情感语义映射准确率要显著优于FNN。

图2 FNN语义映射的结果

图3 GA-FNN的语义映射结果
4.2 图像匹配算法
本文中的图像检索模块采用图像匹配算法中的序贯相似检测算法,即SSDA。使用SSDA算法可以保证图像匹配的全局最优性,以往的模板匹配算法是在未知的图像中寻找对应已知模型的子图像,将需要被搜索的图像与要被匹配的图像进行空间上的对准。首先把模板T(M×N)放在被搜索图像S(W×H)上,随后平移,令与T进行匹配的子图像为Sxy(x和y为子图像像素点在图像上的坐标),将T与Sxy进行相似度匹配,计算两者差的平方D(x,y),即:

(29)
将D(x,y)展开,得:
(30)
等号右边第1项为Sij的能量,第2项为T与Sij的相关程度,第3项为T的能量,两者的相关程度用R(x,y)表示,即:

(31)
R(x,y)也称匹配度量函数,范围为[0,1]。R(x,y) 越大,则表明模板与子图像之间的相关度越高,若R(x,y)=1,则表明T与Sxy完全一致。
传统的图像匹配算法存在计算量过大、匹配速度慢等缺点,针对此,本文中提出了SSDA算法。该算法在原有匹配方法的基础上由用户自行设定一个阈值,若当前位置匹配得到的相关程度小于阈值,则直接停止此次运算转而进行下一次匹配过程,由此在一定程度上提高匹配速度。令D(n)为T与Sxy差的绝对值,即:
(32)

由于图像匹配的主要过程是找到匹配的最佳位置,所以最优解可以由坐标来体现。使用遗传算法来寻找最佳位置就是采用二进制编码方式得到对应坐标的二进制编码,即子图像Sij中的i和j的二进制编码,随后将该编码作为初始个体,开始遗传算法寻优过程。二进制编码的过程如前文所述。
图像匹配中用来与子图像匹配的子模板的划分为:
T(x,y)=T1(x1,y1)∪T2(x2,y2)∪…
∪TN(xN,yN)
(33)
式中,Ti(xi,yi)(i=1,2,…,N)是用来与子图像匹配的子模板,本文中匹配度量函数R(x,y)是每一次匹配中得到的匹配度量函数Ri(x,y)(i=1,2…,N)的加权和。在本文中,遗传算法的适应度函数f(x,y)表述如下:

(34)
式中ci是相应的权系数。
本文首先把图像均分成14×8=112个区域,每一个区域对应一个个体,对个体坐标进行二进制编码,随机得到区域内的2个初始图像个体。计算每个个体的匹配度量函数,选择适应度最高的30个个体作为初始群体,随后进行交叉和突变等一系列的遗传操作,最终得到最优的匹配位置,然后与测试集中的图像进行匹配,返回相似度最高的20幅图片给用户,并求出对应的查全率和查准率,以此来反映图像检索系统性能的优劣。
4.3 检索结果
本文方法通过和SSDA、GA-SSDA进行对比,将检索结果以图的方式展示。本次检索共返回10张图片,第一张为待检索图片,SSDA检索结果见图4。GA-SSDA的检索结果见图5。
通过对比这2种检索方法的结果可知:GA-SSDA的效果优于SSDA。
本文中使用查全率和查准率来评价检索系统性能的优劣。查全率是检索得到的相关图像数与相关图像的总数的比值,而查准率是检索得到的相关图像数与总的检索图像数的比值。一般而言,查全率相同的情况下,查准率的高低反映了检索系统性能的优劣,两者呈正比关系。

图5 GA-SSDA检索结果展示
图6是对本文检索系统的展示,其中左上角是需要被检索的情感语义为妩媚的花朵图片,右侧的结果区返回20幅与它相似度最高的图片,该检索方法使用SSDA。
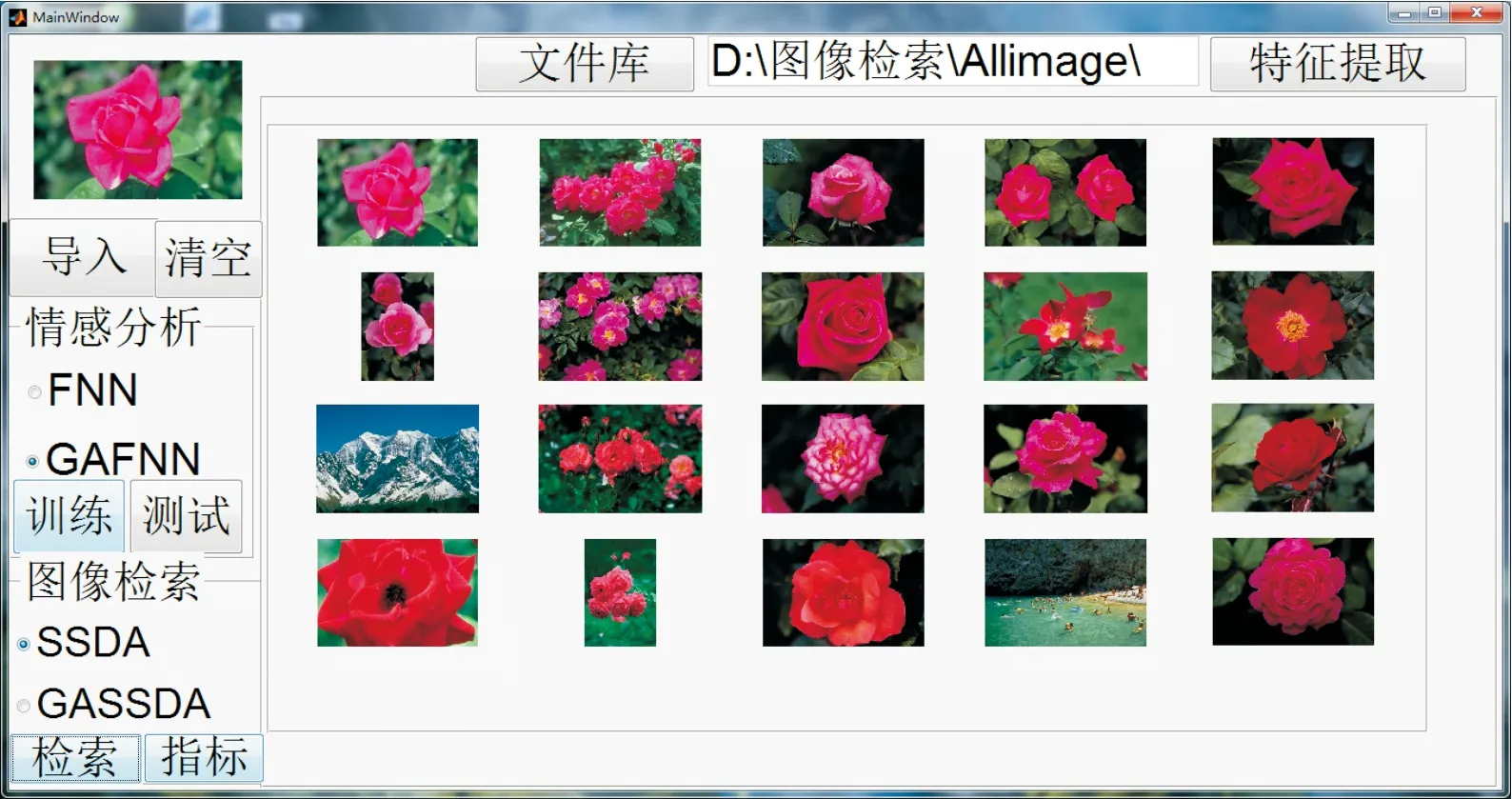
图6 检索系统
为了比较不同检索方法得到的不同效果,比较使用哪种方法得到的检索效率更高,图7、8分别列出了使用SSDA和GA-SSDA检索相同图片时对应的查全率-查准率曲线。

图7 SSDA查全率-查准率

图8 GA-SSDA查全率-查准率
对比图7、8的结果可知:GA-SSDA的检索结果优于SSDA,对应的查全率-查准率的整体准确效率优于SSDA。
5 结束语
图像情感语义的语义鸿沟是一个研究难点。在目前的图像检索中,并没有一种方法能完全从图像中提取所有可以激起人类感情变化的对象,而且对于图像情感语义目前仍然没有统一的和更加权威的方法。本文实现的图像颜色和形状等底层特征到高层情感语义的映射存在很多的不足,例如,当训练样本很大时计算量会变得很大;GA寻求局部最优解的能力比较低,大部分时候都不会在全局最优解中收敛,一般只能达到全局次优解等。这些都是今后研究中需要不断改进和学习的地方。另外,在图像的检索过程中需要寻找更好的方法,使图像的查全率-查准率准确度更高。
[1] 刘烨,陶霖密,傅小兰.基于情绪图片的PAD情感状态模型分析[J].中国图象图形学报,2009,14(5):753-758.
[2] 汪卫星,李峰,殷苌茗.一种新型的基于神经网络的图像检索算法[J].微计算机信息,2010,21(26):228-230.
[3] 于琴.基于Water-Filling的医学图像检索技术的应用研究[D].北京:中国石油大学,2010.
[4] 胡帆.基于轮廓的物体识别算法研究[D].北京:华北电力大学,2012.
[5] 王华秋,王斌.优化的邻近支持向量机在图像检索中的应用[J].重庆理工大学学报(自然科学),2014,28(9):66-71.
[6] 张万亮,许晨,张丁等.基于T-S模糊神经网络的边坡稳定性分析[J].露天采矿技术,2013(4):20-22.
[7] JIAO Y,XU G.Optimizing the lattice design of a diffraction-limited storage ring with a rational combination of particle swarm and genetic algorithms [J].Chinese Physica C,2017(2):166-176.
[8] KABIR M M J,XU S,KANG B H,et al.A New Multiple Seeds Based Genetic Algorithm for Discovering a Set of Interesting Boolean Association Rules[J].Expert Systems with Applications,2017,74:55-69.
[9] SHEN G,ZHANG Y.Power Consumption Constrained Task Scheduling Using Enhanced Genetic Algorithms[M]//Germany:Spring Berlin Heidelberg Publisher,2013,139-159.
[10] 胡文斌,韩璞,孙明.二进制编码遗传算法中的控制参数选取方法[J].计算机仿真,2015,32(3):447-450.
(责任编辑杨黎丽)
ImageEmotionalSemanticClassificationandRetrievalResearch
WANG Huaqiu, HU Lisong
(College of Computer Science and Engineering, Chongqing University of Technology, Chongqing 400054, China)
It is the main subject of the images retrieves to improve the accuracy of emotional semantic mapping and retrieval. In the model of emotional semantic mapping, the shape seventh moment and color moment of images are input into the fuzzy neural networks, and the weights and thresholds of networks are encoded into binary format, which are the chromosomal strings of genetic algorithm. Genetic algorithm is used to find the optimal individual coding that makes the efficiency of emotional semantic mapping reach the highest. In the retrieval model, genetic algorithm is used to optimize the image matching algorithm. The sub template coordinates which are most suitable for direct matching can found by the way. The model greatly improves the efficiency of image matching compared to the traditional sequential similarity detection algorithm. Through the comparison of recall ratio and precision ratio, the emotional mapping and image retrieval model optimized by genetic algorithm have obviously improved performance.
emotional semantics classification; image retrieval; genetic algorithm; fuzzy neural network; color moment; shape seventh moment
2017-06-28
国家社会科学基金一般项目“数字图书馆智能图像检索系统研制”(14BTQ053)
王华秋(1975—),男,博士,教授,主要从事图像检索、数据挖掘、智能控制方面的研究,E-mail: wanghuaqiu@163.com; 胡立松(1990—),男, 硕士研究生,主要从事图像检索研究。
王华秋,胡立松.图像情感语义分类及检索研究[J].重庆理工大学学报(自然科学),2017(10):180-186.
formatWANG Huaqiu, HU Lisong.Image Emotional Semantic Classification and Retrieval Research[J].Journal of Chongqing University of Technology(Natural Science),2017(10):180-186.
10.3969/j.issn.1674-8425(z).2017.10.029
TP18
A
1674-8425(2017)10-0180-07
猜你喜欢
测控技术(2018年10期)2018-11-25
现代电子技术(2018年20期)2018-10-24
现代电子技术(2018年16期)2018-08-21
现代情报(2018年11期)2018-01-07
现代电子技术(2017年23期)2017-12-20
计算机测量与控制(2017年6期)2017-07-01
计算机应用(2016年10期)2017-05-12
西安建筑科技大学学报(自然科学版)(2014年5期)2014-11-10
航天器工程(2014年4期)2014-03-11
中国管理信息化(2009年10期)2009-06-19
