
基于聚类分析的电子商务客户忠诚度研究
2017-11-17 07:22广东省经济贸易职业技术学校杨雄钢
电子世界 2017年21期
广东省经济贸易职业技术学校 杨雄钢
基于聚类分析的电子商务客户忠诚度研究
广东省经济贸易职业技术学校 杨雄钢
全面分析电子商务顾客忠诚度的影响因素,立足于经典RFM客户忠诚度模型,将RFMSA电子商务客户忠诚度划分模型有效地建立起来,借助聚类分析算法划分顾客忠诚度,立足于经典聚类分析法K-means,将分段确定初始聚类中心的改进算法提出,以此来划分顾客的忠诚度.借助分析经典样本数据,从实验结果可以看成,通过对粗糙集K-means聚类算法进行改进后,可以将聚类的准确率有效提高.
聚类分析;电子商务;客户忠诚度
在电子商务环境下,企业可以对互联网进行利用将产品和服务提供给客户.企业不认识顾客,顾客也不认识企业,没有当面交流过一句,所有客户关系都通过网络来进行维持.能够让消费者更好的进行对比、选择以及提供各方面综合程度较高的商品和企业即为互联网的优点,对互联网进行利用,让消费者更好的对信息进行搜索,这样就可以利用相关企业在网上开设的商城,将商品的价格等相关信息获取到,并且还可以和企业服务商进行对比,不仅可以在价格上进行比较,同时还可以在服务商进行比较,通过以上所讲到的对比,消费者就会选择和自己消费意象更相符的产品或商家,因此在电子商务中,客户忠诚度基本较低,最终流失掉本有的客户.怎样才能将客户的忠诚度提高是现阶段电子商务迫切需要解决的问题.
一、电子商务客户忠诚度模型研究
(一)RFM模型
在电子商务行业中,RFM模型是对客户忠诚度进行分析时用得最多的一种模型,客户真实的交易数据即为RFM数据,因此,数据具有较强的准确性,客户的个人隐私通常不会涵盖在内,获取较为容易.RFM模型在客户忠诚度研究中得到了广泛的运用,其以客户的消费金额、购买频率、购买时间间隔为基础.
(二)RFMSA 模型
作为电子上我中对客户行为的重要指标,RFMSA 模型将交易金额、交易频率、交易时间、关注度、商品评价包括在内.在RFMSA 模型中,每一个属性维度的重要程度都具有一定的差异性,也就是五个属性维度的权重不同.五种指标所影响用户忠诚度的程度不一样,以综合反映客户忠诚度的指标CLV客户终生价值指标为基础,来定义RFMSA 模型,如式(1)所示:

其中i表示客户中的第i个客户,CLVi表示此客户的忠诚度指标,Ri、Fi、Mi、Si、Ai分别表示此客户RFMSA 指标的ωR、ωF、ωM、ωS、ωA分别表示五个指标的权重系数[1].在所有指标当中,CLV与购买时间成反比,而在另外四项指标方面都成正比.在将 RFMSA模型确立之后,应预先处理数据,将其转换成系统需要的 RFMSA数据并加以规范,然后在分析数据,在对数据进行分析的过程当中,系统主要是通过采取聚类分析的方式,来实现数据集的分类.
二、以模糊集聚类算法为基础的电子商务客户忠诚度算法
(一)模糊K-means算法
微课可以使模糊聚类更好地实现,以下设计和分析了模糊K-means算法,其具体描述如下所示:假设数据集集合为,数据集的簇数量为K个,第i个簇的中心即为mi,i=1,2,...k0uj(xi)表示K-means算法聚类过程中第x个样本对第j类的隶属度,模糊K-means算法的目标函数可以对以下式子予以使用来描述.
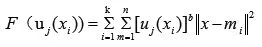
其中,b使一个可以对模糊聚类结果予以控制的模糊度常数,通过模糊K-means均值隶属度函数求导数,就可以将K-means算法的最佳解放得到,如以式(2)、(3)所示:

在对K- means算法予以执行时,能够通过对上述两个方程式予以实际的执行,来得到一各具体的模糊K- means算法,这样就能够将其应用到实际数据划分当中[2].给予模糊思想下的K- means算法,在对其进行具体描述时分为以下几点:第一,对随机初始法予以采用,以此作为数据集设定K个簇,并将各个簇的中心设定为mi;第二,对客户的购买记录数据集中所有的数据对象的隶属函数进行计算,计算方式为(3);第三,将第二个步骤当中的隶属函数作为基础,来对所有簇的中心值mi予以计算,能够通过算式(2)来进行;第四,遍历数据集中所有数据对象,当隶属度不再改变时,算法结束,不然就返回到步骤二.
(二)具体运用
本文所采用的系统实验工具为Matlab2009程序处理平台,而第五代智能英特尔酷睿i7处理器是本次实验采用的服务器,i7一SSOOU为CPU的型号,主频为2. 40GHz,4G内存,W in8是其操作系统,在分析算法、实现算法、运行数据的准确性和有效性中得到了较好的运用.
实验数据对中科院模式予以采用,对国家重点实验室采集的SUNING、JD、TMALL等三个购物网站的用户消费数据进行识别,使用BOW工作预处理数据集,所有的数据集中都将3万条电子商务浏览记录包括在其中,可以将其分为高、中、低三个客户忠诚度的类别,黄金消费群体即为高忠诚度的客户,其具有较高的交易频率,每个月的消费金额较多,浏览了很多的商品,具有极高的潜在消费价值,其黏性较高;普通消费群体即是中忠诚度的客户,商品流量的数量一般,不能确定出潜在消费价值和黏性;低忠诚度客户也就是低值客户,用户对网站进行访问的时间具有较长的间隔,交易很少能够成功完成,消费额度极少.上述三个类别都其记录都有1万条.
为了能够对改进的K- means算法的有效性进行评估,本文对召回率评估算法聚类的精确程度进行使用,其定义如式(4)所示.

其中,T和C分别表示的是改进的K-means的算法执行结果的簇标号、实际客户属于的忠诚度类型的数目,A1(c,T )和A2(c,T )分别表示浏览记录分到其归宿的忠诚度类别T中的数目、浏览记录C被错误地划分到非归属忠诚度类别T中的数量.
通过以上三种算法运行在TMALL数据集上的结论可以看此,改进的K-means可以对软化分的思想予以采用,可以以客户需求为基础,将数据准确的分为高、中、低三个忠诚度类群中[3].对于改进的k-means算法,相较于用户兴趣度模型,在高忠诚度准确度上提高了16%,相较于RFM模型,在中忠诚度准确度上和低忠诚度模型上分别提高了21.8%、25.7%,使电子商务网站忠诚度划分准确度得到了有效提高,对弈档次不同的数据,可以采用不一样的营销方法,对客户群体的消费能力进行维护.在JD数据集上,在中忠诚度上RFM模型所划分的结果只有32.4%,低于在其它数据集上的划分,极大的改变了数据划分准确度;在高忠诚度上,用户兴趣度模型的划分结果为43.4%,明显低于在其它数据集上的划分结果,也改变了数据划分准确度.而在k-means模型进行了改进后,在山中数据集上的划分结果没有较大的差异,比较稳定,由此可知,在不同的数据集上,改进的k-means模型鲁棒性较高,能够对用户忠诚度进行有效获取.在SUNING数据集上,RFM模型执行时间为86ms,用户兴趣度模型执行时间为87ms,通过改良折后K-means算法需要的执行之间为63ms,因此能够让用户忠诚度在划分时间方面的效率得到较大的提升,能够在很短的时间内得到准确的计算结果,进而使得电子商务网站在运行与推荐效率方面得到有效地提升,具体忠诚度模型见表1.

表1 SUNING数据忠诚度模型执行时间
三、结语
大力发展的网络技术,在各个领域得到了广泛的应用,在此背景下,电子商务得到了极大的发展.电子商务网站要想在竞争激励的市场中占据优势,就必须立足于先进的数据挖掘及时,和客户保持良好的关系.本文为了达到将电子商务客户忠诚度模型的准确性提高的目的,将模糊数学理论引入到了传统的k-means算法中,使改进的k-means算法被提了出来,据实验结果表明,这种算法可以将客户忠诚度挖掘准确度提高,相较于用户兴趣度模型以及RFM模型,本文算法的鲁棒性更好,应用的价值较高.
[1]牛咏梅.基于粗糙集的海量数据挖掘算法研究[J].现代电子技术,2016,39(7):115-119.
[2]王林彬,黎建辉,沈志宏.基于NoSQL的RBF数据存储与查询技术综述[J].计算机应用研究,2015,32(2):1281-1286.
[3]谢丽.基于聚类分析的机场客户细分服务系统的设计与实现[D].西安电子科技大学硕士论文,2014:15-17.
猜你喜欢
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
建筑科技(2018年6期)2018-08-30
电子测试(2017年15期)2017-12-18
数学物理学报(2017年5期)2017-11-23
雷达学报(2017年6期)2017-03-26
中国交通信息化(2016年5期)2016-06-06
电测与仪表(2016年18期)2016-04-11
电子设计工程(2015年6期)2015-02-27
天津冶金(2014年4期)2014-02-28
