
基于深度学习变分自动编码器算法的电价执行稽查研究
2018-02-22 02:46高曦莹杨飞龙曹世龙王英新
东北电力技术 2018年11期
高曦莹,关 艳,杨飞龙,曹世龙,王英新
(1.国网辽宁省电力有限公司电力科学研究院,辽宁 沈阳 110006;2.国网沈阳供电公司,辽宁 沈阳 110004)
电费收入是供电企业的主要收入来源,是保证国家电力行业持续健康发展的基础和保证。然而,由于诚信体系的缺失,个别用电企业存在违约用电,供电企业内部个别员工存在徇私舞弊现象,致使供电企业蒙受较大的经济损失。因此,研究科学有效的电价执行稽查方法成为一项不断更新的研究课题[1]。
随着科技的发展,供电企业信息化程度不断提高,国家电网公司建立了“客户导向型,机构扁平型,业务集约化,管理专业化,管控实时化,服务协同化”一型五化电力营销体系。大量电力营销系统信息使得采用智能数据分析方法进行数据挖掘成为可能,并随着智能方法的更新发挥出越来越大的作用。其中,电价执行稽查方法也在不断更新,现有的方法有3种:一是采用人工检查定期巡检,该方法效率低、工作量大,正在逐渐淘汰;二是通过普通网络稽查监控系统,设立用电量门限阈值筛选,该方法只能对门限阈值超量的电价执行异常进行筛选,原理简单但准确率较低;三是通过聚类等传统机器学习方法进行系统筛选,但该方法只能凭借用电轨迹对电价执行异常进行辨别[2],情况单一,无法处理异构数据,在用户数据局部缺失的情况下无法进行有效分析计算[3]。
针对上述方法局限性,本文提出一种基于深度学习变分自动编码器算法(variational autoencoder based anomaly detection algorithm,VABAD)解决在电价执行稽查过程出现的问题。该方法中采用的变分自动编码技术既是判别性模型又是生成性模型,既可以用来检测异常数据又可以通过特征概率来恢复数据。其最大的优势是该技术通过重构概率来判定异常数据而不是重构数据本身,使得多种异常数据可加入判别,极大丰富了判定依据,可有效处理多种电价执行稽查。该方法分为3部分:一是用电数据获得并进行分类;二是用电数据提取概率特征,为每一个样本构造专属正态分布,然后采样重构,并训练编码器及解码器;三是利用重构概率(蒙特卡洛估计值)实现异常客户判别,实现电价执行稽查。该方法的总体框图见图1,利用该方法在东北某省电网进行电价执行稽查,结果表明,该方法有效提高了稽查准确性,大幅降低了稽查不匹配率,极大减轻了供电企业工作量,具有较好的实用性和可行性。
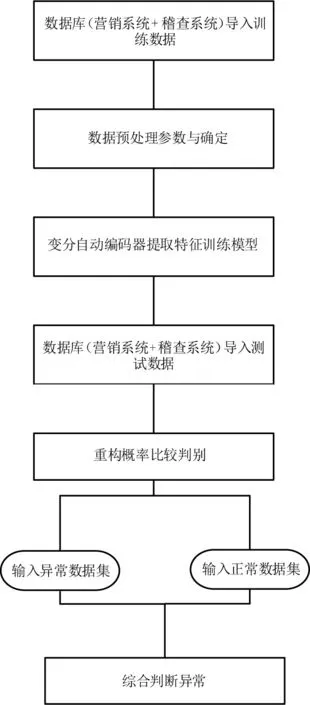
图1 电价稽查执行方法总体框图
1 用电数据获取
1.1 获取数据
数据取自供电企业市场营销及营销稽查监控业务数据库,数据类型及对应数值化举例如下。
异常种类:包括售电均价波动、特殊电价执行异常、超容量用电、居民大电量、农排大电量、化肥大电量、力率执行异常、变损电量异常、两部制电价执行异常、分时电价执行异常等,对应数值种类从1到N。
客户用电一般属性:包括电压、电流、变压器容量、平均功率因数、平均负载率、超容率、总电费、基本电费、峰时电费、平时电费、谷时电费等,数值按归一化处理以便于计算。
客户用电高级属性:包括用电同比、环比、偏差率、峰总比、平总比、谷总比、峰谷比等,数值大部分为比值,直接代入矩阵。
客户数据属性:包含用户类别、所属行业、所属位置、抄表号段、售电均价、上月售电均价、上年同期售电均价、售电环比同比、景气指数等,数值分类数值化。
1.2 简单分类
将系统中采集的数据按照正常数据集和异常数据集分类导入算法模型,异常数据集样本数量较少,但足以对模型进行半监督学习训练。将样本中的文字信息转化为数字信息,并将包含4类数据类型的数据形成正常数据集X、异常数据集x。
式中:M、N、m、n代表维度。
2 用电数据提取概率特征
判别模型通过变分自动编码器模型得以实现。变分自动编码器主要由编码器、解码器、额外损失3部分构成。其原理图见图2。
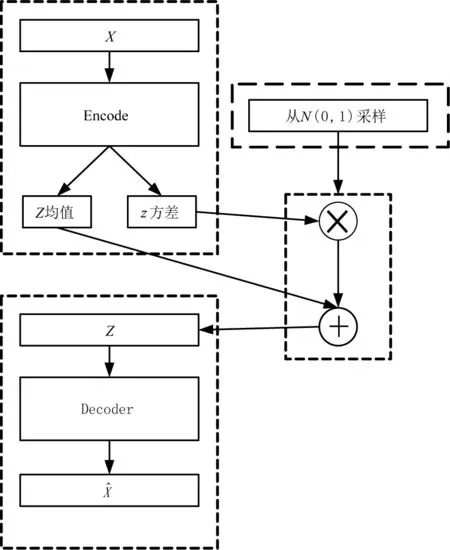
图2 变分自动编码器原理图
每一个样本数据在编码器中通过均值和方差分布降维生成隐藏变量z,通过解码器还原样本(升维);通过KL散度衡量额外损失L;通过重建概率可有效判别电价执行异常客户。具体步骤如下。
确定网络结构,总共具有q+2层,输入层和输出层各占1层,q为隐藏层的层数。
导入正常数据集X,确定到模型的超参数,训练有向图模型参数θ、φ[4]。
初始化编码器网络,网络作用是将数据集中的样本数据映射到隐藏分布参数z中,输入过程是将非线性激活函数的密度集(Dense函数)进行连接并向前发送,然后将输入数据转换成隐藏空间的2个变量,使用密度集连接隐藏变量z的均值μz(i)和z的logσ2使用σz(i)表示输入。使用异常数据集数据通过神经网络均值μz(i)和方差σz(i)计算模块反向传播训练编码器fθ(z|x(i))。 表达式为μz(i),σz(i)=fθ(z|x(i))。
解码器将z作为输入量,并将参数输出到数据概率分布中,使用μz(i)和σz(i)作为采样数值正态分布的均值和方差,通过定义采样函数从隐藏正态分布中随机采样概率近似点。
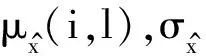
logpθ(x(i))≥L(θ,φ,x(i))=DKL(qφ(z|x(i))||pθ(z))+Eqφ(z|x(i))[logpθ(x|z)]
式中:logpθ(x(i))为数据集点的边缘似然值;qφ(z|x(i))为潜变量z的近似后验值;pθ(z)为潜变量z的先验分布值;KL为散度,计算独立分量X正态分布与标准正态分布KL散度作为L值。具体实现程序流程见图3。
3 重构概率判别
基于大数据深度学习的电价稽查执行方法,数据获取出自Hadoop分布式架构硬件服务器系统,通过营销系统SQL语言提取数据库数据。
本方法是一种基于大数据深度学习的电价稽查执行方法,通过变分自动编码器算法,由于判断因子是概率分布,不受不同指标之间权重关系的影响可有效处理电价执行异常的多种情况,有效区分电力用户。
4 实例分析
4.1 数据获取

图3 变分自动编码器流程图
数据取自某省供电公司营销系统及稽查系统近年中某一年的具体数据。针对超容量用电电价执行异常、居民大电量电价执行异常、两部制电价执行异常3种情况进行测试,针对性提取工业及居民用电数据。由于电价执行稽查异常客户数量在正常无标签样本中占比较低,为了加快试验速度,测试和训练数据提高了异常数据占比,对算法的计算效果无影响。
4.2 测试结果
结算结果根据超容量用电电价执行异常、居民大电量电价执行异常、两部制电价执行异常3种情况列于表1、表2、表3中。
4.3 结果分析
由于电价执行稽查采用人工方法与聚类方法已有文献进行过对比[4-5],本文测试部分重点对比变分自动编码器与聚类(k-mean)方法的对比[6]。
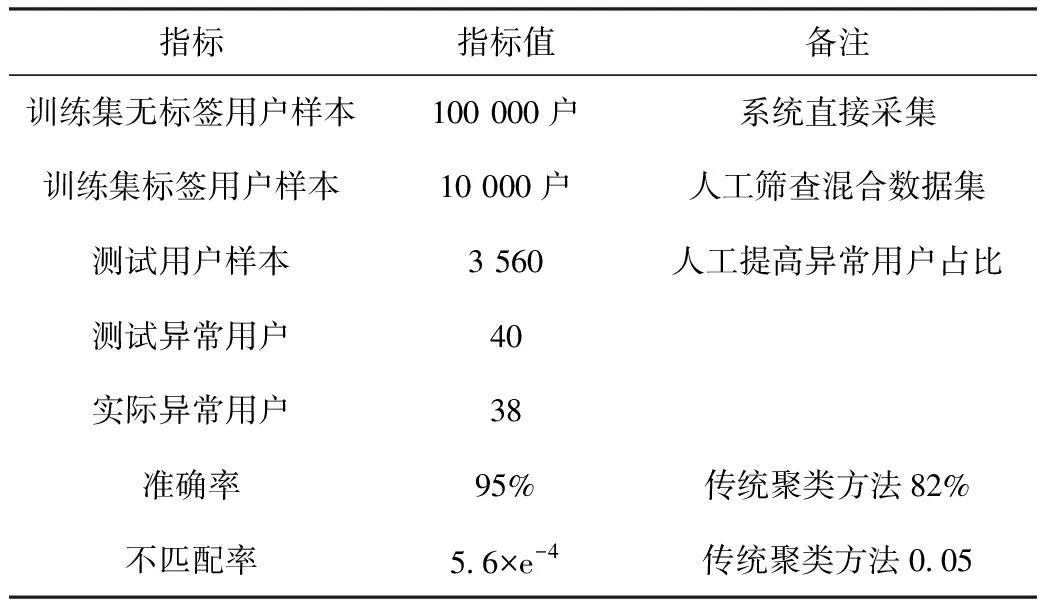
表1 超容量用电电价执行异常
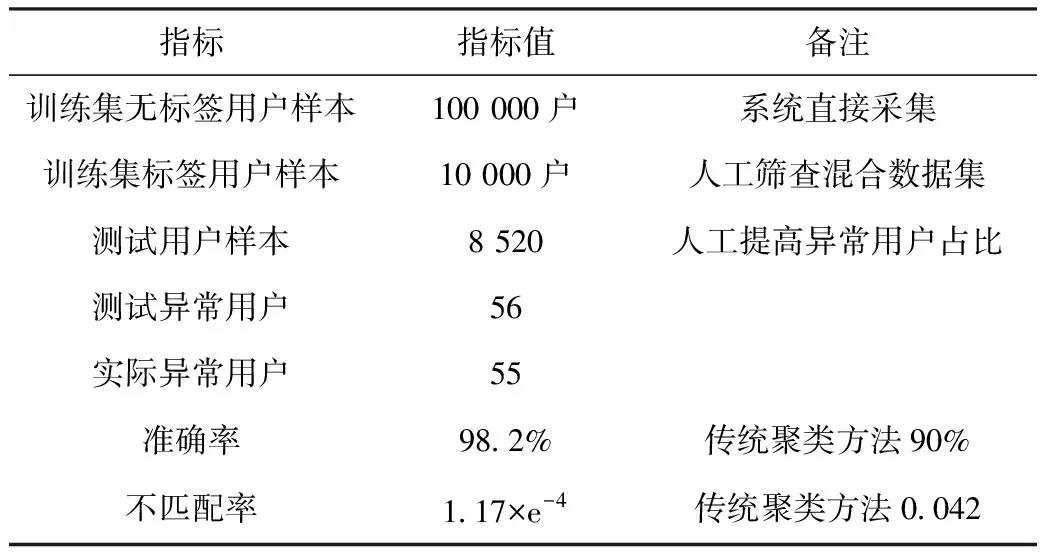
表2 居民大电量电价执行异常

表3 两部制电价执行异常
注:传统聚类方法为采用k-mean法对测试数据的判定效果。只采用用电量特征曲线;稽查准确率=(诊断结果中异常的用户数/实际异常的用户数)×100%;稽查不匹配率=(误判异常用户数量/测试用户样本)×100%。
由试验结果可见:变分自动编码器方法在准确率上较聚类方法有大幅提高;在不匹配率上变分自动编码器方法更是大幅低于聚类方法;无论准确性和不匹配性,大量的数据样本是获得良好性能的基础和保证,由表3可见,在训练样本数量下降的同时,准确率下降,不匹配率上升。
5 结束语
针对目前电价执行稽查工作方法的局限性,提出了一种基于深度学习变分自动编码器的新方法。该方法突出的优点是可以分析异常数据,不拘泥于电量等常规判据,通过概率方法有效加入多种参数而无需考虑参数权重[7-8]。通过试验证明,该方法可有效提高电价执行稽查的准确率,有效降低不匹配率,大量减少供电企业工作量,提高供电企业收入,为电力营销工作提供有效的保障。
猜你喜欢
湖南税务高等专科学校学报(2021年3期)2021-07-21
数学杂志(2020年3期)2020-07-25
数学物理学报(2019年6期)2020-01-13
中国交通信息化(2019年8期)2019-11-04
中国交通信息化(2019年7期)2019-10-08
能源(2018年10期)2018-12-08
商周刊(2018年16期)2018-08-14
数学物理学报(2017年6期)2018-01-22
数学物理学报(2016年3期)2016-12-01
中国环境监察(2016年12期)2016-10-24
