
基于聚类标签均值的半监督支持向量机*
2018-02-26 10:13汪西莉
计算机工程与科学 2018年12期
田 勋,汪西莉
(陕西师范大学计算机科学学院,陕西西安710062)
1 引言
图像分类在社会生产与日常生活中变得日益重要,无论是国防安全、医疗检测、遥感分析还是交通监控等领域,都离不开图像分类。目前图像分类已经成为机器学习与模式识别的研究热点之一。传统的机器学习分为监督学习与无监督学习,而半监督学习 SSL(Semi-Supervised Learning)[1]是监督学习与无监督学习相结合的一种学习方法,它兼顾了监督学习与无监督学习的优点,往往在少量标记样本与大量无标记样本的情况下进行训练和分类,并且得到比较好的分类结果。对于图像分类,大量标记样本会耗费大量人力与时间,是不实际的,但图像的无标记样本却相对容易获取,所以半监督学习广泛运用于图像分类当中。
半监督分类是指利用大量无标记样本信息来帮助训练,调整使用少量类别标签信息训练得到的分类器,使分类的准确度提高。一般假设样本xi∈Rm(i=1,2,3,…,n) ,其中m是样本的维数,n是样本的个数,yi为其类别标记,L={(x1,y1),(x2,y2),…,(xl,yl)} 表示 l个有类别标签信息的样本,U={xl+1,xl+2,…,xl+u} 表示 u 个无标记样本。通过大量无标记样本提供的分布信息有效弥补了少量有类别标签信息的不足,使分类器的训练更加充分。半监督分类有四个不同的分支:基于生成式模型算法、基于差异的半监督分类算法、基于判别式的半监督分类算法、基于图的半监督分类算法。本文主要研究基于判别式的半监督分类算法。
基于判别式的半监督学习算法也被称作基于低密度划分的半监督学习算法,同时使用类别标签信息与无标记样本信息训练分类器,使分类面在仅通过低密度样本区域的情况下,样本到分类面的距离间隔最大,如图1所示。典型的基于判别式的半监督学习算法就是半监督支持向量机S3VM(Semi-Supervised Support Vector Machine)[2]。

1998年,Bennett等人提出了最初的半监督支持向量机(S3VM),在传统的支持向量机 SVM(Support Vector Machine)基础上,对无标记样本引入松弛项,表示对于无标记样本错分的惩罚。同年,Vapnik和Sterin提出了直推式支持向量机TSVM(Transductive SVM),TSVM利用线性预测函数f(x)=wTx+b作为整个样本空间上的分类边界,其目标函数为:
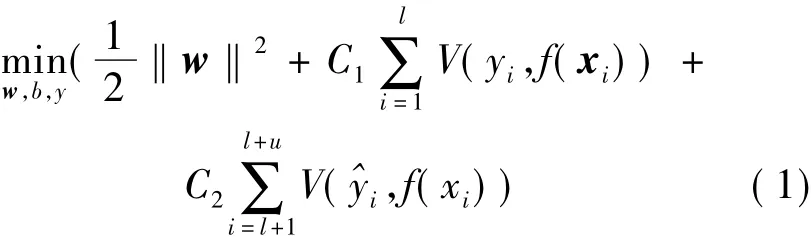
其中,w∈Rm,‖w‖是支持向量到分类超平面的距离,V(yi,f(xi))是损失函数,l和u分别为有类别标签信息样本和无标记样本的数量,C1与C2是有类别标签信息样本和无标记样本损失权值,用于调整有类别标签信息样本和无标记样本在目标函数中的重要性。随后科研人员不断提出新的半监督支持向量机:拉普拉斯支持向量机(LapSVM)[3-5]、基于高斯混合模型核的半监督支持向量机、基于谱聚类核的半监督支持向量机、基于随机游走核的半监督支持向量机。
式(1)是非凸的,很难直接求解全局最优解,一般情况下使用半定规划SDP(Semi-Definite Programming)、梯度下降(Gradient Descent)、连续优化CT(Continuation Techniques)、分支界定BB(Branch and Bround)、确定性模拟退火算法DA(Deterministic Annealing)等方法来求解。
为了提升半监督支持向量机算法效率,Li等人[6]提出标签均值半监督支持向量机meanS3VM(mean Semi-Supervised Support Vector Machine)。对比传统的半监督支持向量机,meanS3VM算法并不直接使用每一个无标记样本的估计标签来训练分类器,而是使用无标记样本估计标签均值来训练分类器。对比半监督SVM方法,meanS3VM算法仅仅使用样本估计标签均值训练分类器,减少了训练分类器的约束条件,减少算法运行时间。
meanS3VM算法最初用于数据集分类,针对图像的光谱特征[7],将无标记样本预分为两类,使用无标记样本的标签均值来训练分类器,对复杂图像,类内光谱信息差异较大,两类的标签均值难以反映各类光谱信息的实际情况,而且对分类器的训练除了标记样本提供的信息外,只增加了无标记样本的标签均值信息,对训练分类器提供的信息较少。并且meanS3VM算法是随机选取无标记样本的,所以无标记样本的标签均值会有很大的随机性,影响算法的稳定性。因此,本文提出聚类标签均值,针对图像分类既提高分类精度,又提高分类器的稳定性。
本文提出基于聚类标签均值的半监督支持向量机算法,与传统的半监督支持向量机相比有很大优势,比如S3VM算法对应的是混合整数规划问题,通常难以计算。TSVM虽然将规划问题转化成迭代求解,但是需要的迭代次数很多,算法运行时间较长。而LapSVM则需要计算一个n×n(n是标记样本与无标记样本数量之和)矩阵的逆,当n的值过大时,会造成内存溢出。本文算法有利于表达图像多样的光谱特征,针对图像,利用光谱特征分类,将无标记样本聚类成多类,利用多类的标签均值和有标记样本训练分类器,一方面提供更多类别信息,一方面和meanS3VM一样加快训练速度,减小了求解难度。与meanS3VM相比,将标签均值间隔最大化约束条件改为聚类后多类的标签均值间隔最大化约束条件,是本文的创新点,在实验中验证了这种改进明显提高了分类的正确率,而且聚类后多类的标签均值比meanS3VM两类标签均值随机性小,提高了算法的稳定性。
2 标签均值半监督支持向量机
半监督支持向量机结合了监督学习和无监督学习的优点,使用有少量标记样本和大量无标记样本设计分类器。在半监督支持向量机的训练过程中,给定的训练样本为一组有标签训练样本集:L={(x1,y1),…,(xl,yl)},xi∈ Rd,yi∈ {+1,-1},和另一组无标记样本集:U={xl+1,xl+2,…,xl+u},其中l和u分别为标记和未标记样本数。半监督支持向量机可以定义为形如式(2)的优化问题:
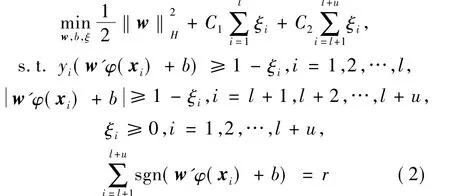
其中,H 是再生核希尔伯特空间[8]; ξ={ξ1,ξ2,…,ξl+u},{ξ1,ξ2,…,ξl} 是标记样本的松弛变量,{ξl+1,ξl+2,…,ξl+u} 是无标记样本的松弛变量;参数C1需要人为设置,如果选择较小的值,表示对标记样本错分比较容忍而更强调对正确分类的样本的样本间隔,相反,C1取较大值,则更强调对错分的惩罚;yi(w'φ(xi)+b) ≥1 - ξi,i=1,2,…,l是标记样本的约束条件;l+1,l+2,…,l+μ是无标记样本的约束条件;φ(xj)是将特征映射到高维空间的非线性映射函数;参数C2与参数C1类似,C2的取值较小表示对无标记样本错分比较容忍而更强调对正确分类的样本的样本间隔,相反则更强调对错分的惩罚;最后一个约束条件是平衡约束条件,防止所有的无标记样本分为一类;r表示无标记样本中正类个数比负类个数多多少,根据具体情况设定r的值。
标签均值半监督支持向量机算法简称为meanS3VM算法,与传统半监督支持向量机(如式(2)所示)相比,它改变了无标记样本惩罚项,以无标记样本的估计标签均值之间的间隔ρ最大化为目标,使用了标签均值这一个简单的统计量来训练分类器,数学表达如式(3)所示:

3 基于聚类标签均值的半监督支持向量机
标签均值支持向量机最初被设计用于普通数据集分类,若用于图像分类,存在分类正确率较低的问题。图像分类需要考虑图像的光谱特征,但meanS3VM算法只将无标记样本预分为两类,计算两类的预估标签均值,以预估标签均值间隔ρ最大化为目标训练分类器。对于大量无标记样本,meanS3VM算法只使用了均值信息。而且传统无标记样本的选取都是随机的,无标记样本标签均值的随机性比较大,显然会影响算法的稳定性。本文算法以如何增加有意义的标签均值约束条件,并提高算法的稳定性为出发点,提出一种改进的标签均值支持向量机算法。该方法首先对所有无标记样本进行聚类,假设聚类数为k,在每个类别中分别求取预估标签均值,利用一个基于间隔的框架使每类的预估标签均值之间的间隔最大化,使分类面到各个聚类中心的预估标签均值间隔尽可能大,达到适应多类图像分类任务,并提高分类精度和结果稳定性的目的。这时问题定义为:
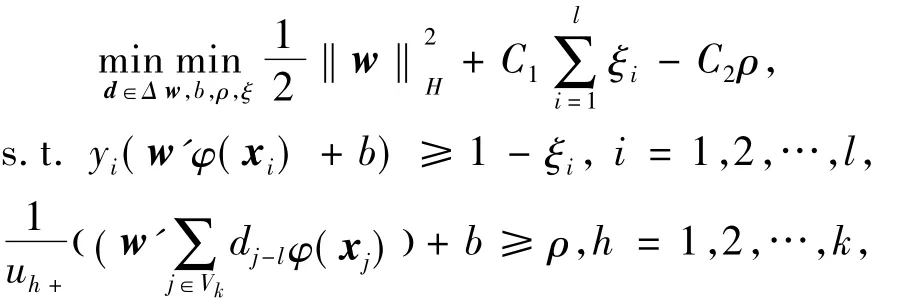

其中,V= [V1,V2,…,Vk]是无标记样本聚类的结果。uh+与uh-分别为聚类后第h类中正类个数和负类个数。对该问题本文采用交替迭代方法求解,首先原最优化问题可以转化成如下的对偶问题[9]:


针对式(5),如果固定了d的取值,α的求解就是一个标准的二次规划(Quadratic Programming)[10]问题。另一方面,如果固定 α的取值,使用KKT条件[11]可以求取w和b,并且式(5)被简化成式(6):
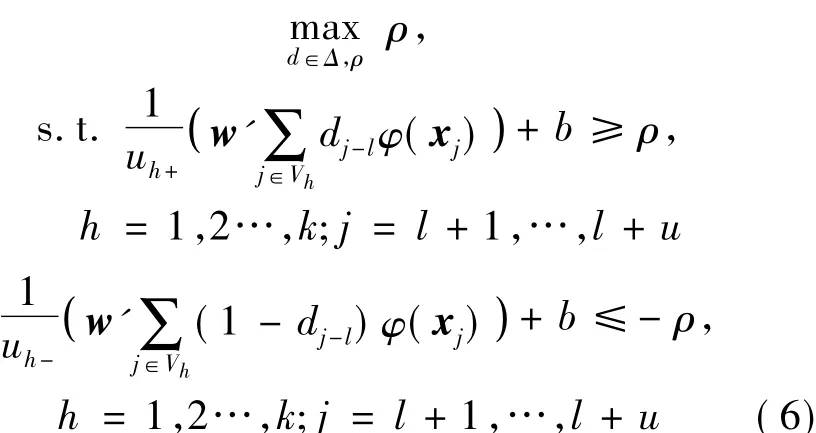
所以,本文算法是通过交替迭代方法求解,首先对无标记样本聚类;接着使用监督SVM进行预分类得到无标记样本的预分类标签d;固定d的取值,通过聚类结果与预分类标签d构建约束条件,求解式(5)得到乘子α的取值;接着固定α值求解式(6)得出参数w和b的取值,用w和b的值再估计新的无标记样本的标签d';如果d等于d'停止迭代,否则继续固定标记样本的标签d',通过聚类结果与预分类标签d'构建约束条件,求解式(5)依次迭代。
本文的算法流程如下:
Step 1首先对u个无标记样本进行K-means聚类,聚成k类。
Step 2使用SVM分类器对u个无标记样本预分类,得到预估标签d。
Step 3使用聚类信息与预估标签信息,求出聚类簇的标签均值,构建2k个约束条件。
Step 4使用二次规划求解式(5)优化问题,求得新的α值。通过KKT条件,求解w和b。
Step 5使用w和b估计u个无标记样本新的标签d'。如果d'=d,停止迭代,否则跳转Step3。
Step 6使用最终训练好的分类器对全图分类,算法结束。
通过算法流程可以得出本文算法的时间复杂度和空间复杂度,由于K-means算法的时间复杂度为O(n),空间复杂度为O(n),二次规划算法的时间复杂度为O(n2),空间复杂度为O(n2),又因为k<<n,本文提出的聚类标签均值半监督支持向量机的时间复杂度为:O(u)+O(n2) =O(n2),空间复杂度为:O(u)+O(n2)=O(n2),其中u是无标记样本的个数。
meanS3VM算法的参数有:针对标记样本的错分惩罚参数C1和针对无标记样本的错分惩罚参数C2。C1的大小决定了标记样本在训练分类器过程的重要性,C2的大小决定了无标记样本在训练分类器过程的重要性。还有高斯核函数k(x,y)=exp(-gamma*‖x-y‖2)的参数gamma。当gamma→0时,k(x,y)→1,只能得到一个近似于常函数的判决函数[12],对目标与背景稍微复杂的图像分类正确率较低。当gamma→∞ 时,k(x,y)→0,训练好的分类器推广能力较差,测试样本错分的情况比较普遍。参数ep是无标记样本正类数目的估计值,其值对分类器的分类正确率影响较大。本文改进算法中,需要对无标记样本聚类,聚类数k值减小,则每类样本数增多,聚类标签均值间隔约束条件减少。k值增大则相反,所以聚类数k的取值直接影响算法的性能。
4 实验结果及分析
为了研究本文算法是否增加了有意义的标签均值约束条件,并提高了算法的稳定性,实验对象选择目标与背景复杂度不同的图像,分别使用监督SVM和半监督meanS3VM以及本文算法进行分类,并对比分析分类结果。程序使用 Matlab R2011a编写,运行在内存为 4 GB,CPU为 Intel(R)Core(TM)i5-2400频率为3.10 GHz的机器上。实验用图都选自 Weizmann horse dataset[13],并且可以利用 Weizmann horse dataset给出的理想分类结果进行对比评价。本文采用图像分类中常用的像素分类正确率PCR(Pixel Classification Rate)来评价分类效果。
实验中,监督SVM方法随机选择20个标记样本,其中正类与负类各10个来进行分类器的训练,meanS3VM与本文算法在选好的20个标记样本基础上,再随机选择200个无标记样本训练分类器,最终用训练好的分类器对全图估计标签,得到分类结果。
实验中监督SVM算法使用网上流行的工具包实现,版本号为 libsvm-mat-2.83-1[14],核函数使用高斯核函数,其中gamma的取值采用网格搜索法在 gamma=[1.0E -04:0.2E -04:1.0E -03]中寻找最优值,参数C采用经验取值1。
实验中meanS3VM算法的参数有C1与C2,C1的取值与监督SVM算法的参数C的取值相同,C2采用经验最优值0.1。ep的选取:对无标记样本标签预估计,假设正类数目为u+,然后再用网格搜索在ep= {u+-10:1:u++10}中寻找最优值。gamma的取值采用网格搜索法在gamma=[1.0E- 04:0.2E - 04:1.0E - 03]中寻找最优值。
本文的改进算法中,聚类数k采用对不同图像多次实验得到的一个经验取值。在实验中,每幅图像选取20个标记样本和200个无标记样本,实验中聚类数k的选取从2到8进行实验。以实验中的“Horse008”和“Horse109”为例,分类正确率如表1所示。

Table 1 Impact of clustering number on algorithm accuracy表1 聚类数k对算法的正确率影响
从表1可以看出在聚类数为4时分类准确率的值较高,所以实验中聚类数k初始取值为4,然后采用网格搜索法在k={2:1:6}中选择最优值。ep的选取:对无标记样本标签预估计,假设正类数目为u+,然后再用网格搜索在ep={u+-10:1:u++10}中寻找最优值。C1与 C2的取值与meanS3VM中的C1与C2取值相同。gamma的取值采用网格搜索法在gamma=[1.0E-04:0.2E-04:1.0E -03]中寻找最优。
4.1 Hourse数据集实验结果
实验选取了有代表性的五幅图作为结果展示,对于每幅图像算法的参数寻优后的结果如表2所示。

Table 2 Algorithm parameters表2 算法参数
监督SVM算法、meanS3VM算法与本文算法的分类结果如图2所示,各方法的运行时间与分类正确率如表3所示。各方法的正确率对比图如图3所示。从表3可看出,因为添加了无标记样本信息,所以meanS3VM与本文算法的分类正确率都高于监督SVM算法。Horse008的背景与目标都比较简单,选取的20个标记样本提供了大量的信息,而无标记样本的标签均值没有提供额外的训练信息,所以针对Horse008,meanS3VM算法分类正确率与监督SVM算法分类正确率相当,本文算法的分类正确率高于前两种算法。监督SVM算法不使用无标记样本,训练分类器时间最短,本文算法需要对无标记样本聚类再求聚类标签均值,所以时间会略高于meanS3VM算法,但是相比于分类器正确率的提高,本文算法的时间开销可以接受。从图3可以看出,本文算法对不同类型的图像分类正确率都优于meanS3VM算法,因为对于图像的光谱特征进行聚类后,通过聚类均值标签间隔最大化约束,使得同一光谱特征的样本点标签一致,提高了算法的分类正确率。
因为监督SVM算法只使用标记样本来训练分类器,随机选取无标记样本不会影响算法的分类结果。所以,仅仅对比meanS3VM算法与本文算法的稳定性。先固定选取好的20个标记样本,随机选取200个无标记样本进行实验,对每幅图像进行10次实验,10次正确率的均值和方差如表4所示。meanS3VM算法与本文算法的稳定性对比如图4所示,从图4可以看出,本文算法的稳定性更优。

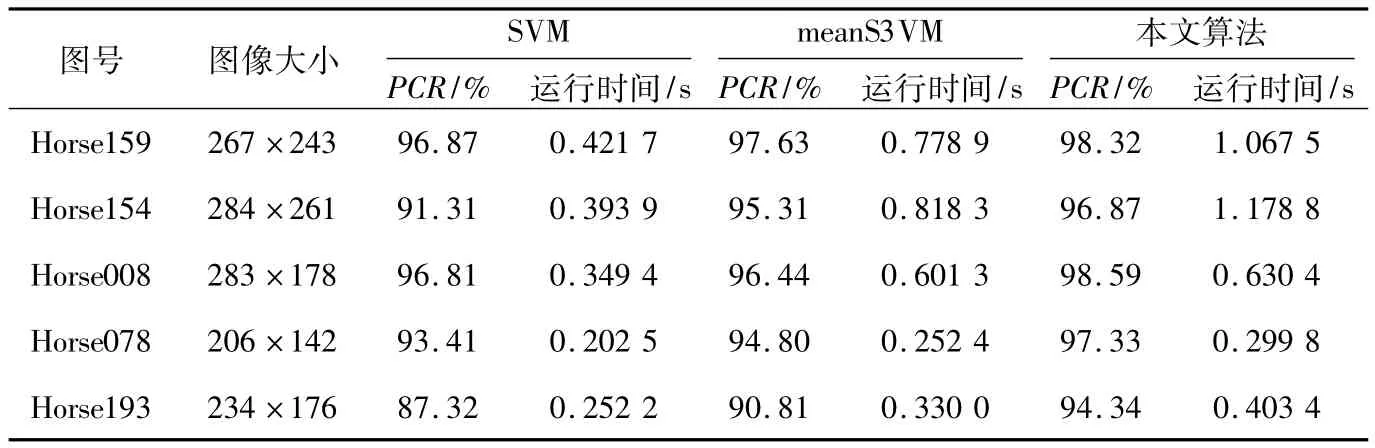
Table 3 Classification accuracy and time efficiency of each method on horse dateset表3 Horse数据集上各方法分类正确率和时间效率

4.2 Flower数据集分类结果
在Flower数据集上的分类结果如图5和表5所示,参数的寻优过程与4.1节类似,因为篇幅的原因本文选取数据集中的三幅图像进行展示。如图5所示,其中第一列图像是待分类图像,第二列图像是理想分类结果,第三列图像是监督SVM分类结果,第四列图像是meanSVM分类结果,第五列是本文算法分类结果。因为聚类标签均值约束利用了图像的光谱特征训练分类超平面,分类的结果更加符合光谱特性,即光谱特性相似的样本标签一致,这样就会减少错分,提升算法的正确率,表5是各算法分类的正确率与时间效率。
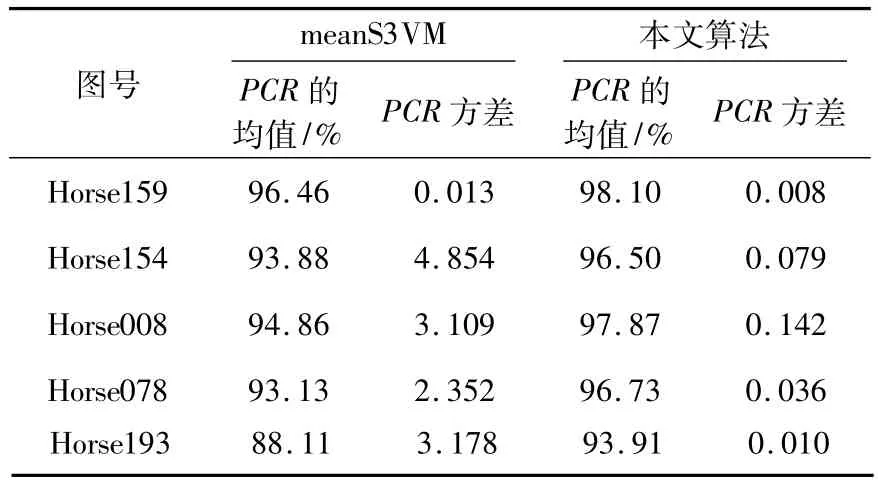
Table 4 Stability tests表4 稳定性实验

5 结束语
本文将meanS3VM算法的标签均值修改为聚类标签均值,并改变了原算法对无标记样本的惩罚项的约束条件,在训练分类器的过程中,首先对无标记样本聚类,在聚好的每个类别中分别求取预估标签均值,利用一个基于间隔的框架使每类的预估标签均值之间的间隔最大化。实验结果显示,本文算法的分类正确率比meanS3VM算法的要高,而且在无标记样本随机选取的情况下,本文算法的稳定性也远远高于meanS3VM。今后将研究针对不同的图像,根据图像的光谱特征自适应地得到聚类数k,以期可以适用于光谱特征更加复杂的遥感图像分类中。

Table 5 Classification accuracy and time efficiency of each method on flower dataset表5 Flower数据集上各方法分类正确率和时间效率

猜你喜欢
中华养生保健(2020年7期)2020-11-16
智富时代(2019年4期)2019-06-01
智富时代(2019年4期)2019-06-01
电子技术与软件工程(2017年14期)2017-09-08
计算机应用(2017年4期)2017-06-27
家教世界·创新阅读(2016年11期)2016-12-27
天津护理(2016年3期)2016-12-01
故事会(2016年15期)2016-08-23
浙江理工大学学报(自然科学版)(2015年5期)2015-03-01
航天返回与遥感(2014年5期)2014-07-31
