
基于PCA和随机森林的故障趋势预测方法研究
2018-03-08 08:51王梓杰周新志
计算机测量与控制 2018年2期
王梓杰,周新志,2,宁 芊,2
(1.四川大学 电子信息学院,成都 610065;2.电子信息控制重点实验室,成都 610036)
0 引言
现代工业科技在信息化技术发展下,航天、通信和工业等各领域工程系统日趋庞大复杂,考虑到复杂系统的可靠性、安全性和经济性,以诊断与预测技术为核心的PHM[1-2](故障预测和健康管理系统)技术成为设备与系统保障的重要基础和技术支撑。PHM主要包括故障诊断、故障预测和健康管理三个核心部分,其中故障诊断预测又可以分为故障分类[3]和趋势预测[4]等方向,目前的故障趋势预测主要通过传感器提取机械部件的时间序列物理量进行分析诊断,这些时间序列往往是非线性的,对于这类问题,常常用机器学习算法解决。文献[5]等基于神经网络信息融合对舵面系统故障趋势进行预测,但是神经网络在趋势预测中收敛速度缓慢[6-7],同时网络的运算和结构参数依靠经验设置,调参优化缺乏理论指导;文献[8]等人使用HMM/SVM串联结构模型进行联合预测,取得优于任一单一算法的故障预测效果;文献[9]等人提出一种基于ARMA的趋势预测方法,但是容易出现调参复杂的问题。在实际的故障趋势预测中,往往具有多组物理量[10],同时针对每一组时间序列的非线性数据,都可以提取很多频域和时域特征量用于趋势预测和故障分类[11],而在将特征量输入算法作为趋势预测前,为了减少运算量提高精度,往往需要去除特征量中的冗余和干扰性的数据,这些数据无法准确反映趋势并且有重负数据冗余,因此在预测之前对数据进行降维预处理在某些应用场景下能显著提高预测精度,例如PCA、KPCA等特征降维与特征融合方法[12]。而随机森林算法[13](Random forest)是利用多棵树对样本进行训练并预测的一种算法,它既可以应用在分类问题中,也可以用来做回归分析。随机森林相对于传统的决策树算法,具有不剪枝也能避免数据过拟合的特点,同时具备很快的训练速度,并且参数调整简单,在默认参数下往往就能够具备较好的回归预测效果。文中使用轴承退化过程的实验数据,选取BP(back propagation)神经网络模型作为参照模型进行趋势回归效果比较。
1 特征提取与PCA降维处理
在机械轴承故障趋势预测中,由于环境噪声和设备的工况因素,传感器采集到的数据一般带有噪声,对这些时间序列物理量直接进行处理受噪声干扰较大得到的预测精度不高;在趋势预测中,机械的退化与故障反映在时序波形中有时并不能及时反映故障的开始时间,而是存在一定的时移;因此对传感器采集到的数据进行时域和频域的特征提取,本文所使用的数据集为,并且在不清楚不同特征量对于趋势预测的贡献率和相关度的情况下进行趋势预测往往得到的结果并不理想,因此在没有足够物理含义和先验知识的情况下,需要采取方法对特征量进行降维处理。
主成分分析[14](Principal Component Analysis,后文简称为PCA)是最常用的线性降维方法,对于原有的高维特征数据,利用坐标变换的思想,通过线性关系的投影,将高维的数据映射到低维的数据空间中表示,数据的对应关系并非简单的将原有高维数据进行信息量的删减,而是在高维向低维的坐标映射中对相关性特征量进行了整合,得到之前特征量的协方差矩阵,这里的特征量是一个经过重构的全新正交特征量。一方面去除原始数据中各维度数据间的线性关系对于最终分类或者预测算法的精度影响,另一方面,在样本数据不多,但是数据本身维度却相对较高的情况下提高算法分类或者预测的精度。得到低维度的特征量后,保留占据绝大多数影响的特征量,能在保留住较多的原数据点的特性的同时进一步降低特征数据的维度。PCA的计算过程中不需要人为的设定参数或是根据任何经验模型对计算进行干预,最后的结果只与数据相关。但是,如果用户对观测对象有一定的先验知识,掌握了数据的一些特征,却无法通过参数化等方法对处理过程进行干预,可能会得不到预期的效果。是丢失原始数据信息最少的一种线性降维方式。因为PCA相对于其他的降维方法,对于原始数据的信息和关联性丢失较少。设定一个PCA的执行步骤如下:
1)构建m*n阶的变量矩阵,其中m为样本数量,n为原始数据的维数;
2)将m*n阶的变量矩阵X的每一行,即原始数据的一个属性,进行数据的归一化处理;
3)求出协方差矩阵C,并对其特征值和特征向量进行求解;
4) 将特征值从大到小进行排序,选择其中最大的k个,然后将其对应的k个特征向量分别作为列向量组成特征矩阵M;
5)即可以求得原n维的原始高维数据降维到k维后的数据Y=XM。
矩阵Y是由数据协方差矩阵前k个最大的特征值对应的特征向量作为列向量构成的。这些特征向量形成一组正交基并且最好地保留了数据中的信息。
2 决策树与随机森林算法
2.1 决策树
相较于传统的神经网络和贝叶斯算法,决策树是以实例为基础的算法,通过不断的对样本归纳学习从而对分类以及预测等问题进行概率计算。决策树本身的构造并不需要相关样本数据领域的先验知识或者参数设置,因此,决策树很适用于探索性的应用。决策树本身是一个树结构(可以是二叉树或非二叉树)。它表示对象属性和对象值之间的一种映射,树中的每一个节点表示对象属性的判断条件,其分支表示符合节点条件的对象。树的叶子节点表示对象所属的预测结果。使用决策树进行决策的过程就是从根节点开始,测试待分类和待遇测项中相应的特征属性和特征值,并按照其值选择输出分支,将叶子节点存放的类别作为决策结果。构造决策树的关键步骤是分裂属性。所谓分裂属性就是在某个节点处按照某一特征属性的不同划分构造不同的分支,其目标是让一个分裂子集中待分类项属于同一类别。
在此基础上J.Ross Quinlan于1986年提出ID3算法,采用信息增益最大的特征;Breiman等人于1984年提出CART算法利用基尼指数最小化准则进行特征选择;J.Ross Quinlan于1993年提出C4.5算法,采用信息增益比选择特征。
2.2 随机森林
随机森林(Random Forest)是Leo Breiman和Adele Cutler在2001年提出的一个新的组合分类器算法,在此之后,Deitterich在模型中引入了随即节点优化的思想,对随机森里进行了进一步完善,运用了Leo Breiman的“套袋”思想构建了控制方差的决策树集合。随机森林算法利用多个CART(Classification And Regression Tree)作为元分类器,用套袋算法制造有差异的训练样本集,同时在构建单棵树时,随机地选择特征对内部节点进行属性分裂。因此随机森林能较好容忍噪声,并且具有较好的分类性能。实际应用中随机森林作为一种多功能的机器学习算法,除了执行回归、分类的任务,同时也用于处理缺失值、异常值以及其他数据探索中,作为一种降维手段。通常随机森林通过以下步骤运作:
1)我们设定一个样本个数为N的样本集,M表示变量的数目;
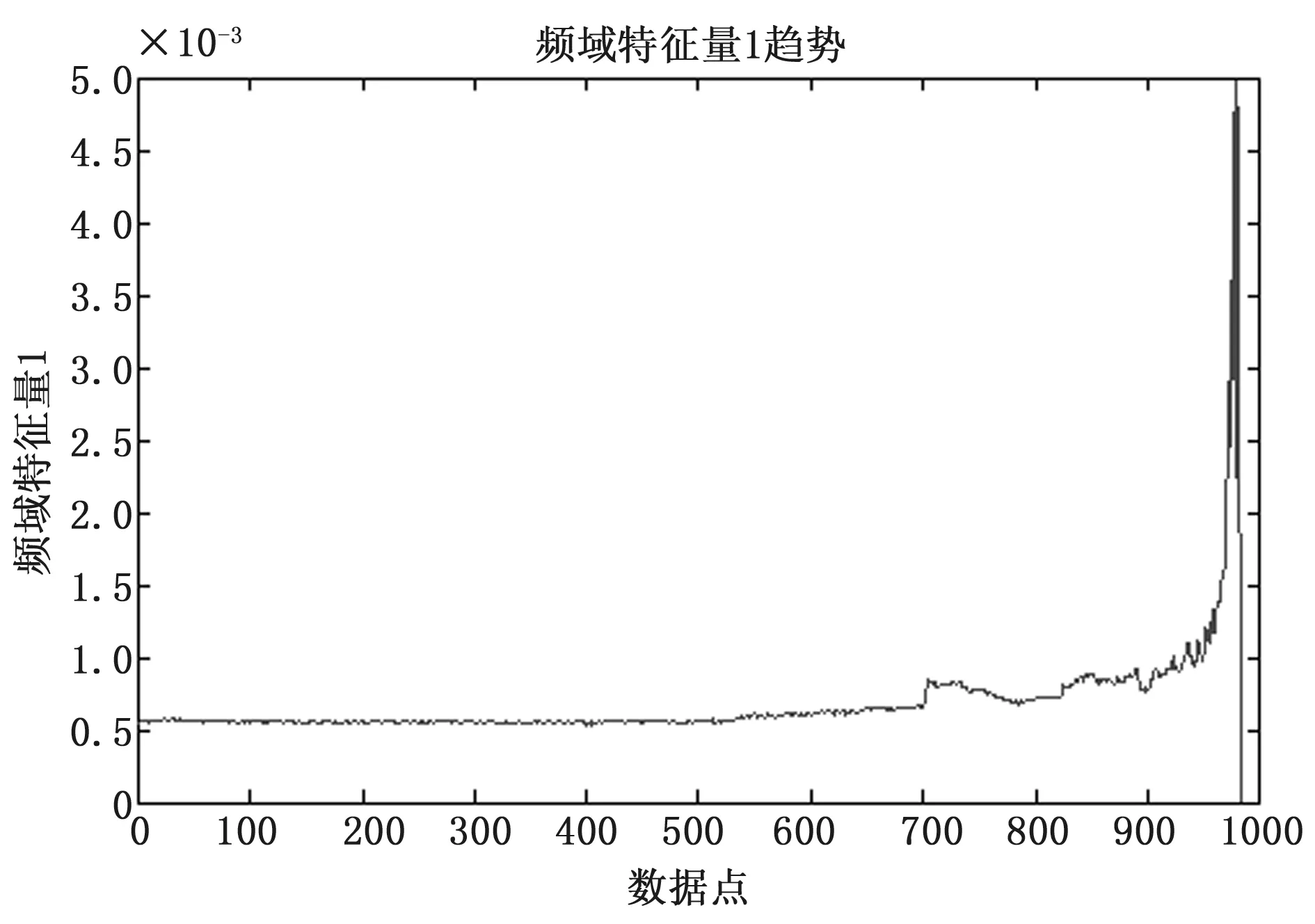
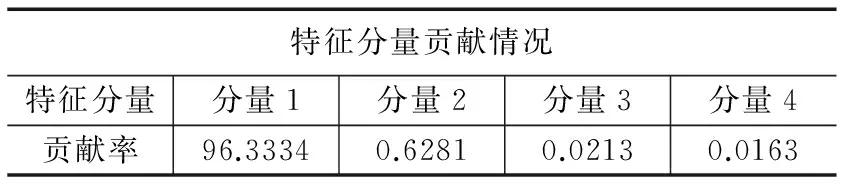
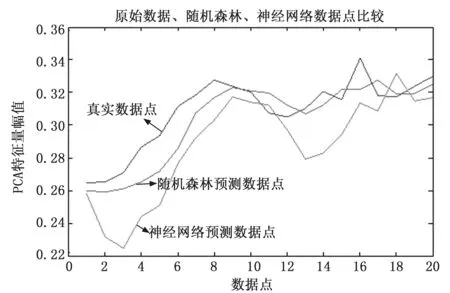
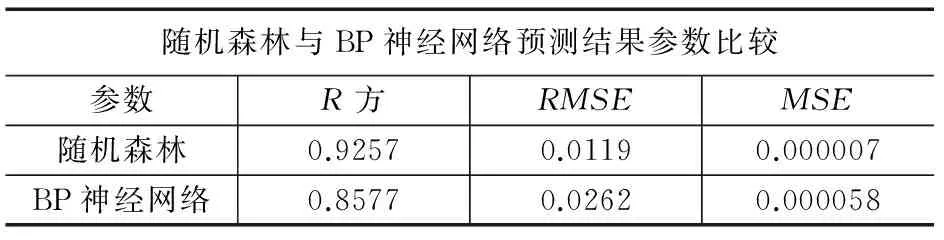
2)每个节点都将随机选择m(m 3)从样本集(N个样本)中以可放回取样的方式,取样N次,形成一组训练集(即bootstrap取样)。并使用这棵树预测剩余类别并评估其误差。 4)对于每一个节点,随机选择m个基于此点上的变量。根据这m个变量,计算其最佳的分裂点。 5)每棵决策树都最大可能地进行生长而不进行剪枝(Pruning),通过对所有的决策树进行加总来预测新的数据。 图1 原始数据振动幅值图 本次针对随机森林算法在轴承诊断中的应用,选择美国辛辛那提大学智能系统维护中心提供的滚动轴承全寿命周期加速轴承性能退化实验数据进行趋势预测实验。该数据为提取的加速度时间序列,采样的时间间隔是10 min,采样频率是20 kHz,采样点数为20480个,实验数据记录了从轴承完好到发生故障的全寿命周期过程,总共984条数据,本文截取其中后期从正常运行工况到具备退化趋势的一段数据进行实验,图1是轴承运行后期的第700条数据的振动信号幅值图。 由于原始数据点数较多,且具有一定的噪声干扰,需要对原始数据进行压缩处理,提取特征量进行分析预测。参考文献(KPCA),从每一节数据中提取10个频域特征量和15个时域特征量,共计25个特征量进行主成分分析,其中时域特征量如时域均值趋势如图2,频域均方根值如图3所示。 图2 时域均值趋势 图3 频域均方根值 对数据的趋势分析得到:从500点开始,数值呈现上升趋势,物理上的表现即反映轴承产生性能退化,并且在700点位置左右有第一个波峰。在所有25个特征值里,反映轴承实际退化趋势的有18个,为了降低数据冗余,提高预测精度,选取了这18个特征量进行PCA主成分分析对高维特征量进行降维,经过主成分分析得到前四个分量的贡献率如表1所示,其中分量1的贡献率超过95%,为96.3334%,依照PCA中选取贡献率位85%以上的特征分量的原则,选择贡献率最高的分量作为随机森林预测效果的实验数据。 表1 部分特征分量贡献率 % 3.3.1 随机森林预测模型构建 根据所采用的实验数据和随机森林的输入输出和结构,首先确定训练集和预测数据,参考数据分析结果,将PCA降维处理后得到的984个数据点中能正确反映轴承故障退化趋势的数据段中,701~900数据点作为训练集,901~920数据点作为预测数据,并建立训练集的训练样本特征空间S=[X,Y],其中X为训练集样本空间如下: (1) (2) X的列数为26,为预测的步长,试验中分别选择10、15、20、25和30作为步长,实验结果显示当步长为25时随机森林预测模型具备最佳的预测效果,因此预测步长为25。随机森林的树的数量选定100~1000,以100为步长步进,得到的结果为树的数量设定为500时具有较好的预测精度。mtry设置为25,其他参数设置为默认值。 3.3.2 实验结果分析 为了验证本文采用的随机森林的预测效果,选取BP神经网络对数据进行预测比较两者的预测精度。选用R方和RMSE以及MSE作为衡量预测值和实际值拟合优度的标准,图4为原始数据点、随机森林预测数据点和BP神经网络预测数据点对比图。 图4 随机森林与BP神经网络对比图 从图4可以看到,神经网络在较为平缓的部分预测值就出现了较大的偏差,并且有明显的预测延迟的情况,而随机森林的预测趋势不但在较为平缓的地方和实际值一致,并且很好的反映了真实值在出现较大波峰时的趋势情况,不仅实际反映退化趋势,同时具备精度较高的预测数值。表2为随机森林算法和BP神经网络算法预测效果的RMSE值、R方值以及MSE值的比较结果。可以看到随机森林模型的R方值为0.9257,相比BP神经网络模型的0.8077提高了14.6%;RMSE值相对于神经网络,降低了55%;随机森林模型的MSEMSE值相较于BP神经网络的MSE值要小一个数量级。 表2 算法预测结果参数比较 提出了一种PCA-随机森林算法用于提高机械故障诊断的趋势预测精度。分析了PCA降维与随机森林算法的建模,使用实际的轴承故障数据进行了趋势预测实验验证,并取用BP神经网络模型作为参照组,来对比随机森林模型的预测效果,使用R方和RMSE以及MSE作为预测趋势的精度评价指标,根据实验结果,BP神经网络在轴承趋势预测中精度相对较低,并且不能很好的反映轴承退化趋势;随机森林模型相对具备更高的预测精度,用时拟合效果较好。然而随着使用的树的数量增加,如本文中在精度较高的情况下,设置树的数量为500棵,在较大的数据处理下,会对计算机造成比一般算法更大的计算压力,预测时间也会显著增加,后期将对随机森林的其他参数进行改进提高运算速度以及趋势预测精度。 [1] 王晓勇. 故障预测和健康管理(PHM)及其应用[J]. 中国电子商务,2013(3):120-120. [2] 刘恩朋,杨占才,靳小波. 国外故障预测与健康管理系统开发平台综述[J]. 测控技术,2014,33(9):1-4. [3] 曾声奎,Pecht M G,吴际. 故障预测与健康管理(PHM)技术的现状与发展[J]. 航空学报,2005,26(5):626-632. [4] 续媛君,潘宏侠. 设备故障趋势预测的分析与应用[J]. 振动、测试与诊断,2006,26(4):305-308. [5] 李 斌,章卫国,宁东方,等. 基于神经网络技术的飞机舵面故障趋势预测研究[J]. 系统仿真学报,2008(21):5840-5842. [6] Feng Z,Chu F,Song X. Application of general regression neural network to vibration trend prediction of Rotating machinery[M]. Advances in Neural Networks - ISNN 2004. Springer Berlin Heidelberg,2004:367-371. [7] Hajnayeb A,Ghasemloonia A,Khadem S E,et al. Application and comparison of an ANN-based feature selection method and the genetic algorithm in gearbox fault diagnosis[J]. Expert Systems with Applications,2011,38(8):10205-10209. [8] 谢松汕,许宝杰,吴国新,等. 基于 HMM/SVM 的风电设备故障趋势预测方法研究[J]. 计算机测量与控制,2014,22(1):39-41. [9] 李 波,赵 洁,郭 晋. 设备故障评估新指标及基于ARMA的预测系统[J]. 系统工程与电子技术,2011,33(1):98-101. [10] Rauber T W,Boldt F D A,Varejão F M. Heterogeneous Feature Models and Feature Selection Applied to Bearing Fault Diagnosis[J]. IEEE Transactions on Industrial Electronics,2015,62(1):637-646. [11] 李 兵,张培林,任国全,等. 基于互信息的滚动轴承故障特征选择方法[J]. 测试技术学报,2009,23(2):183-188. [12] 张 恒,赵荣珍. 故障特征选择与特征信息融合的加权KPCA方法研究[J]. 振动与冲击,2014,33(9):89-93. [13] Surhone L M,Tennoe M T,Henssonow S F,et al. Random Forest[J]. Machine Learning,2010,45(1):5-32. [14] Tipping M E,Bishop C M. Probabilistic Principal Component Analysis[J]. Journal of the Royal Statistical Society,2010,61(3):611-622. [15] Quinlan J R. Induction on decision tree[J]. Machine Learning,1986,1(1):81-106.
3 基于随机森林的故障趋势预测
3.1 实验数据
3.2 特征提取与PCA降维

3.3 实验方案及结果分析
4 结语
猜你喜欢
车主之友(2022年4期)2022-08-27
汽车实用技术(2022年4期)2022-03-07
第一财经(2021年6期)2021-06-10
海峡姐妹(2019年12期)2020-01-14
电子制作(2018年16期)2018-09-26
Coco薇(2017年9期)2017-09-07
科学与财富(2016年32期)2017-03-04
电子制作(2017年24期)2017-02-02
纺织服装流行趋势展望(2016年2期)2016-05-04
