
基于PSO-SVM的网络舆情垃圾观点识别∗
2018-03-20 07:04马晓宁董松月
计算机与数字工程 2018年2期
马晓宁 王 婷 董松月
(中国民航大学 天津 300300)
1 引言
网络舆情是指一定社会群体在一定时间内,对某种事件的看法,是网民对社会舆论情况的反映。随着互联网的快速发展,网民通过网络平台发表自己的见解和看法越来越普遍。由于网络具有虚拟性和开放性,导致网民在工作、生活中遇到不快,均可以通过网络进行宣泄,网络上的负面言论对社会稳定会产生不利影响[1]。加之用户的评论没有质量控制机制,网民可以在互联网上发布任何观点甚至包括恶意的言论,从而导致网民生成的评论中存在许多噪声或者虚假的垃圾[2]内容,例如商家可以雇佣“水军”(写手)为自己歌功颂德、对竞争对手口诛笔伐。最早对垃圾评论的定义是出现在文献[13]中,而且应用的场景是在商品评论中,文献中的定义是垃圾评论指的是那些为了促销某种商品而给出一些与实际不相符的积极的评论,或者是为了诋毁某种商品或品牌而给出一些虚假的负面评论,试图故意误导阅读的人或自动的数据挖掘和情感分析系统的“不合法”的活动。本论文将垃圾评论应用于网络舆情领域中,网民生成的垃圾评论的目的大致可能是为了宣泄或者是针对政府,还有的评论可能是由怀有恶意的和情绪失控的人所写[4]。因此,这在很大程度上影响了用户对某个话题的看法,不仅对舆论的导向产生无法逆转的影响,而且影响舆情监管部门对舆情的处置,使其不能够做出正确的舆论引导和正确的舆情分析。所以,清除网络垃圾,净化网络环境,为人们提供一个真实可信的信息平台是必要的。
国内外学者对垃圾网页和垃圾邮件的研究非常广泛,但是对垃圾观点的识别研究相对较少。而且大多数对垃圾观点的识别主要集中在产品评论[5]、互联网销售等[11~12]领域,对网络舆情领域的垃圾观点的识别研究几乎没有。因此如何从海量的网络舆情观点中有效地识别出不真实的、垃圾的评论,是一个亟待解决的课题。
为了有效识别网络舆情垃圾观点,本文首先对网络舆情垃圾观点进行详细的界定,同时设计和采用粒子群优化的支持向量机模型[6~7]对评论进行识别,并且和未被优化的支持向量机模型进行了比较,实验结果表明本文所提出的识别模型能对舆情垃圾观点进行有效的识别。此外,将界定垃圾观点的特征多少和不同特征对垃圾观点识别的影响进行了分析,并通过实验说明选择合适的特征对于垃圾观点识别的重要性。
2 网络舆情垃圾观点的获取和界定[13~20]
对网络舆情垃圾观点的识别,最主要的是界定什么类型的评论属于垃圾,不真实的。而尽可能正确地界定垃圾观点对随后的识别模型效果有直接的影响。本论文中的垃圾观点特征的界定是在借鉴了文献[2]、[3]和[13]基础上,结合和研究了微博上关于网络舆情事件中网民评论的特点,总结出将以下六个特征作为网络舆情垃圾观点识别的特征,因此含有这六个特征的评论即界定为垃圾观点,这六个特征如下:
1)评论者是否匿名:多数情况下,非匿名评论比匿名评论真实性强,可信度更高。蓄意误导价值观,或具有反社会倾向的评论者,以引导舆论,扰乱社会为目的,通常会隐藏身份,选择匿名的可能性较大。
2)评论是否重复出现:普通评论者发表评论目的较单纯,重在表达意见,抒发情感。而发布垃圾信息的评论者,其重点在于误导民众情感,以达到引导舆论的目的,在这一前提下,通常认为虚假评论者希望尽可能扩大网络影响力,在微博中重复发表十分相似的评论,尤其是重复评论,因此本文认为,重复出现的评论可以作为识别垃圾评论的重要特征。
3)评论中是否出现主要评论对象的名称:经过对大量评论的统计分析,垃圾评论通常针对国家、政府或非政府机构,在引导民众对它们产生负面情感的过程中,评论者会忽略评论对象本身。例如马航事件中,评论者会忽略“马航”而着重强调政府词汇。
4)评论中正面情感词出现次数/评论中所有情感词出现次数:一些垃圾评论制造者可能会使用情感词来过分赞扬或者诋毁某一事件。因此,如果一条评论含有多个情感倾向较大的词汇,则该评论作为垃圾评论的可能性就比较大。
5)评论中负面情感词出现次数/评论中所有情感词出现次数。
6)评论中政府部门的出现次数/评论中所有评论对象的出现次数:经过对大量评论的研究统计,在事件的评论中,大多垃圾评论内容是关于贬低、污蔑国家政府,这一特征已成为大多垃圾评论的共性。
3 网络舆情垃圾观点识别模型
3.1 网络舆情垃圾观点识别思想
对网络舆情垃圾观点进行识别前,需要先对判定为垃圾观点的六个特征进行权重的计算,权重的计算采用信息增益(IG)算法。在对网络舆情垃圾观点进行识别时,选择合适的数学模型非常重要。对于垃圾观点的识别其实本质上属于文本的分类问题,分类算法通过对已知类别训练集的分析,从中发现分类规则,以此预测新数据的类别。而目前关于文本的分类算法主要有BP神经网络,贝叶斯分类器,决策树分类算法等。其中,基于基于统计学习理论和结构风险最小化原则的支持向量机(SVM)模型在解决小样本、非线性及高维模式识别问题中有明显的优势,SVM解决问题时,和样本的维数是无关的,这使得SVM很适合用来解决文本分类问题[9]。但是SVM模型的分类效果在很大程度上依赖于惩罚参数C和核函数参数g选取的准确程度,为了提高惩罚参数C和核函数参数g的选择准确率[8],采用启发式的粒子群优化算法对惩罚参数C和核函数参数g进行寻优。
3.2 网络舆情垃圾观点识别模型图
网络舆情垃圾观点识别的模型图如图1所示。

图1 模型整体流程
3.3 粒子群优化算法原理简介
粒子群算法[10]是由Kennedy和Eberhart于1995年提出,他的寻优思想源于对鸟群捕食行为的研究,其基本思想是把每个优化问题的潜在解看成是搜索空间中的粒子,每个粒子都有一个适应值,它由要优化的目标函数决定,每个粒子还有一个速度向量,它决定了该粒子在搜索空间中飞行的距离和方向。假设在一个D维的搜索空间中,由n个粒子组成的种群 x=(x1,x2,…,xn),其中第 i个粒子在D维搜索空间中的位置亦代表问题的一个潜在解。根据目标函数即可计算出每个粒子位置xi对应的适应度值。第i个粒子的速度为vi=(vi1,vi2,…,viD)T,其个体极值为 pi=(pi1,pi1,…,piD)T,全局极值为 pg=(pg1,pg2,…,pgD)T。在每一次迭代中,粒子通过跟踪个体极值和全局极值更新自身的速度和位置,直到搜索到最优位置为止,更新公式如下:
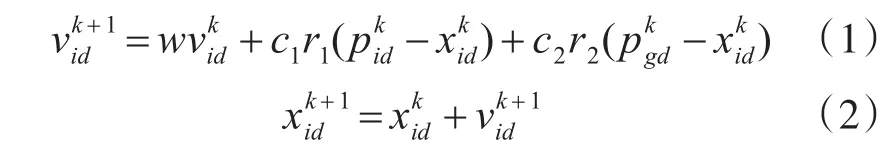
式 中 ,w 为 惯 性 权 重 ;d=1,2,…,D ;i=1,2,…,n;k为当前迭代次数;vid为粒子的速度;c1和c2为非负常数,称为加速度因子;r1和r2为分布于[0,1]之间的随机数。为了防止粒子的盲目搜索,一般将其位子和速度限制在一定的区间[-xmax,xmax]、[-vmax,vmax]。
粒子群算法寻优流程图如图2所示。
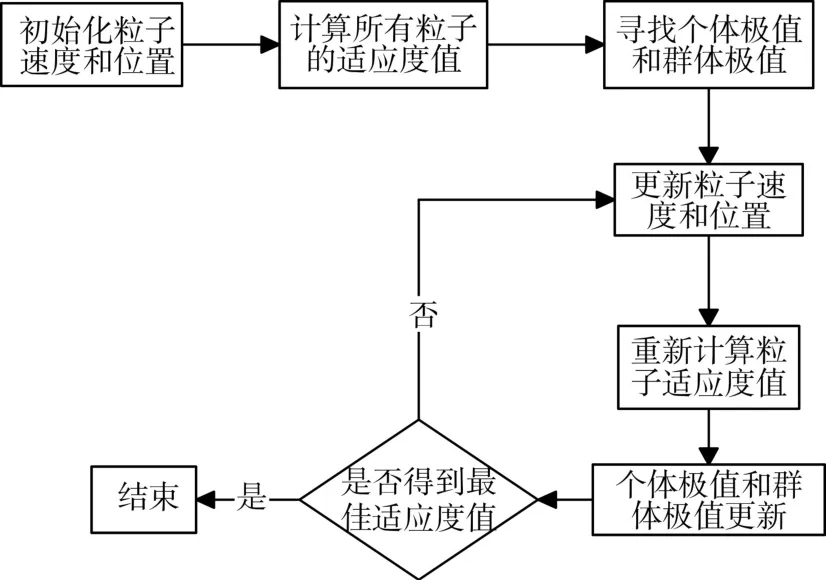
图2 粒子群算法参数寻优流程图
3.4 基于PSO-SVM的网络舆情垃圾观点识别算法设计
本文选择PSO算法来优化SVM分类器的惩罚参数C和核函数参数g,用两个粒子分别代表C和g,基于PSO-SVM的网络舆情垃圾观点识别算法主要步骤如下:
1)选用评论是否匿名、评论是否重复出现、评论中是否出现主要评论对象的名称、评论中正(负)面情感词占比、评论中政府部门出现的占比这6个特征界定是否为垃圾观点,并把这6个特征表示为向量形式,具体表示为:x=(x1,x2,x3,x4,x5,x6)。通过信息增益(IG)计算出每个特征的信息增益值,特征的信息增益值越大,表示其对于垃圾观点的识别贡献越大,对分类也越重要;
2)将从微博上爬取的每一条舆情事件的评论都用以上特征向量表示,分别选取一部分作为训练集,一部分作为测试集,并且将这些特征向量的数据进行归一化处理;
3)将粒子群算法中的惩罚参数C和核函数参数g进行初始化,随机产生C和g的位置和速度;
4)结合舆情事件评论的训练集计算初始的惩罚参数C和核函数参数g的适应度值;
5)根据适应度值通过式(1)和式(2)更新当前的惩罚参数C和核函数参数g的位置和速度;
6)当迭代次数或者适应度值满足最优解时,则停止迭代,否则返回步骤(2);
7)利用评论训练集和最佳的参数C、g进行SVM的训练;PSO-SVM的形成是通过选取训练集的6维评论样本,通过SVM算法计算出5维超平面(将6维空间一分为二的超平面比6维少一维)作为分类的边界,将6维空间一分为二,二分以后的两个空间分别代表真实评论的特征向量集合和垃圾观点评论的特征向量集合。运用PSO-SVM计算出的5维超平面的数学表达式如下:

该最优化问题的求解需要联立式(4)和式(5)

其中的约束是指要求各个数据点到分类面的距离大于等于1。由SVM数学模型可知,需要求解的是支持向量机系数 αi(i=1,2,…,m),自适应函数为

步骤(3)中粒子的初始位置应该满足以下条件:

得到的函数属于二次规划问题,使用拉格朗日函数结合优化问题和约束,再使用对偶理论,即可计算出超平面的数学表达式。
8)将预测集输入进训练好的PSO-SVM分类器中进行垃圾观点的识别;
9)通过评测指标:准确率、召回率和F-mea⁃sure进行垃圾观点识别准确率的评测。
PSO优化SVM网络舆情垃圾观点识别算法的流程图如图3所示。

图3 PSO-SVM网络舆情垃圾观点识别流程图
4 实验结果分析
本实验以2014年3月8日发生的马来西亚航班失踪事件为主题,随机从新浪微博上爬取有关该事件的200条评论,选择6名实验人员,分别对这200条评论进行垃圾评论和非垃圾评论的人工标注,选择标注结果相同的评论作为实验的数据集。其中50条垃圾评论,50条有意义的评论。实验的结果是为了识别这100条评论是否是垃圾评论,用T代表垃圾评论,F代表有意义评论。
1)先对界定为垃圾观点的6个特征进行信息增益的权重计算,计算结果如表1。

表1 信息增益权重表
2)未优化参数的SVM训练与预测
实验选择40条评论作为训练集,进行SVM分类器的训练,然后用剩下的60条作为测试集测试分类器的识别性能。此时惩罚参数C和g是随机选择的,未被优化的。其中C=3,g=4,所得实验结果如图4。
3)PSO-SVM训练与预测
用粒子群算法优化的适应度变化曲线如图5,优化后的最佳惩罚参数C=18.0918,最佳的核函数参数g=0.94346。经过PSO-SVM的识别图如图6,通过对比SVM和PSO-SVM的结果,可以得出经过优化惩罚参数和核函数参数g使得识别效果有明显提高。

图4 SVM网络舆情垃圾观点识别图
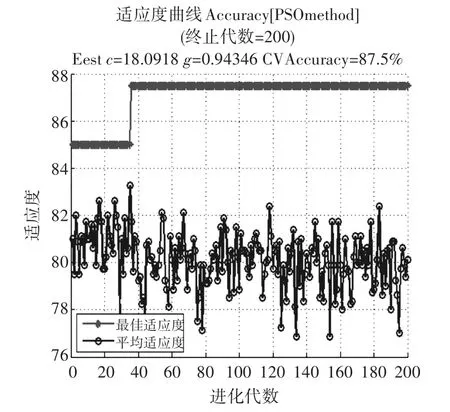
图5 PSO适应度曲线

图6 PSO-SVM网络舆情垃圾观点识别
4)将PSO-SVM中的6维特征输入改成5维特征,用来检测输入特征对识别结果的影响。
首先将输入的信息增益值最小的评论对象名称这一特征去掉并进行识别实验,然后再将信息增益值最大的政府部门这一特征去掉进行识别实验。实验结果如图7和图8,实验结果表明评价对象这一特征对识别结果影响不大,而政府部门这一特征由于信息增益值比较大,所以对识别结果影响较大。

图7 去掉特征(1)垃圾观点识别图

图8 去掉特征(6)的垃圾观点识别图
5)网络舆情垃圾观点识别性能评测
对识别性能的评测,实验采用准确率,召回率和F-measure作为网络舆情垃圾观点识别的评判标准。实验中,准确率是指评论被分类器分类到类别ci而且这个分类正确的概率。召回率就是一条评论应该属于类别ci,而分类器也确实将其分类到类别 ci的概率。计算结果通式(9),(10)和(11)计算得出。
准确率和召回率的计算公式分别为

其中a表示测试评论集中本来属于类别ci而且被分类器分到类别ci的评论数;b表示测试评论集中本来不属于类别ci但却被分类器错误分类到类别ci的评论数;c表示本来应该属于类别ci但被分类器分到别的类别的评论数。
F-measure的计算采用由Van Rijsbergen提出使用综合考虑准确率和召回率两种指标来计算,计算公式如下:

将以上不同各实验结果进行比较结果如表2所示。
由表得出优化了参数的SVM识别效果比未被优化的SVM要好。而垃圾识别特征的界定对分类的准确率也有很重要的影响,通过实验可得,信息增益值越大的特征对分类效果影响越大,从而可知这个特征在垃圾观点评论中越重要。
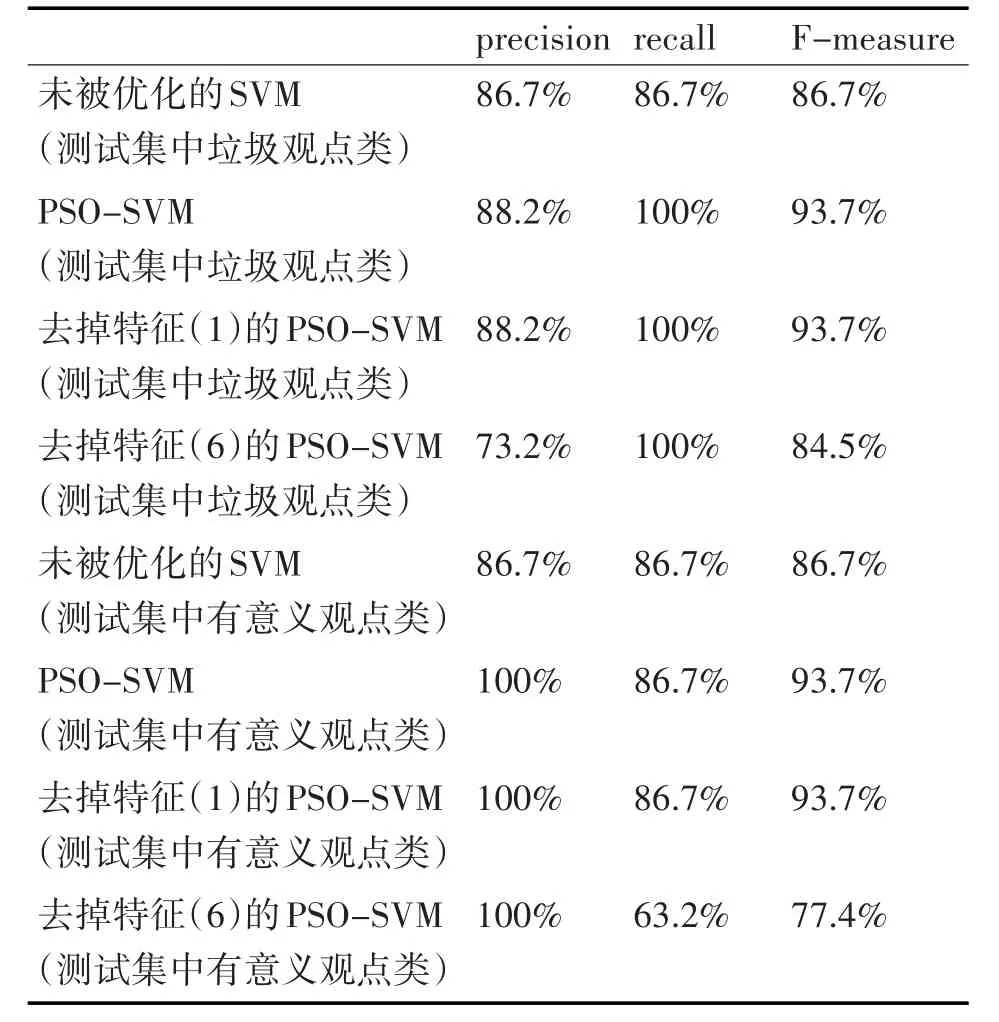
表2 不同实验的比较结果
5 结语
1)总体上,对于垃圾观点的识别研究是一个比较新的领域,关键是提取垃圾观点特征上,不同的事件特征有可能不同[14],但是融合评论内容和评论人这两方面特征适用于多数的垃圾观点识别,并且特征越多,对于垃圾观点的识别越有效。
2)在实现技术上,由于存在标注的偏差,基于机器学习的分类方法存在一定的局限性,所以在实现技术上还需进一步的探索。
3)在Web2.0互联网环境中用户的隐私保护和信息安全问题是垃圾观点识别研究发展的制约,垃圾观点识别研究是为了将网络中存在的大量水军或者垃圾评论进行识别并且对其采取防治的措施[15]。所以,实验分析中如何避免涉及用户的个人信息同时还能将网络水军和垃圾观点高校的识别出来,是研究中的一个难点。
[1]陈晓美.网络评论观点知识发现研究[D].长春:吉林大学,2014.
CHEN Xiaomei.Network review opinions knowledge dis⁃covery research[D].Changchun:Jilin University,2014.
[2]李霄,丁晟春.垃圾商品评论信息的识别研究[J].情报分析与研究,2013,229(1):63-68.
LI Xiao,DING Maochun.Rubbish goods comments infor⁃mation recognition research[J].Intelligence Analysis and Research,2013,229(1):63-68.
[3]董松月,陈润雨,刘西菩,等.网络民航事件虚假评论的识别研究[J].智能计算机与应用,2016,6(4):28-31.
DONG Songyue,CHEN Runyu,LIU Xipu,et al.False comments identifying research about network of civil avia⁃tion events[J].Intelligent Computer and Application,2016,6(4):28-31.
[4]韩晓晖.Web社会媒体中信息的质量评价及应用研究[D].济南:山东大学,2012.
HANG Xiaohui.Web information quality evaluation and application of research in social media[D].Jinan:Shan⁃dong University,2012.
[5]莫倩,杨珂.网络水军识别研究[J].软件学报,2014,25(7):1505-1526.
MO Qian,YANG Ke.Network water army recognition re⁃search[J].Journal of Software,2014,25(7):1505-1526.
[6]李明.改进PSO-SVM在说话人识别中的应用[J].电子科技大学学报,2007,36(6):1345-1349.
LI Ming.Improved PSO-SVM application in speaker rec⁃ognition[J].Journal of University of Electronic Science and Technology,2007,36(6):1345-1349.
[7]朱凤明,樊明龙.混沌粒子群算法对支持向量机模型参数的优化[J].计算机仿真,2010,27(11):183-186.
ZHU Fengming,FAN Minglong.Chaotic particle swarm optimization algorithm for support vector machine(SVM)model parameters optimization[J].Computer Simulation,2010,27(11):183-186.
[8]胡云艳,彭敏放,田成来.基于粒子群算法优化支持向量机的模拟电路诊断[J].计算机应用研究,2012,29(11):4053-4055.
HU Yunyan,PENG Minfang,TIAN Chenlai.Based on par⁃ticle swarm algorithm to optimize the analog circuit diagno⁃sis of support vector machine(SVM)[J].Computer Appli⁃cation and Research,2012,29(11):4053-4055.
[9]谷文成,柴宝仁,滕艳平.基于粒子群优化算法的支持向量机研究[J].北京理工大学学报,2014,34(7):705-709.
GU Wencheng,CHAI Baoren,TENG Yanping.Support vector machine research based on particle swarm optimiza⁃tion algorithm[J].Journal of Beijing institute of Technolo⁃gy,2014,34(7):705-709.
[10]杨钟瑾.粒子群和遗传算法优化支持向量机的破产预测[J].计算机工程与应用,2013,49(18):265-270.
YANG Zhongjin.Particle swarm optimization and genetic algorithm of support vector machine(SVM)bankruptcy prediction[J].Computer Engineering and Applications,2013,49(18):265-270.
[11]邓冰娜.一种应用于博客的垃圾评论识别方法[J].郑州大学学报,2011,43(1):65-69.
DENG Bingna.A kind of application in blog comment spam recognition method[J].Journal of Zhengzhou Uni⁃versity,2011,43(1):65-69.
[12]马焕强.论坛垃圾回帖的识别与过滤[D].保定:河北大学,2014.
MA Huanqiang.BBS spam reply identification and filter⁃ing[D].Baoding:Hebei University,2014.
[13]Jindal N,Liu B.Review Spam Detection[C]//In:Pro⁃ceedings of the 16th International Conference on World Wide Web,Banff,Al-berta,Canada.New York,NY,USA:ACM,2007:1189-1190.
[14]Mukherjee A,Liu B,Wang J,etal.Detecting Group Re⁃view Spam[C]//In:Proceedings of the 28th ACM Interna⁃tional Conference on Information and Knowledge Manage⁃ment,Hyderabad,India.New York,NY,USA:ACM,2011:1123-1126.
[15]Lim E-P,Nguyen V-A,Jindal N,et al.Detecting prod⁃uct reviews spammers using rating behaviors[C]//In Pro⁃ceedings of the 19th ACM International Conference on In⁃formation and Knowledge Management.Toronto,ON,Canada:ACM,2010:930-948.
[16]Jindal N,Liu B,Lim E-P.Finding a typicalreview pat⁃terns for detecting opinion spammers[R].2010.
[17]Jindal N.Liu B,Lim E P.Finding Unusual Review Pat⁃terns using Unexpected Rules[C]//Proceedings of the 19th ACM International Conference on Information and Knowledge Management,2010:1549-1552.
[18]WU G,Greene D,Smyth B,et al.Distortion as a Valida⁃tion Criterion in the Identification of Suspicious Reviews[C]//1st Worksh op on Social Media Analytics.Washing⁃ton,DC,U SA,2010.
[19]Wang G,Xie S H,Liu B,et al.Identify Online Store Re⁃view Spammers via Social Review Graph[J].ACM Trans⁃actions on Intelligent Systems and Technology(TIST),2012,3(04).
[20]Xie S H,Wang G,Lin S Y,et al.Review Spam Detection via Temporal Pattern Discovery[C]//Proceedings of the 18th ACM SIGKDD International Conference on Knowl⁃edge Discovery and Data Mining,2012:823-831.
猜你喜欢
电子产品世界(2022年4期)2022-04-21
昆明医科大学学报(2022年1期)2022-02-28
计算机系统应用(2021年2期)2021-02-23
新疆大学学报(自然科学版)(中英文)(2020年2期)2020-07-25
电子技术与软件工程(2019年18期)2019-11-18
电子技术与软件工程(2017年14期)2017-09-08
领导决策信息(2017年13期)2017-06-21
领导决策信息(2017年9期)2017-05-04
消费电子(2016年12期)2017-01-19
