
数据缺失下微粒群优化特征选择方法
2018-03-23 03:45胡滢
西安文理学院学报(自然科学版) 2018年2期
胡 滢
(铜陵学院 电气工程系,安徽 铜陵 244061)
微粒群优化(Particle Swarm Optimization,PSO)是一种受鸟群或鱼群觅食行为启发产生的全局搜索方法.由于具有参数少、易于实现,以及不依赖优化问题的梯度等优点,微粒群优化已被用于解决许多实际问题,如电网经济调度、机器人路径规划,以及车间生产调度等.但是,目前仍没有关于数据缺失下的微粒群优化特征选择方法的研究.
1 提出的方法
首先,采用多重插补方法对缺失的数据进行插补,得到完整数据集;然后,采用k折交叉验证法计算分类器的精度,并在算法运行后期,对微粒群进行K均值聚类,从中选择微粒的全局最优点,以提高算法的全局搜索能力.
1.1 多重插补
多重插补是一种以模拟为基础的方法,对每个缺失值产生m个合理的插补值,这样插补后,得到m组完全数据,使用标准的完全数据方法分析每组数据并融合分析结果[1].通常,往往假定抽样机制是可以忽略的,因此,可以考虑简单随机抽样下的多重插补方法.具体过程如下:

1.2 微粒编码
特征选择是指从大量特征中选择出具有较好可分性的特征子集,是离散优化问题.因此,需要采用特征选择的概率对微粒进行编码,将离散变量的特征选择问题转化为连续变量优化问题[2].假设第i个微粒的位置表示为xi=(xi1,xi2,…,xiD),若xij=1,则第j个特征被选中,否则,该特征没有被选中.
1.3 适应度函数
在特征选择过程中,期望所选特征子集的分类精度越高,特征个数越少.本文借鉴文献[3]的方法设置适应度函数:
(1)
其中,A(x)表示以特征子集x反映的特征进行分类的精度,n(x)和β分别表示特征的数量及其重要程度,由于重点考虑分类精度,因此β可以取0.005.本文采用k折交叉验证法,计算分类器的精度,对于含有S个数据的数据集而言,将S个数据分成k个不相交的子集,记作{s1,s2,…,sk}.每次从分好的子集里,选择一个作为验证集,剩余k-1个作为训练集.首先,由训练集对特征子集形成的分类器进行训练,得到一个分类模型;然后,利用验证集,验证分类模型的性能,得到分类精度;最后,计算k次分类精度的平均值,作为该模型的真实分类精度[4].
1.4 全局极值的选择
由于微粒全局极值选择直接影响微粒速度的更新,从而影响微粒下一时刻的位置.因此,采用合适的方法选择微粒的全局极值,是非常重要的.采用传统方法选择微粒全局极值,易使算法陷入早熟和局部最优.因此,在算法运行后期,使用K均值聚类算法,增大搜索范围,使微粒及时跳出局部最优解.方法是:首先,对微粒群进行K均值聚类,产生若干个聚簇;然后,计算各个簇的中心,找到当前全局最优粒子所在的簇;最后,依次对其余簇进行讨论,计算是否包含更优的解.具体过程如下:
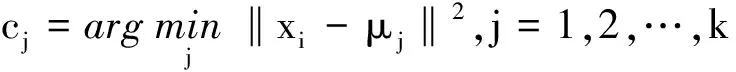

(2)
式中:α=(-1)λ,用于控制搜索的方向.rand为[0,1]之间均匀分布的随机数.

1.5 算法步骤
Step1:对缺失数据进行插补,得到完整的数据集;
Step2:初始化微粒群,设置每个微粒的个体极值为其本身,储备集为空,迭代次数t=0,最大迭代次数记为Tmax;
Step3:根据式(1)计算目标函数值;
Step4:更新微粒的全局极值和个体极值;
Step5:算法运行后期(t=0.8Tmax),按1.4节方法更新微粒的全局极值;
Step6:调整微粒的位置;
Step7:判断算法是否满足终止条件.如果满足,输出优化结果;否则,转Step3.
2 实验与结果分析
为验证本文方法的性能,基于UCI数据集,将所提方法与标准微粒群优化方法(SPSO)、NSGA-II,及混沌映射二进制微粒群优化(CBPSO)进行比较[5],验证所提方法的有效性.所有试验采用的PC机配置为双核2.66 GHz、2 G RAM,Matlab编程.
2.1 测试数据及参数设置
选择4个UCI数据集进行分析,分别是Class、Letter、WDBC及Sonar,随机删除其中的一部分数据.相关信息如表1所示.

表1 UCI数据集相关信息
算法参数设置如下:最大迭代次数Tmax=100,微粒群规模N=100,c1=c2=2,由于惯性权重w用来平衡微粒群的探索和开发能力,因此,按照文献[6]给出线性时变调节方法取值,其中,wmax=0.995,wmin=0.5,比较算法参数依据相应文献进行设置.
2.2 实验结果
针对完整数据集和缺失数据集两种情况,将本文方法与其他3种方法进行比较,分别计算它们的分类精度和降维后特征子集的个数,结果如表2所示.

表2 四种方法的分类精度比较
由表2可知,对于缺失数据集,4种方法所得分类精度均小于完整数据集.原因是采用多重插补方法得到的替代值仍是估计值.由此,训练集构建的分类器也是一个近似分类器,分类精度要小于实际分类器的分类精度[7].对于Class、Letter及Sonar数据集,本文方法获得的分类精度均较高,且得到的特征子集的个数也是最少的,而对于WDBC数据集,尽管CBPSO方法获得的分类精度要优于本文方法,但本文方法能够获得最少的特征子集个数.综上结果可知,针对缺失数据下的特征选择,所提方法比其它3种方法具有更好的特征选择效果.
图1针对完整数据集和缺失数据集,给出了本文方法对上述4种数据集的进化优化结果.从图中可以看出,缺失数据下的分类精度均小于完整数据集的分类精度,且随着进化代数的增加,分类精度越来越高,当达到100代后,分类精度基本保持不变.由此可知,本文方法均能以较快的寻优速度获得较高的分类精度.

图1 本文方法对上述4种数据集在完整数据和缺失数据上的分类精度进化曲线
3 结语
本文针对数据缺失这一普遍现象,提出了一种改进的微粒群优化特征选择方法.首先,采用多重插补方法对缺失的数据进行插补,得到完整数据集;然后,用k折交叉验证法计算分类器的精度,比较微粒解的优劣;同时为防止微粒群陷入局部最优,在算法运行后期,进行K均值聚类,使微粒群跳出局部最优点;最后,通过测试4个典型UCI数据集,对完整数据集与随机删除部分数据后的缺失数据集的特征选择结果进行比较.结果表明,本文方法在处理数据缺失的特征选择问题上具有一定的优势,是一种有效的特征选择方法.
[1] 周勇,何创新.基于独立特征选择与相关向量机的变载荷轴承故障诊断[J].振动与冲击,2012,31(3):157-161.
[2] 巩敦卫,胡滢,张勇.知识引导微粒群优化特征选择方法[J].模式识别与人工智能,2014,27(1):1-10.
[3] 宋相法,张延锋,郑逢斌.基于L2,1基范数稀疏特征选择和超法向量的深度图像序列行为识别[J].计算机科学,2017,44(2):306-308,323.
[4] 曾现峰.基于双层微粒群优化的机器人全局路径规划[J].计算机工程与应用,2013,49(19):238-241.
[5] 邓桂秀,江修波,蔡金锭.基于混沌二进制粒子群算法的配电网重构研究[J].电力科学与工程,2013,29(9):34-37.
[6] 王丽,王晓凯.一种非线性改变惯性权重的粒子群算法[J].计算机工程与应用,2007,43(4):47-49.
[7] 徐海波,仲梁维,龚文露.车间生产调度优化中改进微粒群算法的引用[J].机械工程与自动化,2015,6(3):76-80.
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
南京大学学报(数学半年刊)(2020年1期)2020-03-19
心肺血管病杂志(2019年12期)2019-05-20
吉林大学学报(理学版)(2018年4期)2018-07-19
中国有色金属学报(2018年2期)2018-03-26
疯狂英语·新悦读(2017年6期)2017-06-24
电子制作(2017年23期)2017-02-02
西北工业大学学报(2015年4期)2016-01-19
智能系统学报(2015年4期)2015-12-27
都市丽人(2015年4期)2015-03-20
