
DrawerPipe:基于FPGA的可重构分组处理流水线模型
2018-04-16 11:59厉俊男杨翔瑞孙志刚
计算机研究与发展 2018年4期
厉俊男 杨翔瑞 孙志刚
(国防科技大学计算机学院 长沙 410072) (lijunnan@nudt.edu.cn)
公有云在共享基础设施为多租户提供计算、存储等服务的同时,还需要部署各种类型的网络功能以实现租户之间的网络隔离、服务质量保证以及安全防护功能.因此,公有云必须具有灵活部署网络功能的能力,可以将其总结为2方面的需求:1)公有云将每个租户部署在特定的虚拟网络环境中,需要灵活地部署多种类型的网络功能以实现租户间的性能隔离,并保证租户所需的网络服务质量[1];2)云服务提供商需要为租户提供动态部署网络功能的能力,方便租户获取公有云网络的状态信息,例如网络的拓扑信息、链路流量分布、交换机实时队列长度等[2-3].
传统的网络功能通常基于专用硬件实现,灵活性较差,无法满足快速部署网络功能的需求[4].为此,目前主流云服务商,如微软、亚马逊,主要采用软件实现各类网络功能,以获得最大的灵活性[1,5-6].然而软件实现的网络功能存在2方面不足:1)处理性能有限,通常需要多个CPU核并行处理才能达到10 Gbps速率[1,7],难以满足40 Gbps甚至更高速率[8]的处理需求;2)软件处理的延时具有较大不确定性,延时从几十微秒到几毫秒不等[9],这对许多低延迟应用而言是难以接受的[10].
为了在保证灵活性的同时提升处理性能,最近一些研究提出了基于图形处理器(GPU)[11]、网络处理器(NP)[12]或FPGA[1,13]的实现方法.由于FPGA具有更高的能耗比和功能定制能力,获得了更高的关注,并在数据中心中得到应用.例如,微软、百度和亚马逊等云服务提供商[14-16]已经在他们的数据中心部署了FPGA,用于加速内部和第三方工作负载,以及实现定制的网络服务.
基于FPGA的网络功能实现方式面临的主要问题是硬件编程困难,与GPU和NP等基于软件的编程方式相比,开发周期更长.为了简化硬件开发,近年来基于高级语言在FPGA上开发网络功能得到广泛研究[1,17-18],包括使用高级语言(如CC++)编程的高级综合工具(HLS)[19-20],或直接使用特定域语言(domain-specific language)(如P4)[21],描述网络处理功能[22],并通过编译器将其映射到FPGA逻辑[23-24].然而,上述研究还难以达到实用的效果,主要是因为高级语言并不涉及寄存器级描述,而且高级综合工具仍无法很好地解决数据相关问题(例如读写依赖).此外,由高级语言编译产生的硬件代码还存在资源开销大、处理性能低等不足[25].
我们认为,除了使用高级语言编程以外,基于模块化的分组处理流水线设计,通过模块复用同样可以简化FPGA开发的复杂性,缩短开发周期.为此,我们提出了可重构流水线模型——DrawerPipe.该模型将网络功能实现架构抽象为5个标准的“抽屉”,不同的“抽屉”可以根据需要装载不同的处理模块,然后通过组合这些处理模块实现各种网络功能.
与公有云数据中心需要实现五花八门的应用加速不同,需要在公有云中部署的网络功能类型,以及这些功能分解出来的分组处理类型是有限的.这些处理类型主要包括分组解析、精确查表、带掩码查表、各种策略执行以及输出调度等.因此,基于“抽屉化”的流水线架构设计,通过在“抽屉”中填充和组合分组处理模块,能够有效地降低FPGA设计的复杂性,缩短开发和测试周期.
本文对基于FPGA的网络功能实现模型进行了深入研究,主要创新点包括:
1) 对数据中心常见网络功能的处理流程分析发现,网络功能的处理流程均可以映射到解析、分类、功能相关处理、报文修改和输出调度5个阶段.本文在此基础上提出了DrawerPipe流水线模型,只需在流水线的5个“抽屉”中装载处理模块,即可实现特定的网络功能.
2) 针对模块的可重用需求,为“抽屉”之间的信息交互设计了一种可编程接口——DrawerMPI.DrawerMPI采用“强语法,弱语义”的信息交换模型,通过语义适配模块将相邻“抽屉”里的模块解耦,使得第三方模块的开发不再依赖于上下游模块的接口定义.
3) 基于DrawerPipe模型,在NetMagic平台上实现了自定义转发、分组聚合等网络功能,验证了DrawerPipe架构、DrawerMPI的有效性.实验结果初步证明基于DrawerPipe,可在FPGA上按需实现各类网络功能,适合用于网络功能的快速部署.
1 研究背景
1.1 网络功能动态部署的需求
公有云除了部署必要的基础网络功能外,还要根据租户的需求,动态部署不同类型的网络功能,以满足租户对各自虚拟网络的管理.例如,租户需要部署网络功能以增强对自身虚拟网络状态的可视性,包括网络拓扑信息、交换机实时队列长度等.如图1(a)所示,在交换机上部署测量功能[26],能够将交换机实时队列长度反馈回应用程序,方便租户了解虚拟机之间的网络链路拥塞程度,从而能够执行更优的任务分派策略.除此之外,公有云还需要部署多种自定义网络功能,以实现租户特定的分组处理需求[3].例如,由于IP组播缺乏可靠的数据包传播、流量控制和可扩展性,数据中心本身没有开启组播协议[27].但租户的一些分布式计算或系统备份任务[28-29]需要同步数据,即将各自的状态、数据信息组播或者广播给该租户的其他虚拟机.如果采用单播方式实现组播功能,需要复制多份相同的数据包送给目标虚拟机,会占用额外的链路带宽.图1(b)展示了在交换机端部署自定义转发功能,能够节省发送带宽.另外,一些网页搜索服务通常采用分派-聚集模型[30],即向多个服务器发送查询请求,再将返回的响应信息聚合得到最终的查询结果;或者分布式计算架构采用映射-归约(map-reduce)模型.如果在主机端实现聚合或归约功能,则可能出现incast问题[30],即多个响应报文同时返回给请求主机导致链路拥塞.图1(c)展示了在交换机侧部署数据聚合功能,可以有效地缓解incast所导致的链路拥塞.
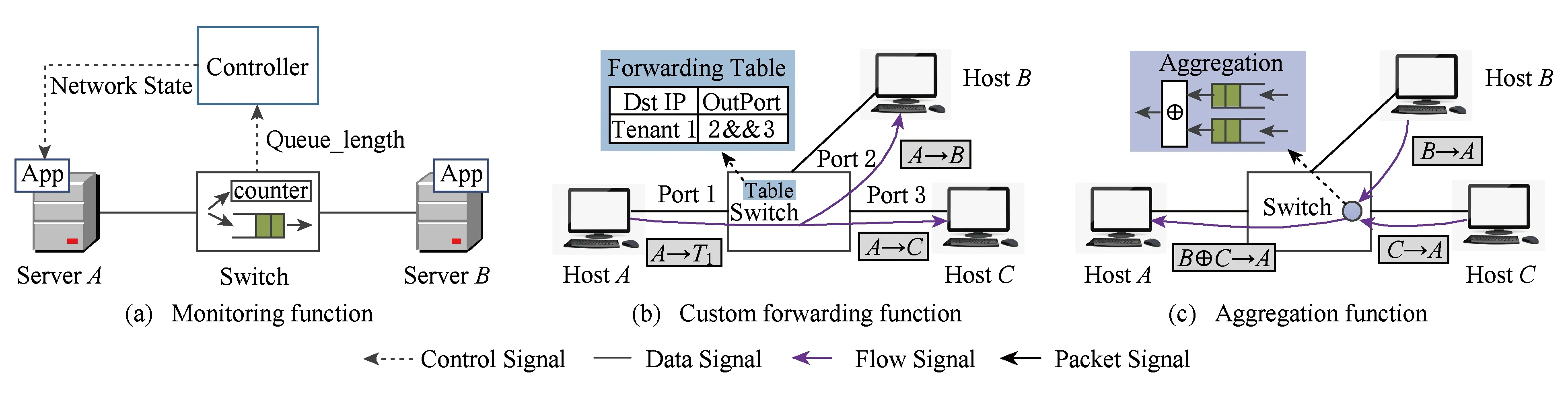
Fig. 1 Three specific network functions in datacenter图1 数据中心的3种特殊网络功能
1.2 相关研究
在FPGA上部署网络功能可以解决软件实现网络功能处理性能低、处理延时高的不足.但由于租户对网络功能的需求随着自身所部署的应用类型、计算任务发生变化,要求FPGA具备灵活快速部署网络功能的能力.
为了避免新网络功能开发与测试周期长的不足,不少的工作[1,7,13,25]借鉴Click[31]路由器模块化设计的思想,并通过共享硬件模块使开发者使用已有的模块重新组合所需的分组处理逻辑.但不同分组处理流水线在功能划分、模块接口定义上存在差异,导致不同模块间无法直接互联,仍需要一种统一的可重构流水线模型.为此,相关研究[32-33]提出了基于FPGA的可重构流水线模型,即将流水线分解为不同的处理阶段,通过在每一处理阶段加载不同的功能模块重构新的网络功能.
目前的可重构流水线模型分为动态可重构[32]和静态可重构[33]2种方式.动态可重构是预先在FPGA上实现多种基本功能模块,然后根据分组处理需求,动态编排数据包经过模块的次序,获得所需的分组处理逻辑.这种方式极大地提升了FPGA的灵活性,只需要重新编排模块顺序即可实现新的网络功能.但由于FPGA资源有限,能够同时在FPGA上加载的模块数量较少,因此只能支持少量的网络功能.
静态可重构首先是连接所需的硬件模块,再综合生成分组处理逻辑.静态可重构流水线模型设计的关键是解决不同流水线间模块重用问题.例如FAST[33],按照分组处理功能划分为5级,每一级采用统一的接口规范,解决了因模块接口定义差异导致的模块重用问题.但FAST采用类似OpenFlow1.0的大流表匹配方案(288-bit多维匹配),而非多级流表匹配方式,存在可扩展性差等不足.
2 网络功能处理流程分析
我们对数据中心常部署的11种网络功能[34]的分组处理流程进行了分析研究,如表1所示.通过分析我们得到的主要结论如下:网络功能可以分解为5个处理阶段(2.1节),以及各处理阶段的功能模块可以在不同网络功能之间重用(2.2节).

Table 1 Five Processing-Stage Abstraction of Network Functions Commonly Deployed in Data Center表1 数据中心常部署网络功能的5个阶段
2.1 网络功能的5个处理阶段
对11种网络功能分析研究发现,网络功能可以被抽象成一系列有序处理动作的组合,而且绝大部分网络功能具有相似的处理流程.例如,大多数网络功能在处理数据包之前都需要执行报文解析功能,以提取后续查表所需的关键字.
我们将这些网络映射到报文解析、报文分类、功能相关处理、报文修改和输出调度5个阶段.其中,报文解析阶段判别报文类型并提取关键字.解析模块可以依据网络分层结构设计,例如二层解析、三层解析.报文解析的另一个功能是分析报文头和报文体,其中报文头用于查表操作,报文体则存放在报文缓存区;报文分类阶段依据关键字实现报文分类,或者实现报文过滤功能.报文分类算法可以依据查表算法设计,例如基于Hash的精确匹配,基于决策树、分解算法、元组空间搜索的多维匹配;功能相关处理阶段实现特定的分组处理功能.例如,在1.1节提及的网络测量功能、自定义转发功能和数据聚合功能;报文修改阶段实现封装解封装操作、标签替换功能.由于报文封装可能超过最大传输单元,例如隧道协议[37],报文重组层还实现报文分片功能,以及在对端网络设备实现分片重组功能;输出调度阶段实现报文的转发功能、QoS流调度功能、整流限速功能,以及深度报文检测功能.当然,还可以获取输出队列长度,显示地通告通信主机链路拥塞程度.
2.2 处理模块的复用
实现上述5个处理阶段中的逻辑称为模块,例如L2解析模块、加解密模块等.通过分析,我们发现这些模块具有2种特性:
1) 可枚举性
分组处理的动作有限,需要的模块类型也有限,其数量基本上随着网络功能的增加而线性增加.目前,网络功能的数目相对有限,因此模块的类型是可以枚举的,例如在上述11类网络功能中,每阶段的模块数目大致为1~3个.
2) 稳定性
通信协议的变化频率相对较低,模块的生存期比较长.因此一旦模块完成设计测试,其内部的处理逻辑可以保持相对稳定.例如L3解析模块,只有在L3协议发生变化时才需要修改具体解析的处理逻辑.
处理模块具有可枚举性和稳定性,可在实现不同网络功能时复用,能够降低网络功能开发的复杂性,并缩短开发与测试周期.然而,在不同的网络功能实现中复用硬件模块,也存在一定的挑战.
1) 模块内在的差异性.由于不同模块内部处理逻辑的复杂性不同,自身实现所需要的资源,以及对外部存储器访存的需求存在较大差异.例如L2解析器只需要提取源、目的MAC地址,资源开销小;而最长前缀查表逻辑需要大量的硬件资源开销.
2) 模块间传递的信息存在差异.不同流水线的模块在设计时难以统一接口的语法语义,导致不同模块在不修改的情况下很难直接互联.例如,接口信号数量、位宽不同的2个模块无法直接连接.
3 DrawerPipe模型
3.1 设计思想
DrawerPipe的设计思路是利用FPGA的特点,解决模块复用面临的2个挑战:
1) FPGA芯片由大量同构的可编程逻辑块组成,而FPGA开发工具的作用是将用户编写的逻辑映射到这些逻辑块中.因此,不同功能模块间逻辑资源的分配是在代码综合过程中实现的.这种方式与ASIC或CPU实现相比,具有2个优点:①模块之间的资源是预分配的,在分配时所有模块共享FPGA的所有资源,比RMT需要将逻辑映射到固定的32级流水线上更简单.②一旦分配成功,其处理性能是可预测的,而且访问外部存储器完全由有限状态机控制,没有cache层次,因此性能是有保证的.
2) FPGA设计方法对各阶段处理模块所占用的资源大小并没有约束,便于实现粗粒度流水线.例如,适合网络功能处理特点的5级流水线.在模块内部屏蔽大量的实现细节,与RMT的32级流水线相比,大大简化了上下级流水线之间信息交换的复杂性,便于设计相对统一的信息交换规范.
3.2 DrawerPipe流水线结构
DrawerPipe根据网络功能处理的流程,将流水线抽象为5个标准的“抽屉”,通过执行装载在“抽屉”中的硬件代码,可以实现相应的网络功能.其中,“抽屉”的特点主要有:
1) “抽屉”具有良好的弹性.由于FPGA的可编程性,不同“抽屉”之间可以共享FPGA资源.因此,在“抽屉”中安装的模块其资源占用具有较大的弹性.
2) “抽屉”之间具有并行性.由于FPGA的并行处理能力,不同“抽屉”之间能够并行执行.而且“抽屉”各自独占内部的存储资源,避免“抽屉”之间的依赖关系.
3) “抽屉”之间具有良好的可移植性.规格相同的“抽屉”之间可以相互替换.对模块而言,接口定义相同的模块之间也可以相互替换.
因此,DrawerPipe可以根据需求在不同的“抽屉”装载不同的功能模块,并通过组合这些功能模块实现各种网络功能.这种可重构流水线模型与可编程流水线模型不同.图2对比了DrawerPipe模型与RMT,ClickNP两种可编程流水线模型.ClickNP流水线中的模块均由高级语言编译生成,模块的接口定义与实现的网络功能相关,即模块之间具有耦合性.虽然高级语言代码可以复用,但编译生成的底层模块因为接口的耦合性无法直接重用.例如,二层解析与三层解析模块可能都提取了目的MAC地址,但放置在flit[1]中位置不一定相同.RMT虽然具有统一的模块接口,但均匀分配流水级资源存在资源浪费;使用VLIW实现分组处理需要消耗大量的逻辑资源,并不适合在FPGA上实现.DrawerPipe则是在5个“抽屉”中装载不同的硬件模块实现所需的网络功能.这些“抽屉”具有相同的外部接口,功能模块直接加载在任意一个“抽屉”中.

Fig. 2 Comparation among different pipeline models图2 不同的流水线模型对比

Fig. 3 DrawerPipe model图3 DrawerPipe模型
DrawerPipe的5级“抽屉”流水线模型,由报文解析、报文分类、功能相关处理、报文修改、输出调度组成,如图3所示.同时,为了避免报文体经过所有模块造成模块存储资源的浪费,我们还设计了单独的报文缓存模块用于存储报文.功能模块间使用Metadata作为信息交互,Metadata采用标准的语法定义(即具有确定的数据位宽),而非采用统一的语义(即定义Metadata中每一位数据所代表的含义).这种功能无关的抽象能够解除模块间由接口信号定义而绑定的耦合性,将在第4节中详细介绍.
3.3 可重构模块库
可重构功能模块库能够为DrawerPipe提供分组处理的功能模块.每一阶段均有其对应的功能模块库,方便用户从中挑选合适的模块,并将它们重组成所需的分组处理逻辑.例如,为了实现二层交换与ACL过滤功能,我们需要在解析阶段加载四层解析器L4 Parser,用于提取报文的五元组信息,并分离报文头与报文负载.与此同时,将报文负载存储在报文缓存模块中;而将报文头以及解析器提取的关键字段组成报文控制块Metadata,送给报文分类模块.在报文分类阶段加载基于BV的报文分类算法[45],实现ACL过滤功能.在功能相关处理阶段加载二层交换功能,实现源MAC地址学习、目的MAC地址查表转发功能.然后在报文修改模块将报文重组,最后经输出调度模块从网络设备的端口输出.
可重构模块库支持功能模块的复用是利用DrawerPipe“抽屉”化设计的特性,即规格相同的“抽屉”之间可以直接相互替换.对模块而言,相同“规格”的定义更加宽松,只需要具有定义相同的模块接口,而不需要统一模块的“尺寸”(即硬件资源开销).这是因为FPGA具有可重构能力,能够按照模块的大小重新分配资源,而非采用均匀的资源分配方式.在DrawerPipe中,我们设计了标准的“抽屉”接口——DrawerMPI(第4节),以保证模块间接口的一致性.
4 DrawerMPI设计
目前,模块的设计是功能相关的,即模块的接口定义与模块所实现的分组处理功能相关.而模块的接口信号定义直接影响模块之间能否重组.进一步分析,模块的接口信号定义类似于自然语言,也可以将其分成语法与语义2部分.模块接口的语法是指接口信号的位宽以及输入输出接口信号的数量;而模块接口的语义则是指信号所代表的含义.因此,协议相关的模块接口设计导致处理不同协议的模块之间在语法或者语义上存在差异,无法直接重组来构建新的分组处理流水线.
本文提出了DrawerMPI(DrawerPipe module programmable interface),一种功能无关的可编程模块接口,用于解除模块间由接口信号定义而绑定的耦合性.功能无关是指DrawerMPI采用语法一致的模块接口(4.1节),包括输入输出接口数量、信号位宽,并利用语义转化模块(4.2节)实现模块接口间的语义适配.DrawerMPI还具有编程能力,通过配置接口信号语义的转化规则,实现不同模块接口之间的适配.因此,对网络功能开发者而言,不需要关心上下游模块所实现的功能类型(或模块接口定义),只需通过配置语义转化模块即可实现模块信号格式的转化.
4.1 DrawerMPI语法设计
模块间能够互连的基本条件是模块接口的语法相同,包括接口数量、位宽.为此,DrawerMPI采用语法一致的模块,即使用固定位宽的报文控制块Metadata作为模块间通信的消息,如图3(b)所示.Metadata作为模块间交互消息的好处是位宽恒定,保证了所有模块具有相同的接口.DrawerPipe所使用的Metadata位宽为132 b,其中包括header tag共4 b,分别是MHT(metadata header tag)用于标识Metadata首部,MET(metadata end tag)标识Metadata尾部,PHT(packet header tag)标识报文首部,PET(packet end tag)标识报文尾部,随后的128 b是具体的报文控制块内容.另外,DrawerPipe使用报文控制块连接模块,即上游模块只需要往下游模块队列中写控制块信息,而下游模块只需要从队列中读取控制块信息,从而能够保证所有模块都具有单输入、单输出接口的特性,便于模块重组.
对报文控制块进一步分析,我们发现模块间对通信内容可以分为3种类型的消息,即平台相关消息、通用报文头字段消息、模块间中间状态交互消息(后两者与网络功能实现的平台无关).其中,平台相关消息是指平台自身提供的内容,包括报文输入端口、输出端口、报文时间戳等信息.通用报文头字段消息是指由解析模块提取的关键字信息,可以用于后续查表操作.由于关键字具有固定格式,在不同的语义环境下可以通过转化进行适配(4.2节).模块间中间状态交互消息是指协同工作的模块间所传递的中间状态消息.例如,源MAC地址学习与目的MAC地址转发功能分离的2个模块,在源MAC地址学习到新的MAC-Port映射关系后需要将该信息(中间状态信息)告诉目的MAC地址转发模块.在需要相互协同的模块设计之初,开发者已定义好中间状态通信格式,具有统一的语义,无需第三方加以转化.针对上述3种类型消息,DrawerMPI所定义的Metadata采用平台相关消息层、通用报文头字段消息层、模块间中间状态交互消息层3层消息模型.
4.2 DrawerMPI语义转化模块设计
虽然模块具有相同语法的接口,即采用统一位宽的Metadata作为模块间,但通信消息仍存在语义不一致导致模块间不兼容的情况.例如,不同解析模块提取的目的MAC地址在Metadata中的位置不尽相同.先前的可重构流水线,例如FAST[33],采用统一语义的接口设计模式,即事先确定好Metadata信号每一位所代表的含义,以避免模块间语义的冲突.但我们在模块开发中发现,如果采用多流表匹配而非FAST的大流表匹配方式,不同流表之间存在中间状态的交互.例如,IP查表后产生下一跳地址,再根据下一跳地址查询目的MAC地址.而采用语义统一的Metadata不利于第三方功能模块的开发.例如,开发一种新的协议解析,我们需要先申请一片未使用的Metadta区域,并将该区域的定义通告给其他所有的开发者,这样会导致Metadata消息越发复杂.另外,统一语义的模块接口设计,还要求开发者事先了解Metadata的语义定义,已获取自己所需的关键字信息.并在不同模块所定义的Metadata存在语义冲突时,模块间无法共用.例如,负载均衡模块,QoS管理模块分别将某一相同字段定义为根据5-tuple计算的Hash值和ToS,则导致这2个模块无法在同一流水线中共存,如图4所示:

Fig 4 Different modules have semantic conflict in Metadata图4 不同功能模块在自定义区域存在语义冲突
我们在4.1节中对报文控制块进行了详细的分析,将其分为3类消息,其中只需要对通用报文头关键字段消息进行语义适配.因此,DrawerMPI在模块间增加语义转化模块,能够将上游模块所输出的控制块格式转化为下游模块输入的控制块格式.如图3(c)所示,语义转化模块是动态可配置的,根据相邻模块接口信号的语义,生成相应的格式转化命令并配置语义转化模块,实现控制块的适配功能.
语义转化模块使用多路选择器(在verilog中采用case语句实现多路选择器)完成Metadata格式转化功能,如图3(c)所示.我们发现所支持的Metadata格式转化粒度越细(例如,支持1 b的syn_tag语义转化),灵活性越高,但消耗的硬件资源也越多.为了在灵活性与资源开销得到较好的折中,我们选择8 b作为最小拼接单元.算法1描述了语义转化模块处理流程.
算法1. 模块间接口语义转化算法.
① procedureMetadataAdapter(Metadata,SelectCode)
②units←Segment(Metadata,8);
③ fori=0 to 15 do
④fieldIndex←SelectCode[i];
⑤unitsNew←units[fieldIndex];
⑥ end for
⑦Metadata←Assemble(unitsNew);
⑧ end procedure
为了增加模块接口语义描述的可读性,本文使采用XML描述模块接口的信号定义,并设计了编译器用于生成模块间语义转化规则.算法2描述了语义转发规则的生成算法.
算法2. 接口语义转化规则生成算法.
① procedureGenSelectCode(xmlPreModule,xmlNextModule)
②itemsPreModule←GetItems(xmlPreModule);
③itemsNextModule←GetItems(xmlNextModule);
④ for (nameNext,offsetNext) initemsNextModule
do
⑤ for (namePre,offsetPre) initemsPreModule
do
⑥ if (nameNext==namePre) then
⑦SelectCode[offsetNext8]←
offsetPre8;
⑧ end if
⑨ end for
⑩ end for
5 实验与测试
为了评估该模型的有效性、性能与资源开销,我们基于DrawerPipe模型在Netmagic[46](Altera FPGA, Arria Ⅱ)平台上实现了1.1节中提到的2种网络功能,即自定义转发、数据聚合功能.测试的网络拓扑如图1(b)(c)所示,由一台基于FPGA的网络设备通过网线连接多台外部主机,并在FPGA上实现了最基本的2层转发功能实现主机间的通信.由于NetMagic端口数量有限(4个千兆电口、4个千兆光口),本实验中使用电口组成了4台主机互联的简单拓扑.
我们利用Quartus 13.0(Altera综合工具)综合所编写的硬件代码,得到这2种网络功能所使用的一些关键功能模块及模块信息,包括模块的最大吞吐率、处理延时、硬件存储、逻辑资源开销等,如表2所示:
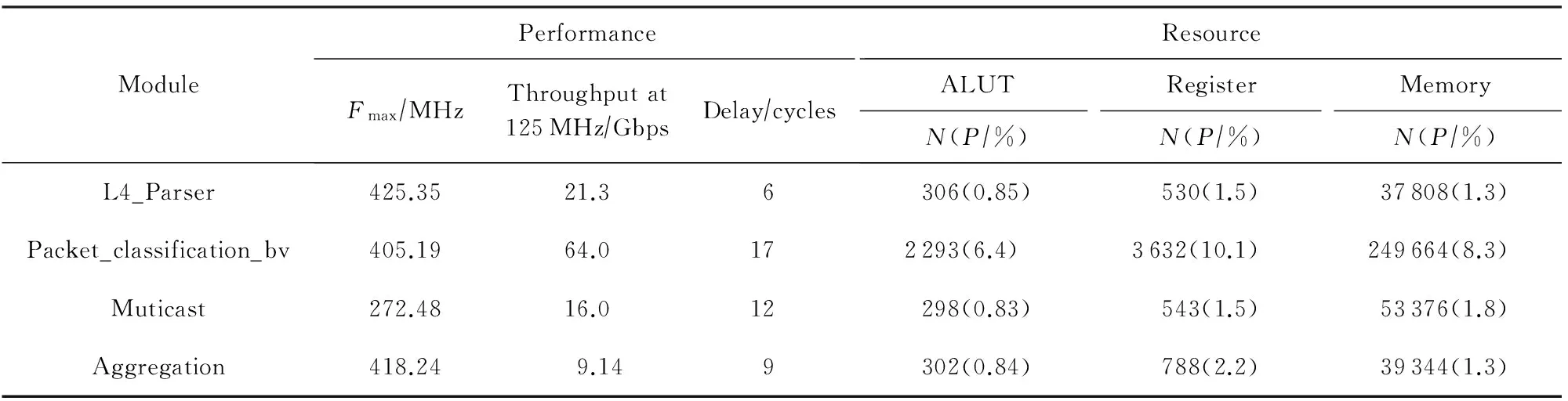
Table 2 Key Processing Modules Used by Two Network Functions Based on Altera Arria Ⅱ表2 基于Altera Arria Ⅱ构建2种功能网络功能所使用的关键功能模块
Notes:Fmaxmeans the maximal frequency;Nmeans the number of resources;Pmeans the percentage of utilization of per resource.
从表2可以发现DrawerPipe的模块化设计可以很大程度提高代码的重用,并简化新网络功能的构建.例如,这2种网络功能均使用了L4_Parser,以及基于BV的报文分类算法.
5.1 性能测试
5.1.1 自定义转发功能
我们基于DrawerPipe实现了自定义转发功能,所加载的模块依次为表2中的L4解析、基于BV的报文分类、自定义转发、报文修改、按端口转发的输出调度模块.其中,L4解析模块解析和提取五元组;报文分类模块根据五元组分类,识别需要多播的报文;功能相关模块根据分类结果查找目标主机簇地址,并构建相应的Metadata;为支持多播,需要在报文修改模块中根据Metadata重组并复制报文;最后输出调度模块根据端口转发报文.
为了验证基于DrawerPipe实现自定义转发功能的有效性,我们对比了加载自定义转发功能与未加载该功能2种通信方式.其中在未加载自定义转发功能时,测试主机需要与通信对端主机簇建立一对一连接.而基于DrawerPipe实现自定义转发功能,可以认为只需要与虚拟的主机簇地址建立一条连接.
在实验测试中,我们通过一台主机向多台主机发送相同数据.但受Netmagic端口数量的限制,最多测试1 to 4的情况.如图5所示,我们测试了传输不同大小数据所需的传输时间,即流完成时间(flow completion time, FCT).由于传输不同大小数据的流完成时间相差较大,我们采用归一化流完成时间(normalized FCT)指标来比较2种实现方式.其中,归一化流完成时间是指以部署自定义转发功能所需的流完成时间作为参考基数,即为“1”,其他测试结果为该流完成时间的倍数.分析实验结果可以发现,在传输的数据流较小时(≤10 KB),单播与自定义转发2种方式传输时间相差较小.这是因为主机整体所需要发送的报文数量较少(<10个),流完成时间中的绝大部分为传输延时.而在传输的数据流量较大时(≥1 MB),自定义传输方式能节省大量的传输时间,并且随着通信对端主机数量的增多,缩短的流完成时间也越多.

Fig. 5 FCT of custom forwarding with different data size图5 自定义转发功能在不同流大小下的传输时间
另外,为了验证基于DrawerPipe实现自定义转发功能的处理性能,我们将其与2台主机间之间互联(1 to 1 without custom forwarding)做了对比,两者在传输不同大小数据的流完成时间相当,说明基于DrawerPipe实现的自定义转发网络功能处理延时较低,并支持端口的线速处理.
5.1.2 数据聚合功能
数据聚合属于网内处理(in-network processing)功能.这类网络功能大多与具体的应用类型相关,对分组的处理往往涉及自定义算法.本实验选择了其中一种相对简单又具代表性的数据聚合功能,即将报文序列相同的报文聚合.这一网络功能可应用于数据中心某一虚拟机同时向多个服务发送的查询请求的场景,能够最快地获取服务响应.我们基于DrawerPipe实现该网络功能,只需要在自定义转发处理流水线中将自定义转发模块替换为数据聚合模块.报文分类模块的功能变为识别需要聚合的报文,只需要通过外部控制器配置规则即可.
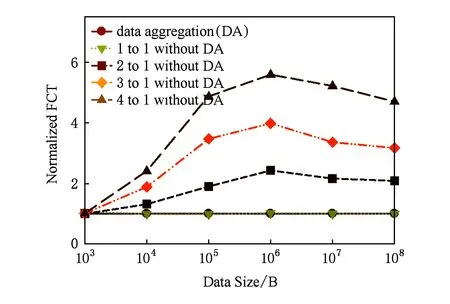
Fig. 6 FCT of data aggregations with different data size图6 数据聚合功能在不同流大小的传输时间
数据聚合功能的测试方式是多台主机同时向同一台主机发送数据报文,并在所有传输报文中携带特定的数据序列号(位于UDP报文负载中).可以预测到部署数据聚合功能的交换机会将不同主机所发送的相同序列号报文聚合,即每一个序号只有最新达到交换机的报文才会被送给目标主机.
为了验证网络功能的有效性,我们比较了部署数据聚合功能与传统未部署聚合功能在传输不同大小数据下的流完成时间,如图6所示.实验结果显示,在传输较小数据流时(≤10 KB),未部署数据聚合功能的流完成时间只是稍大;而在传输的数据增大时(100 KB~1 MB),流完成时间急剧上升.这是因为多台主机同时发送报文,交换机的队列溢出而发生丢包(即incast问题[30]),导致主机需要重传丢失的报文.在通信数据更大时,多个主机通过平分带宽避免拥塞,而流完成时间与通信主机数量相关.
同样,我们将其与2台主机间之间互联(1 to 1 without data aggregation)做了对比,以验证基于DrawerPipe实现自定义转发功能的处理性能.如图6所示,两者在不同数据大小下流完成时间相当,说明基于DrawerPipe实现的数据聚合功能处理延时较低,并同样支持端口的线速处理.
5.2 资源开销分析
我们利用Quartus 13.0(Altera综合工具)测试了DrawerPipe同时实现的2种功能网络功能所需的硬件资源开销,包括功能模块、Metadata Adapter以及平台相关资源开销3部分,如表3所示.平台相关部分大概占用了一半的硬件资源(35.8%~59.1%),功能模块的资源开销相对较小(11.9%~20.9%),Metadata Adapter的资源开销也相对较少(2.6%~3.5%).

Table 3 Resource Usage Comparation Based on Altera Arria Ⅱ表3 基于Altera Arria Ⅱ硬件资源开销对比
Notes:Nmeans the number of resources;Pmeans the percentage
of utilization of per resource.
6 总 结
本文提出了可重构分组处理流水线模型——DrawerPipe.DrawerPipe将网络功能抽象成通用的五级流水线模型,每一级实现某一类分组处理功能.通过为每一级流水线加载一个或者多个类似的功能模块快速重构所需的分组处理逻辑.采用模块重组的方式不仅具有良好的处理性能与高效的资源利用率,同时避免重新开发分组处理流水线,节省开发时间和成本.此外,本文还设计了一种功能无关的可编程模块接口模型——DrawerMPI.DrawerMPI采用语法一致的接口信号定义,而放宽对接口语义的定义,有利于提高模块复用.最后,我们为每一级流水线设置相应的功能模块库,方便用户从每一级模块库中选择并重构所需的处理逻辑.
下一步我们将研究基于DrawerPipe的可编程模型,即用户可以通过高级语言描述分支流水线架构,经编译器解析后从功能模块库中选择并组合适当的功能模块,从而更方便软件工程师参与FPGA的开发.
[1]Li Bojie, Tan Kun, Luo Layong, et al. Clicknp: Highly flexible and high-performance network processing with reconfigurable hardware[C]Proc of the 2016 Conf on ACM SIGCOMM. New York: ACM, 2016: 1-14
[2]Costa P, Migliavacca M, Pietzuch P, et al. NaaS: Network-as-a-service in the cloud[C]Proc of the USENIX Conf on Hot Topics in Management of Internet, Cloud, and Enterprise Networks and Services. Berkelely, CA: USENIX Association, 2012: 1-6
[3]Benson T, Akella A, Shaikh A, et al. CloudNaaS: A cloud networking platform for enterprise applications[C]Proc of the 2nd ACM Symp on Cloud Computing. New York: ACM, 2011: 8-16
[4]Sherry J, Hasan S, Scott C, et al. Making middleboxes someone else’s problem: Network processing as a cloud service[J]. ACM SIGCOMM Computer Communication Review, 2012, 42(4): 13-24
[5]Li Jie, Humphrey M, Van Ingen C, et al. eScience in the cloud: A MODIS satellite data reprojection and reduction pipeline in the windows Azure platform[C]Proc of the Int Symp on Parallel & Distributed Processing. Piscataway, NJ: IEEE, 2010: 367-376
[6]Koponen T, Amidon K, Balland P, et al. Network virtualization in multi-tenant datacenters[C]Proc of the 11th USENIX Conf on Networked Systems Design and Implementation. Berkelely, CA: USENIX Association, 2014: 203-216
[7]Martins J, Ahmed M, Raiciu C, et al. ClickOS and the art of network function virtualization[C]Proc of the 11th USENIX Conf on Networked Systems Design and Implementation. Berkelely, CA: USENIX Association, 2014: 459-473
[8]Bando M, Chao H J. FlashTrie: Hash-based prefix-compressed trie for IP route lookup beyond 100 Gbps[C]Proc of the 2010 IEEE Int Conf on Computer Communications(IEEE INFOCOM). Piscataway, NJ: IEEE, 2010: 821-829
[9]Gandhi R, Liu H H, Hu Y C, et al. Duet: Cloud scale load balancing with hardware and software[J]. ACM SIGCOMM Computer Communication Review, 2015, 45(4): 27-38
[10]Hong C Y, Caesar M, Godfrey P. Finishing flows quickly with preemptive scheduling[J]. ACM SIGCOMM Computer Communication Review, 2012, 42(4): 127-138
[11]Han S, Jang K, Park K S, et al. PacketShader: a GPU-accelerated software router[J]. ACM SIGCOMM Computer Communication Review, 2010, 40(4): 195-206
[12]Song Haoyu. Protocol-oblivious forwarding: Unleash the power of SDN through a future-proof forwarding plane[C]Proc of the 2nd ACM SIGCOMM Workshop on Hot Topics in Software Defined Networking. New York: ACM, 2013: 127-132
[13]Rubow E, Mcgeer R, Mogul J, et al. Chimpp: A click-based programming and simulation environment for reconfigurable networking hardware[C]Proc of the Symp on Architecture for Networking & Communications Systems (ANCS). Piscataway, NJ: IEEE, 2010: 421-430
[14]Caulfield A M, Chung E S, Putnam A, et al. A cloud-scale acceleration architecture[C]Proc of the 49th Annual IEEEACM Int Symp on Microarchitecture (MICRO). Piscataway, NJ: IEEE, 2016: 75-87
[15]Jackson K R, Ramakrishnan L, Muriki K, et al. Performance analysis of high performance computing applications on the Amazon Web services cloud[C]Proc of the 2nd Int Conf on Cloud Computing Technology and Science. Piscataway, NJ: IEEE, 2011: 159-168
[16]Ouyang Jian, Lin Shiding, Qi Wei, et al. SDA: Software-defined accelerator for large-scale DNN systems[C]Proc of the 26th Hot Chips Symp (HCS). Piscataway, NJ: IEEE, 2014: 1-23
[17]Xilinx. SDNet development environment[EBOL]. [2017-12-04]. http:www.xilinx.comproductsdesign-toolssoftware-zonesdnet.html
[18]Sultana N, Galea S, Greaves D, et al. Emu: Rapid prototyping of networking services[C]Proc of the 2017 USENIX Annual Technical Conf. Berkelely, CA: USENIX Association, 2017: 459-471
[19]Intel. Intel FPGA SDK for OpenCL[EBOL]. [2017-12-04]. https:www.altera.com.cncontentdamaltera-wwwglobalen_USpdfsliteraturehbopencl-sdkaocl_programming_guide.pdf
[20]Dang V, Skadron K. Acceleration of frequent itemset mining on FPGA using SDAccel and Vivado HLS[C]Proc of the 28th Int Conf on Application-Specific Systems, Architectures and Processors (ASAP). Piscataway, NJ: IEEE, 2017: 195-200
[21]Bosshart P, Daly D, Gibb G, et al. P4: Programming protocol-independent packet processors[J]. ACM SIGCOMM Computer Communication Review, 2014, 44(3): 87-95
[22]Wang H, Soulé R, Dang H T, et al. P4FPGA: A rapid prototyping framework for P4[C]Proc of the Symp on SDN Research. New York: ACM, 2017: 122-135
[23]Bosshart P, Gibb G, Kim H S, et al. Forwarding metamorphosis: Fast programmable match-action processing in hardware for SDN[J]. ACM SIGCOMM Computer Communication Review, 2013, 43(4): 99-110
[24]Jose L, Yan L, Varghese G, et al. Compiling packet programs to reconfigurable switches[C]Proc of the 12th USENIX Conf on Networked Systems Design and Implementation. Berkelely, CA: USENIX Association, 2015: 103-115
[25]Rinta-Aho T, Karlstedt M, Desai M P. The Click2NetFPGA Toolchain[C]Proc of the 2012 USENIX Annual Technical Conf. Berkelely, CA: USENIX Association, 2012: 77-88
[26]Zhu Yibo, Kang Nanxi, Cao Jiaxin, et al. Packet-level telemetry in large datacenter networks[J]. ACM SIGCOMM Computer Communication Review, 2015, 45(4): 479-491
[27]Vigfusson Y, Abu-Libdeh H, Balakrishnan M, et al. Dr. multicast: Rx for data center communication scalability[C]Proc of the 5th European Conf on Computer Systems. New York: ACM, 2010: 349-362
[28]Dean J, Ghemawat S. MapReduce: Simplified data processing on large clusters[C]Proc of the 6th Conf on Symp on Opearting Systems Design & Implementation. Berkelely, CA: USENIX Association, 2004: 137-150
[29]Alizadeh M, Yang S, Sharif M, et al. pfabric: Minimal near-optimal datacenter transport[J]. ACM SIGCOMM Computer Communication Review, 2013, 43(4): 435-446
[30]Alizadeh M, Greenberg A, Maltz D A, et al. Data center TCP (DCTCP)[J]. ACM SIGCOMM Computer Communication Review, 2010, 40(4): 63-74
[31]Kohler E, Morris R, Chen Benjie, et al. The Click modular router[J]. ACM Trans on Computer Systems, 2000, 18(3): 263-297
[32]Anwer M B, Motiwala M, Tariq M B, et al. SwitchBlade: A platform for rapid deployment of network protocols on programmable hardware[J]. ACM SIGCOMM Computer Communication Review, 2010, 40(4): 183-194
[33]FAST. FPGA bAsed SDN swiTch[EBOL]. [2017-12-04]. http:fast-switch.github.io
[34]Sun Chen, Bi Jun, Zheng Zhilong, et al. NFP: Enabling network function parallelism in NFV[C]Proc of the Conf of the ACM Special Interest Group on Data Communication. New York: ACM, 2017: 43-56
[35]Zhu Shuyong, Bi Jun, Sun Chen, et al. SDPA: Enhancing stateful forwarding for software-defined networking[C]Proc of the 23rd Int Conf on Network Protocols (ICNP). Piscataway, NJ: IEEE, 2015: 323-333
[36]Vallentin M, Sommer R, Lee J, et al. The NIDS cluster: Scalable, stateful network intrusion detection on commodity hardware[C]Proc of Int Workshop on Recent Advances in Intrusion Detection. Berlin: Springer, 2007: 107-126
[37]Cisco. Introduce to virtual overlay technologies: Virtual extensible LAN (Vxlan) enhancements and VXLAN gateway[EBOL]. [2017-12-04]. https:learningnetwork.cisco.comdocsDOC-32654?dtid=osscdc000283
[38]Hopps C E. Analysis of an equal-cost multipath algorithm[J]. Journal of Allergy & Clinical Immunology, 2000, 109(1): 265-296
[39]Reese W. Nginx: The high-performance Web server and reverse proxy[J]. Linux Journal, 2008 (173): 2-10
[40]Liu J, Li Yue, Vorst N V, et al. A real-time network simulation infrastructure based on OpenVPN[J]. Journal of Systems & Software, 2009, 82(3): 473-485
[41]Shin S, Yegneswaran V, Porras P, et al. AVANT-GUARD: Scalable and vigilant switch flow management in software-defined networks[C]Proc of the 2013 ACM SIGSAC Conf on Computer & Communications Security. New York: ACM, 2013: 413-424
[42]Barr K C. Energy-aware lossless data compression[J]. ACM Trans on Computer Systems, 2006, 24(3): 250-291
[43]Seddiki M S, Shahbaz M, Donovan S, et al. FlowQoS: QoS for the rest of us[C]Proc of the Workshop on Hot Topics in Software Defined NETWORKING. New York: ACM, 2014: 207-208
[44]Sivaraman V, Narayana S, Rottenstreich O, et al. Heavy-hitter detection entirely in the data plane[C]Proc of the Symp on SDN Research. New York: ACM, 2017: 164-176
[45]Ganegedara T, Prasanna V K. StrideBV: Single chip 400G+ packet classification[C]Proc of the Int Conf on High Performance Switching and Routing. Piscataway, NJ: IEEE, 2012: 1-6
[46]Li Tao, Sun Zhigang, Jia Chunbo, et al. Using NetMagic to observe fine-grained per-flow latency measurements[J]. ACM SIGCOMM Computer Communication Review, 2011, 41(4): 466-467

LiJunnan, born in 1992. PhD candidate at National University of Defense Technology. His main research interests include packet processing on FPGA, network function acceleration.

YangXiangrui, born in 1993. Master candidate at National University of Defense Technology. His main research interests include SDN, network security, network function virtualization.

猜你喜欢
汽车电器(2022年9期)2022-11-07
电子技术与软件工程(2022年11期)2022-09-09
电子制作(2019年19期)2019-11-23
中国外汇(2019年11期)2019-08-27
永善文学(2017年1期)2017-07-18
中国信息技术教育(2017年11期)2017-07-01
中国广播(2016年11期)2016-12-26
软件导刊(2016年9期)2016-11-07
电脑知识与技术(2016年21期)2016-10-18
汽车维修与保养(2014年12期)2014-04-18
