
基于KPCA和投影字典对学习的人脸识别算法①
2018-05-17 06:47邓道举李秀梅
计算机系统应用 2018年5期
邓道举,李秀梅
(杭州师范大学 信息科学与工程学院,杭州 311121)
当前,稀疏表达理论在图像识别中越来越受到人们关注[1,2].2009 年,Wright等人提出了基于稀疏表达分类SRC的人脸识别方法[3],稀疏表达是利用字典中的原子线性表示信号的一种方法,它通过稀疏编码和重构分类两步来解决识别问题.2013年,张磊等人提出了基于联合表达分类CRC的识别方法[4].研究指出,在SRC方法中对识别率的贡献起到关键性作用的并非求稀疏约束的L1范数最小化算法,而是联合表达.在保证识别率的前提下,为了提高识别速度,引入了正则化最小平方法替代原SRC方法中的L1范数最小化算法.其中,字典在稀疏表达和联合表达中具有重要作用,分析字典[5]和综合字典[5]是最常用的字典.分析字典能快速实现稀疏编码,但不能有效表达复杂的局部信息.综合字典能有效表达复杂局部信息,实现完美重构,但稀疏编码速度较慢.
字典学习是设计或构造字典[6,7]的一种重要方法.常用的字典学习算法有最优方向法、K-SVD算法等[8].Yang等人提出了Metaface字典学习算法MFL[9]和线性判别字典学习算法FDDL[10],MFL和FDDL算法与K-SVD相比具有更强的表达能力.然而,MFL算法和FDDL算法利用综合字典学习速度慢,不能实现大样本快速识别任务.
主成分分析PCA[11]在数据分析和模式识别中,通过计算数据的协方差矩阵来处理数据,而协方差矩阵属于二阶统计特性,并未涉及到高阶统计特性,因此做PCA变换后数据还会有高阶冗余信息存在.此外,PCA只分析了数据间相关性,未对非相关性做分析.因此,PCA一般适用于线性数据和线性可分情况,而对于非线性数据和线性不可分问题,PCA往往满足不了解决问题的需要.为了解决非线性问题,A Smola 等人提出了核主成分分析KPCA算法[12],运用核方法,通过非线性映射将数据变换到某个高维特征空间后再做PCA分析.
本文提出了一种基于KPCA与DPL相结合的字典学习算法,即 K-DPL 算法.该算法利用核技术,将数据样本映射到高维空间(特征空间)以解决非线性问题,再进行DPL训练,得到更具有判别性的字典以提高识别率和识别速度.最后针对ORL、扩展YaleB、AR人脸库,对本文提出的识别方法进行性能分析与比较.
本文的其它部分安排如下: 第1节介绍了KPCA算法的主要实现过程和流形学习方法,第2节介绍了传统字典学习模型与投影字典对学习DPL算法,第3节提出了将KPCA与DPL相结合的K-DPL算法,并介绍了及其实现步骤,第4节设计实验进行了仿真验证,第5节进行了总结.
1 KPCA 算法
1.1 KPCA算法的主要过程
在人脸识别中,假设: 每张人脸图像是大小为的灰度矩阵,样本数为N.将每张人脸图像按列首尾连接拉成维数为d的列向量,则整个样本集X表示为大小为其中第i张人脸图像记为
定义一个映射其中将样本映射到维数为D的高维空间中.将人脸图像映射到该空间,得中心化后的样本数据满足设C表示中心化的样本数据协方差矩阵,那么,从而得式 (1):

其中分别表示C的特征值和对应的特征向量,并且可以证明: 任意一个特征向量均可由张成的空间线性表示,即,存在常系数满足式(2):

将式(1)等号两边同时左乘将式(2)带入(1)中,得式 (3):

将等式(3)两边同时进行化简,得式(4):
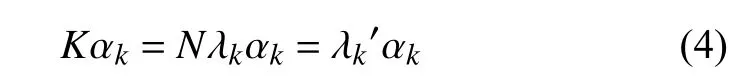
其中,表示中心化的核矩阵,也称为核函数,表示核函数K的第k个特征向量,表示K的特征值.
最后,根据K与C的特征值和特征向量关系式(5):

即可求出C的特征值和特征向量.
1.2 核函数类型
根据核函数的性质,可以划分为如下4种常用类型:
(1) 线性核函数:
(2) 高斯核函数:

(3) 多项式核函数:

(4) Sigmoid 核函数:

其中,为各核函数对应的参数,可以根据不同的问题和数据选择上述核函数并调整这些参数,从而在模式识别等问题中达到最佳的模型.具体核函数及参数的选择往往依据多次实验的效果来确定和调整.针对后文提出的算法,为了达到最佳识别表现,实验时本文将分别选择线性核、高斯核与多项式核作为核函数.
1.3 流形学习
KPCA是将低维空间数据映射到高维空间后进行PCA降维的特征提取方法.它能够提取出一些线性不可分的信息,便于后续的识别分类.流形学习[13,14]也是特征降维的一类方法,它将高维的数据映射到低维,使该低维的数据能够反映原高维数据的某些本质结构特征,这些高维数据实际上是一种低维的流形结构嵌入在高维空间中.它分为线性和非线性两种.其中,线性流形学习包括PCA与多维尺度变换MDS[15].与KPCA的作用类似,非线性流形学习也属于非线性降维方式,其代表性方法有局部线性嵌入LLE[16]、等距映射Isomap[17]、拉普拉斯特征映射LE[18]等.上述方法在运用中已经取得了一些不错的效果.然而,在人脸识别中还存在许多方法不收敛、采样密度与采样方式选择以及降低维数不确定等问题,这些问题都会对最终的识别准确性和识别速度产生较大影响.
2 投影字典对学习算法
2.1 传统字典学习模型
传统的字典学习算法是运用稀疏表达对过完备字典学习一个综合字典,而稀疏表达涉及稀疏系数或稀疏矩阵的求解.其模型描述如下.
假设有K类训练样本,每个样本的维数为d,整个训练样本集其中表示第i类训练样本子集,n为每类样本数.则大多数传统字典模型框架为:
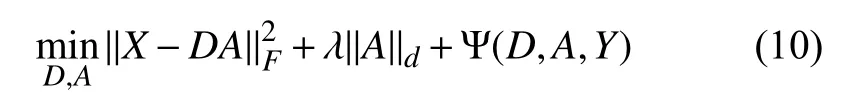
然而,利用L0或L1范数最小化求解具有判别性的编码稀疏矩阵A的方法的时间代价很高,在识别问题中,不能满足快速识别的要求.针对这一问题,Gu 等人提出了一种新的字典学习模型——投影字典对学习DPL[19].
2.2 投影字典对学习DPL
假设可以找到某个分析字典使得编码A可通过分析得到,那么,X的表达会变得非常高效.基于这一思想,通过同时学习分析字典Q和综合字典D,得到DPL的模型如下[19]:


其中为标量为整个训练集X中去除后部分为综合字典D的第i个原子.
3 基于KPCA的投影字典对学习算法K-DPL
由KPCA算法的原理可知,KPCA算法首先通过非线性映射将线性不可分的样本投影到某个高维空间,使得样本线性可分,然后再对该空间内的样本进行PCA分析.而人脸图像的某些信息是线性不可分的,比如某些局部纹理信息.通常,提取到的信息越好往往越有利于后续的识别工作.因此,单纯地利用PCA来对人脸图像分析往往未能对图像的线性不可分类的信息进行分析,从而影响识别效果.而DPL算法打破了传统字典学习算法对稀疏表达的依赖,不仅提高了识别率,识别速度更是大幅提升.基于这两方面,为了进一步提高DPL的识别性能,本文提出了一种将KPCA与DPL相结合的算法,即K-DPL.
3.1 K-DPL算法

算法.K-DPL 算法

输入: 对训练人脸样本进行K P C A特征提取,得到降维后的K类训练样本 选择测试人脸样本y,分别设定参数λ、τ、m、γ输出: 分析字典 Q,综合字典 D① 固定 Q和 D,更新A:A∗=a r g m i n A =1∥X k−D k A k∥2 F+τ∥Q k X k−A k∥2 F∑K k (1 3)可将上式最小二乘问题转化为下式求解:A∗k=(D T k D k+τ I)−1(τ Q k X k+D T k X k) (1 4)② 固定 A,更新 Q和 D:?Q的解可通过下式获得:Q∗k=τ A k X T k(τ X k X T k+λ X′k X′T k+γ I)−1.(1 7)其中,γ为一个很小的常数.从第1类到第K类,利用式(1 4)、(1 7)、(1 6)分别更新 、 、A(t)k Q(t)k.D(t)k i d e n t i t y(y)=a r g m i n ③ 判定: ,当相邻两次迭代结果差值小于某个阈值,则循环结束,输出判定结果; 反之, ,返回上一步.i ∥y−D i Q i y∥2 t=t+1
4 实验
本实验分为三部分: 第一部分是将DPL算法与MFL、SRC、CRC、FDDL算法进行比较,验证DPL的有效性和优越性; 第二部分是将本文提出的KDPL与DPL、PCA降维后的DPL进行比较,分析KDPL的识别性能; 第三部分是验证K-DPL对有光照变化和遮挡的人脸识别的有效性.第一、二部分在ORL人脸库上测试.第一部分实验选择每一类样本中前5个人脸图片作为训练样本,后5个人脸图片作为测试样本.第二部分实验分别设置训练比例为0.1、0.3、0.5、0.7进行实验.第三部分在扩展YaleB人脸库和 AR 人脸库上测试.实验环境为: Matlab 2015b,Intel i3-2350M 2.30 GHz,6 G 内存.
ORL人脸库中共有40个人的正面照,每个人有10张大小均为112×92像素的灰度图片,每张图片的主要区别在于表情和姿势的变化.ORL人脸库的部分图像如图1所示.
扩展YaleB人脸库中共有38个人的正面照,包含9种姿势下的64种不同光照变化.扩展YaleB人脸库的部分图像如图2所示.

图1 ORL 人脸库部分图像

图2 扩展 YaleB 人脸库部分图像
AR人脸库中共有126个人的正面照,总计有4000 张.选取其中 50 名男性,50 名女性作为样本.每人有26张大小均为165×120像素的灰度图片,每张图片的主要区别在于光照变化、墨镜和围巾遮挡.AR人脸库的部分图像如图3所示.

图3 AR 人脸库部分图像
4.1 DPL与MFL、SRC、CRC、FDDL算法比较
本实验首先将ORL人脸库中每张训练样本和测试样本照片按照像素拉成10 304×1的向量,然后下采样至1024×1的列向量,得到处理后的训练样本和测试样本进行实验分析.为了达到最好的识别效果,实验参数设置为:迭代次数为20次.为了降低识别引入的误差,每组实验进行5次实验,取其平均识别率和时间.实验结果如表1所示.

表1 在 ORL 库上的识别结果比较
由表1可知,在ORL库上,DPL算法实现人脸识别相比表中其他算法的识别率具有很大竞争力,而且,相比MFL、FDDL等利用稀疏编码求解训练字典的算法,DPL具有训练速度快,测试耗时短的优点.
4.2 K-DPL算法与DPL、P-DPL比对
4.2.1 ORL 人脸库上的实验与分析
为了提高DPL算法的识别率和识别速度,验证本文提出的K-DPL算法的有效性和优越性,将KDPL与DPL、PCA降维后的DPL进行比较,分别在训练比例为0.1、0.3、0.5、0.7的ORL人脸库上进行,表示为: ORL(1)、ORL(3)、ORL(5)、ORL(7),其中括号里的数表示训练样本数.每种训练比例下均进行5次实验取平均识别率和识别时间.这里K-DPL算法的核函数选择线性核函数,而将PCA降维后的DPL表示为 P-DPL.实验参数设置为:取每个库的训练样本数.ORL(1)库上核函数选择的是线性核函数,核函数的参数其他库上核函数选择多项式核函数,核函数的参数迭代次数在 ORL(1)、ORL(3)、ORL(5)、ORL(7)库上分别为8、4、3、2.实验所得识别率如表2所示.

表2 不同训练比例下识别率 (%)
识别所需训练时间和测试时间分别如表3.

表3 不同训练比例下训练时间和测试时间比较(s)
由表3可知,本文提出的K-DPL算法训练和测试的速度比DPL算法的大约快20倍,和P-DPL相当.而在不同训练比例下,K-DPL的识别率均高于DPL和PDPL.因此,本文提出的K-DPL算法进一步提升了DPL算法的识别速度和识别率.训练字典的效果图如图4所示.

图4 训练字典的效果图
4.3 扩展YaleB和AR人脸库上的实验与分析
实验所用扩展YaleB人脸库大小为504×2414,整个训练样本大小为504×1216,整个测试样本大小为504×1198.这里所用扩展YaleB人脸库为Jiang博士所提供,下载网址为: http://www.umiacs.umd.edu/ ~zhuolin/projectlcksvd.html.实验中,设置参数如下:核函数选择的是高斯核函数,核函数的参数设置为迭代次数为20.AR人脸库上的实验,首先将AR库裁剪为大小504×2600样本数据,再将其为训练和测试两部分.其中每类训练样本20个,测试样本6个.整个训练样本大小为 504×2000,整个测试样本大小为 504×600,实验参数设置为:核函数选择的是高斯核函数,核函数的参数设置为迭代次数为20.得到每种算法的最高识别率,实验结果如表4和5所示.
从表4和表5可见,在扩展YaleB人脸库上,本文提出的K-DPL算法相比DPL算法提高了0.3%,识别速度较DPL、P-DPL更有竞争力; 而在AR人脸库上,K-DPL算法相比DPL提高了0.4%,识别速度介于DPL和P-DPL之间.综合来看,本文提出的K-DPL算法能够对有光照变化和遮挡的人脸进行有效识别,且相比DPL算法具有更强的识别能力.

表4 在扩展 YaleB 库上的识别结果比较

表5 在 AR 库上的识别结果比较
5 结论
本文比较了DPL算法与MFL、SRC、CRC、FDDL等算法的性能,并提出了一种改进投影字典对学习算法K-DPL,将KPCA与DPL相结合,从而取得了比DPL算法更好的识别性能.并在ORL人脸库、扩展YaleB人脸库、AR人脸库上验证了K-DPL算法的优越性.实验结果表明,K-DPL算法在样本数据量较小的ORL人脸库上的识别速度提高了约20倍,识别率也得到较好地提高; 而在对有光照变化和遮挡的人脸库上,K-DPL相比DPL表现出更高的识别率,且具有更快的识别速度,对光照和遮挡具有较强的鲁棒性.
参考文献
1杨荣根,任明武,杨静宇.基于稀疏表示的人脸识别方法.计算机科学,2010,37(9): 267–269,278.
2邓承志.图像稀疏表示理论及其应用研究[博士学位论文].长沙: 华中科技大学,2008.
3Wright J,Yang AY,Ganesh A,et al.Robust face recognition via sparse representation.IEEE Transactions on Pattern Analysis and Machine Intelligence,2009,31(2): 210 –227.[doi: 10.1109/TPAMI.2008.79]
4Zhang L,Yang M,Feng XC.Sparse representation or collaborative representation: Which helps face recognition?Proceedings of 2011 IEEE International Conference on Computer Vision (ICCV).Barcelona,Spain.2011.471–478.
5练秋生,石保顺,陈书贞.字典学习模型、算法及其应用研究进展.自动化学报,2015,41(2): 240–260.
6Pham DS,Venkatesh S.Joint learning and dictionary construction for pattern recognition.Proceedings of 2008 IEEE Conference on Computer Vision and Pattern Recognition.Anchorage,AK,USA.2008.1–8.
7Dorr BJ.Large-scale dictionary construction for foreign language tutoring and interlingual machine translation.Machine Translation,1997,12(4): 271 –322.[doi: 10.1023/A:1007965530302]
8Aharon M,Elad M,Bruckstein A.rmK-SVD: An algorithm for designing overcomplete dictionaries for sparse representation.IEEE Transactions on Signal Processing,2006,54(11): 4311–4322.[doi: 10.1109/TSP.2006.881199]
9Yang M,Zhang L,Yang J,et al.Metaface learning for sparse representation based face recognition.Proceedings of the 17th International Conference on Image Processing (ICIP).Hong Kong,China.2010.1601–1604.
10Yang M,Zhang L,Feng XC,et al.Fisher discrimination dictionary learning for sparse representation.Proceedings of 2011 IEEE International Conference on Computer Vision(ICCV).Barcelona,Spain.2011.543–550.
11Turk M,Pentland A.Eigenfaces for recognition.Journal of Cognitive Neuroscience,1991,3(1): 71 –86.[doi: 10.1162/jocn.1991.3.1.71]
12Schölkopf B,Smola A J,Müller KR,et al.Kernel principal component analysis.Proceedings of the 7th International Conference on Artificial Neural Networks.Lausanne,Switzerland.1997.583–588.
13徐蓉,姜峰,姚鸿勋.流形学习概述.智能系统学报,2006,1(1): 44–51.
14Ding M,Fan GL.Multilayer joint gait-pose manifolds for human gait motion modeling.IEEE Transactions on Cybernetics,2015,45(11): 2413 –2424.[doi: 10.1109/TCYB.2014.2373393]
15Kruskal JB.Nonmetric multidimensional scaling: A numerical method.Psychometrika,1964,29(2): 115–129.[doi: 10.1007/BF02289694]
16Roweis ST,Saul LK.Nonlinear dimensionality reduction by locally linear embedding.Science,2000,290(5500):2323–2326.[doi: 10.1126/science.290.5500.2323]
17Tenenbaum JB,de Silva V,Langford JC.A global geometric framework for nonlinear dimensionality reduction.Science,2000,290(5500): 2319–2323.[doi: 10.1126/science.290.5500.2319]
18Belkin M,Niyogi P.Laplacian eigenmaps for dimensionality reduction and data representation.Neural Computation,2003,15(6): 1373–1396.[doi: 10.1162/0899766033217 80317]
19Gu SH,Zhang L,Zou WM,et al.Projective dictionary pair learning for pattern classification.Proceedings of the 27th International Conference on Neural Information Processing Systems.Montreal,Canada.2014.793–801.
猜你喜欢
科技创新与应用(2020年6期)2020-02-29
小学阅读指南·低年级版(2019年11期)2019-07-01
小天使·一年级语数英综合(2017年11期)2017-12-05
中国高新技术企业(2017年5期)2017-05-05
软件(2016年6期)2017-02-06
物联网技术(2016年11期)2017-01-12
现代电子技术(2016年23期)2017-01-12
北京理工大学学报(2016年6期)2016-11-22
电脑知识与技术(2016年24期)2016-11-14
读者(2016年14期)2016-06-29
