
基于非结构网格隐式算法的GPU加速研究①
2018-05-17 06:48徐添豪田书玲
计算机系统应用 2018年5期
陈 龙,徐添豪,田书玲
(南京航空航天大学 航空宇航学院,南京 210016)
近年来,图形处理器(GPU)在科学计算领域中发挥了重要的作用.由于其出色的浮点运算性能以及具有优势的显存带宽,GPU往往能给科学计算带来可观的加速.计算流体力学(CFD)领域的GPU加速已得到广泛的研究,Hagen等人[1,2]先后在GPU上实现了基于欧拉方程以及基于NS方程的求解器,得到了良好的加速效果.随着GPU硬件自身的发展,更复杂的算法得到了实现,基于RANS方程、LES方法以及DNS方法的国内外先进研究成果不断被发表[3–7].为了进一步地提高运算能力,基于多GPU的实现也得到了越来越多的关注[8].刘枫等人[9]基于MPI+CUDA的异构并行可压缩流求解器,用于高超声速流动的数值模拟计算效率较CPU同构并行计算提高10倍以上.采用GPU加速的CFD算法在航空航天工程中具有广阔应用前景.
CFD算法GPU加速目前的研究前沿主要集中在结构网格和显式时间推进.非结构网格相比于结构网格更适用于复杂的几何外形,但由于其存储结构的特点难其内存存取的连续性较差,在GPU架构上难以获得很高的效率.同时,以LU-SGS算法为代表的隐式方法具有较显式方法高数倍的计算效率,但其每次迭代过程中多次需要相邻单元数据,需要大量的内存访问,在GPU架构上需要较好的数据局部性才能得到较高的效率,因此通常非结构网格的隐式算法在GPU上的加速效果不佳.
针对这一问题,本文发展了LU-SGS算法在非结构网格上的高效率的GPU实现方法.首先,介绍了基本控制方程和LU-SGS算法.然后,给出了算法的GPU实现方法.并采用RCM以及基于Metis网格分区的网格重排序方法优化算法的加速效果,详细讨论各网格排序算法在GPU实现中的适用性.最后,通过算例验证了算法的正确性以及实现方案的高效性.
1 数值方法
惯性系下,忽略源项的RANS方程形式如下:

其中W,F,G分别代表守恒变量、对流通量及粘性通量.本文采用非结构网格下格点格式离散有限体积控制体,使用Roe格式离散对流通量.通过线性重构实现空间二阶精度.使用收敛性良好的Venkatakrishnan限制器.采用隐式LU-SGS方法进行时间推进,其形式如下[10]

其中,U,L和D分别为严格上三角矩阵,严格下三角矩阵和对角矩阵.
采用向前扫掠和向后扫掠求解该方程,过程可以写成:
向前扫掠:

向后扫掠:

该方法最早由Jameson和Yoon[11]应用于结构网格,在扫掠时确定超平面,如图1.同一超平面内的控制体可以同步更新而不存在相互的依赖,这也为计算的数据并行提供了理论基础.后Nakahashi等人[12]将其应用到非结构网格上,扫掠时也需要确定类似形式的超平面,如图2.

图1 结构网格上的超平面形式

图2 非结构网格上的超平面形式
湍流模型选用Spalart-Allmaras一方程模型[13].该模型广泛应用于飞机机翼、翼身组合体等绕流的数值模拟中.
2 算法 GPU 并行加速
2.1 GPU并行方法
单个GPU,从硬件上来说,由多个流多处理器SM组成.每个SM可以同时处理上千个线程.在英伟达公司提出的CUDA框架下,线程以32为一束进行调度,即同一线程束(Warp)内的线程在同一时间执行相同的指令,这也对应着并行的最细粒度.而若干个Warp又组成线程块(Block)被分发到不同SM上执行.每个计算任务会对应一个线程网格(Grid)进行线程组织,而一个Grid是由多个Block组成的.从Grid到Block到Thread都可以在编程时进行一维、二维乃至三维的索引,如图3所示.
运行于GPU上的并行程序是基于数据并行的,每个线程执行相同的任务,程序员也无需过多地关心线程的调度方式,它由 GPU 自行处理.因此,在 CFD 领域内,涉及大量数据并行的CPU程序很容易移植到GPU上.在传统的CPU求解器中,非结构网格结合格点格式会涉及两种形式的循环,即基于点的和基于边的.对于这样两种循环,我们在GPU上最为直接地将单个点或者单条边映射到单个线程上,而每个线程则执行原来循环体内的指令.

图3 线程、线程块、线程块网络的组织形式

可以写成对应的由CPU调用、GPU执行的函数(Kernel函数)的形式

代码区域则几乎相同,这为快速的代码移植提供了相当的便捷性.可见GPU的细粒度并行方式通常与CPU上的多线程、多进程实现的任务并行不同(将单个任务拆分成多个子任务).当然在单个或者多个GPU上进行类似于CPU的任务并行也是实现大规模GPU运算的必要手段.
2.2 算法的GPU实现
涉及算法在GPU上的流程图如图4.
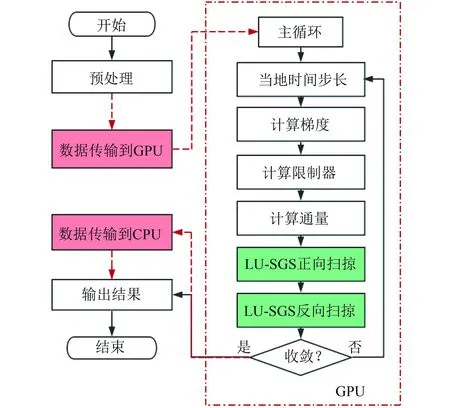
图4 CPU 及 GPU 算法流程图
GPU流程与CPU上的实现几乎完全相同.在GPU上进行计算的前后,需要将数据拷贝到GPU上或者从GPU拷贝回CPU,但是所有的求解过程是在GPU上进行的,如图中红色虚线框.可以认为GPU上实现的每一个步骤对应一个Kernel函数.不同的是,LU-SGS向前、向后扫掠步骤中涉及了数百甚至上千个Kernel函数(与超平面个数有关).LU-SGS算法本身就适合于进行超平面内的数据并行.而进行扫掠的时候,下一个超平面内的变量依赖于更新过后的当前面内的变量.因此,可以采用每一层对应一个Kernel函数,而这些Kernel函数串行执行来实现对应语义.
2.3 性能优化
对应于上述流程图的实现并不一定立即获得显著的加速比.GPU上程序的性能优化需要更多地关注硬件底层.通常认为会有基于硬件利用率、内存以及指令三个层面的优化方法.在进行了基本的包括上述三个层面的常见优化[14]后,本文着重关注非结构网格下全局内存访问效率的提升,属于内存层面的深度优化.
全局内存访问的优化关键在于合并访问.合并访问指的是同一个Warp内的Thread访问全局内存时,内存访问指令可以合并成若干个32、64或者128字节的内存读取指令.当相邻Thread内存访问可以合并时,说明其访问的内存在地址上是连续的.一般在结构网格下,合理安排数据形式就能实现合并的内存访问,采用 SoA(Structure of Array)而不是CPU实现常用的AoS(Array of Structure)形式,如守恒变量安排如图5所示.

图5 SoA 和 AoS 内存组织方式对比
在非结构网格中,根据本文使用的Thread映射方式,连续的Thread对应连续的边,但是每条边需要访问它相连的左右节点,而左右节点由于非结构网格的不规则性,在内存上却是不连续的.得益于GK110核心对应的 L2 Cache 以及 Read-only Data Cache,对于内存连续性的要求并没有之前的硬件那么高,不再需要保证完全按照顺序在地址上连续,仅需保证有良好的数据局部性 (Data Locality).因此,本文采用对网格重排序的方法来改善基于非结构网格的内存合并访问性能.
考虑由边描述的节点连接关系的邻接关系矩阵(nNodes×nNodes),可以通过 RCM(Reverse Cuthill-McKee algorithm)排序[14]来减小该稀疏矩阵带宽,也意味着空间中邻近的点在内存上也是邻近的,效果如图6所示.
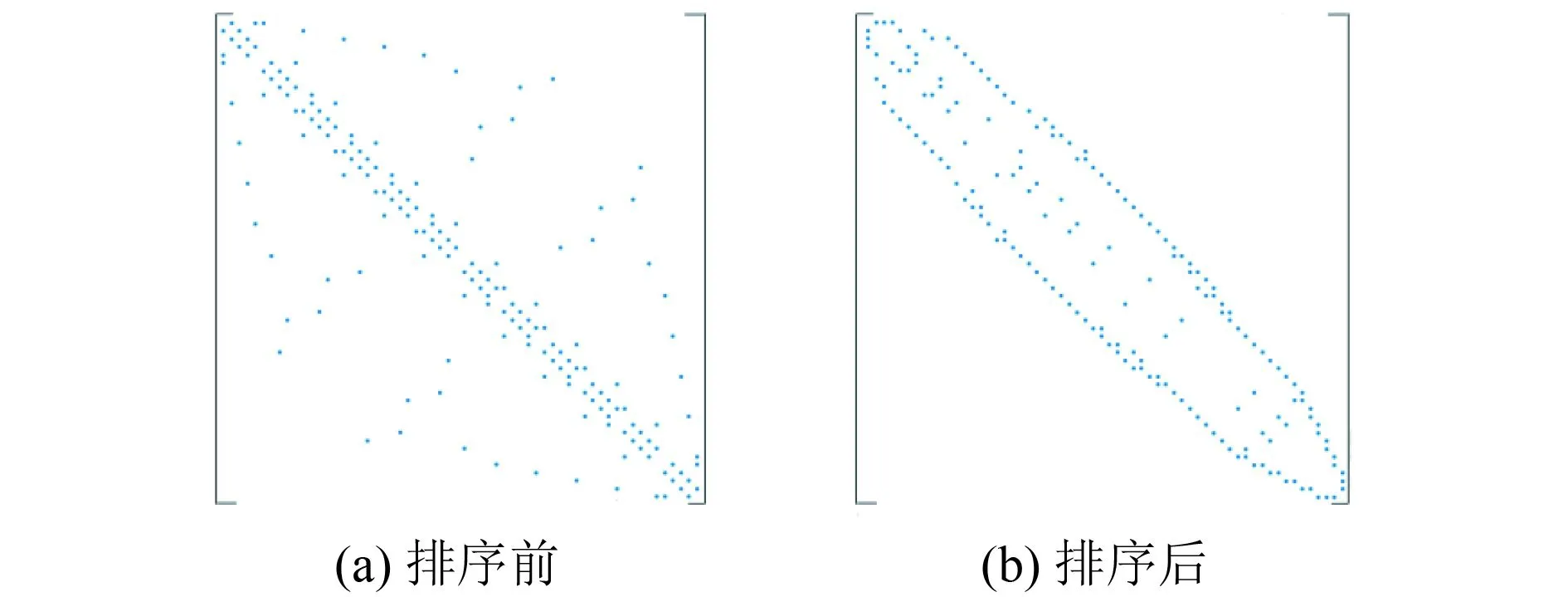
图6 RCM排序用于减小稀疏矩阵带宽
对网格点进行RCM排序,然后根据排序后的网格点顺序,按照每个网格点遍历连接边的贪婪算法进行边的重排序,完成排序后加速效果显著.
RCM排序可以在线性的时间复杂度下完成,这是该方法的优势.本文再提出另一种基于Metis网格分区方法[15]的排序方法用于改善数据局部性,旨在通过时间代价换取更高的加速比.Metis方法常用于并行计算过程的中的网格分区及负载均衡.针对GPU结构优化时,基于Metis的排序方法较RCM排序更为直观,语义上直接对应: 靠的近的点分进同一组.本文通过将网格使用Metis分成N个小区域,每个区域包含100到1000个点(不同点的个数在这个区域内对效果影响不明显).如简化了的只包含四种颜色的示意图7.

图7 基于 Metis的网格排序方法示意图
基于Metis的排序方法同样也需要根据新的点顺序使用贪婪算法对边进行重排序.这种方法在绝大多数情况下性能优于RCM方法,但是问题在于需要占用大量的内存并且需要较长的时间.对于CPU内存满足条件的设备,使用这种排序算法能够实现更高的加速比.
3 算例分析
本节通过ONERA M6机翼算例验证求解器求解三维绕流问题的正确性.该算例是CFD中的经典算例,几何模型简单却又包含了流动的复杂性,涉及跨音速流动、局部超音速流动、激波以及湍流边界层分离等现象.并于实验结果进行了对比.计算条件设置为: 来流马赫数 0.8395,攻角 3.06°,无侧滑角,雷诺数11.72×106.网格由四面体网格和附面层区域的棱柱网格组成,包含 210 万格点,467 万单元,877 万条边,241万棱柱单元,第一层网格高度计算得到的采用音速无量纲化后的压力云图与物面网格如图8所示.

图8 ONERA M6 机翼表面网格及压力分布
3.1 数值结果分析
实验结果给出的数据为展向七个截面处压力系数分布,以翼展b为基准,本节选出20%和90%翼展处截面的压力系数分布作为对比,结果与实验数据基本吻合,如图9所示.

图9 机翼展向不同截面处压力系数分布
3.2 加速性能分析
本节所用 CPU 设备为 Intel(R) Xeon(R) CPU E3-1230 v3,GPU 设备为 NVIDIA Tesla K40c.操作系统环境为 Ubuntu14.04.C++编译器选用 gcc-4.8,CUDA 版本为7.5.GPU端以及CPU端代码均采用-O2等级优化.加速比通过执行并对比算法相同的CPU串行程序和GPU并行程序得到.计算采用双精度变量.
采用本章算例网格,分别在CPU和GPU上进行1000步迭代步计算,并在GPU实现中结合本文提出的基于RCM及基于Metis的网格排序方法同样进行1000步迭代,所需计算时间及相应加速比如表1所示.
结合基于Metis的网格排序的隐式算法求解过程在GPU上相较于CPU得到了27倍的加速比.表1也反应出了本文提出的网格排序算法的高效性,分别得到了63%和69%的性能提升.如果原始网格过于规整,该提升也将会因为对合并访问改善幅度的下降而有所下降.此外,通过不断改善网格质量,或者使用结构网格,本文实现的GPU并行程序可以实现50倍的加速比.可见,对内存合并访问的改善仍然有很大空间.另外,测试所用网格应避免过小以防GPU未被充分利用,这一点不再展开.
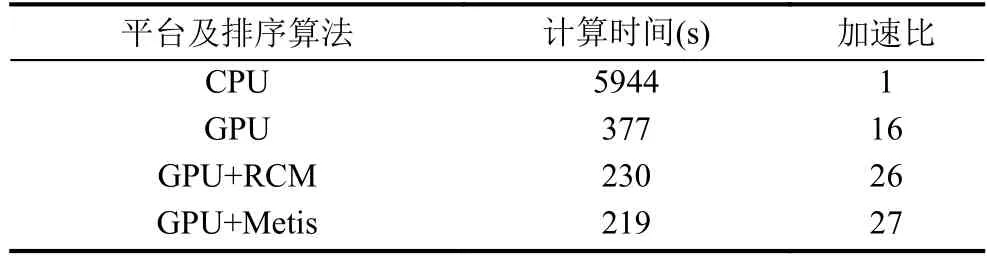
表1 计算时间及相应加速比
4 结论
针对非结构网格格点格式在GPU上计算加速效果不佳的问题,提出了采用RCM以及基于Metis网格分区的网格重排序方法,大大地改善了基于非结构网格的隐式算法在GPU上的并行加速效果.针对文中算例,两种方法分别得到了63%和69%的加速效果.基于Metis的排序方法在效果上往往优于RCM方法,但对于规模较大的网格,其耗时较长.采用了基于Metis的网格重排序方法后,文中算例结果得到了相较于CPU串行程序27倍的加速比,充分证明了本文提出的方法的可行性及优越性.此外,本文的结果也意味着基于非结构网格格点格式的隐式算法在GPU上也能得到良好的加速性能,相关应用拥有着广阔的前景.
致谢: 英伟达公司为本研究工作的展开赞助了Tesla K40计算卡,我们为此表示由衷的感谢.
参考文献
1Hagen TR,Lie KA,Natvig JR.Solving the Euler equations on graphics processing units.Proceedings of the 6th International Conference Computational Science-ICCS 2006.Berlin,Heidelberg,Germany.2006.220–227.
2Cohen J,Molemaker MJ.A fast double precision CFD code using CUDA.Proceedings of Parallel Computational Fluid Dynamics: Recent Advances and Future Directions.Lancaster,UK.2009.414–429.
3Zimmerman BJ, Wie B. Graphics-processing-unitaccelerated multiphase computational tool for asteroid fragmentation/pulverization simulation.AIAA Journal,2017,55(2): 599–609.
4Croaker P,Kessissoglou N.Aeroacoustic scattering using a particle accelerated computational fluid dynamics/boundary element technique.AIAA Journal,2016,54(7): 2116–2133.
5Mostafazadeh B,Marti F,Pourghassemi B,et al.Unsteady navier-stokes computations on GPU architectures.Proceedings of the 23rd AIAA Computational Fluid Dynamics Conference.Denver,CD,USA.2017.4508.
6Jude D,Baeder J.Extending a three-dimensional GPU RANS solver for unsteady grid motion and free-wake coupling.Proceedings of the 54th AIAA Aerospace Sciences Meeting.San Diego,CA,USA.2016.1811.
7董廷星,李新亮,李森,等.GPU 上计算流体力学的加速.计算机系统应用,2011,20(1): 104–109.
8Watkins J,Romero J,Jameson A.Multi-GPU,implicit time stepping for high-order methods on unstructured grids.Proceedings of the 46th AIAA Fluid Dynamics Conference.Washington,DC,USA.2016.3956.
9刘枫,李桦,田正雨,等.基于 MPI + CUDA 的异构并行可压缩流求解器.国防科技大学学报,2014,36(1): 6–10.
10陈龙.基于CFD/CSD耦合的旋翼气动弹性数值模拟[博士学位论文].南京: 南京航空航天大学,2011.
11Jameson A,Yoon S.Lower-upper implicit schemes with multiple grids for the Euler equations.AIAA Journal,1987,25(7): 929–935.
12Sharov D,Nakahashi K.Reordering of 3-D hybrid unstructured grids for vectorized LU-SGS Navier-Stokes computations.Proceedings of the 13th Computational Fluid Dynamics Conference.Snowmass Village,CO,USA.1997.
13Spalart PR,Allmaras SR.A one-equation turbulence model for aerodynamic flows.Proceedings of the 30th Aerospace Sciences Meeting and Exhibit.Reno,NV,USA.1992.
14George A,Liu JW.Computer solution of large sparse positive definite.Biometrical Journal,1981,26(2): 218–225.
15Karypis G,Kumar V.Metis-unstructured graph partitioning and sparse matrix ordering system,version 5.1.0.University of Minnesota,Department of Computer Science,2013.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
计算机应用与软件(2022年4期)2022-06-24
现代电子技术(2022年8期)2022-04-13
计算机应用与软件(2022年2期)2022-02-19
体育科技文献通报(2022年1期)2022-01-15
中北大学学报(自然科学版)(2021年5期)2021-11-15
电子技术与软件工程(2018年10期)2018-07-16
速读·中旬(2018年4期)2018-04-28
时尚北京(2017年1期)2017-02-21
读写算·教研版(2016年10期)2016-06-08
