
自适应融合局部和全局稀疏表示的图像显著性检测
2018-05-21 01:01石爱业
计算机应用 2018年3期
王 鑫,周 韵,宁 晨,石爱业
(1.河海大学 计算机与信息学院,南京 211100; 2.南京师范大学 物理科学与技术学院,南京 210000)
0 引言
随着信息技术的不断发展,人们拥有的数据资源越来越多。其中,图像资源因其直观性,出现了前所未有的增长速度,然而随之而来的信息冗余问题也成为了图像处理的新增难题。神经学和心理学研究专家指出,视觉显著性是人类视觉中非常重要的一个机制,它通过过滤人眼所及之处的冗余信息,突出人们最感兴趣(即显著性)的目标,从而减小信息的冗余度。通过模仿该机制,计算机视觉专家提出了图像显著性检测技术,目前该技术在图像自动裁剪[1]、视频压缩[2]、图像检索[3]、图像分割[4]、目标识别[5]和图像分类[6]等领域得到了广泛的应用。
通过对生物视觉的研究发现,人眼和大脑在处理场景信息时,有两种模式。第一种是,当我们不带任何目的去观察周围的环境,纯粹只是浏览时,环境中与其他背景差异过大的部分会牢牢抓住我们的眼球,吸引我们的注意力,而背景则会被选择性忽略。另一种模式是,如果我们带有目的性的去审视周围的环境时,那么我们更加倾向于找到与目标相关的信息,而忽略其他不相关信息。这两种视觉模型都是大脑处理信息的有效模式,前者没有任务驱动,大脑自动选取感兴趣的区域,减少冗余信息;而后者则是带有目的的寻找有用信息,去除不相干信息。根据大脑处理信息的这两种模型,在计算机视觉领域,图像显著性检测即可分为无任务驱动的自下而上(Down-up)模型和有任务驱动的自上而下(Top-bottom)模型。其中,前者常基于图像的低级特征,没有任务先验信息,无需学习,所以处理相对较快;后者通常基于某个任务,处理过程中带有先验的信息、记忆和经验等高级的图像特征,需要对图像库学习,所以计算量一般较大。为了能快速有效地检测图像显著性区域,本文对自下而上的方法进行重点讨论。
近年来,自下而上的方法得到了显著的发展,很多经典算法相继被提出,如早先的IT(ITTI)算法[7]、GBVS(Graph-Based Visual Saliency)算法[8]、SR(Spectral Residual)算法[9]等,以及较新的SUN(Saliency Using Natural statistics)算法[10]、CA(Context-Aware)算法[11]等。2015 年, Cheng 等[12]提出了基于全局对比度的显著性检测算法,取得了良好的效果。2016年,Liu 等[13]提出了一种基于卷积神经网络的端到端深层次显著性网络,用于检测显著性目标。2017年,叶子童等[14]提出了基于引导Boosting算法的显著性检测方法,它提出采用自下而上的模型生成的样本来引导特征学习,强化显著性检测效果。这些算法又可以细分为基于局部思想的检测算法和基于全局思想的检测算法。其中,基于局部思想的检测算法通常关注图像的边缘,而无法很好地检测显著目标内部信息;而基于全局思想的检测算法能较为有效地检测出显著性目标的内部区域,但却对背景抑制不是很理想[15-19]。
为了解决该问题,本文考虑融合局部和全局两类检测思想的优势,以得到更为良好的检测结果。由于显著性区域相对于其他大面积的非显著性区域往往具有非常独特的特性,因此,它的特征在整个场景中重复的频率通常较低,这使得显著性区域也具有稀疏的特征,故稀疏表示理论可以有效用于视觉显著性检测中。具体而言,针对一幅输入图像,通过对其进行随机采样,可以得到若干个图像块,由于显著性区域在整个场景中出现的频率通常较低,随机采样得到的这些图像块将大多数为背景块,而非显著性块;然后,利用这些图像块,构建稀疏表示过完备字典,由此学习得到的字典将包含较多的背景特征;最后,基于该字典,对原始图像进行稀疏表示,则稀疏重构误差较大的图像块为显著性块的可能性就较大。基于上述思想,本文提出了一种有效的融合局部和全局稀疏表示的图像显著性检测方法。首先,对原始图像进行分块处理,利用图像块代替像素级操作,降低算法复杂度;其次,对分块后的图像进行局部稀疏表示,即:针对每一个图像块,选取其周围的若干图像块生成过完备字典,基于该字典对图像块进行稀疏重构,得到原始图像的初始局部显著图;接着,对分块后的图像进行全局稀疏表示,与局部稀疏表示过程类似,不同的是针对每一个图像块所生成的字典来源于图像四周边界处的图像块,这样可以得到初始全局显著图;最后,将初始局部和全局显著图进行自适应融合,生成最终显著图。该方法由于融合了局部和全局的思想,能够识别并保存显著性区域的边缘信息,同时准确提取出显著性区域的内部信息。实验结果表明,本文提出的算法大大优化了检测效果。
1 稀疏表示
本文提出的算法将采用模拟人类神经细胞的标准稀疏编码模型[20],此模型可以突出图像中的显著部分(该部分具有独特性、稀少性和不可预测性)。Huang等[21]通过实验发现,某个特征描述子用几个基进行编码,如果其中的某个基比其他的基和特征描述子有更相近的特征,通常这个基比其他的基具有更强的响应。通过这个发现,指出稀疏编码等价于一种显著性编码机制。基于该编码机制计算得到的输入信号重构误差越大,则该信号被认为越显著。
设Y=[y1,y2,…,yN]∈Rn×N为输入信号,D为Y的稀疏表示重构字典,则稀疏表示的目标函数[22]如下:
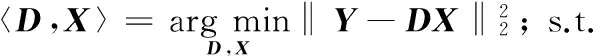
(1)

在稀疏编码过程中,每一步的迭代字典D是固定的,可通过式(2)计算输入信号yi的稀疏编码系数xi:

s.t. ‖x‖0≤T
(2)
上式可通过贪婪追踪算法中的OMP(Orthogonal Matching Pursuit)算法[23]求解,选取最匹配的原子分解信号和分解信号残差,在每一步中都把所选择的原子进行Gram-Schmidt正交化处理,使得字典空间展开结果最优。
基于稀疏表示理论,计算yi所对应的稀疏重构误差:
(3)
2 自适应融合局部和全局稀疏表示方法
为了克服传统的局部或全局显著性检测算法的缺陷,本文提出了一种基于自适应融合局部和全局稀疏表示的图像显著性检测方法,其总体思路是分别进行基于局部或全局稀疏表示的显著性检测,然后将结果进行融合生成图像显著图,提出算法的整体框架如图1所示。

图1 提出算法的框图 Fig. 1 Block diagram of the proposed algorithm
2.1 基于局部稀疏表示的显著性检测
给定一幅原始图像,为了得到其局部显著性图,首先对其进行分块,针对每一个图像块,选取其周围的若干图像块生成过完备字典,基于该字典对图像块进行稀疏重构,最终得到原始图像的初始局部显著图。具体过程如下所示:
1)输入原始图像I,设其尺寸为M×N。
2)将原始图像I分割成为若干个图像块bi。与大部分的局部或全局处理算法不一样,本文没有以像素作为最小处理单元,因为像素点数量庞大,处理起来费时费力耗资源,而采用图像块作为最小处理单元,虽然比像素级误差略微大一点,但是节省了很多时间,也能取得不错的效果。设分割成的图像块大小为m×n,则M×N大小的原始图像可以被不重叠地分成(M×N)/(m×n)个图像块。这里需要说明的是,图像块的大小对后续算法的效果和复杂度有一定的影响:图像块越大,检测效果下降,时间效率提高;反之,图像块越小,检测效果越好,但时间效率较低。在程序实现过程中,以 320×400大小原始图像为例,选取的图像块大小为4×4,这将原始图像恰好分成8 000个图像块,通过实验表明这些参数量可以在计算效率和误差大小之间维持一个平衡。最后,将分割后的每个图像块按从左到右、从上到下的顺序进行标记,同时将每个图像块进行列向量化。
3)图像重组,得到矩阵B。这一步是为稀疏求解作准备,由于稀疏表示的实现是基于矩阵运算,所以对分割成图像块的图像进行重新整合。重组后的图像标记为B=[b1,b2,…,bK],其中,bi代表第i个列向量化后的图像块,K为图像块的总数。B可以直观地表示为图2所示。

图2 矩阵B的直观表示 Fig. 2 Visual representation of matrix B
4)构造局部稀疏字典D。对于字典的生成,本文根据显著性检测的实际情况,直接从图像内选取合适的图像块来构造字典,这样能更加方便、有效地重构原始信号。在局部稀疏表示中,对某一选定的图像块bi稀疏重构,选取的是该图像块周围的图像块作为字典。由于在第3)步中图像已经表示成图像块的行向量,因此我们选择的是重构图像块前s列和后s列一共2s个图像块构造字典,形成的字典可以表示为D=[d1,d2,…,d2S]。
5)求解稀疏系数α。本文中稀疏系数求解算法综合对比考虑了算法精度问题和实现复杂度问题,采用了上文提到的OMP算法求取最佳的表示系数α:
arg min‖α‖0; s.t.B=Dα
(4)
其中,α是所有图像块的系数集合。
6)生成初始局部显著图SL。在步骤5)的基础上,利用求得的稀疏系数α重构每个图像块bi,并计算其重构误差ei:
(5)
将该结果赋给所在的图像块,然后进行高斯滤波即可得到初始局部显著图SL。图3给出了基于局部稀疏表示的显著性检测示例,其中:图3(a)为三幅原始图像,图3(b)为计算得到的初始局部显著图,图3(c)为对应的真值图。由图3可以看出,基于局部稀疏表示的显著性检测算法,能大致检测出图像的显著区域,但是其更加关注显著性物体的边缘信息,对物体的内部信息有所抑制。

图3 基于局部稀疏表示的显著性检测 Fig. 3 Saliency detection via local sparse representation
2.2 基于全局稀疏表示的显著性检测
下面对原始图像进行全局稀疏表示显著性检测。与2.1节描述的基于局部稀疏表示的显著性检测过程类似,只是步骤4)中字典生成方式有所不同。
在传统的稀疏表示中,全局字典的生成一般是从图像中随机选取图像块,进行字典学习。此时,对于大部分的应用领域而言,稀疏表示的重构误差越小,说明算法越好,但是在显著性检测中,并非如此。我们希望属于背景的图像块能得到很好的重构效果,理想误差值为0;而属于前景目标的图像块,根据字典重构,并不能得到很好的重构效果,归一化的理想误差值为1。这样才能准确地检测出显著区域。
基于以上思想,本文没有选用现有常见的全局字典构造法,而是直接从属于背景的图像块中选择字典。对于大部分图像而言,图像四周靠边缘的图像块一般都属于非显著性区域,所以本节选择上下左右四个边界的图像块构造字典。由此即可得到基于全局稀疏表示的显著性检测结果。图4给出了图3(a)的全局稀疏表示显著图SG。从图4可以看出,基于全局稀疏表示的显著性检测算法,检测显著部分的内部信息体现得要比局部全面,但非显著性部分没有得到很好的抑制,噪声较多。
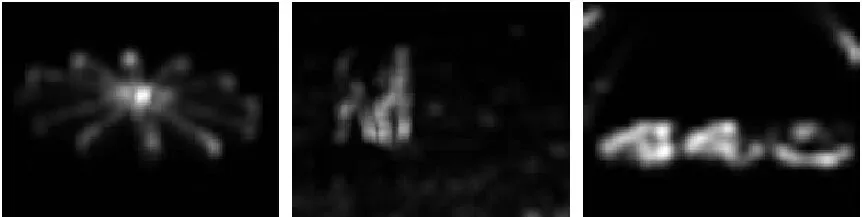
图4 基于全局稀疏表示的显著性检测(初始全局显著图) Fig. 4 Saliency detection via global sparse representation (initial global saliency map)
2.3 局部和全局显著性自适应融合
综合考虑上述基于局部或全局稀疏表示的显著性检测效果,各有利弊:局部稀疏检测法侧重于检测物体轮廓,容易丢失显著物体内部信息;而全局稀疏检测法可以很好地突出物体内部信息,但是背景噪声得不到很好地抑制。
基于此,本节将求得的初始局部和全局显著图进行相互融合,取长补短,以获得更好的检测结果。现有的图像显著图融合方法包括取乘法融合[24]、最大值融合[25]、加权融合[26]等。不同融合算法的融合结果对比如图5所示,其中,图5(a)为原始图像,图5(b)是初始局部显著图,图5(c)是初始全局显著图,图5(d)是乘法融合结果,图5(e)是取最大值融合结果,图5(f)是加权融合结果(以1:1加权为例)。通过对比发现,乘法融合只能显示两幅图像共同显著的部分,对于局部区域而言,被抑制的内部信息在经过乘法融合之后,依旧不显著;最大值融合得到的显著图由于只来源于某个主要渠道,不能很好地突出显著区域;加权融合相比前两种方法,能取得较好的效果,此外加权融合实现也简单,效率高。

图5 不同融合策略对比结果 Fig. 5 Comparison of different fusion strategies
对于加权融合,如何选取两幅显著图的权重之比非常重要,一般有两种方式:固定权重值[27]和自适应权重值[28]。前者两幅显著图的权重值固定,实现简单,运行速度快,但是灵活性差,不能根据图像的不同特点调整相应的比例。因此,为了更加合理地融合两幅初始显著图,得到更好的融合效果,这里提出了一种自适应权重计算策略。
给定初始局部显著图SL和全局显著图SG,并分别进行归一化,然后将它们自适应融合,得到最终的显著图S:
S(i,j)=ωL×SL(i,j)+ωG×SG(i,j)
(6)

定义SL相对于SG的相关性,相关系数用PL表示:
(7)
同理,定义SG相对于SL的相关系数PG:
(8)
在此基础上,计算权重值ωL和ωG:
(9)
(10)
将计算的得出的权重值ωL和ωG代入式(6)中,即可得到最终的融合图像S。图6给出了图3(b)初始局部显著图和图4初始全局显著图的自适应加权融合结果,由该图可以看出融合了局部和全局的显著图比单一算法显著图要好很多,克服了单一算法的缺点,最终显著图既抑制了背景信息,又突出了显著物体内部,取得了不错的效果。

图6 基于自适应加权融合的最终显著图生成 Fig. 6 Final saliency map generation by using adaptive weighted fusion
3 实验和分析
为了验证提出算法的有效性,在CPU主频为2.3 GHz,内存为4 GB,仿真软件为Matlab R2013b的PC上对提出算法进行了实验。实验图像来源于MSRA、ECSSD, NUSEF 和INRIA数据库[29-32],这些图像库包含了各种各样的自然场景原始图像和被人工标记过的真值图像,从这些库中随机挑选了400幅图像进行实验。
3.1 定性分析
为了评价本文提出的显著性检测方法,选择了IT、GBVS、SR、SUN和CA这5种经典的显著性检测算法及基于稀疏重建残差(Sparse Representation Residual, SRR)的显著性检测算法[33]进行对比,结果如图7所示。图7(a)均表示原始图像。这里选取了一些具有代表性的原始图像,包括:具有较大显著性区域的原始图像(如图7(a)的前三幅图)、具有较小显著性区域的原始图像(如图7(a)的第4到第7幅图)、具有多个显著性区域的原始图像(如图7(a)的最后两幅图)。图7 (b)~(h)分别为IT、GBVS、SR、SUN、CA、SRR和提出算法(记为Ours)得到的显著图,图7 (i)为真值图。对比不同算法的显著图,可以看出IT算法可以检测出显著性区域,但是边缘信息模糊,且检测目标内部信息不能很好地保留;GBVS算法略优于IT算法,但显著性目标内部仍无法有效检测;SR算法对边缘信息过于敏感,忽视了显著目标内部;SUN算法较好地检测出显著目标,但很多背景信息也被检测到;CA算法也很关注背景信息,从而导致非显著性区域不能得到很好的抑制;SRR算法更加关注显著性物体的边缘信息,内部区域未能有效检测出来。相比其他算法,本文算法有很大的优势,由于融合了局部和全局的思想,对较大显著性对象不仅能够识别并保存其边缘信息,同时能够准确提取出其内部信息(如图7(h)的前三幅图);此外,本文提出算法对较小显著性对象也达到了良好的检测效果(如图7(h)的第4到第7幅图);最后,针对包含多个显著性对象的原始图像,提出算法也能够将相关对象区域提取出来,使得这些对象在整体上得到了提升(如图7(h)的最后两幅图)。
3.2 定量分析
为了进一步验证提出算法的性能,本文采用查准率(precision),查全率(recall)和F值(F-measure)这三个指标来定量分析[34]。这三个指标的具体计算公式如下:
(11)
(12)
(13)
其中:SB代表将检测结果图像进行二值分割后的结果,G为该图像的真值图,Num(SB)和Num(G)分别代表SB和G中像素值为1的个数,参数β2取0.3。
本文将不同算法在整个实验数据集(共400幅图像)上进行了实验,针对每个算法计算得到的400幅显著图结果,在[0,1]区间上,以0.05为步长,选取阈值对所有显著图进行二值化分割,然后计算每个阈值下的查准率和查全率,最终得到该算法的平均查准率,查全率和F值,结果如表1所示。由表可见,提出算法的在查准率、查全率及F值上均有较好的表现,明显优于其他方法的相应指标。其中,查准率反映了检测出的并包含在真值图中的显著像素与检测出的显著像素之比,体现了检测的有效像素在整个显著像素中的百分比,查准率越高说明检测的正确性越高。查全率反映的是检测出的包含在真值图中的显著像素与总的真值图像素比,体现了被检测出的有效显著像素与实际有效像素之比,查全率越高说明检测出的显著性区域越完整。F值是对查准率和查全率的综合量化指标,总体而言更具可靠性。因此,本文提出的算法在显著性检测的正确性、完整性及综合评价方面均优于其他方法。

图7 不同算法显著图对比 Fig. 7 Saliency map comparison of different methods 表1 不同方法的查准率、查全率和F值比较 Tab. 1 Precision, recall and F-measure comparisons of different methods

算法查准率查全率F值IT0.540.210.3963GBVS0.600.390.5337SR0.450.370.4286SUN0.610.390.5397CA0.670.580.6468SRR0.580.360.5083Ours0.770.740.7629
此外,除了上述量化评价之外,为了分析提出算法的时间效率,在Matlab 2013(b)的平台上进行了实验。不同算法的运行时间结果如表2所示,结果保留到小数点后三位,时间单位是“秒”。由于本文提出的算法基于稀疏表示理论进行显著性检测,所以在时间效率上,本文提出的算法不如前4种经典算法。为了提高算法的效率,后续将采用具备并行计算能力的计算机以及更高效的软件实现平台(如C++)对算法进行实现。
总之,通过实验结果分析及量化指标评价,本文提出的方法相对现有算法在显著性检测效果及性能方面均有明显提高。
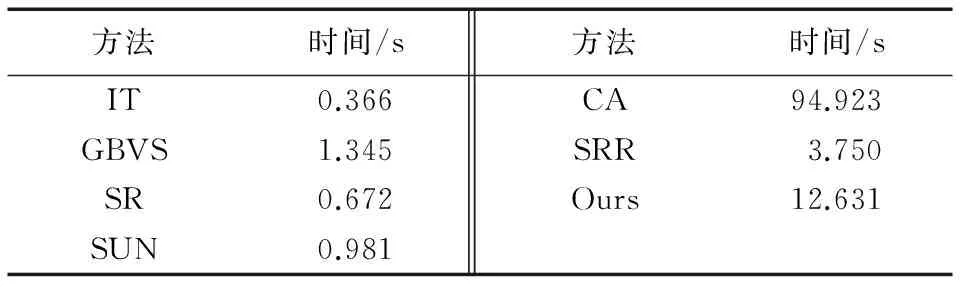
表2 不同方法的效率比较(Matlab)Tab. 2 Computation time comparison of different methods (Matlab)
4 结语
本文提出了一种基于自适应融合局部和全局稀疏表示的图像显著性检测方法,通过在常用基准数据库进行评测,与IT、GBVS、SR、SUN和CA 5种经典方法进行性能对比,结果表明,本文提出的方法能够有效检测显著性目标的边缘和内部区域,并在查准率、查全率和F值 3个指标上明显优于比较算法。由于本文算法基于稀疏表示理论,算法效率有待进一步提高。
参考文献(References)
[1] SANTELLA A, AGRAWALA M, DECARLO D, et al. Gaze-based interaction for semi-automatic photo cropping [C]// CHI ’06: Proceedings of the 2006 SIGCHI Conference on Human Factors in Computing Systems. New York: ACM, 2006: 771-780.
[2] BRADLEY A P, STENTIFORD F. Visual attention for region of interest coding in JPEG 2000 [J]. Journal of Visual Communication & Image Representation, 2003, 14(3): 232-250.
[3] CHEN T, CHENG M M, TAN P, et al. Sketch2Photo: Internet image montage [C]// Proceedings of the 2009 ACM SIGGRAPH Asia. New York: ACM, 2009: Article No. 124.
[4] WANG L, XUE J, ZHENG N, et al. Automatic salient object extraction with contextual cue [C]// ICCV ’11: Proceedings of the 2011 International Conference on Computer Vision. Washington, DC: IEEE Computer Society, 2011: 105-112.
[5] NAVALPAKKAM V, ITTI L. An integrated model of top-down and bottom-up attention for optimizing detection speed [C]// Proceedings of the 2006 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2006: 2049-2056.
[6] KANAN C, COTTRELL G. Robust classification of objects, faces, and flowers using natural image statistics [C]// Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2010: 2472-2479.
[7] ITTI L, KOCH C, NIEBUR E. A model of saliency-based visual attention for rapid scene analysis [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1998, 20(11): 1254-1259.
[8] SCHÖLKOPF B, PLATT J, HOFMANN T. Graph-based visual saliency [C]// Proceedings of the 2006 20th Annual Conference on Neural Information Processing Systems. Cambridge, MA: MIT Press, 2007:545-552.
[9] HOU X, ZHANG L. Saliency detection: a spectral residual approach [C]// CVPR ’07: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society. 2007: 1-8.
[10] ZHANG L, TONG M H, MARKS T K, et al. SUN: a Bayesian framework for saliency using natural statistics [J]. Journal of Vision, 2008, 8(7): 1-20.
[11] GOFERMAN S, ZELNIKMANOR L, TAL A. Context-aware saliency detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2012, 34(10): 1915-1926.
[12] CHENG M M, MITRA N J, HUANG X, et al. Global contrast based salient region detection [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(3): 569-582.
[13] LIU N, HAN J. DHSNet: deep hierarchical saliency network for salient object detection [C]// Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2016: 678-686.
[14] 叶子童,邹炼,颜佳,等.基于引导Boosting算法的显著性检测[J].计算机应用, 2017,37(9):2652-2658.(YE Z T, ZOU L, YAN J, et al. Salient detection based on guided Boosting method [J]. Journal of Computer Applications, 2017, 37(9): 2652-2658.)
[15] HOU X, ZHANG L. Dynamic visual attention: searching for coding length increments [EB/OL]. [2017- 03- 03]. http://pdfs.semanticscholar.org/1432/d0c3a4b96bc3af9f83d65d77be2fb1046fb6.pdf.
[16] BORJI A. Exploiting local and global patch rarities for saliency detection [C]// CVPR ’12: Proceedings of the 2012 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2012: 478-485.
[17] 陈文兵,鞠虎,陈允杰.基于倒数函数-谱残差的显著对象探测和提取方法[J].计算机应用,2017,37(7):2071-2077.(CHEN W B, JU H, CHEN Y J. Salient object detection and extraction method based on reciprocal function and spectral residual [J]. Journal of Computer Applications, 2017, 37(7): 2071-2077.)
[18] LI Y, ZHOU Y, XU L, et al. Incremental sparse saliency detection [C]// ICIP ’09: Proceedings of the 16th IEEE International Conference on Image Processing. Piscataway, NJ: IEEE, 2009: 3057-3060.
[19] HAN B, ZHU H, DING Y. Bottom-up saliency based on weighted sparse coding residual [C]// MM ’11: Proceedings of the 19th ACM International Conference on Multimedia. New York: ACM, 2011: 1117-1120.
[20] OLSHAUSEN B, FIELD D J. Emergence of simple-cell receptive field properties by learning a sparse code for natural images [J]. Nature, 1996, 381(6583): 607-609.
[21] HUANG Y, HUANG K, YU Y, et al. Salient coding for image classification [C]// CVPR ’11: Proceedings of the 2011 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2011:1753-1760.
[22] DAMNJANOVIC I, DAVIES M E P, PLUMBLEY M D. SMALL box — an evaluation framework for sparse representations and dictionary learning algorithms [C]// LVA/ICA ’10: Proceedings of the 9th International Conference on Latent Variable Analysis and Signal Separation. Berlin: Springer, 2010: 418-425.
[23] PATI Y C, REZAIIFAR R, KRISHNAPRASAD P S. Orthogonal matching pursuit: recursive function approximation with applications to wavelet decomposition [C]// Proceedings of the 1993 Conference Record of the 27th Asilomar Conference on Signals, Systems and Computers. Piscataway, NJ: IEEE, 1993, 1: 40-44.
[24] KIM W, KIM C. Spatiotemporal saliency detection using textural contrast and its applications [J]. IEEE Transactions on Circuits & Systems for Video Technology, 2014, 24(4): 646-659.
[25] LI Y, TAN Y, YU J G, et al. Kernel regression in mixed feature spaces for spatio-temporal saliency detection [J]. Computer Vision & Image Understanding, 2015, 135: 126-140.
[26] SU Y, ZHAO Q, ZHAO L, et al. Abrupt motion tracking using a visual saliency embedded particle filter [J]. Pattern Recognition, 2014, 47(5): 1826-1834.
[27] FANG Y, WANG Z, LIN W. Video saliency incorporating spatiotemporal cues and uncertainty weighting [C]// Proceedings of the 2013 IEEE International Conference on Multimedia and Expo. Washington, DC: IEEE Computer Society, 2013: 1-6.
[28] WANG X, NING C, XU L. Saliency detection using mutual consistency-guided spatial cues combination [J]. Infrared Physics & Technology, 2015, 72:106-116.
[29] LIU T, SUN J, ZHENG N N, et al. Learning to detect a salient object [C]// CVPR ’07: Proceedings of the 2007 IEEE Conference on Computer Vision and Pattern Recognition. Piscataway, NJ: IEEE, 2007:1-8.
[30] YAN Q, XU L, SHI J, et al. Hierarchical saliency detection [C]// CVPR ’13: Proceedings of the 2013 IEEE Conference on Computer Vision and Pattern Recognition. Washington, DC: IEEE Computer Society, 2013: 1155-1162.
[31] RAMANATHAN S, KATTI H, SEBE N, et al. An eye fixation database for saliency detection in images [C]// Proceedings of the 2010 European Conference on Computer Vision, LNCS 6314. Berlin: Springer, 2010: 30-43.
[32] JEGOU H, DOUZE M, SCHMID C. Hamming embedding and weak geometric consistency for large scale image search [C]// Proceedings of the 2008 European Conference on Computer Vision, LNCS 5302. Berlin: Springer, 2008: 304-317.
[33] XIA C, QI F, SHI G, et al. Nonlocal center-surround reconstruction-based bottom-up saliency estimation [J]. Pattern Recognition, 2015, 48(4): 1337-1348.
[34] WANG X, NING C, XU L. Spatiotemporal saliency model for small moving object detection in infrared videos [J]. Infrared Physics & Technology, 2015, 69: 111-117.
This work is partially supported by the National Natural Science Foundation of China (61603124), the Six Talents Peak Project of Jiangsu Province (XYDXX-007), the 333 High-Level Talent Training Program of Jiangsu Province, the Fundamental Research Funds for the Central Universities (2015B19014).
WANGXin, born in 1981, Ph. D., associate professor. Her research interests include image processing, pattern recognition, computer vision.
ZHOUYun, born in 1992, M. S. candidate. Her research interests include image processing.
NINGChen, born in 1978, M. S., lecturer. His research interests include compressed sensing.
SHIAiye, born in 1969, Ph. D., associate professor. His research interests include image processing, visual computing.
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
中国医院院长(2022年13期)2022-08-15
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
中国生殖健康(2020年7期)2020-12-10
现代计算机(2019年19期)2019-08-12
小学阅读指南·低年级版(2019年11期)2019-07-01
金桥(2018年4期)2018-09-26
小天使·一年级语数英综合(2017年11期)2017-12-05
商周刊(2017年6期)2017-08-22
