
棘腹蛙线粒体局部重复序列非排序聚类
2018-05-28 04:27曹跃夏云郑渝池
四川动物 2018年3期
曹跃, 夏云, 郑渝池*
(1. 中国科学院成都生物研究所两栖爬行动物研究室,成都610041; 2. 中国科学院大学,北京100049)
动物线粒体基因组发生局部串联重复后,涉及区域的序列具有多拷贝和大量插入缺失的特点,故难以排序。分析这类序列的演化时,可将序列进行聚类并以树形结构直观地归纳和呈现序列间的相似性及差异。理论上讲,可通过非排序比对方法(alignment-free comparison methods,AFM)计算序列间差异矩阵,由此得到聚类树。但迄今未见此类评估和运用。线粒体基因组各位点间通常完全连锁。如果基于AFM的重复区域序列聚类树和非重复区域基因树的拓扑结构相近,才能被实际运用。基于什么样的AFM和参数空间才能得到这样的聚类树则有待研究。
AFM始于20世纪80年代中期,其后不断发展,已被应用于不同领域,例如序列检索(Hideetal. ,1994)、全基因组序列聚类(Simsetal. ,2009a;Renetal. ,2016)、宏基因组对比(Jiangetal. ,2012;Wangetal. ,2014)、调控序列演化和识别(Songetal. ,2013)、重组特别是重排序列分析(Vinga,2014;Zielezinskietal. ,2017)。AFM主要分为2大类:一类不对序列进行拆分,如计算全长序列间共享信息(Vinga & Almeida,2003;Vinga,2013);另一类将序列分解为特定长度(k)的子序列集作为对比时的数据来源(Ulitskyetal. ,2006;Almeida,2013)。后者在准确性、计算资源占用、序列差异程度等方面有较好表现(Haubold,2013;Bernardetal. ,2016;Zielezinskietal. ,2017)。
序列间差异越小,其k长度子序列集的相似程度越高,可通过不同特征进行度量。一类方法基于子序列集中独特序列的计数,如Co-phylog算法(Yi & Jin,2013),有对该计算进行校正的版本,如CVTree算法(Qietal. ,2004)。另一类常见方法考查某条序列是否在子序列集中出现,如Yule算法(Luetal. ,2017)。k值直接决定每条序列的子序列集,一组序列在不同k值下生成不同的距离矩阵,为一重要参数,其在不同应用中的适宜值域不同。在进行氨基酸序列对比时,有工作提示k值为2~6时可以得到稳定的结果(Höhletal. ,2006;Höhl & Ragan,2007)。进行核酸对比时,k值可设为8~10(Chanetal. ,2014);9~14可用于聚类树构建(Simsetal. ,2009b;Junetal. ,2010;Wangetal. ,2014)。一般来讲,当序列差异较大时,k值应较小;反之,当序列相似性高时,k值应较大(Wuetal. ,2005;Simsetal. ,2009b;Zielezinskietal. ,2017)。
脊椎动物线粒体基因tRNA簇trnW、trnA、trnN、OL、trnC、trnY是发生串联重复的一个热点区域,习惯上称“WANCY”区,其中,OL为轻链复制起点。重复后会发生基因的随机丢失,故该区域往往含有同一基因的功能序列和残基(San Mauroetal. ,2006;Fonseca & Harris,2008)。棘腹蛙Quasipaaboulengeri线粒体基因组存在这样的重复和随机丢失,其WANCY序列依功能基因的排列可分为Ⅰ~Ⅳ 4种类型(Xiaetal. ,2016)。Ⅰ型序列和其他类型明显不同。重排区外蛋白编码序列的线粒体基因树也显示Ⅱ~Ⅳ型聚为一支,是一次串联重复后的不同随机丢失形式,长度600~700 bp。其中,Ⅲ型和Ⅳ型的关系更近,但Ⅲ型有2次起源,分为Ⅲa和Ⅲb,后者和Ⅳ型关系更近(Xiaetal. ,2016)。这也表明功能基因的排列顺序不足以反映这些重排序列的相似性和差异程度。
选取19号有代表性的Ⅱ~Ⅳ型棘腹蛙个体,采用基于k长度子序列集的AFM对其WANCY序列进行聚类,以其1 518 bp蛋白编码序列线粒体基因树为参照,计算两者间Robinson-Foulds拓扑结构距离(Robinson & Foulds,1981),并考查AFM聚类树能否反映Ⅲa型、Ⅲb型和Ⅳ型间的关系,探寻在该条件下有更好表现的AFM和k值范围,以期为将AFM引入动物线粒体串联重复序列的演化研究提供帮助。
1 材料和方法
1.1 样品和DNA序列
样品选自作者所在研究团队前期发表的一项棘腹蛙WANCY序列演化研究的样本(Xiaetal. ,2016)。选择依据为具有代表性和稳定的基因树拓扑结构。19号样品来自Ⅱ~Ⅳ型,Ⅱ型作为外群。DNA序列来自2个片段:1个片段包括WANCY及其两翼的nad2(115 bp)和cox1(565 bp)基因部分序列;另1个片段为长度838 bp的cytb基因部分序列。前者全部和后者中12条序列下载自GenBank,登录号:KX571520、KX571524、KX571530、KX571533、KX571553、KX571557~ KX571560、KX571565、KX571568、KX571570、KX571571、KX571574、KX571583、KX571586、KX571588、KX571591、KX571592、KX571838、KX571843、KX571844、KX571850、KX571860、KX571861、KX571865、KX571876、KX571880、KX571886、KX571892、KX571898(Xiaetal. ,2016)。另外7条cytb基因序列为实验获得,所用PCR引物为CYTBF-3(5’-ACCTCCCCGCTCCAGCAAATCTA-3’)和CYTBR-3(5’-CCGATGGTGACGAATGGGTCTTC-3’),退火温度52 ℃,GenBank登录号:MG799837~MG799843。蛋白编码序列的排序采用Clustal X 2.1(Larkinetal. ,2007)。
1.2 蛋白编码序列基因树和WANCY序列AFM聚类树的构建和比较
蛋白编码序列基因树的构建采用常用的最大似然法(ML),使用RAxML 8.2.10(Stamatakis,2014)。3个基因片段nad2、cox1、cytb被合并为1个数据集。由于是种下水平的分析,未尝试根据基因或密码子位点对数据集进行分区,以避免可能的过参数化。在RAxML已有DNA序列演化模型中,依据贝叶斯信息准则使用PartitionFinder 2.1.1(Lanfearetal. ,2016)选择最适模型。RAxML分析包括1 000次独立推断得出最优ML树,自展法1 000次重复计算其支持率。
WANCY序列AFM聚类使用CAFE 071017(Luetal. ,2017)。该软件是对基于k长度子序列集AFM的最新整合。作为将AFM引入线粒体串联重复序列聚类的探索,分析采用其编译的全部28种可使用普通个人计算机运算的AFM。这些算法的名称与CAFE一致。采用默认设置逐一计算得到k值为4、6、8、10、12、14、16、18、20时的距离矩阵。随后使用Phylip 3.695(Felsenstein,1989)中的邻接法将这些距离矩阵转换成聚类树。
基因树和AFM聚类树间Robinson-Foulds距离的计算使用DendroPy 4.3.0(Sukumaran & Holder,2010)。Python库使用Newick格式树文件,格式转换在FigTree 1.42(http://tree.bio.ed.ac.uk/software/figtree/)中进行。另外,记录AFM聚类树是否将序列划分为Ⅱ、Ⅲa、Ⅲb、Ⅳ支系,以及是否呈现和基因树相同的(Ⅲa,(Ⅲb,Ⅳ))支系关系。
2 结果
19条蛋白编码序列排序未发现插入或缺失。所得数据集含1 518个位点,其中可变位点116个,简约信息位点81个。RAxML中适合该数据集的模型为GTR+I+G。所得ML树拓扑结构总体稳定,平均自展支持率为89(图1)。
19条WANCY序列长度在583~695 bp之间。28种AFM与k值共产生252种组合。有7种AFM可以完成全部组合的计算。普通个人计算机无法满足部分组合(k值为12、14、16、18、20)的计算量,反映了k值与计算资源需求间的一定正相关。另外,有3个组合得到明显无意义的聚类树,所有序列无支长或呈梳状,分别为Co-phylog算法(k值为4)、Hamming算法(k值为18)、Russel算法(k值为8),无法总结出规律。最终得到141个组合的聚类树用于后续分析,它们与ML树的Robinson-Foulds距离及主要拓扑关系比较总结见表1。
141个AFM聚类树与ML树的Robinson-Foulds距离介于4~24,这表明没有得到和ML树拓扑结构完全相同的AFM聚类树,两者最相近的情况为2个节点(11.8%)的差异,即Robinson-Foulds距离等于4。得到距离为4的组合共16个(11.3%),其中14个来自几乎所有的基于特定序列是否在子序列集中出现的算法,另外2个来自基于子序列集中独特序列计数的Canberra算法。这16个组合来自14种算法,其中12种/个算法/组合的k值为8,Chisq算法的2个组合k值为4、6,Canberra算法的2个组合k值为4、20。得到距离6和8的组合各自为66个和20个,分别占全部组合的46.8%和14.2%。这些和ML树更接近的聚类占全部结果的72.3%,但并不是所有的AFM都可得出。D2star、CVTree、Ch、FFP算法所得聚类树和ML树的距离为10~24,平均为18,占全部结果的17.0%。
可以将19条WANCY序列聚为Ⅱ、Ⅲa、Ⅲb、Ⅳ4支的组合共121个,占85.8%。大多数算法在不同k值下均可得到这样的结果,例如Ma和Canberra算法。但来自D2star、CVTree、Ch算法的组合无法得出这样的聚类。呈现和ML树相同(Ⅲa,(Ⅲb,Ⅳ))支系关系的15个组合占全部组合的10.6%。这15个组合来自13种算法,其中11种算法/组合的k值为4,另外2种算法Hamming和Canberra的各2个组合k值分别为4、20。
得到和ML树最小距离的16个组合条件与发现ML树主要支系关系的15个组合条件的重叠度不高(表1)。主要表现为,很多方法中k值为8时距离最小,k值为4时呈现关系(Ⅲa,(Ⅲb,Ⅳ))。两大类条件间仅重叠2个组合,即Canberra算法设k值为4和20时,可认为是本工作中的最理想AFM分析条件。2个条件下所得聚类树拓扑结构相同,前者作为示例见图1,其和ML树的拓扑关系的区别仅存在于支系Ⅳ内,可能与ML树该支内部分节点的支持率不高有一定关联。
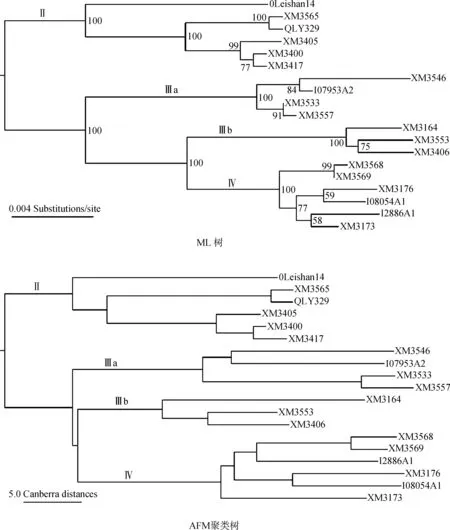
图1 蛋白编码序列最大似然树和运用Canberra算法设k值为4所得WANCY序列非排序比对树Fig. 1 The Maximum Likelyhood tree of the protein coding sequences and the Canberra alignment-free comparison method tree of the WANCY sequences using a k value of 4
ML树节点旁数值为自展支持率; 蛋白编码序列和WANCY序列均使用该号个体的编号
Numbers beside nodes of the ML tree are bootstrap supporting values; tip labels are lab numbers of the 19 individuals
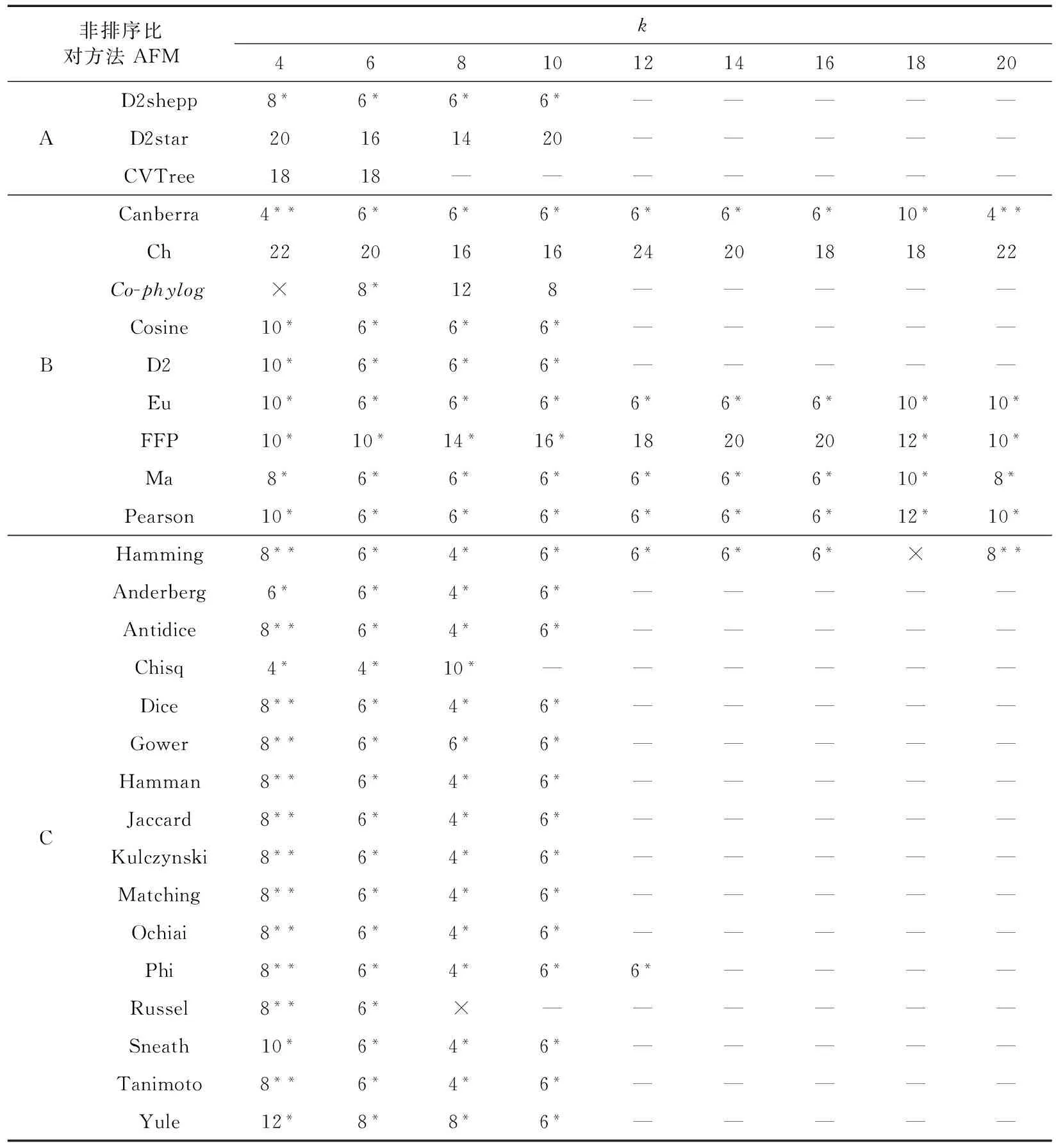
表1 最大似然树和不同k值下非排序比对聚类树Robinson-Foulds距离及主要拓扑关系比较Table 1 Robinson-Foulds distances and topology comparison between the Maximum Likelyhood treeand alignment-free comparison trees obtained using various k values
注: A. 基于校正后子序列集中独特序列的计数; B. 基于子序列集中独特序列的计数; C. 基于序列是否在子序列集中出现的计数;*AFM聚类树将序列划分为Ⅱ、Ⅲa、Ⅲb、Ⅳ 4个支系;**AFM聚类树呈现和ML树相同的(Ⅲa,(Ⅲb,Ⅳ))支系关系; × 明显错误的结果; — 运算无法在i7-6700HQ 2.60 GHz CPU、8 GB RAM配置的个人电脑上完成
Notes: A. methods using adjustedk-mer counts; B. methods based onk-mer counts only; C, methods based on presence/absence ofk-mers;*AFM tree clustering sequences into clades Ⅱ, Ⅲa, Ⅲb, and Ⅳ;**AFM tree shows a (Ⅲa, (Ⅲb, Ⅳ)) relationship observed also on the ML tree; × apparently strange result; — computation can’t be finished in a reasonable time on a laptop with i7-6700HQ 2.60 GHz CPU and 8 GB RAM
3 讨论
本工作表明,AFM聚类树可以被用于显示动物线粒体串联重复序列的关系和相似性,并达到较为理想的效果。对于棘腹蛙一组种下变异水平的WANCY序列,大多数(85.8%)算法和k值组合都可以成功地将其聚为Ⅱ、Ⅲa、Ⅲb、Ⅳ四大支。可见这些基于k长度子序列集的算法总体上对该系统中的主要序列差异有很好的判别能力。而且,很多方法都可以获得和蛋白编码序列树相近的结果。所测试的28种算法中,半数可在特定k值下产生和ML树拓扑结构非常接近、相差仅2个节点的聚类树,也能呈现前述序列差异较大的支系间的关系。最理想条件下,Canberra算法聚类树和ML树的差别仅存在于支系Ⅳ内的2个节点,有效地归纳和呈现了序列间的相似性及差异。这样的表现也提示了此类算法具有被运用于其他动物线粒体串联重复序列系统的潜力。
但是,不同AFM在本工作中的表现可以有很大的差异。和其他算法相比,D2star、CVTree、Ch、FFP算法所得聚类树无论是在大支关系还是在细节上,都和ML树有较大的差别。例如,不同k值所得Ch树和ML树的平均Robinson-Foulds距离为20,表明两者间的大多数节点都不同。这提示可能不是所有的AFM都适用于动物线粒体基因组复制重排区域序列的聚类。上述4种算法都基于子序列集中独特序列的计数,但表现最好的Canberra算法同属此类,不支持根据类型选择算法。这些结果提示了在不同复制重排系统中进行类似评估的必要性。
针对不同评估标准,不同算法内存在可以得出最理想聚类的特定k值,而且算法间表现出较高的一致性,具有规律。绝大多数得出最小Robinson-Foulds距离的组合中,k值为8。而在几乎全部得出和ML树支系关系一致的组合中,k值为4。Robinson-Foulds距离反映拓扑结构间的全部节点差异,不考虑节点位置所代表的序列间差异程度,显示在棘腹蛙WANCY系统中k值为8时可以很好地显示序列间的关系。作为经验数据,这与基于模拟数据所得出的适合于DNA序列聚类的8~10的k值域一致(Chanetal. ,2014)。大支间拓扑结构代表差异相对较大的序列间关系,本文所得适合解析这样关系的k值为4。该现象的实质是,不同的k值适合解析不同差异程度的序列间关系,存在权衡。这样的权衡已经在AFM中被发现。总的来讲,较小的k值适合聚类差异程度高的序列,较大的k值适合更相似序列(Bonham-Carteretal. ,2013),需要根据研究目的进行设置。而本研究结果表明,即使是种下水平的研究,也可能需要考虑这种权衡。如果聚类的目的是作为辅助手段展示序列间的异同,可以考虑对数据进行分层次的分析。例如,采用较小的k值聚类得到大支系间关系,在各支系内的聚类则设定较大的k值,再整合展示结果。另外值得一提的是,Canberra和Hamming算法在k值分别为4和20时得到较理想结果,但原因有待解析。
总结以上,本工作例证AFM可有效聚类蛙类WANCY序列,所得算法k值组合对类似系统有借鉴意义,揭示了AFM对于动物线粒体复制重排序列演化研究的价值。对于同一组数据,不同算法的表现可能迥异。WANCY区的主要特点是tRNA基因复制后随机假基因化并导致重排,对其他类型的复制重排区也可开展评估以辨识算法。k值的设定与序列差异程度相关,根据聚类目的可尝试对数据进行分层分析。
致谢:感谢中国科学院成都生物研究所戴强老师在数据分析中给予的帮助。
:
Almeida JS. 2013. Sequence analysis by iterated maps, a review[J]. Briefings in Bioinformatics, 15(3): 369-375.
Bernard G, Chan CX, Ragan MA. 2016. Alignment-free microbial phylogenomics under scenarios of sequence divergence, genome rearrangement and lateral genetic transfer[J]. Scientific Reports, 6: 28970.
Bonham-Carter O, Steele J, Bastola D. 2013. Alignment-free genetic sequence comparisons: a review of recent approaches by word analysis[J]. Briefings in Bioinformatics, 15(6): 890-905.
Chan CX, Bernard G, Poirion O,etal. 2014. Inferring phylogenies of evolving sequences without multiple sequence alignment[J]. Scientific Reports, 4: 6504.
Felsenstein J. 1989. PHYLIP-phylogeny inference package (version 3.2)[J]. Cladistics, 5(2): 164-166.
Fonseca MM, Harris DJ. 2008. Relationship between mitochondrial gene rearrangements and stability of the origin of light strand replication[J]. Genetics and Molecular Biology, 31(2): 566-574.
Haubold B. 2013.Alignment-free phylogenetics and population genetics[J]. Briefings in Bioinformatics, 15(3): 407-418.
Hide W, Burke J, Da Vison DB. 1994. Biological evaluation of d2, an algorithm for high-performance sequence comparison[J]. Journal of Computational Biology, 1(3): 199-215.
Höhl M, Ragan MA. 2007. Is multiple-sequence alignment required for accurate inference of phylogeny?[J]. Systematic Biology, 56(2): 206-221.
Höhl M, Rigoutsos I, Ragan MA. 2006. Pattern-based phylogenetic distance rstimation and tree reconstruction[J]. Evolutionary Bioinformatics Online, 2(1): 359-375.
Jiang B, Song K, Ren J,etal. 2012. Comparison of metagenomic samples using sequence signatures[J]. BMC Genomics, 13: 730.
Jun SR, Sims GE, Wu GA,etal. 2010. Whole-proteome phylogeny of prokaryotes by feature frequency profiles: an alignment-free method with optimal feature resolution[J]. Proceedings of the National Academy of Sciences, 107(1): 133-138.
Lanfear R, Frandsen PB, Wright AM,etal. 2016. PartitionFinder 2: new methods for selecting partitioned models of evolution for molecular and morphological phylogenetic analyses[J]. Molecular Biology and Evolution, 34(3): 772-773.
Larkin MA, Blackshields G, Brown NP,etal. 2007. Clustal W and Clustal X version 2.0[J]. Bioinformatics, 23(21): 2947-2948.
Lu YY, Tang K, Ren J,etal. 2017. CAFE: aCcelerated Alignment-FrEe sequence analysis[J]. Nucleic Acids Research, 45: W554-W559.
Qi J, Luo H, Hao B. 2004. CVTree: a phylogenetic tree reconstruction tool based on whole genomes[J]. Nucleic Acids Research, 32: W45-W47.
Ren J, Song K, Deng M,etal. 2016. Inference of Markovian properties of molecular sequences from NGS data and applications to comparative genomics[J]. Bioinformatics, 32(7): 993-1000.
Robinson DF, Foulds LR. 1981. Comparison of phylogenetic trees[J]. Mathematical Biosciences, 53(1-2): 131-147.
San Mauro D, Gower DJ, Zardoya R,etal. 2006. A hotspot of gene order rearrangement by tandem duplication and random loss in the vertebrate mitochondrial genome [J]. Molecular Biology and Evolution, 23(1): 227-234.
Sims GE, Jun SR, Wu GA,etal. 2009a. Whole-genome phylogeny of mammals: evolutionary information in genic and nongenic regions[J]. Proceedings of the National Academy of Sciences, 106(40): 17077-17082.
Sims GE, Jun SR, Wu GA,etal. 2009b. Alignment-free genome comparison with feature frequency profiles (FFP) and optimal resolutions[J]. Proceedings of the National Academy of Sciences, 106(8): 2677-2682.
Song K, Ren J, Reinert G,etal. 2013. New developments of alignment-free sequence comparison: measures, statistics and next-generation sequencing[J]. Briefings in Bioinformatics, 15(3): 343-353.
Stamatakis A. 2014. RAxML version 8: a tool for phylogenetic analysis and post-analysis of large phylogenies[J]. Bioinformatics, 30(9): 1312-1313.
Sukumaran J, Holder MT. 2010. DendroPy: a Python library for phylogenetic computing[J]. Bioinformatics, 26(12): 1569-1571.
Ulitsky I, Burstein D, Tuller T,etal. 2006. The average common substring approach to phylogenomic reconstruction [J]. Journal of Computational Biology, 13(2): 336-350.
Vinga S, Almeida J. 2003. Alignment-free sequence comparison-a review[J]. Bioinformatics, 19(4): 513-523.
Vinga S. 2013.Information theory applications for biological sequence analysis[J]. Briefings in Bioinformatics, 15(3): 376-389.
Vinga S. 2014. Alignment-free methods in computational biology[J]. Briefings in Bioinformatics, 15(3): 341-342.
Wang Y, Liu L, Chen L,etal. 2014. Comparison of metatranscriptomic samples based onk-tuple frequencies[J]. PLoS ONE, 9(1): e84348. DOI: 10.1371/journal.pone.0084348.
Wu TJ, Huang YH, Li LA. 2005. Optimal word sizes for dissimilarity measures and estimation of the degree of dissimilarity between DNA sequences[J]. Bioinformatics, 21(22): 4125-4132.
Xia Y, Zheng Y, Murphy RW,etal. 2016. Intraspecific rearrangement of mitochondrial genome suggests the prevalence of the tandem duplication-random loss (TDLR) mechanism inQuasipaaboulengeri[J]. BMC Genomics, 17: 965.
Yi H, Jin L. 2013.Co-phylog: an assembly-free phylogenomic approach for closely related organisms[J]. Nucleic Acids Research, 41(7): e75. DOI: 10.1093/nar/gkt003.
Zielezinski A, Vinga S, Almeida J,etal. 2017. Alignment-free sequence comparison: benefits, applications, and tools[J]. Genome Biology, 18(1): 186.
猜你喜欢
医学研究生学报(2022年5期)2022-12-07
中华实用诊断与治疗杂志(2022年1期)2022-08-31
海洋通报(2021年1期)2021-07-23
生物学通报(2021年4期)2021-03-16
铁道通信信号(2019年6期)2019-10-08
神州民俗(2018年9期)2018-11-21
流行色(2017年1期)2017-05-31
雷达学报(2017年6期)2017-03-26
新西部·中旬刊(2016年5期)2016-06-08
互联网天地(2016年1期)2016-05-04
