
支持告警序列差分隐私保护的网络入侵关联方法
2018-05-30 01:37李洪成吴晓平
计算机工程 2018年5期
李洪成,吴晓平
(海军工程大学 信息安全系,武汉 430033)
0 概述
随着网络攻击的复杂性、持续性和针对性不断提高,网络攻击的检测工作越来越困难。目前高级网络攻击往往采用逐层渗透的方式达到攻击目的[1-3],因此,现有的高级网络攻击检测工作大多建立在各个安全机构对威胁告警信息进行协同共享的基础上[4-5],进而通过告警信息的关联分析来识别入侵轨迹,为有针对性的网络安全防御工作提供铺垫[6-7]。
然而,网络威胁告警中可能包含被攻击者的网络拓扑、安全配置和服务等敏感信息,同时遭受网络攻击的企业部门往往不希望将针对自己的攻击事件完全公之于众[8]。因此,隐私保护是网络安全数据共享和协同检测急亟需突破的瓶颈,需要采用满足隐私保护的网络告警协同关联分析方法,在有效检测网络攻击行为的同时,保护共享的告警隐私信息。
在满足隐私保护的告警关联研究方面,有很多学者做了卓有成效的研究工作。文献[9]利用概念层次法对告警数据进行泛化,将告警信息中的离散属性值用更高层次的概念代替(例如用网络地址代替IP地址),并将连续属性值用间隔代替,然后设计了利用泛化告警进行因果关联的方法,在告警关联分析时采用乐观策略,将可能建立关联的告警构成关联图,并计算关联成功的概率,利用概率阈值和时间约束对关联图进行聚合,进而降低泛化告警关联的误差。该方法的缺点是告警的因果关系过分依赖于预定义的谓词知识。针对此问题,文献[10]提出了基于频繁序列挖掘的隐私保护告警关联方法,利用k-匿名算法对告警进行泛化,设计了类Apriori方法挖掘泛化后的频繁告警序列,并通过支持度评估优化了候选序列生成方法,在关联效率和隐私性之间实现了较好的折中。然而,基于概念层次法和k-匿名的隐私保护模型在应对基于背景知识的恶意分析时存在较大隐患,恶意分析者可利用再识别攻击和Link攻击[11-12]等手段发现告警中的隐私信息。在大数据时代,分析者所拥有的背景知识越来越多,给数据隐私保护带来了巨大挑战。为应对任意背景知识下的恶意分析,文献[13]提出了差分隐私保护模型,该模型在最大背景知识假设下,提供了严格且可证明的隐私保护定义。
本文提出一种支持差分隐私保护的网络告警关联分析方法,一方面最大程度地保护告警序列的隐私信息,另一方面利用频繁告警序列挖掘关联网络告警,为网络告警协同安全分析问题提供一种有效的解决方案。
1 差分隐私保护
差分隐私保护技术属于一类基于信息干扰的隐私保护技术,对离散型和连续型数据分别采用随机响应和随机噪声添加机制来完成干扰,同时使经过处理后的数据仍可以完成一定的统计、查询或挖掘任务,并保证一定程度上的可用性[14]。
差分隐私保护算法的设计要求是删除或更改数据集中任何一条记录对于查询结果几乎不产生影响,即使恶意分析者掌握除敏感记录之外的其他所有记录,仍不能获取该敏感记录的信息。因此,差分隐私保护能够抵御任意背景知识下的分析行为[15]。该算法的原理如下:
设分析者的数据分析操作为算法F,算法A对算法F的分析结果进行隐私泛化处理,使之满足差分隐私保护要求。
定理1设数据集D和D′是最多只差一条记录的2个数据集,Range(A)为泛化算法A的值域,Pr[X]是事件X出现的概率,如果对于所有S∈Range(A)都满足:
Pr[A(D)⊆RA]≤eε×Pr[A(D′)⊆RA]
(1)
那么泛化算法A提供ε-差分隐私。在式(1)中,ε表示隐私保护预算。
全局敏感度是数据分析函数的一项固有属性,表示某一记录删除或改变对分析结果的影响,其定义如下:
定义1数据分析函数F的全局敏感度为:
(2)
其中,‖·‖1为向量的1-范数,即所有元素的绝对值之和。
在具体的实现方法上,差分隐私保护利用Laplace机制实现连续型数据的随机噪声添加,并利用指数机制实现离散型数据的随机相应。下面对本文中使用到的Laplace机制进行介绍。
定理2若数据集D的分析结果表示为F(D),其全局敏感度用ΔF表示,那么泛化算法A(D)=F(D)+Y支持差分隐私保护,当且仅当随机数Y服从尺度为ΔF/ε的Laplace分布,其概率密度函数为:
(3)
在设计满足差分隐私的数据分析方法时,需要分配隐私预算并对隐私性进行证明,在这个过程中,需要用到差分隐私保护的2条重要性质,即序列组合性和并行组合性。

性质2若泛化算法Ai支持εi-差分隐私,则泛化算法在数据集上的一系列独立的处理过程支持max(εi)-差分隐私保护。
2 保护差分隐私的入侵告警关联方法
网络入侵检测系统、防火墙等安全设备检测出的威胁信息主要以告警的形式出现。在入侵轨迹识别过程中,定义网络告警数据类型为alert={Time,S_IP,D_IP,AttackType},其中,Time表示告警时间,S_IP表示源IP,D_IP表示目的IP,AttackType表示对应的攻击类型。
在差分隐私保护的实现机制上,本文不采用直接对每个序列的计数添加随机噪声的方法,而是在原始告警序列数据集的基础上,利用Laplace机制构建噪声前缀树。由于前缀树中节点的计数比每个序列的计数要大,在前缀树节点上添加噪声对于数据集的可用性影响较小,因此可以在隐私保护预算一致的情况下,应尽可能降低对算法准确性的影响。
本文告警关联方法的具体过程如图1所示。

图1 本文告警关联方法流程
2.1 噪声告警序列前缀树构建
在构建噪声前缀树之前,首先对前缀树进行定义。
定义2告警序列前缀:告警序列S=
定义3告警序列前缀树:原始告警序列数据集D的前缀树PT是一个三元组PT=(V,E,Root(PT)),其中:Root(PT)是PT的虚拟根节点;V是用告警记录标记的节点集合,每个节点v对应着D中某个特定的前缀prefix(v,PT),即从Root(PT)到v的序列;E是连接各节点的连边集合。
在告警序列前缀树中,节点v以二元组(tr(v),c(v))的结构存储,其中,tr(v)表示告警序列数据集D中以prefix(v,PT)为前缀的序列记录的集合,c(v)是对|tr(v)|添加噪声后的结果。此外,记前缀树中深度为i的节点组成的集合为level(i,PT),Root(PT)的深度为0。
为使原始数据集D中的告警序列满足差分隐私保护的要求,需要保证所有可能的告警记录均以一定的概率出现在泛化后的数据集中。噪声前缀树的构建过程如算法1所示。
算法1噪声告警序列前缀树构建
输入原始告警序列数据集D,隐私保护预算ε,前缀树深度h,可能的告警记录集合U

1.i=0;
3.ε-=ε/h;
4.while i 6. for each u∈U do 7. 将u作为v的候选子节点; 9. c(u)=NoisyCount(|tr(u)|,ε-); 10. if c(u)≥θ then 12. end if 13. end for 14. end for 15. i++; 16.end while 算法第6行~第13行是关键,即判断新的子节点u是否应加入树中,并计算tr(u)和c(u)。核心的步骤是判断c(u)是否达到阈值θ,若达到则将节点u加入树中。 利用噪声前缀树发布泛化告警序列数据的基本思路是从叶子节点依次向上进行一次遍历,计算在每个节点处v终止的告警序列数量count(v),并将count(v)个prefix(v,PT)加入到泛化告警序列数据集D中。count(v)的计算公式为: (4) 泛化告警序列数据的发布过程如算法2所示。 算法2泛化告警序列数据发布 2. if children(v)=ø//如果v是叶子节点 6.end for 在识别频繁入侵轨迹过程中,需要挖掘出频繁告警序列。传统的基于类Apriori的频繁序列模式挖掘方法需要生成候选序列集,需要遍历数据集的次数过多,而PrefixSpan算法可以在不生成候选序列的情况下高效挖掘频繁序列,有效减少了遍历次数和挖掘时间。因此,本文提出基于PrefixSpan的入侵轨迹序列挖掘方法,算法的具体步骤如下: 步骤3输出满足min_sup的 步骤4在各后缀数据库内,重复步骤1~步骤3,对于新生成的频繁告警序列,加上其前缀作为长频繁序列输出,直到生成的后缀数据库为空为止。 在泛化告警序列数据发布和频繁入侵轨迹序列挖掘过程中,仅仅是使用了加噪前缀树作为输入,并没有在发布和挖掘中对数据集进行隐私保护操作,因此,这两部分过程不占用隐私保护预算。 综上,第2.1节~第2.3节提出的告警关联过程满足ε-差分隐私保护要求。 实验计算机配置如下:操作系统为Ubuntu 16.04,CPU为3.30 GHz,内存为2.99 GB。使用LLDoS1.0攻击场景中inside内网的流量数据。该攻击场景数据取自一个典型的分布式拒绝服务攻击案例,该攻击场景的具体过程已通过官方文档给出。实验通过将得到的攻击轨迹与官方文档描述进行对比来验证本文方法的有效性。 利用入侵检测系统Snort处理LLDoS1.0 inside攻击场景数据,并激活Snort的全部rules规则,得到的攻击告警数据记录共1 820条。实验中各告警类型代表的主要攻击行为及其在DDoS中对应的攻击阶段如表1所示,其中,告警类型和主要攻击行为的信息均由Snort提供。 表1 告警类型、攻击行为及攻击阶段间的对应关系 在以上的告警数据库中,将特定时间窗内的告警按时间顺序排序,生成原始的告警序列数据库。在不同隐私保护预算下,利用第2.1节提出的方法构建噪声前缀树,并在此基础上利用第2.2节方法生成泛化后的告警序列数据集。不同隐私保护预算下,泛化数据集中告警序列的数量如表2所示,其中结果取10次实验的平均值。 表2 泛化数据集中告警序列的数量 在泛化告警序列数据集中,利用第2.3节提出的频繁告警序列挖掘算法挖掘频繁告警序列,通过反复实验,当时间窗口取120 s、支持度阈值min_sup取0.01时,关联准确度最高。此时,不同隐私保护预算下得到的告警关联结果如表3所示,其中结果为取10次实验的平均值。 表3 不同隐私保护预算下的告警关联结果 考虑到在特定时间窗内相邻攻击步骤间的关联为正确关联,由表1中各攻击步骤之间的递进关系可知,在表3中,type1→type2、type2→type3、type3→type4和type4→type5为正确关联,type2→type5和type1→type4为误关联。关联准确率的计算公式为: (4) 其中,NCOR_T为正确关联数,NCOR为所有关联数。因此,原始数据集和泛化数据集的关联准确率如图2所示。 图2 原始数据集和泛化数据集的关联准确率 由图2可以看出,当隐私保护预算ε>0.5时,本文算法的关联结果准确率达到较高水平。因此,本文算法可以在实现隐私性的情况下,保证告警关联结果具有较好的准确性。另外,图2中当隐私保护预算ε较小时,关联准确率随着ε的增加而显著增加,当ε增大到一定值时,关联准确度的增加速度趋于平缓,而考虑到隐私保护预算ε与添加噪声的尺度参数成反比,因此用在处理LLDoS1.0 inside攻击场景对应的告警序列数据集时,隐私保护预算ε取0.5~1.0有利于实现算法隐私性和可用性的平衡。 本文利用基于Laplace机制的噪声前缀树对告警序列数据进行泛化,使其满足差分隐私保护要求,并利用频繁序列挖掘完成告警关联分析,实现了告警序列隐私性和告警关联准确性的折中。下一步将利用告警关联分析的结果识别网络攻击轨迹,并获取关键网络节点和网络安全态势信息。此外,为更好地缓解告警序列隐私性和告警关联准确性之间的矛盾,在保证隐私保护水平的前提下,将综合利用Laplace机制和指数机制减少随机噪声的添加量。 [1] FRIEDBERG I,SKOPIK F,SETTANNI G,et al.Combating advanced persistent threats:from network event correlation to incident detection[J].Computers & Security,2015,48(7):35-57. [2] 张小松,牛伟纳,杨国武,等.基于树型结构的APT攻击预测方法[J].电子科技大学学报,2016,45(4):582-588. [3] 胡 彬,王春东,胡思琦,等.基于机器学习的移动终端高级持续性威胁检测技术研究[J].计算机工程,2017,43(1):241-246. [4] ALI A R,MORTEZA A,REZA E A.RTECA:real time episode correlation algorithm for multi-step attack scenarios detection[J].Computer & Security,2015,49:206-219. [5] KAYNAR K,SIVRIKAYA F.Distributed attack graph generation[J].IEEE Transactions on Dependable and Secure Computing,2015,5(1):12-23. [6] MODAMMAD G,ABBAS G B.E-correlator:an entropy-based alert correlation system[J].Security and Communication Networks,2015,8(5):822-836. [7] 刘 敬,谷利泽,钮心忻,等.基于神经网络和遗传算法的网络安全事件分析方法[J].北京邮电大学学报,2015,38(2):50-54. [8] CHEN R,FUNG B,DESAI B C.Differentially private trajectory data publication[EB/OL].(2011-12-09)[2017-01-21].http://arxiv.org/abs/1112.2020. [9] XU D B,NING P.Privacy-preserving alert correlation:a concept hierarchy based approach[C]//Proceedings of the 21st Annual Computer Security Applications Conference.New York,USA:[s.n.],2005:53-62. [10] 马 进,金茂菁,杨永丽,等.基于序列模式挖掘的隐私保护多步攻击关联算法[J].清华大学学报(自然科学版),2012,52(10):1427-1434. [11] 卢国庆,张啸剑,丁丽萍,等.差分隐私下的一种频繁序列模式挖掘方法[J].计算机研究与发展,2015,52(12):2789-2801. [12] 柴瑞敏,冯慧慧.基于聚类的高效(K,L)-匿名隐私保护[J].计算机工程,2015,41(1):139-142. [13] DWORK C.A firm foundation for private data analysis[J].Communications of the ACM,2011,54(1):86-95. [14] 宋 健,许国艳,夭荣朋.基于差分隐私的数据匿名化隐私保护方法[J].计算机应用,2016,36(10):2753-2757. [15] 张啸剑,孟小峰.面向数据发布和分析的差分隐私保护[J].计算机学报,2014,37(4):927-949.


2.2 泛化告警序列数据发布
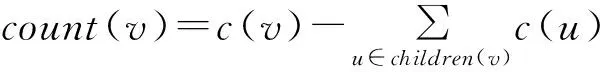






2.3 频繁入侵轨迹序列挖掘

2.4 算法隐私性分析


3 实验与结果分析




4 结束语
猜你喜欢
数学杂志(2022年5期)2022-12-02
新世纪智能(数学备考)(2021年9期)2021-11-24
新世纪智能(数学备考)(2021年5期)2021-07-28
数学年刊A辑(中文版)(2020年3期)2020-10-27
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
中学生数理化·八年级物理人教版(2017年9期)2017-12-20
读者(2017年5期)2017-02-15
信息安全研究(2015年3期)2015-02-28
噪声与振动控制(2015年4期)2015-01-01
