
基于LDA模型的文本聚类检索
2018-06-28 02:55李霄野李春生张可佳
计算机与现代化 2018年6期
李霄野,李春生,李 龙,张可佳
(东北石油大学计算机与信息技术学院,黑龙江 大庆 163318)
0 引 言
信息化媒体的迅速发展使得网络上存在大量的新闻数据,如何从这些数据中检索到用户需要的信息成了当今研究的热点内容。计算机对于中文的处理比对于西文的处理存在更大的难度,集中体现在对文本分类的处理上。在这种背景下,利用聚类分析技术对文本数据进行简化处理,对检索出的结果进行重新组织,加快信息检索速度,实现信息的个性化推送都是一系列极具发展前景的应用。文本聚类是一种无监督的、不需要训练过程的、不需要预先对文档手工标注类别的机器学习方法。这种方法具有一定的灵活性且有较强的自动化处理能力,具体体现在其能够将无结构的自然语言文本转化成可供计算机计算的特征文本,现已成为一种处理文本信息的重要手段,被越来越多的研究人员关注[1]。相似度计算是文本聚类中非常重要的一个步骤,以往在判断2个文档的相似度时,通常是根据查看2篇文档中共同包含单词的数量多少,例如TF-IDF(Term Frequency-Inverse Document Frequency)模型,但是可能存在2个文档之间几乎没有相同的词,而2个文档的语义相似,这种方法没有考虑文字背后的语义关联,导致检索系统对用户的查询需求有偏差,返回的结果不够全面[2]。所以在判断文档相似性时需要挖掘出文档的语义,而语义挖掘的关键在于选取合适的主题模型,LDA(Latent Dirichlet Allocation,潜在狄利克雷分配模型)就是其中一种比较有效的潜在语义模型。采用LDA模型进行文本建模,分析每个文档的主题分布,挖掘其潜在的语义知识,有利于完善单纯使用关键词方法所造成丢失信息的缺陷。因此本文设计一种基于LDA模型的文本聚类技术,应用到凤凰网网站的检索中,实现类簇中的主题发现,提高信息检索的准确率。
1 LDA主题模型
1.1 LDA基本原理
LDA是一种挖掘文本潜在主题的概率生成模型,它依据此常识性假设:隐含主题集是由一系列相关特征词组成,文档集合中所有文档均按照一定比例共享隐含主题集合。LDA模型是一种经典的贝叶斯模型,分为文档集层、主题层及特征词层,每层均有相应的随机变量或参数控制。所谓生成模型,就是每一篇文档都是由其隐含的主题随机组合生成,每一个主题对应特定的特征词分布,不断抽取隐含主题及其特征词,直到遍历完文档中的全部单词。因此把各个主题在文档中出现的概率分布称为主题分布,把各个词语在某个主题中出现的概率分布称为词分布[3]。利用LDA模型生成文档,首先需要生成该文档的一个主题分布,再生成词的集合;根据文档的主题分布随机选择一个主题,然后根据主题中词分布随机选择一个词,重复这个过程直至形成一篇文档[4]。同时LDA主题模型对文档集进行内部语义信息分析,从而得出3层贝叶斯模型:文本-主题-特征词模型。假设所有文档存在K个隐含主题,LDA的图模型结构如图1所示。
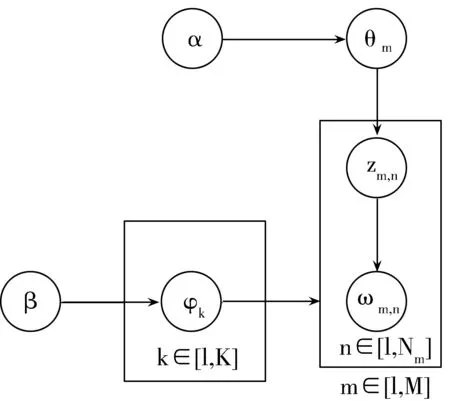
图1 LDA图模型结构
给定一个文档集合D={d1,d2,…,dM},M为文档总数,Nm为第m篇文档的单词总数。假设主题数为K个,α和β表示语料级别的参数,取先验分布为Dirichlet分布,其中α是每篇文档下主题的多项分布的Dirichlet先验参数,β是每个主题下特征词的多项分布的Dirichlet先验参数。主题向量θm为第m篇文档能生成主题的概率分布变量,每个文档对应一个θ,φk代表第k个主题下的特征词分布变量。对于第m篇文档中的第n个特征词ωm,n,生成第m篇文档中第n个词的主题zm,n。ωm,n是可以观测到的已知变量,α和β是根据经验给定的先验参数,把θm、φk和zm,n当作隐藏变量,根据观察到的已知变量估计预测[5]。根据LDA的图模型结构,可以推理出所有变量的联合分布:对于第m篇文档中第n个特征词ωm,n(1≤n≤Nm,1≤m≤M),生成一个主题zn服从隐含变量θ的多项式分布;根据先验参数β,对特征词ωn生成P(ωn|zn,β)。则每个文档的概率密度函数为:
(1)
1.2 Gibbs Sampling抽样算法
主题模型中假设每个词对应一个不可观测的隐主题,由于在LDA概率生成模型中不能直接获得参数θ和φ的值,所以需要通过参数估计的方法近似推理主题参数值,得到主题间的联合分布。常用的估计参数方法有变分推理、Laplace近似、Gibbs Sampling抽样算法和期望-扩散[6]。其中Gibbs Sampling随机抽样算法以其实现简便、计算速度快的优势广泛地应用于LDA概率生成模型中。Gibbs Sampling抽样算法属于一种特殊的MCMC(Markov Chain Monte Carlo,马尔科夫链蒙特卡洛方法)算法。马尔科夫链是一种离散的随机过程,MCMC方法就是使用蒙特卡洛方法计算积分进而构造合适的马尔科夫链进行抽样。Gibbs Sampling抽样算法的核心理念为交替地固定概率向量中的某一维度,通过其他维度的变量值,抽样确定该维度的值,不断迭代直到收敛,输出待估参数。这种方法只对二维以上的高维情况有效[7]。利用Gibbs Sampling算法学习LDA模型参数的过程如下:
1)初始化特征词。给文本中的每个单词随机分配主题z(0)。
2)特征词数量统计。统计每个主题z中出现的特征词数量和每个文档m下出现主题z中的特征词的数量。
3)主题概率计算。去除当前词的主题分布,根据其他所有词的主题分布估计当前词分布各个主题的概率。每轮估算一次主题分布概率P(zi|z,d,ω),其中P(zi|z,d,ω)也称为吉布斯更新规则(Gibbs updating rule),如公式(2)所示:
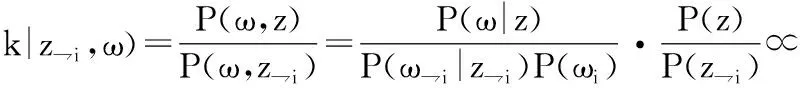

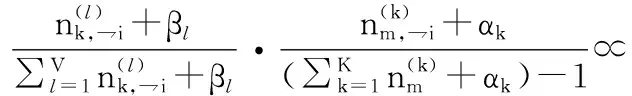
(2)
4)随机抽取。根据当前词属于所有主题z的分布概率为该词随机地抽取一个新主题z(1)。
5)循环。用步骤4中的方法不断随机抽取下一个词的主题,当发现第m篇文档下的主题分布变量θm和第k个主题下的特征词分布变量φk收敛时,输出θm、φk。最终得出每个词的主题zm,n[8]。
当Gibbs结果收敛后,根据最后文档集中所有单词的主题分布来估算多项式分布的参数θm、φk的值,如公式(3)、公式(4)所示:
(3)
(4)
2 文本聚类
2.1 文本聚类的原理
文本聚类(text clustering)是传统聚类算法在文本挖掘领域的应用,实质上是把一个文本集分成若干子集的过程,划分出的子集称为簇,各个簇中的文本相似性较大,各个簇之间的文本相似性较小[9]。文本聚类能够帮助用户有效地导航、总结和组织文本信息,是文本信息检索的核心技术,也是一种在文本信息处理过程中用到的知识获取方法。简而言之,文本聚类是从很多文档中把一些相似内容的文档聚为一类的一种方法。文本聚类的算法主要包括基于划分、基于层次、基于模型、基于网络、基于模糊等聚类算法[2],本文采用划分聚类算法对文档进行聚类,该方法可在任意范数下进行聚类,对数值属性有很好的几何统计意义。
2.2 划分聚类算法
基于划分的聚类算法主要包括K-means算法、K-中心点算法和大型数据库划分法,划分聚类要求将文档集分割成K个类,而且每个类最低包含一个文档,其流程如图2所示。

图2 划分聚类算法流程图
K-means算法是一种经典的基于划分的聚类算法。首先任意选择K个文档作为初始的聚类中心点,对于剩下的其他文档,计算其与聚类中心的相似度,然后分配给最近似的聚类,再重新计算新的聚类中心,重复迭代直到聚簇的划分结果不再改变。这种方法以其简单、快速、高效的特点被广为使用。传统的K-means聚类算法中,聚类中心的选择是整个算法过程的关键[10]。随机地选择聚类中心会导致每次聚类的结果有差异,从而不能较好地反馈聚类的实际情况,所以本文采用优化聚类中心选择的K-means++算法对测试数据进行聚类。该算法的基本思想是初始的聚类中心之间的相互距离要尽可能地远。假设D(x)为样本集中每一个点x到最近聚类中心的距离,该算法的过程如下:
1)随机选取数据点集合N中一个点作为第一个聚类中心p1;
3)不断重复步骤2直到聚类中心不再变化,得到K个聚类中心;
4)利用第K个聚类中心执行标准的K-means聚类算法对数据进行聚类[11]。
2.3 聚类的有效性评价
对于一个聚类是否有效,通常会对聚类的实际效果进行评价。常用的聚类有效性评价标准有外部标准和内部标准。外部标准通过测量聚类结果和参考标准的一致性来评价聚类结果的好坏,内部标准则是用于评价同一聚类算法在不同聚类条件下聚类结果的好坏,根据聚类结果的优劣选取最佳聚类数。本文从外部标准引入2种常用的评价指标,纯度Purity评价方法和F-measure评价方法。
2.3.1 纯度Purity评价方法
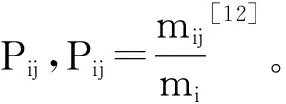
Pi=max (Pij)
(5)
整个聚类划分的纯度Purity为:
(6)
其中K是聚类的数目,m是整个聚类划分所涉及的成员个数。
2.3.2 F-measure评价方法
F-measure是信息检索领域评价聚类效果的一个标准,简称F值,它是准确率(Precision,又称精度)与召回率(Recall)的结合。准确率和召回率是广泛用于信息检索和分类体系等领域的2个重要指标,其中准确率是系统检索到的相关文档数与系统所有检索到的文档总数的比率,召回率是指系统检索到的相关文档数和系统所有相关的文档总数的比率,这2个指标可以用来评价检索结果的质量[13]。
在一个大规模数据集合中检索文档时,对每个查询(Query)可以统计出以下4个值:
1)TP:检索到的,相关的。
2)FP:检索到的,但是不相关的。
3)FN:未检索到的,但却是相关的。
4)TN:未检索到的,也不相关的。

F-measure的公式定义如下:
(7)
其中,β为调和系数,一般取β=1,P为准确率,R为召回率。此种方法适用于更看中准确率或召回率中某一特性时使用。在聚类有效性评价中,全局聚类的F值可通过F值的加权平均求得,公式如下:
(8)
3 实验设计及结果分析
3.1 实验数据选取
本文采用的实验数据来自国内知名综合门户网站凤凰网。分别选取网站中财经、体育、房产、文化、科技这5个版块中的新闻文档,利用网络爬虫对其进行数据采集,共采集了2017年10月25日至10月28日的新闻1310篇。首先使用IKAnalyzer分词软件对实验数据进行文本预处理,并剔除中文常规停顿词,将文本向量化,表示为文档-特征词矩阵,之后用GibbsLDA建模工具对其进行LDA建模,得到文档的主题概率分布[14]。选取指定的潜在主题个数K的初始值为50,α=50/K,β=0.1,Gibbs随机抽样的次数T设定为1000。其中主题数K的取值依次为50,100,…,300,利用不同主题数进行多次聚类实验获得最优主题数K[15]。由图3可以看出,当K=150时,F值最高,聚类效果最好,所以选取主题数K为150。将数据用K-means++算法进行聚类,聚类中心数N设为50。
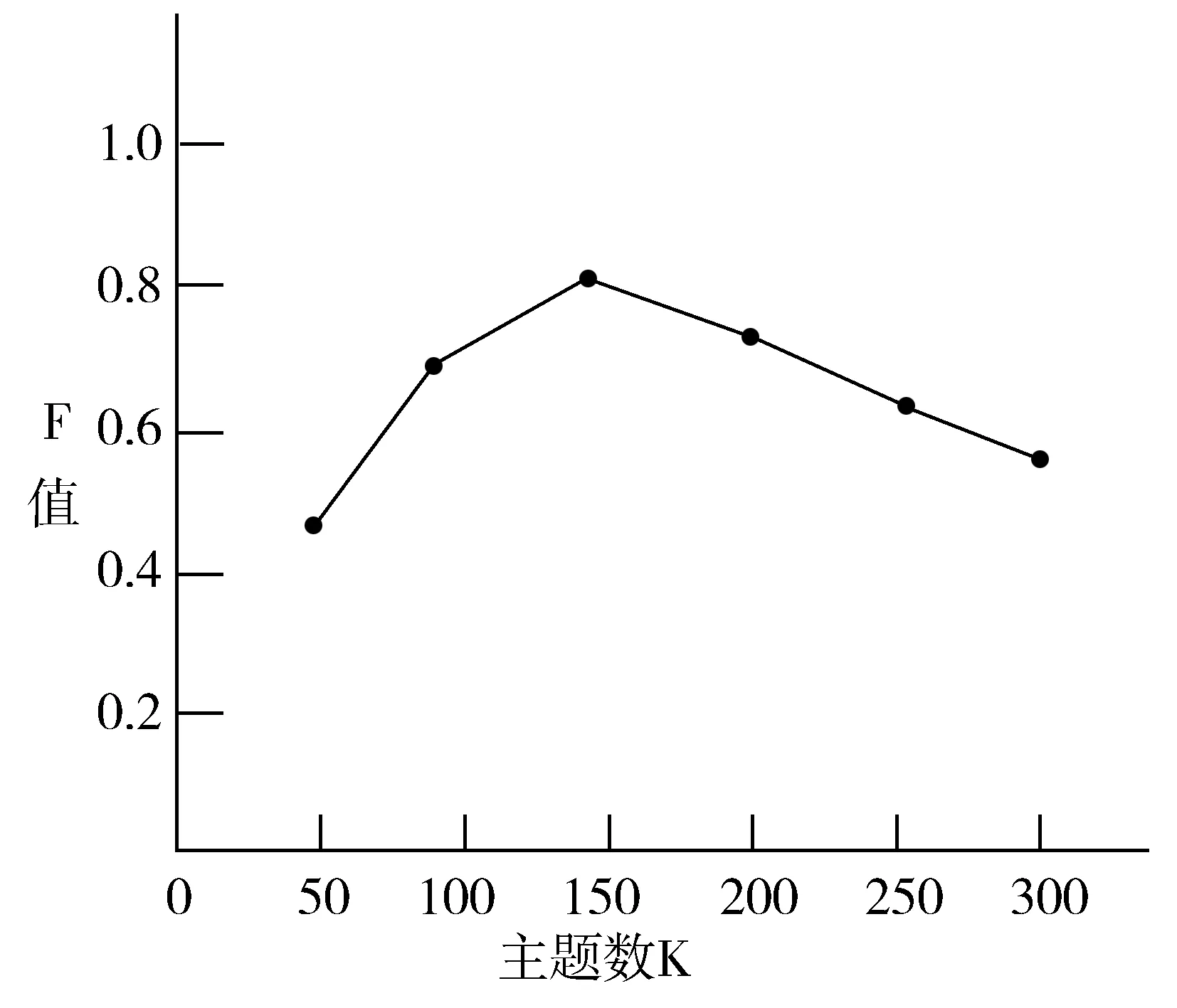
图3 不同主题数K下的F值
3.2 实验结果分析
本文的实验中,LDA-Gibbs模型生成的潜在主题-特征词模型部分结果如表1所示。从表1可以看出特征词描述的结果,Topic1中为经济股票方面的内容,Topic2中为体育运动方面的内容,Topic3中为房产家居方面的内容,Topic4中为文化艺术方面的内容,Topic5中为科技信息方面的内容。主题分类和原始分类基本一致,有些词的语义与主题不够贴切,可以通过进一步提高参数设定的精度来解决[16]。
表1 LDA-Gibbs主题-特征词模型结果
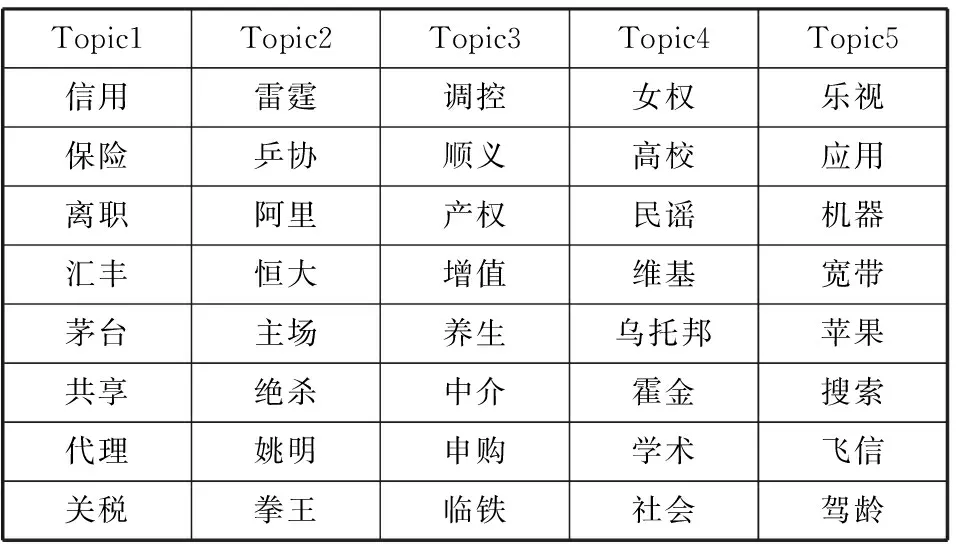
Topic1Topic2Topic3Topic4Topic5信用雷霆调控女权乐视保险乒协顺义高校应用离职阿里产权民谣机器汇丰恒大增值维基宽带茅台主场养生乌托邦苹果共享绝杀中介霍金搜索代理姚明申购学术飞信关税拳王临铁社会驾龄
首先将聚类实验分为2种方案进行对比,分别为:
1)数据预处理后选择传统的K-means聚类算法;
2)数据预处理后选择优化聚类中心的K-means++聚类算法。
经过实验验证,不同主题类别在不同的实验方案下,其聚类结果的准确率、召回率分别如表2、表3所示。
表2 传统K-means算法聚类分析评价
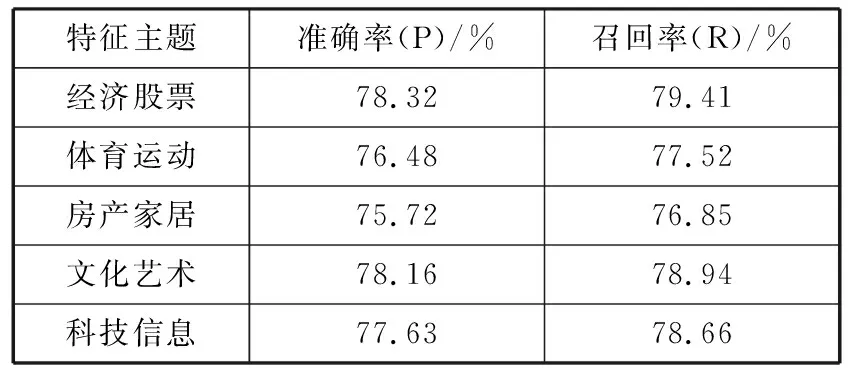
特征主题准确率(P)/%召回率(R)/%经济股票78.3279.41体育运动76.4877.52房产家居75.7276.85文化艺术78.1678.94科技信息77.6378.66
表3 优化聚类中心的K-means++算法聚类评价
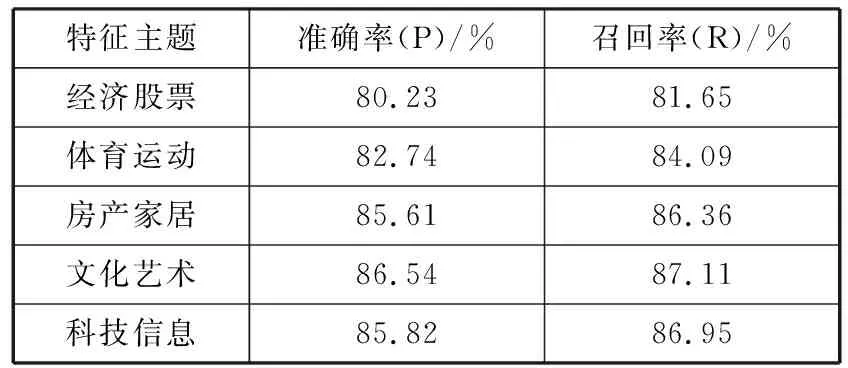
特征主题准确率(P)/%召回率(R)/%经济股票80.2381.65体育运动82.7484.09房产家居85.6186.36文化艺术86.5487.11科技信息85.8286.95
之后根据聚类结果的Purity(纯度)和F-measure这2方面对基于LDA-Gibbs模型和基于TF-IDF模型的文本聚类效果分别进行对比评价,如图4所示[17]。可以看出,本文设计的基于LDA-Gibbs的模型在Purity和F-measure方面都明显优于传统的TF-IDF模型,说明该模型的文本聚类的效果更好。综合上述实验可以看出,本文提出的基于LDA的文本聚类检索方法较为合理,具有推广价值。

图4 LDA-Gibbs模型与TF-IDF模型聚类效果对比
4 结束语
本文提出了一种基于LDA主题模型的文本聚类方法并将其应用到门户网站的主题挖掘中。根据LDA模型建立了文本主题空间,充分挖掘了文档的潜在主题,利用主题分布概率向量替代文本,降低了文本向量的维度,并利用K-means++算法对主题空间中的文本数据进行聚类,加快了聚类速度,进而提高了聚类的效果。最后从纯度和F特征值这2方面评价了聚类的有效性。实验结果表明,该方法能够较好地按主题对网站中的文本信息数据聚类,可以将其推广到信息检索领域,从而提高检索效率与准确率。
参考文献:
[1] 王鹏,高铖,陈晓美. 基于LDA模型的文本聚类研究[J]. 情报科学, 2015,33(1):63-68.
[2] 杨平,王丹,赵文兵. 微博网站中面向主题的权威信息搜索技术研究[J]. 计算机科学与探索, 2013,7(12):1135-1145.
[3] 董婧灵. 基于LDA模型的文本聚类研究[D]. 武汉:华中师范大学, 2012.
[4] 唐晓波,房小可. 基于文本聚类与LDA相融合的微博主题检索模型研究[J]. 情报理论与实践, 2013,36(8):85-90.
[5] Cao Buqing, Liu Xiaoqing, Liu Jianxun, et al. Domain-aware Mashup service clustering based on LDA topic model from multiple data sources[J]. Information and Software Technology, 2017,90:40-54.
[6] 李湘东,张娇,袁满. 基于LDA模型的科技期刊主题演化研究[J]. 情报杂志, 2014,33(7):115-121.
[7] Hajjem M, Latiri C. Combining IR and LDA topic modeling for filtering microblogs[J]. Procedia Computer Science, 2017,112:761-770.
[8] 焦潞林,彭岩,林云. 面向网络舆情的文本知识发现算法对比研究[J]. 山东大学学报(理学版), 2014,49(9):62-68.
[9] 马军红. 文本聚类算法初探[J]. 电子世界, 2012(6):71-72.
[10] 江浩,陈兴蜀,杜敏. 基于主题聚簇评价的论坛热点话题挖掘[J]. 计算机应用, 2013,33(11):3071-3075.
[11] Clyne B, Cooper J A, Hughes C M, et al. A process evaluation of a cluster randomised trial to reduce potentially inappropriate prescribing in older people in primary care (OPTI-SCRIPT study)[J]. Trials, 2016,17, doi: 10.1186/s13063-016-1513-z.
[12] 王振振,何明,杜永萍. 基于LDA主题模型的文本相似度计算[J]. 计算机科学, 2013,40(12):229-232.
[13] 孟雪井,孟祥兰,胡杨洋. 基于文本挖掘和百度指数的投资者情绪指数研究[J]. 宏观经济研究, 2016(1):144-153.
[14] Zhang Yi, Zhang Guangquan, Chen Hongshu, et al. Topic analysis and forecasting for science, technology and innovation: Methodology with a case study focusing on big data research[J]. Technological Forecasting and Social Change, 2016,105:179-191.
[15] Reddy A S S, Brik M G, Kumar J S, et al. Structural and electrical properties of zinc tantalum borate glass ceramic[J]. Ceramics International, 2016,42(15):17269-17282.
[16] 王军. 热门微博话题事件主题聚类分析[D]. 合肥:安徽大学, 2016.
[17] 陈晓美. 网络评论观点知识发现研究[D]. 长春:吉林大学, 2014.
猜你喜欢
客联(2022年3期)2022-05-31
计算机系统应用(2021年9期)2021-10-11
中国新闻周刊(2021年26期)2021-07-27
计算机技术与发展(2018年8期)2018-08-21
中国机械工程(2017年22期)2017-12-02
电脑爱好者(2017年7期)2017-05-06
专利代理(2016年1期)2016-05-17
中文信息学报(2015年4期)2015-04-21
质量与标准化(2010年5期)2010-05-03
