
深度学习的方法论辨析
2018-07-10 06:26张玉宏秦志光
重庆理工大学学报(社会科学) 2018年6期
张玉宏,秦志光
(1.电子科技大学 网络与数据安全四川省重点实验室, 四川 成都 6100542;2.河南工业大学 信息科学与工程学院, 河南 郑州 450001)
近年来,深度学习(Deep Learning)在诸多领域都有着很多惊人的表现[1]。例如,它在棋类博弈、计算机视觉、语音识别及自动驾驶等领域,表现得跟人类一样好,甚至更好。在2013年,深度学习被麻省理工学院的《MIT科技评论》(MITTechnologyReview)评为世界十大突破性技术之一[2]。
2016年3月,代表人类围棋顶级水平的李世石九段,以1∶4负于谷歌公司研发的阿尔法围棋(AlphaGo),这标志着人工智能在围棋领域已经超越人类,一时震惊四野。而在背后支撑AlphaGo具备如此强悍智能的技术之一,就是深度学习算法。一时间,深度学习,这个本专属于计算机科学的术语,成为包括学术界、工业界甚至风险投资界等众多领域的热词,它对我们的工作、生活甚至思维都已产生深远的影响。
当前,学者多从技术或工程实现的角度来研究这个议题,而从科技哲学的角度,尚未有深入的讨论。在深度学习备受瞩目的背后,我们不禁思考,人工智能的技术本质是什么,深度学习的技术哲学特性是什么,它成功背后的方法论又是什么?本文着重对以上几个问题进行讨论。
一、人工智能的技术本质
从宏观的视角来看,人类科学与技术的发展一路走来,主要依靠两条腿的“并驾齐驱”:一条腿是能量传输,从生火、烧柴、烧煤、蒸汽机,到火电、风电、太阳能及核聚变;另一条腿就是信息传输,从语言、文字、烽火台、穿孔卡、磁带、无线电,到硬盘、电子计算机、量子通信,它们大致都遵循着这样的规律:发现现象、深入认识和人工模拟(或重现)。
20世纪40年代以后,脑科学、神经科学、心理学及计算机科学等众多学科,取得了一系列重要进展,使得人们对大脑的认识相对“深入”,从而为科研人员从“观察大脑”到“重现大脑”搭起了桥梁,哪怕这个桥梁到现在还仅仅是个并不坚固的浮桥。而所谓的“重现大脑”,在某种程度上,就是目前的研究热点——“人工智能”。
1958年,神经生物学家大卫·休伯尔(David Hunter Hubel)与托斯坦·威泽尔(Torsten N.Wiesel)在动物视觉信息处理的研究中发现,对于视觉的信息处理,动物大脑皮层是分级、分层处理的[3-4]。正是因为这个重要的生理学发现,二人获得了1981年的诺贝尔医学奖。而这个科学发现的意义,并不仅仅局限于生理学,它还间接促成了人工智能在50年后的突破性发展。
休伯尔和威泽尔等人的研究表明(由于我们对大脑的认识非常有限,所以他们的研究也并非定论),大脑的工作过程是一个不断迭代、不断抽象的概念认知过程。动物视觉系统的信息处理就是这样分级完成的。这种分层次结构的感知系统,由于逐层抽象迭代,使大脑的视觉系统需要处理的数据量大大减少,但却保留了判别物体所需的最有用信息。
在人工智能领域,正是受到生物神经网络的启发,自20世纪80年代起,人工神经网络开始兴起,而且在很长一段时间,都是人工智能领域的研究热点。
简单来讲,人工智能就是为机器赋予与人类类似的智能。由于目前机器的核心部件是由晶体硅构成,所以可归属为“硅基大脑”。而人类的大脑主要由碳水化合物构成,因此可称之为“碳基大脑”。因此,从技术本质上来讲,现在的人工智能,大致就是用“硅基大脑”模拟或重现“碳基大脑”的过程[5]。
二、深度学习的技术哲学特性
从大脑对视觉信息处理的机理中,我们可以提炼出两个重要的特征:(1)迭代抽象;(2)分层处理。而这两点正是当前深度学习的核心特征。
2006年,加拿大多伦多大学的资深机器学习教授杰弗里·辛顿(Geoffery Hinton)在世界著名学术刊物《科学》(Science)上发表了一篇关于深度学习的开山之作[6]。在这篇文章中,辛顿给出了两个重要结论:(1)具有多个隐层的人工神经网络具备更佳的特征学习能力,多层网络之间,每一层都是以前一层提取的特征作为输入,并对其进行特定形式的变换,得到更加抽象的表达。而且这种层次化的特征提取过程可以叠加,从而让深度神经网络具备强大的特征提取能力;(2)可通过逐层初始化(layer-wise pre-training)方式来克服训练上的困难,而逐层初始化是通过无监督的自主学习完成的。
由此可以看出,深度学习的关键在于建立并模拟人脑进行分析学习的神经网络,它模仿人脑的机制来解析数据(如声音、图像和文本等)。深度学习可视为一种自动的特征学习方法,它把海量原始数据通过一些简单的但非线性的模型,转变成为更高层次的、更加抽象的表达[7]。
具体来说,深度学习的基本工作模式就是,除了输入层和输出层,中间还堆叠多个隐含层,前一层的输出作为下一层的输入。网络中每一层,都由无数神经元构成,而每个神经元都有一组“权值”和一个控制其输出启动的“激活函数”。神经网络的训练涉及到调整神经元的权值,使特定的输入产生我们需要的输出。通过这样的分层框架,就可以实现对输入信息进行分级表达。
深度学习中的“深度”,可理解为更大规模的网络,而“更大规模”可简单理解为包括“更多隐含层”,而“更多隐含层”在某种程度上也可理解为能够提取更高抽象层次的特征,因为每一层都可视为上一级网络的数据抽取变换,层数越多就越抽象,表达能力(如分类能力)也就越强。
深度学习之所以备受瞩目,是因为从最原始的输入层开始,到中间每一个隐含层的数据抽取变换,到最终的输出层的判断,所有特征的提取,全程都是一个没有人工干预的训练过程。这个自主特性,在机器学习领域是革命性的。
知名深度学习专家吴恩达(Andrew Ng)曾表示:“我们没有像通常(机器学习)做的那样,自己来框定边界,而是直接把海量数据投放到算法中,让数据自己说话,系统会自动从数据中学习。”谷歌大脑项目(Google Brain Project)的计算机科学家杰夫·迪恩(Jeff Dean)则说:“在训练的时候,我们从来不会告诉机器说:‘这是一只猫’。实际上,是系统自己发明或者领悟了‘猫’的概念。”
因此,深度学习不仅仅只是一种电子算法的升级,更是一种全新的思维模式。我们完全可以利用深度学习,通过对海量数据的快速处理,消除信息的不确定性,从而帮助我们认知世界。它带来的颠覆性在于,将人类过去痴迷的算法问题演变成数据和计算问题[8]。
三、深度学习的方法论
任何一个事物的成功,都需要一个比较成熟的方法论做指导,深度学习也不例外。为什么早期的人工神经网络屡屡折戟沉沙,而现在的深度学习却大获成功,这不仅要归功于计算机硬件性能的提升和大数据的累积,还要归功于人们在方法论认知上的改变。
(一)传统人工智能学派与还原主义
在过去,包括神经网络在内的大部分的人工智能系统,主要分为如下3个流派,如表1所示。

表1 人工智能的流派
传统的人工智能学派,事实上,大多希望遵循一种“还原主义(reductionism,或称还原论)”的思想来推动科学的发展。而“还原主义”,就其英文词根“reduction”的本意而言,就有“减少”“简化”等含义,意思就是把一种形式变化为另外一种更加简单的形式。在18世纪的科学术语中,“reduction”含义就是把化合物变化为相对简单的元素[9]。
仅从字面的定义就可以看出,“还原主义”里有一种“追本溯源”的含意包含其内,即一个系统(或理论)无论多复杂,都必须能够还原到逻辑原点。在意象上,最终可简单地从一个或几个简洁而漂亮的基本法则推导而出。比如说,很多经典力学问题,不论形式有多复杂,最后都可通过牛顿的三大定律得以解决。再比如,在电磁学领域,麦克斯韦方程组也异常简略完美。
随着伽利略、牛顿等科学巨匠开创近代意义上的科学以来,“还原论”在科学发展中发挥了巨大的作用。面对非线性复杂现象,经典科学家们总是设法忽略非线性影响因素,进而用线性模型来描述,甚至把能够构建出线性模式作为科学研究获得成功的标志,但这一标志也渐显疲态。例如,当代著名物理学家弗里曼·戴森(Freeman Dyson)在其著作《反叛的科学家》(TheScientistasRebel)一书中就提到,一些特别有成就的顶级科学家(比如爱因斯坦、奥本海默等),在功成名就之后,就特别容易犯一个“错误”,即抱负极大,总想用极少的几个基本原理解释世界上的一切事物[10]。
“还原论”的确雄心很大,试图一劳永逸地解决科学发展中的问题,并达到对未来的准确预测。可结果如何呢?事实上,并不乐观!戴森指出,爱因斯坦在美国苦苦研究几十年的统一场理论,没有新的发现,还对同时代的最新实验结果和物理发现视而不见,错过了太多的东西,实属遗憾。那么,问题出在哪里呢?
当代著名物理学家斯蒂芬·霍金在一次演讲中说:“除了非常简单的情况,我们无法准确解出这些理论的方程,在牛顿万有引力理论中,我们甚至连三体运动的问题都无法准确解出。在运用数学方程来预测人类行为上,我们极少成功。所以,即使我们确实找到了基本定律的完整集合,在未来的岁月里,仍然存在发展更好的方法,使我们在复杂而真实的情形下,完成对可能结果的有用预言的智慧,这是极富有挑战性的任务。”[11]
其实,早在19世纪,马克思、恩格斯等人就通过辩证法批判了还原论,将其总结为是孤立、静止地看世界。现代科学技术的发展表明,我们不能把事物的复杂性全部归因为认识过程不充分、不到位,而是必须承认复杂性的客观存在,它并不随着认识的深入而变得简单,变得可还原。1984年,诺贝尔物理学奖获得者盖尔曼(Murray Gell-mann)、诺贝尔物理学奖获得者安德森(Philip Anderson)、经济学奖获得者阿罗(Kenneth Arrow)深感还原论的局限性,提出超越还原论的口号,成立了圣塔菲研究所,专门从事复杂性科学的研究。1999年,美国著名学术期刊《科学》(Science)推出复杂性科学专刊,这标志着复杂性科学得到了国际科学共同体的认可[12]。霍金认为,复杂性科学是21世纪的科学[13]。我们应把复杂性当作复杂性来处理,其言外之意就是说我们应以复杂性本来的面目研究,而不要徒劳地把复杂性简单化、还原化,这或许是解决复杂性科学问题的最有效的方法论[14]。
(二)深度学习与复杂性理论
各类机器学习算法的解析过程,揭示出知识发现更可能是一个非线性的混沌过程[15]。倘若我们依然从传统的“还原论”出发,依靠单纯的线性组合思维(亦称为结构化思维)进行研究,势必会导致人工智能系统的设计功能过于简单,难以描绘智能的复杂内涵。
深度学习是人工智能的一个典型应用场景,它可视为是人类大脑思考过程的物化和工程化。如果我们希望模拟的是一个“类人”复杂系统,那么追求简化的还原论,自然就无法有效指导深度学习达到目标。具体说来,有如下两个方面的原因:
(1)这个世界(特别是有关人的世界)本身是个纷纭复杂的系统,问题之间互相影响,形成复杂的网络,这样的复杂系统,很难利用一个或几个简单的公式、定理来描述和界定。
(2)在很多场景下,受现有测量和认知工具的局限,很多问题在认识上根本就不具有完备性。因此,难以从一个“残缺”的认知中,提取适用于全局视角的公式和定理。柏拉图在《理想国》里就讲到了一个经典比喻——“洞穴之喻(Allegory of the Cave)”[16]。犹如洞穴人受限于链锁一样,会误把他们所能感知到的投影于洞壁的影像(二维世界),当作真实的世界(三维世界),洞穴人怎能基于一个二维世界观测的现象,来归纳出一个适用于三维世界的规律呢[17]?
但幸运的是,我们已到了大数据时代,大数据为我们提供了一种认知纷繁复杂世界的无比珍贵的资源——多样而全面的数据。有学者就认为,大数据时代之所以具有颠覆性,就是因为目前一切事物的属性和规律,只要通过适当的编码(即数字介质),就可以传递到另外一个同构的事物上,得以“无损”全息表达[18]。
但对于这个复杂的世界,直接抓住它的规律并准确描述它,是非常困难的。在一个复杂系统中,由于非线性因素的存在,任何局部信息都不可能代表全局。大数据时代有个典型的特征就是,“不是随机样本,而是全体数据(n=all)”[19](这里,n代表数量大小),而“全体数据”和复杂性科学中的“整体性”,在一定程度上是有逻辑对应关系的。深度学习所表现出来的智能,也正是“食”大数据而“茁壮成长”起来的,其智能所依赖的人工神经网络模型,还可随数据量的增加而“进化”或改良[20]。因此,深度学习可视为是在大数据时代遵循让“数据自己发声”的典范之作。如果说“大数据思维是一种复杂性思维”[21],那么深度学习就是这个思维体系结出的硕果。
(三)深度学习与自主性
在计算机科学领域,传统的计算机电子算法是将人类的知识和洞察转化为一行行结构化的程序。而现有的人工智能——具体体现为各种机器学习算法,表现大大不同,它们是由计算机自行从数据中发掘规律。这种自主性,让计算机不再仰仗人类的智慧,至少不全部依赖于人的经验。举例来说,AlphaGo的升级版AlphaGo Zero(译作阿尔法元),通过自我训练,以100∶0的战绩击败AlphaGo,便是一个有力的佐证。
复杂性科学认为,构成复杂系统的各个要素都自成体系,拥有自己的目标和行为,也就是说,它们具有独立的自主性和主动性,不像机械系统一样只会被动接受。复杂性科学资深学者普利高津(Prigogine)更是认为“复杂性就是自主性的别称”[22],他把复杂性等同于自主性。如前文所述,深度学习最具有革命性的特征,神经网络层次之间的特征抽取完全是自我学习完成的,这正是复杂性网络自主性和适应性的最好例证。
有学者证明,大数据与复杂性科学在世界观、认识论和方法论等诸多方面都是互通的[9]。复杂性是大数据技术的科学基础,而大数据是复杂性科学的技术实现。而深度学习是一种数据饥渴型(data-hungry)的数据分析系统,天生就和大数据捆绑在一起[5]。在某种程度上,大数据是问题,而深度学习就是其中的一种解决方案。
深度学习为我们提供了一种新的机器学习范式(paradigm),即“端到端(end-to-end)”学习方法,它把特征提取和分类任务合二为一,完全交给深度学习模型,直接学习从原始输入到期望输出的映射。这里“端到端”说的是,输入的是原始数据(始端),然后输出的直接就是最终目标(末端)。整个学习流程并不进行人为的子问题划分,而是完全交给深度学习模型,直接学习从原始输入到期望输出的映射。比如,基于深度学习的图像识别系统,其输入端是图片的像素数据,而输出端直接就是或猫或狗的判定。这个“end-to-end”的映射就是:像素→判定。再比如,“端到端”的自动驾驶系统,输入的是摄像头视频信号(其实也就是像素),而输出的直接就是控制车辆行驶的指令(方向盘的旋转角度)。这个“end-to-end”的映射就是:像素→指令。实际上,这种“端到端”的机器学习范式,就是深度学习作为复杂系统所体现出来的“整体性”。
表2所示的就是几个流行的深度学习项目中的参数细节。我们知道,还原主义的实质就是试图通过研究各组成部分来理解整体。但从表2可见,深度学习网络本身就是一个训练数据量巨大、调节参数数量巨多的复杂网络。这些网络之间的参数,呈现出“剪不断、理还乱”的不可分割状态,因此它无法满足“从部分认识整体”的认知范式[23]。
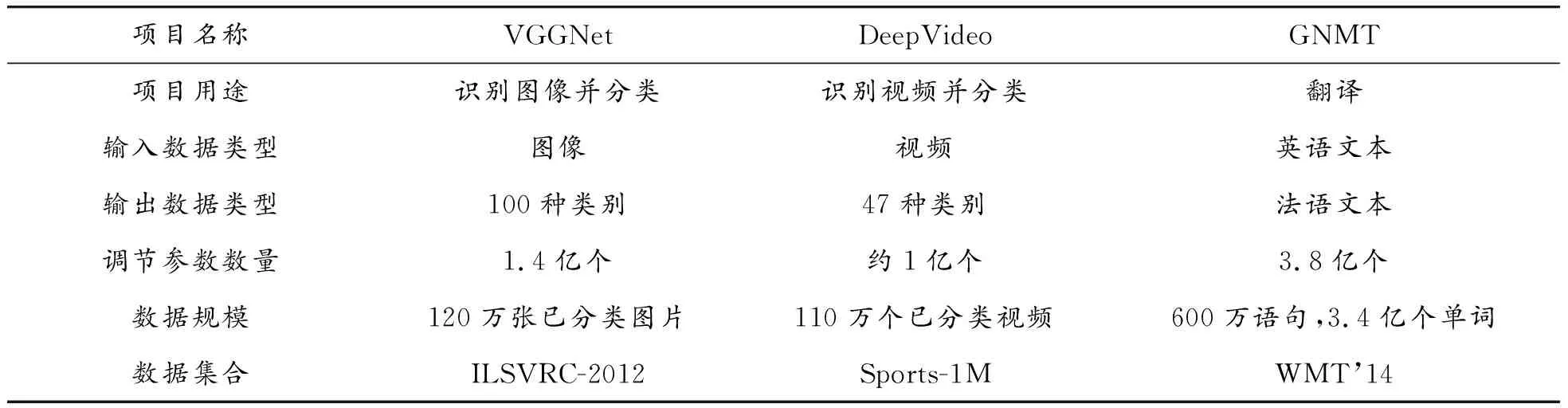
表2 深度学习项目中的数据规模与网络节点参数调整数量
此外,在复杂系统中,各要素之间紧密相连,构成一个巨大的关联网络,存在着各种各样的复杂联系,各种要素组合起来会带来新结构、新功能的涌现,也就是说,整体往往会大于部分之和。而这个特性,与以“整体等于部分之和”的还原论背道而驰。
从上面的分析可知,深度学习具备特征抽取的自主性、网络节点的多关联性(难以找到一个线性结构描述上亿级别的参数)、智能提升的涌现性等特征,这些都表明它是复杂性科学里面的一种技术实现。
四、结语
如今,我们之所以如此重视大数据,本质上是因为大数据为我们提供了一种了解纷繁复杂世界的可贵资源。但是,倘若要从浩瀚的数据资源中挖掘出信息甚至智慧,则需要强有力的利器为我服务,而深度学习技术就是这众多利器中的一种。目前,我们已经步入到一个数据驱动的人工智能时代,在这个时代,数据成为智能模型的“燃料”,如何有效地燃烧这些“燃料”以获取腾飞的动力,迫切需要科学的方法论来为之指导,否则就可能“南辕北辙”,工具越先进,距离目标越远。目前,在复杂性科学理论指导下的深度学习技术,依靠大数据资源,打造出了对这个世界理解的更加深刻的智能认知模型。
但我们也要看到,深度学习是脑科学的一种“仿生”和类比,而脑科学的理论体系本身还远远没有完整构建起来,因此由这种残缺式“仿生”带来的智能,天生就不具备十足的代表性。此外,深度学习的可解释性不足,也是其备受诟病的问题之一。因此,对脑科学研究成果的多样性解读还必须深入[23],对更佳科学方法论的追寻还必须继续。只有这样,才能更好地引领以深度学习为代表的人工智能的研究与发展。
猜你喜欢
中学生数理化·七年级数学人教版(2020年11期)2020-12-14
中华养生保健(2020年2期)2020-11-16
科学(2020年1期)2020-08-24
艺术品鉴证.中国艺术金融(2018年8期)2019-01-14
艺术品鉴证.中国艺术金融(2018年10期)2019-01-08
艺术品鉴证.中国艺术金融(2018年12期)2018-08-26
中国卫生(2016年9期)2016-11-12
肿瘤影像学(2015年3期)2015-12-09
