
基于属性优先关系的多用户Skyline查询处理算法
2018-08-07 10:53邵路伊王沁雪
计算机与现代化 2018年7期
邵路伊,王沁雪,郭 帅
(南京航空航天大学计算机科学与技术学院,江苏 南京 210016)
0 引 言
Skyline查询作为一种新的数据库操作符在2001年被提出[1],从此,它得到了研究者的广泛关注。Skyline查询为多目标决策、数据挖掘等问题提供了解决途径,有助于人们更好地做出决策。然而,随着数据集的增大以及数据维度的增加,Skyline查询返回的结果集仍旧很大,对用户的参考意义不大。同时,在现实生活中,真实数据集的各个属性的相对重要程度可能不同。例如一套房子的属性有面积、价格、所在学区、交通便利性和绿化环境等,当用户选择购买房子时,可能会最看重所在学区的排名,然后再对比价格和面积,而对绿化环境等其他因素没有要求,因此房子所在学区这一属性比其他属性对于用户的决策更有决定性作用,即它的优先等级更高。因此,数据集属性之间的优先关系能更具体地体现用户的偏好。
针对上述问题,研究者对偏好Skyline查询展开研究,关注数据集属性之间的相对重要性[2]。研究者们提出一些新的支配关系和算法[3-7],根据属性优先关系改变数据点之间的支配关系,使Skyline结果集的规模发生变化,同时使查询结果更符合用户提出的偏好需求。目前已有的偏好Skyline查询均是在单用户场景下研究的,而在实际应用中,往往需要考虑多用户参与的情况。
表1 房子数据集信息示例
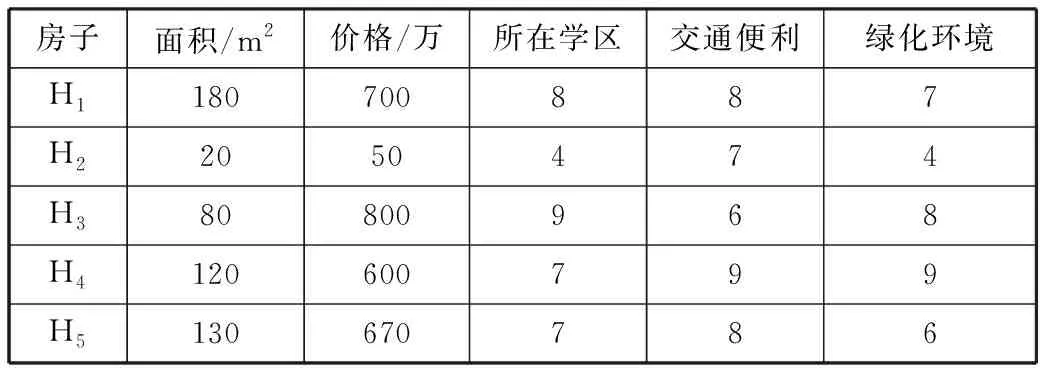
房子面积/m2价格/万所在学区交通便利绿化环境H1180700887H22050474H380800968H4120600799H5130670786
例1一个家庭共同考虑购买一套房子,房子的数据信息如表1所示。其中,所在学区、交通便利和绿化环境这3个属性以数值评分的形式展示,数值越大表示越好。家庭成员A、B、C分别根据自身的偏好提出了不同的查询要求,并给出了自认为最重要的属性:
用户A:查询面积大、价格低,同时附近交通便利的房子,价格优先考虑。
用户B:查询价格低且所在学区好的房子,所在学区优先考虑。
用户C:查询面积大、所在学区好同时附近交通便利的房子,所在学区优先考虑。
从例1可见,每个用户都对数据集均提出不同的偏好查询要求,且每个用户对属性之间的相对重要性的定义也不同,用户A认为价格属性是最重要的,而用户B和用户C认为所在学区是最重要的。此时,当查询主体的数量从单个向多个扩展时,传统偏好Skyline算法会存在以下局限性:
1)偏好Skyline查询需要确定属性之间的重要相关性,由于不同用户对不同属性的重视程度不同,缺乏将多用户的偏好统一成一组属性重要相关性的处理方法。
2)若分别对每个用户采用传统的偏好Skyline查询处理,则无法对子结果集进行有效的处理,特别是属性之间冲突性较大的情况。
3)传统算法缺乏多用户环境下的交互性,无法最大程度地满足各个用户的需求。
经过对现实生活中应用场景的分析,以及对现有偏好Skyline查询算法的分析,本文提出一种支持多用户偏好查询的MUPS算法,有效解决多用户场景中属性重要程度不同的偏好查询,主要贡献如下:
1)提出属性偏好链的概念,并用属性权重表示属性的相对重要性,基于此提出一种新的σ-支配方式,来对结果集进行剪枝。
2)提出一种基于属性优先关系的多用户偏好Skyline查询算法——MUPS算法,查询过程中通过用户群与返回候选集的交互,动态修正属性偏好链上各属性的权重大小,使得最终结果更符合用户群的真实偏好需求。
3)同时采用人造数据和真实数据对算法性能进行评估,实验结果证明,MUPS算法能有效解决多用户偏好Skyline查询问题。
1 相关工作
研究者对传统的Skyline查询展开了大量的研究,传统Skyline查询的基本概念和定义为:
定义1支配。给定一个d维数据集S,D为d个维度的集合,即D={a1,a2,…,ad},ai(1id)表示数据集的第i个维度。对于数据集S中的任意2个数据点p和q,p.ai和q.ai分别表示2点在任意维度ai上的属性值,称p支配q,记为pq,当且仅当:
1)∀ai∈D,p(ai)q(ai);
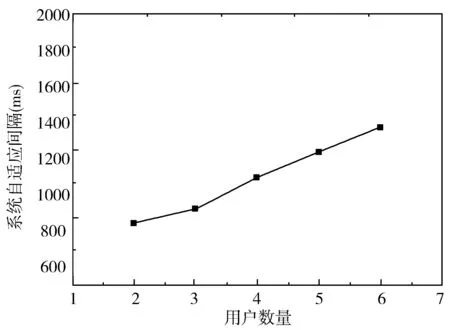
2)∃aj∈D,p(aj) 对于p,q∈S,若p≮q且q≮p,则称p和q不可比较。 定义2Skyline集合。对于数据集S,S上所有不被其他数据点支配的数据点所构成的集合称为Skyline结果集,记为Sky(S),即: 定义3Skyline查询。Skyline查询指的是,从给定的数据集中选择出所有不被任何其他数据点所支配的数据点的过程,其查询结果为Skyline集合。 传统Skyline查询方法主要为集中式数据库上的一般性算法,主要分为不使用索引的Skyline查询算法[1,8-9]和基于索引的Skyline查询算法[10-12]2个大类。此外,研究者还针对高维数据集对子空间Skyline查询处理[13-17]进行研究。 在现实应用中,用户的查询要求更加复杂,每个用户对不同维度的关心程度不同[18],因此,研究者对偏好Skyline查询进行研究。现有的研究中,大多数都是对传统的支配方式进行改变,通过新定义的支配方式对数据集进行Skyline查询计算,具体的研究成果包括: Abbaci等人[4]基于语义量词“几乎全部”定义了另一种新的支配关系,f-约束支配的条件是“绝大多数”的属性值要更好,并在此基础上详细介绍了3种算法来实现对Skyline结果的进一步缩小。第三种LISR算法在前2个算法的基础上,不仅关注支配的维度数和支配的程度,还在一定程度上考虑了部分属性的重要程度,使得结果更接近用户的偏好。 Xia等人[5]提出了ε-Skyline的概念,利用可调整的参数ε,对传统的支配关系进行定量地放松或者收紧,通过新的ε支配关系对Skyline结果集的大小进行有效地控制,并给出了支持该ε支配关系的2种算法。同时,在ε支配关系的定义中,作者加入了属性权重的概念。在比较元组支配关系的过程中,不同权重的属性其评判标准不同且与其权重相关,使返回的结果集更加符合用户的偏好。但是,该算法需要提前定义属性的权重值,缺乏实用性。 杨永滔等人[6]在p-Skyline关系的基础上引入属性相对重要性的概念,并在此基础上提出了一种支持约束分析的CABDA算法。该算法通过对构造优先Skyline关系所必需满足的约束集合的特征进行分析,进一步确定属性之间的相对重要性,最终确定满足约束条件的优先Skyline关系。实验表明CABDA算法的效率远大于已有的算法,且计算得到的优先Skyline关系确实能有效反应用户在数据对象属性之间的偏好。 Zhao等人[7]针对QoS服务提出了一种模糊语言偏好模型,将由量词表示的属性偏好关系通过函数转换成数值表示的权重值;并在此基础上提出了hybrid-EA算法,同时引入加权的切比雪夫距离(WTD),进一步对Pareto支配关系产生的Skyline结果集中的元组进行排序。 综上可知,基于偏好的Skyline查询结果更加符合用户对每个属性的偏好需求,然而,已有的相关研究工作均是针对单用户展开的,在多用户参与的应用背景下缺少相关的研究。 例1中的多用户偏好Skyline查询问题可以抽象为以下模型:对于某数据集,用户群中的每个用户分别基于自身的需求提出了一个偏好查询,偏好包括属性优先关系,系统根据这些偏好查询在数据集上进行偏好Skyline查询,最终返回Skyline结果集给用户群。 下面对所提出的问题做严格化定义,并给出多用户偏好Skyline查询过程中涉及的相关概念的定义。 定义4属性优先关系。给定2个属性d1和d2,d1,d2∈D,D为属性集合,d1和d2之间的优先关系可由≫、≻和≈这3个谓词表示。d1≫d2表示d1属性的重要程度要远大于d2属性;d1≻d2表示d1属性的重要程度要大于d2属性;d1≈d2表示2个属性的重要程度相等。 在例1中,若D={d1,d2,d3,d4,d5}分别表示面积、价格、所在学区、交通便利性和绿化环境这5个属性,则对于用户A来说,价格的重要程度要远大于其他任何属性,因此d2≫d1,d2≫d3,d2≫d4,d2≫d5;而面积和交通便利性都是需要考虑但又不是最重要的属性,因此d1≈d4,d1≻d5,d4≻d5。 定义5属性偏好链。在属性集合D′上,根据属性之间的优先关系形成的偏序的属性偏好链,用φ={dk1φdk2φ…φdkn}表示,其中dki表示属性,φ表示属性之间的优先关系。 在例1中,用户A的属性偏好链为ΦA={d2≫d1≈d4≻d3≈d5}。 定义7多用户偏好Skyline查询。用户群中任一用户uj∈U,针对数据集的属性特点提出相应的偏好查询,表示为qj={C,dkt},其中C={dk1,dk2,…,dkr}表示用户需要考虑的属性,dkt表示用户优先考虑即重要程度最大的属性,dkt∈C。 基于上述给出的相关定义,下面给出可以有效求解多用户偏好Skyline查询问题的MUPS算法。 在多用户偏好Skyline查询中,用户群中每个用户都会提出不同的偏好查询。由定义7可知,用户偏好对数据集属性的重要程度提出定义,通过属性之间的优先关系可定性地推出单用户的属性偏好链。但是每个用户的属性偏好链存在差异性,甚至会出现部分冲突的情况。例如,现有用户u1定义的部分偏好链为d1≫d2,而用户u2定义的为d2≻d1,那么无法简单地合并处理d1和d2这2属性的优先关系。此时需要对用户群的偏好进行整体分析,引入属性权重的概念,定量地判断属性间的优先关系,具体的方法分为以下5个步骤: 1)初始化属性权重。在用户提出偏好查询之前,默认将D中所有属性的权重值初始化为0,即W={w1,w2,…,wd}={0,0,…,0}。 2)对每个用户的偏好属性进行分类。根据属性优先关系的定义,将所有属性分成3类,分别为最重要、一般重要和不重要,记为c1、c2、c3。依次对每个用户的偏好进行分析,用户定义的最优先考虑的属性dkt属于c1,C={dk1,dk2,…,dkr}中除dkt外的其他需要考虑的属性属于c2,其余没有提及的属性属于c3。 例如,对于例1的用户A,有c1={d2},c2={d1,d4},c3={d3,d5}。 3)计算各属性的权重值。在计算权重值的过程中,对于每个用户而言,属于c1和c2类的属性其权重分别自加w(c1)和自加w(c2),w(c1)和w(c2)分别表示c1和c2类的权重且w(c1)>w(c2),由系统提前设定,本文取w(c1)=2,w(c2)=1,而c3类中的属性权重保持不变,这在一定程度上定量地表示属性重要程度的增加。对每个用户按照公式(1)对上一步得到的分类后的属性进行计算,最后累积得到用户群的属性权重。 (1) 因此,对例1中用户群的偏好进行分析得到各属性的权重值为W={2,3,4,2,0}。 例如,第3步得到的属性权重值正规化后为W={0.36,0.28,0.18,0.18,0}。 5)生成属性偏好链。根据归一化后的属性权重大小,对属性权重值不为0的属性降序排列,形成偏序的属性偏好链。 最后可以得出,例1中用户群的属性偏好链为Φ={d3≻d2≻d1≈d4≻d5}。 根据上述步骤给出获取初始偏好链的具体算法,见算法1。 算法1createPriorityList(Q) 输入:用户群的偏好查询集合Q={q1,q2,…,qn} 输出:用户群的属性偏好链PriorityList 1.W←{0}; //初始化属性权重集合W 2.for every user ujin U do 3.for every attribute diin qjdo 4.put diinto different class ckaccording to qj //对属性进行分类 5.if di∈c1then 6.wi+=2; 7.else if di∈c2then 8.wi+=1; //按照属性类别进行累加 9.end for 10.end for 11.normalize the weight of the attributes //权值归一化 12.sort the attributes in descending order according to their weights as PriorityList //对属性降序排列,并赋给PriorityList 13.return PriorityLis 算法1的输入为用户群的偏好查询集合Q,qj表示用户群中第j个用户提出的偏好查询要求,输出为用户群的属性偏好链。该算法通过对各用户偏好的分析,完成了对属性偏好链及其权重的初步设定,为后续查询的支配放松作基础。 在多用户参与的查询中,每个用户的偏好不同。当属性维度增加时,Skyline查询结果集的大小会随之出现指数增长的情况。为了使查询结果对用户的决策有意义,需要对Skyline结果集进行剪枝缩放。 现有的减少Skyline结果集的算法主要是通过放松数据点之间的支配方式来达到缩放的目的,但是已有的算法存在几点不足:1)放松的阈值需要人为提前设定,这对用户对数据集的认识要求较高;2)放松的过程只有一次,用户参与度不高。因此,在2.2节得到的属性权重的基础上,本节提出了新的放松粒度下的支配方式,并给出了一种循序渐进的放松策略。 定义8σ-支配。给定一个d维数据集S,属性权重集合为W={wi|i∈[1,d],0 (2) 值得注意的是,以上的定义假设数据集所有维度上的值越小越好。利用σ-支配,可以对Skyline结果集进行进一步的放松。由定义1可知,传统的支配方式是相对严格的,对于满足pq的2个数据点p和q,在任何属性上都必须满足p不比q差,这也意味着,q能比p好的幅度为0。而在σ-支配方式下,将对某些属性进行放松处理,在这些属性上允许q比p好,但同时要求q比p好的差值不大于放松粒度σ,这也意味着σ-支配并没有那么“严格”。例如,表1中的2个数据点H4和H5,两者在传统支配方式下无法比较,因此H4和H5均是传统Skyline集合中的点。现在假设对其他属性不进行放松,仅对d1属性采用σ-支配比较,且d1属性上的放松粒度为0.1。此时,H4除d1属性以外的属性值均不比H5差,且在d2和d4属性上优于H5,虽然H4在d1属性上比H5差,但满足|H4.d1-H5.d1|<σ1×160=16,即差值在允许的放松范围内,因此H4σ1H5。利用新的支配方式,可以改变数据点之间的支配关系,使不可比较的数据点具有可比性,从而对被支配的数据点进行剪枝,使得结果集规模减小。 由定义8可知,不同优先级的属性对应的放松粒度σ不同,且放松粒度σ与其对应属性的权重值成反比。当权重值越大时,该属性的重要程度更大,在该属性上允许被放松的程度越小,则放松粒度σ更小,反之也成立。同时,当权重值增大逐渐趋向于1时,放松粒度σ缓慢减小;而当权重值逐渐减少至0时,放松粒度σ快速增大,这对后续的权重更新处理有着重要的作用。 利用σ-支配的定义,将对传统的Skyline结果集进行多轮迭代放松,具体的放松策略为:在每一轮的迭代放松过程中,从属性偏好链中尾部的属性开始依次往前放松,用户可提前定义每一轮放松的维度数θ。假设当前放松的属性为第dd-θ+1~dd个属性,那么在2个数据点p和q的比较过程中,对于第d1~di-θ个属性将保持原本传统的支配方式,而对于属性dd-θ+1~dd将通过σ-支配方式来进行比较。在下一次的放松过程中,当前放松的属性为dd-2θ+1~dd,意味着在dd-2θ+1~dd维属性上采用σ-支配方式判断数据点之间的支配关系。以此类推直到所有的属性都经过放松处理。 值得注意的是,在一轮放松的最后一次放松中,若d-xθ<θ,x为已经放松的次数,则最后一次放松的维度为d-xθ,此时放松的属性为d1~dd,即所有维度的属性。 算法2prune(PriorityList,W,θ,Sky) 输入:用户群的属性偏好链PriorityList,属性权重集合W={w1,w2,…,wd},每一轮放松的维度数θ,放松前的Skyline结果集Sky。 输出:放松后的偏好Skyline查询候选集P,部分被剪枝的结果集DeleteSet。 1.P←Sky,DeleteSet←∅ //初始化集合Pskyline和DeleteSet 2.for every attribute diin D do 3.calculate the relax- granularity σi //计算各属性对应的支配放松粒度 4.x←1; 5.for i=d to 0 do 6.for every tpand tq∈P do 7.if tpσtqin dd-xθ+1~dddimension then 8.remove tqfrom P and insert into DeleteSet; //将被支配的点从P移除,加入DeleteSet 9.end if 10.end for 11.x++; 12.end for 13.output P and DeleteSet; 算法2给出了基于σ-支配的逐次放松的算法,算法的前2个输入参数为2.3.1节对用户群偏好的分析后得到的属性偏好链PriorityList和相对应的属性权重集合W,第三个输入参数为用户输入的维度数θ,表示每一轮放松过程一次放松的维度数。算法的输出参数为放松结束后的偏好Skyline查询候选集P以及放松过程中部分被删除出去的结果集DeleteSet。首先,对偏好Skyline查询候选集P以及部分被剪枝的结果集DeleteSet初始化,将其分别赋予Sky集合和置为空集;然后,根据当前属性偏好链中的属性权重值来计算各属性对应的支配放松粒度σi,对应算法2的2~3行;算法第4~12行为支配放松策略的具体实施步骤,从属性偏好链中尾部的属性开始依次往前放松,对P中的任意2点进行比较,对支配结果分类处理:1)若tpσtq则将被支配的tp点从P移除,加入DeleteSet;2)若tp与tq这2点互相支配,将保留这2点在P中;3)若tp与tq无法比较,则将这2点保留在P中,等待下一次在其他维度的放松。通过多次放松,最终所有维度上都经过放松处理,并将最终结果返回,对应算法13行。 此外,算法使用对输入数据Sky进行预排序的方法,来减少数据点之间的比较次数。数据集按照属性优先序排列,即对数据点先在优先级高的维度上降序排列,并依次在接下来的维度中降序排列。在数据点依次比较的过程中,保证了排在窗口后面的数据点在重要维度上的值不优于排在它前面的值,对于未放松的维度,只要满足被窗口末尾的数据点支配,则无需与窗口前面的数据点比较,即可终止本次对该点的比较,因此可减少数据点之间的比较的次数。 通过以上σ-支配放松处理,将有效地减少原始Skyline查询结果集,同时每个属性放松的粒度均与其优先性相关,使得缩放的结果集更加合理,精准地体现了用户群的偏好。此外,算法采用了动态输出结果的方法,当用户得到其满意的结果,则可以随时终止算法的运行,极大提高了用户体验效果。 在实际运用中,数据集的属性权重会动态地发生变化,主要有以下3种原因:1)用户在初次提出偏好查询时,不具备对数据集的充足认识,初始的权重值并不能真实反映用户的偏好;2)受到时间、环境等因素的影响,用户对不同属性的偏好程度会因为个人因素发生变化;3)多用户参与的情况下,用户在查询过程中会受到其他用户的影响,综合他人的决策意见,从而在一定程度上改变自己的偏好。以例1的多用户购房为例,根据用户偏好得到的初始属性偏好链及其权重值并不能真实反映用户群最终的偏好,需要经过动态地修正,才能达到最符合用户群的需求,算法3给出了属性权重的动态修正算法。 算法3modifyWeights(PSkyline,DeleteSet,W,t) 输入:偏好Skyline查询候选集PSkyline,部分被剪枝的结果集DeleteSet,属性权重集合W,迭代轮次t。 输出:修正后的权重属性权重集合W。 1.upAttr[x],downAttr[y]←∅; //初始化需要修改的属性列表 2.for every ukin U do 3.upAttrk,downAttrk←UserSelect (PSkyline,DeleteSet); //用户选择需要增大和减少权重值的属性 4.if count[di]≥n/2 when diin every upAttrkthen 5.insert diinto upAttr[x]; //获取需要增加权重的属性集合 6.if count[dj]≥n/2 when djin every downAttrkthen 7.insert djinto downAttr[y]; //获取需要减小权重的属性集合 8.calculate the Δ=min(1/[t×(t+1)],min(wj)×y) for each wjin downAttr[y]; //计算每轮修改的权重值Δ,且考虑特殊情况 9.for every diin upAttr[x] do 10.wi+=Δ/x; 11.for every djin downAttr[y] do 12.wj-=Δ/y; 13.return W; //返回更新后的属性权重集合 在算法3中,首先,算法对需要调整权重值大小的属性列表进行初始化,将其置为空。接着,用户对本轮缩放得到的PSkyline和DeleteSet结果集进行观察和分析,进行定性的反馈。由于PSkyline结果集是按照属性优先序排列的,因此用户会有一个直观的认识。若PSkyline结果集中某属性值密集且较优,但对应其他属性上的值均很差,则说明该属性的重要程度需要被减小,而其他属性的优先级可能需要增加。根据诸如此类的结果集信息,各用户uk分别选出一个需要增大和减小权重值的属性upAttrk和downAttrk,对应算法3的2~3行。然后,系统对用户群的选择结果进行综合分析,若满足一半以上的用户选择同一个属性,该属性才能认为是需要修改的,从而确定所有需要进行调整权重值的属性upAttr[x]和downAttr[y],分别表示权重值需要增加的属性集合,其个数为x,以及需要减少的属性集合,其个数为y,对应算法3的4~7行。算法3中8~12行对上面步骤得到的需要调整的属性作出修正,值得注意的是,每轮交互迭代过程中,属性权重值增加的总值Δ+与减少的总值Δ-是相当的,其绝对值均为Δ,∑wi(di∈upAttr[x])=∑wj(dj∈downAttr[y])=Δ,保证了调整后所有属性权重值之和仍为1。修改值Δ是有关迭代轮次t的函数f(t)=1/[t×(t+1)],对于需要增大权重值的属性di,其增加的权重值Δwi=Δ/x,而对于需要减少权重值的属性dj,其减少的权重值为Δwj=Δ/y。需要注意的是,若存在Δwj 前面分别给出了多用户偏好Skyline查询中用到的数据处理方法,基于上文的叙述,本节提出完整的基于属性权重的多用户偏好Skyline查询算法——MUPS算法,并详细分析该算法的处理流程。 算法4给出了多用户偏好Skyline查询算法——MUPS算法。算法的输入为:用户群给出的偏好查询集合Q={q1,q2,…,qn},其中qj={C,dkt},C={dk1,dk2,…,dkr}表示用户需要考虑的属性,dkt表示用户优先考虑即重要程度最大的属性,dkt∈C,以及用户设定的每轮放松过程中一次放松处理的维度数θ。首先,对输出的结果集PSkyline初始化,将其置为空;然后利用初始属性偏好链生成算法1分析用户群的偏好查询,形成带权重的属性偏好链PriorityList,并得到各属性的权重值W;接着对偏好属性链上的维度用SFS算法[8]计算初始Skyline候选集,对应算法4的第3行;在此基础上,算法4第4~12行,通过σ-支配放松对上一步得到的初始Skyline候选集进行多轮剪枝处理,每一轮的放松过程中,动态输出放松后结果P和部分被剪枝的结果DeleteSet,用户对结果作出反馈意见,系统通过对用户的意见进行分析,动态地更新属性权重值,若因此属性之间的优先关系发生变化,则还要更新属性偏好链,动态调整后将进入下一轮的放松处理直到满足算法的终止条件,该算法的终止条件具体为:1)用户手动选择终止交互过程;2)分析用户的选择后,没有权重满足需要修改的条件。此时最后一轮放松后的结果即为最优偏好Skyline查询结果PSkyline,将此作为算法的输出参数输出,对应算法4的第11~12行。 算法4MUPS算法 输入:用户群的偏好查询集合Q={q1,q2,…,qn},每次放松的属性维度数θ。 输出:最优偏好Skyline查询结果集PSkyline。 1.PSkyline←∅; 2.createPriorityList(Q)→PriorityList,W; 3.Sky←SFS (PriorityList); //利用SFS算法计算初始的Skyline候选集 4.t←0; 5.while(true) 6.P,DeleteSet←prune(PriorityList,W,θ,Sky); //动态输出放松结果P和部分被剪枝的结果DeleteSet 7.if Terminate(P) then 8.break; //若满足终止条件,则退出循环 9.else 10.W←modifyWeights(PSkyline,DeleteSet); //更新属性权重 11.end if 12.t++; 13.PSkyline←P; 14.return PSkyline; 本章主要对MUPS算法进行实验以及性能评估。算法的性能分为2个部分: 1)有效性。MUPS算法旨在基于属性偏好关系减少原始Skyline结果集的规模大小,为用户群决策提供有利价值,因此需要对剪枝后的结果集大小做检验。 2)交互性能。MUPS算法通过交互来实现,交互过程中,系统需要在合理的时间间隔内提供反馈信息,否则将影响用户的交互体验,因此实验需要对算法过程中的系统自适应间隔进行验证。该算法对应的系统自适应间隔,指系统分析用户选择结果并动态更新属性权重后,在此基础上再次剪枝返回结果的时间间隔。 此外,由于目前尚未有其他专门针对多用户偏好Skyline查询的算法可供比较,因此本实验中作为对比的Baseline算法为传统单用户下的LISR算法[4]的基本扩展。具体为,对n个用户分别通过执行LISR算法完成每个用户的偏好Skyline查询,然后再取各子结果集的并集。 实验分别采用模拟数据集和真实数据集进行测试,如表2所示。本实验使用的模拟数据集参照文献[1]的数据生成器产生,为相关数据集、独立数据集以及反相关数据集3种,数据维度为6~10,且默认属性值越小越优;采用的真实数据集为NBA球员技术统计数据集。由于实验需要多用户同时参与,在学校范围内选取了30名志愿者,在实验过程中作为用户提出不同的偏好需求。为避免随机性对实验结果产生的影响,所有的结果均为10次试验运行结果的平均值。 表2 实验数据集 数据集数据规模数据维度模拟数据集1×104~5×1046,7,8,9,10真实数据集172658 实验所用计算机的操作系统为Windows 10,CPU主频为3.3 GHz,内存为4 GB。所有算法均用C++语言实现,编译器为Visual Studio 2010。 为分析数据量对MUPS算法性能的影响,本实验采用相关、独立和反相关3种人造数据集进行测试。数据点个数n从1×104到5×104变化,数据集维度均为6。实验随机挑选10组测试用户组合,设定每组测试中参与的用户数为4,每个用户关注的最大维度为4,所求结果集大小和系统自适应间隔为10组实验结果的平均值。 (a) 相关数据集 (b) 独立数据集 (c) 反相关数据集图1 数据量对结果集大小的影响 图1分别展示了不同类型数据集下MUPS算法与LISR-base算法的结果集大小对比,从实验结果可以发现:未剪枝前的Skyline查询结果集规模很大,且随着数据集大小的增大而增加,在反相关数据集下尤为明显,这是由于数据类型的特征导致的。MUPS算法与LISR-base算法对原始Skyline结果集均有一定的剪枝效果,结果集大小得到不同程度的控制。但对于同一个类型的数据集,MUPS算法的剪枝效果明显要比LISR-base算法更好,得到的结果集更小,更有利于用户决策。同时,MUPS算法对反相关数据集的剪枝效果比其他2类数据类型要好,这是因为反相关数据集属性之间的冲突较大,而MUPS算法能通过放松控制关系有效地缓解冲突,从而使得结果集规模减小。 图2 数据量对系统自适应间隔的影响 考虑到LISR-base没有交互过程,因此对其不做交互性能的对比。图2为MUPS算法在相关、独立和反相关3种数据集下的系统自适应间隔对比结果。该间隔时间主要包括MUPS算法中的系统对用户反馈结果的分析时间和支配放松计算的运行时间,由于支配放松需要数据点之间的比较,因此随着数据量的增加,支配放松计算消耗的时间递增。而实验中系统交互间隔均在5 s以内,在用户的容忍范围之内,可及时地对结果进行沟通和反馈。 本实验主要考察用户数量对MUPS算法性能的影响。从3.2节实验结果中可以发现,正相关数据集下的Skyline结果集包含的数据点数较少,因此算法性能均较好。因此,不再对比正相关数据集下的算法性能,实验利用独立数据集和反相关数据集进行测试,数据点个数均为1×104,数据集维度均为6。实验随机从30名志愿者中选取不同数量的用户组合,每组用户的数量从2到6变化,每个用户关注的维度最大为4,每组所求结果集大小为10次实验结果的平均值。 图3 用户数量对结果集大小的影响 图3分别为独立数据集和反相关数据集下结果集大小的测试结果,可以看出随着用户数量的增加,LISR-base算法得到的结果集规模随之迅速增大,这是因为用户数量增加,子偏好Skyline结果集的个数增加,并集操作后的结果集大小增加,在反相关数据集中结果集增大的幅度尤为明显。而MUPS算法的返回结果集规模随用户数量的增加缓慢增大,有效地进行了剪枝。 MUPS算法在独立和反相关数据集下的系统自适应间隔结果如图4所示,当用户群中的用户数量增加,系统自适应间隔时间增长的幅度缓慢,这是因为MUPS中对用户的选择分析耗时以及权重更新的时间相比之下在常数级,因此变化影响并不大,而用户的数量对支配比较时间并没有直接影响。 本实验采用NBA球员技术统计数据集对算法的有效性以及偏好性能进行验证。该数据集共有17265条数据,全空间维数为8维。首先为了检验用户数量对算法性能的影响,随机从30名志愿者中选取不同数量的用户组合,每组用户的数量分别从2到6变化,每个用户关注的维度最大为4。 图5 真实数据集下用户数量对算法性能的影响 图5展示了真实数据集下用户数量对MUPS算法的系统自适应间隔的影响,从图5中可以发现其结果与人造标准数据下的结果一致,验证了MUPS算法的交互性,即可较高效地支持用户进行交互式查询。 本文针对现实生活存在的多用户场景下的偏好Skyline查询问题,进行深入分析和研究,阐述了传统单用户偏好Skyline查询在解决该问题上的不足,在此基础上提出了一种基于用户权重的交互式多用户Skyline查询算法MUPS算法。MUPS算法,首先通过分析用户群各用户的偏好查询要求,确定用户群的初始属性偏好链;然后,提出一种基于属性权重的新的支配方式——σ-支配,通过新的支配方式对原始Skyline结果集进行剪枝缩放,并通过用户群与返回候选集的交互,对属性偏好链中各属性的权重大小进行动态修正,多轮迭代后最终返回更符合用户群真实需求的结果。实验结果表明,MUPS算法能有效地解决多用户场景下的偏好Skyline查询问题,返回的结果集大小对用户的决策有参考意义,同时该算法具有良好的交互性能。2 交互式MUPS算法
2.1 查询建模及相关定义
2.2 获取初始属性偏好链
2.3 基于权重的支配放松策略
2.3.1 σ-支配
2.3.2 放松策略
2.4 属性权重动态修正
2.5 MUPS算法
3 实验与分析
3.1 实验数据集及实验环境设置
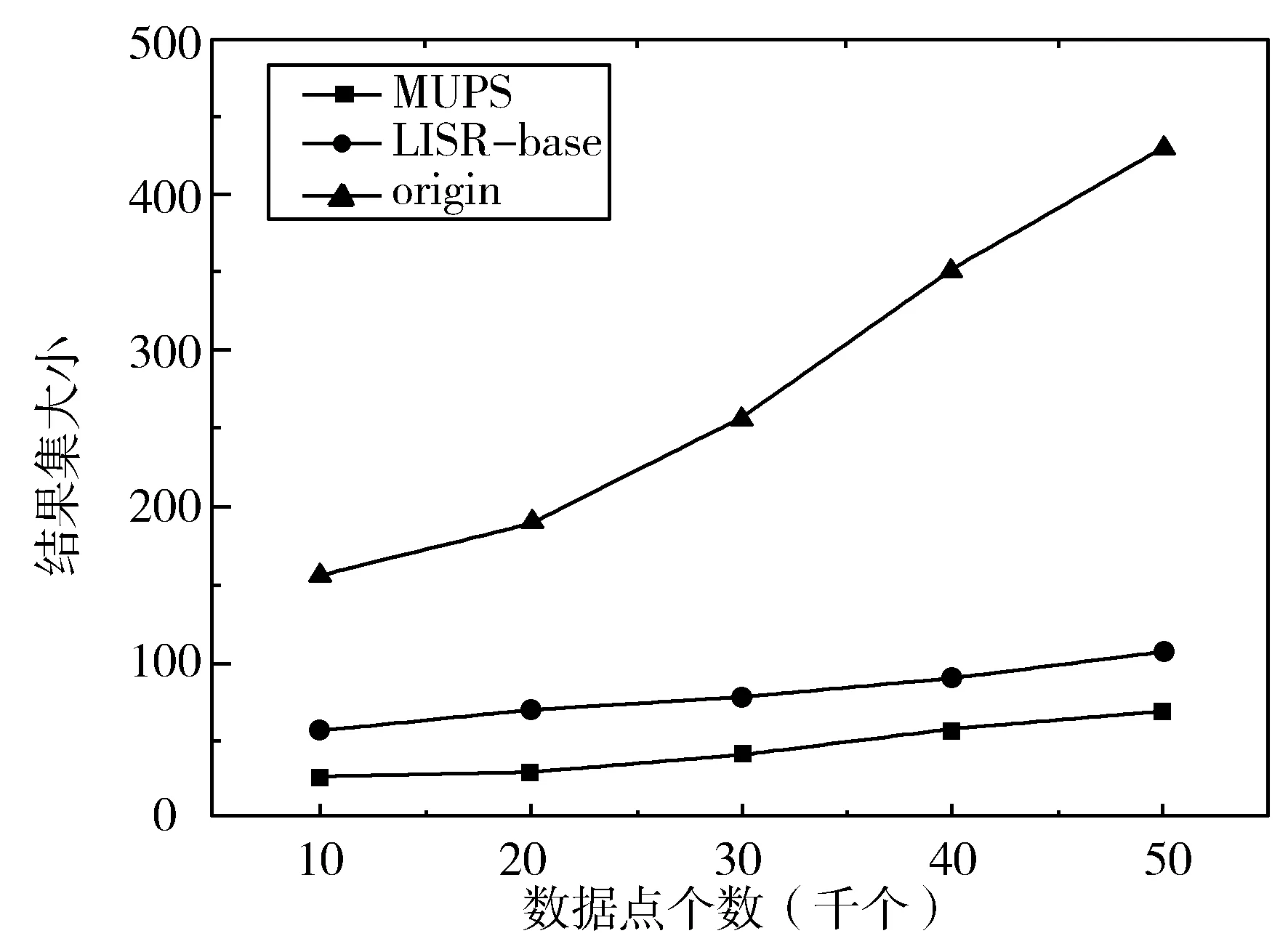
3.2 数据量对算法性能的影响
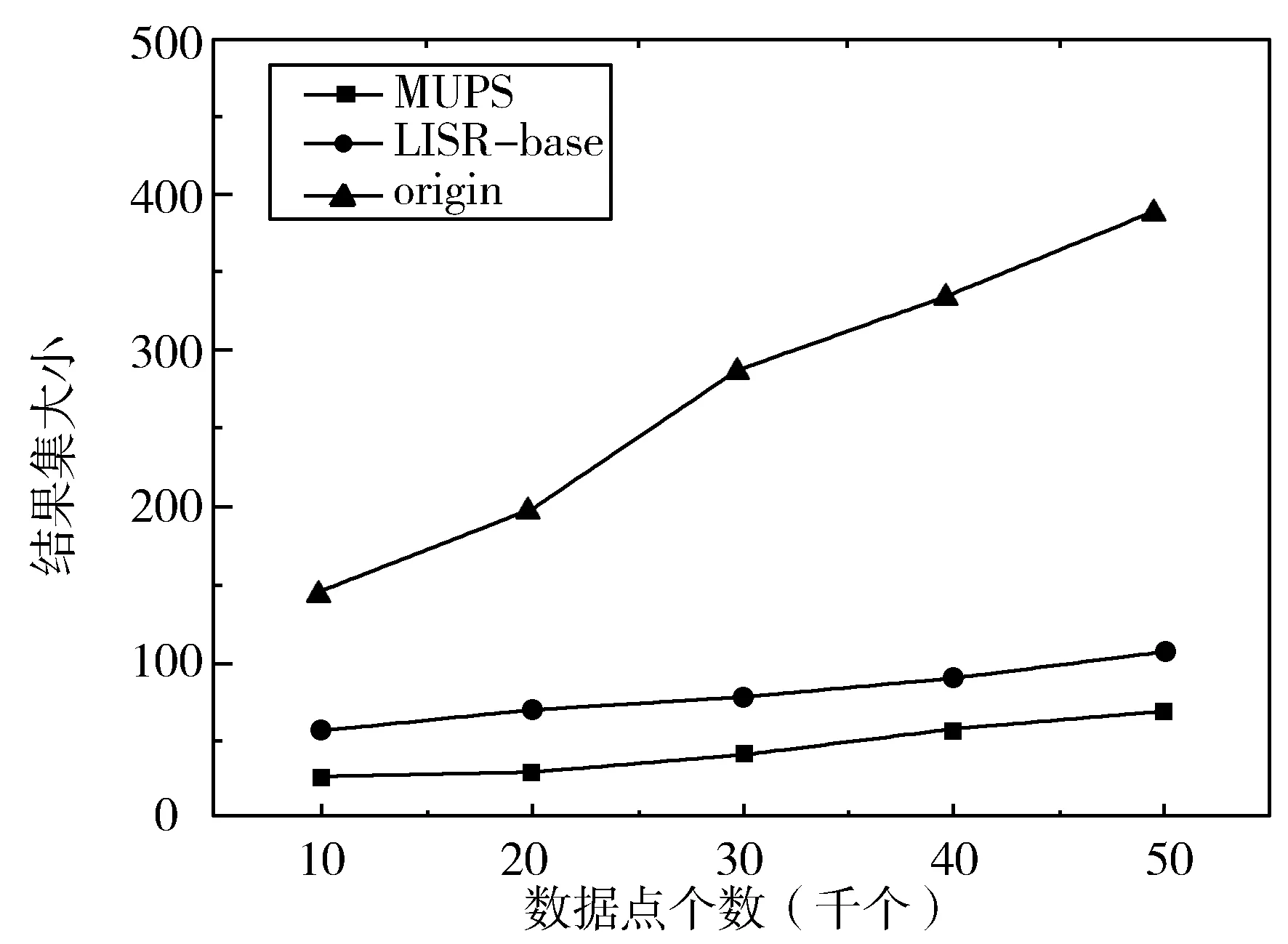
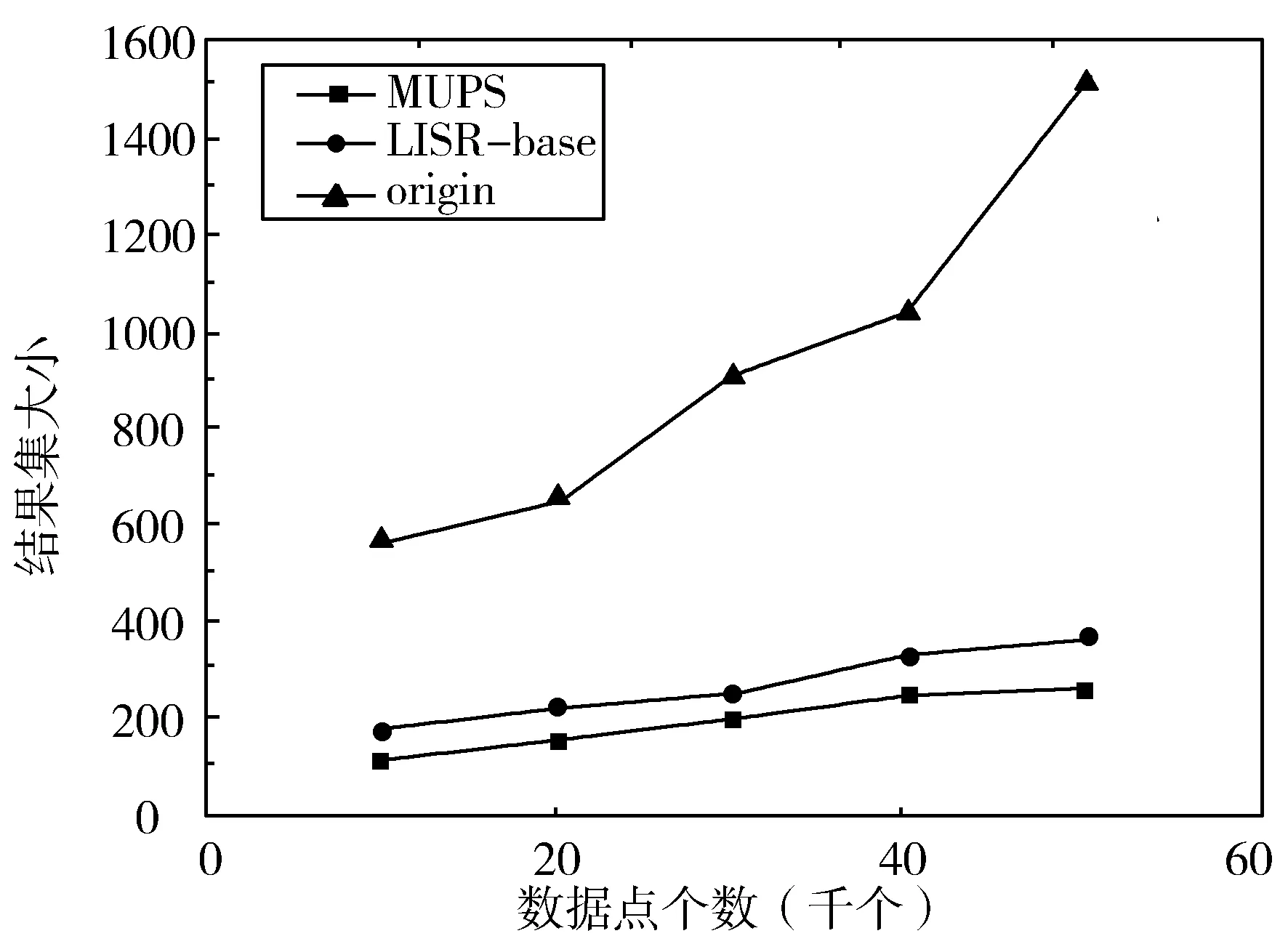
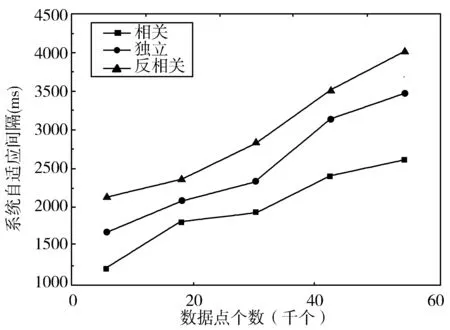
3.3 用户数量对算法性能的影响
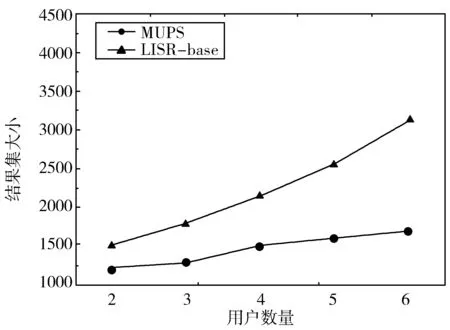
3.4 真实数据下的算法性能
4 结束语
猜你喜欢
中国金属通报(2022年14期)2023-01-06中国金属通报(2021年12期)2021-11-02消费电子(2021年6期)2021-07-17中国金属通报(2021年6期)2021-07-01意林(2021年9期)2021-05-28中国金属通报(2020年14期)2020-04-22求知导刊(2019年17期)2019-10-18时代英语·高一(2019年1期)2019-03-13自动化学报(2017年2期)2017-04-04Coco薇(2016年8期)2016-10-09
