
基于BI-LSTM-CRF模型的限定领域知识库问答系统
2018-08-07 10:53程树东
计算机与现代化 2018年7期
程树东,胡 鹰
(太原科技大学计算机科学与技术学院,山西 太原 030024)
0 引 言
在机械行业,矫直机是冶金工业生产中对板材矫直时必不可少的设备。宋凯等[1]比较详细地介绍了全液压矫直机的结构和技术特点。但以前主要是由人工进行操作控制。随着机器学习的快速发展,国家也大力推动各行各业与人工智能的深度融合,创新生产力,促进经济发展。在此形势下,矫直机也借助人工智能技术实现智能化,解放生产力。张凯等[2]利用分类学习粒子群优化算法取得了使液压矫直机控制性能更佳的参数组合。由于矫直机智能控制系统的性能对金属板材矫直质量起着关键作用,而知识的质量与数量又是决定矫直机智能控制专家系统性能的重要因素,因此,构建一种高效的机械领域知识库问答系统,以解决机械领域的知识快速获取很有必要。信息抽取(Information Extraction)是把非结构化文本数据进行结构化处理,以便于机器处理。据此,本文提出通过信息抽取技术完成对知识的自动获取建立知识库,并结合BI-LSTM-CRF模型建立知识库问答系统。
自动问答系统通常被定义为这样一种任务:用户将以自然语言描述的问题提交到一个系统中,系统在自动理解用户问题的基础上输出答案。其主要有开放域问答系统和面向限定领域问答系统2个研究方向。然而当前,研究的热点主要是开放域问答系统。面向限定领域问答系统与开放域问答系统的不同点主要在于:限定领域的问答系统能利用大量领域相关知识来提高系统的实用性。在目前开放域问答系统取得较大进步的同时,发展面向限定领域的问答系统是很有必要的。因此,本文在开放领域问答系统相关技术的基础上,面向机械领域利用深度学习技术对建立机械领域的知识库问答系统进行研究。
1 相关工作
知识库问答系统是指通过海量数据构建知识库,对用户输入的以自然语言形式描述的问题(例如金属型材矫直的设备是什么?)能够分析理解,再从知识库中查找出能回答该问题的准确的知识答案(例如矫直机)的信息系统。基于知识库的问答系统在人工智能领域具有很长的发展历史。
传统的构建知识库问答系统的研究思路主要是使用语义解析(Semantic Parsing)。该方法是将自然语言通过语言学知识经过分析处理转化为一系列形式化的逻辑表达形式(lambda表达式、依存组合语义树等),再进行逻辑解析,以获得一种能够表达整个问题语义的逻辑形式,再通过相应的查询语句在知识库中查询答案。由于这类方法需要大量人工标注的“自然语言语句—逻辑表达形式”对,因此很难扩展到大规模知识库的情况。
由于神经网络的发展,研究者们逐渐使用向量建模对问答系统进行研究。该类方法首先分析输入的问题,并通过信息抽取技术提取出问题实体,对问题进行分类,进而查询得到知识库中以该实体节点为中心的子图。由于答案和问题主题的关联性,因此,将知识子图中的所有节点和边都作为该问题的候选答案。再将问题和所有候选答案映射为分布式向量,并通过训练数据学习得到问题和答案的向量表达的得分尽量高的参数模型。训练生成模型后,通过模型对问题及其候选答案的向量表达进行测试评分,再按得分高低从候选中得出最终答案。对于文本的信息抽取,主要有2种方法。第一种是基于规则。乔磊等[3]对需要抽取的人物信息进行规则描述,并构建正则表达式,实现半结构化人物属性信息的提取。另一种是基于统计。郑轶[4]通过序列标注的问题思路从人物百科中抽取人物信息,利用条件随机场对生语料进行序列标注,并从语料中提取特征,有效提高了信息抽取的效率。王宗尧等[5]基于CRF模型有效地对中文短文本信息流进行了话题提取。而翟菊叶等[6]利用CRF与规则相结合的方法识别中文电子病历的命名实体,提高了准确率。Yao等[7]通过依存分析技术来获得问题的依存分析树,再从问句中找到其涉及的主要实体,进而查询得到知识库中以该实体为中心的子图,最后从问题的依存树和子图中抽取多种特征并送入逻辑回归模型中进行分类。Bordes等[8-9]通过前馈神经网络对问句和候选答案进行语义编码,以将其分别转换为相同维度的特征向量,最后将2个向量的点积值作为问题候选答案的得分。
近几年,随着深度学习在多个领域的快速发展和应用,研究者开始将其应用在问答系统中,以改善传统方法存在的不足。Li等[10]通过卷积神经网络对问句中隐含的答案类型、关系和上下文信息分别进行语义编码,提升了向量建模方法的特征获取,取得很好的效果。Yih[11]等使用卷积神经网络改善语义解析方法。周博通等[12]使用双向LSTM模型结合注意力机制实现实体消歧和答案选择。在此基础上,本文使用深度学习技术和信息抽取方法进行向量建模,以提高问答系统的性能;提出一种BI-LSTM-CRF模型,结合信息抽取技术,以构建面向机械领域的知识库问答系统。
2 基于BI-LSTM-CRF的问答系统
2.1 CRF
Lafferty等[13]于2001年提出条件随机场(Conditional Random Fields, CRF),它是无向图模型,当输入节点值给定时,可以用于计算指定输出节点值的条件概率。比如线性条件随机场,如果将X={x1,x2,…,xT}表示为输入的观测序列,Y={y1,y2,…,yT}定义为其对应的状态序列,则在给定一个观测序列时,CRF定义状态序列的条件概率为:
(1)
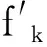
2.2 LSTM
1997年,Hochreiter等[14]在循环神经网络的基础上提出了LSTM单元,它解决了RNN的梯度消失和长期依赖问题。LSTM单元如图1所示,其记忆单元可以用于保存历史信息,通过输入门、输出门和遗忘门可以控制历史信息的更新和利用。
设h为LSTM单元输出,c为LSTM记忆单元的值,x为输入数据。LSTM单元的更新可以分为以下几个步骤:
ft=σ(Wf·[ht-1,xt]+bf)
(2)
it=σ(Wi·[ht-1,xt]+bi)
(3)
ot=σ(Wo·[ht-1,xt]+bo)
(4)
Ct′=tanh(WC·[ht-1,xt]+bC)
(5)
Ct=ft×Ct-1+it×Ct′
例如:在我担任少数民族地区老师的第二年,我就曾经遇到过这么一个女生,她性格十分的内向,并且非常的体弱多病,又受到传统的思想影响,认为学好专业技能才是第一位的,毕业后靠着学习的技能找到一份满意的工作,改变命运。因此她时常不去上体育课,将体育课的时间都用来从事专业的学习。有一次,她累倒了,我去看望她,和她讲了一些体育锻炼的好处,告诉这名女生没有好的体魄,就更加无法有强大的精神去实现梦想的道理,打开了这位少数民族女生的心扉。后来,这名女生每节课都来上体育课,并且主动的参与体育活动,课后积极的锻炼身体,生病的次数越来越少,令我十分的欣慰。
(6)
ht=ot×tanh(Ct)
(7)
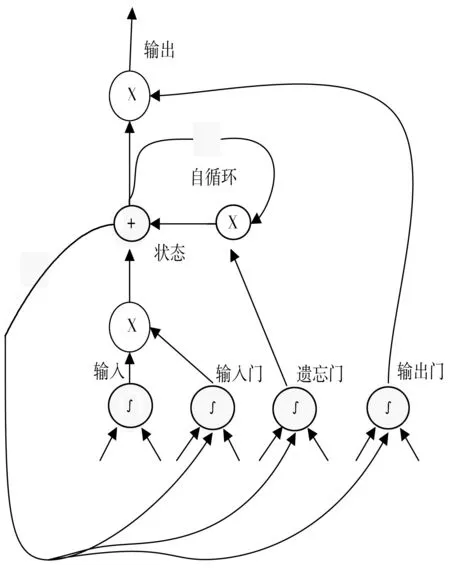
图1 LSTM单元结构
公式(2)~公式(4)分别用来计算遗忘门、输入门、输出门的值,其接受上一时刻记忆单元的输出ht-1和当前时刻记忆单元的输入xt,并乘以各自的权重矩阵,再加上偏置向量,最后通过Sigmoid函数产生一个0到1之间的值来对信息进行筛选。公式(5)和公式(6)更新LSTM单元的状态信息。公式(7)为计算记忆单元的最终输出,其通过tanh函数对当前时刻的LSTM单元状态进行计算,使模型变为非线性,并由输出门决定哪些信息被最终输出。但由于LSTM神经网络的信息输入是单方向的,从而会忽略未来的上下文信息。因此,通过双向LSTM对一个训练序列向前向后各训练一个LSTM模型,再将训练的2个模型的输出进行线性组合,使得序列中每一个节点都能获得完整的上下文信息。
2.3 基于BI-LSTM-CRF的问答系统
2.3.1 预处理
在特征选择之前,本文先进行文本分词,本文使用的分词工具为开源的结巴分词。由于本文语料为机械行业的技术资料文献等,所以本文中含有大量的机械行业专业词汇。为了增加分词的准确性,本文加入大量的机械行业词汇作为文本分词的用户词典。本文选用500本机械文献进行实验,实验中使用自定义词典进行分词和未使用自定义词典进行分词进行实验。实验结果如图2所示,结果表明,使用自定义词典分词相对于默认词典分词,其准确率、召回率和F值都有所提升。
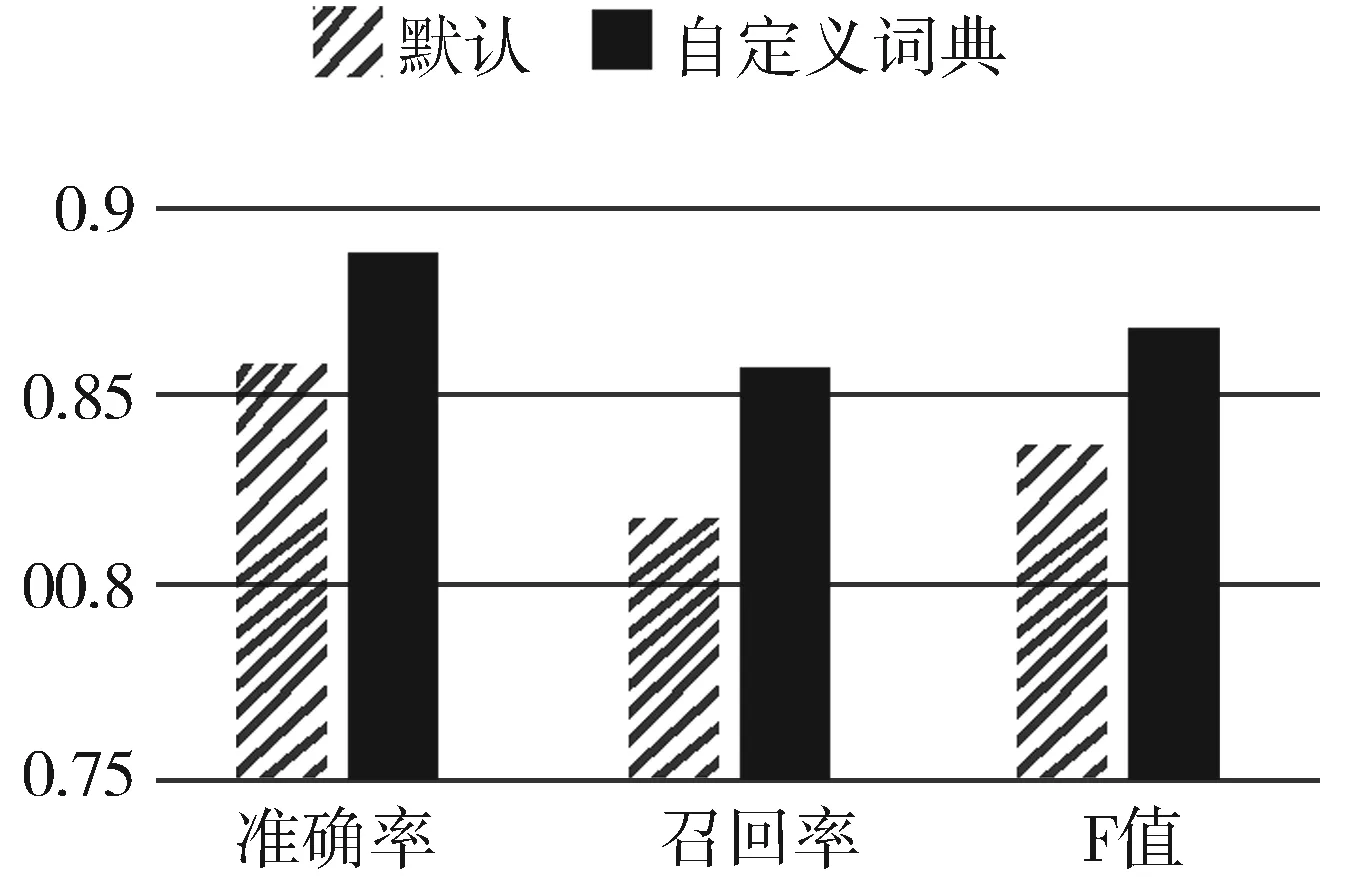
图2 自定义词典与默认词典分词结果对比
2.3.2 BI-LSTM-CRF模型
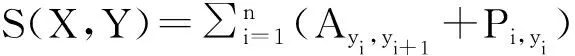
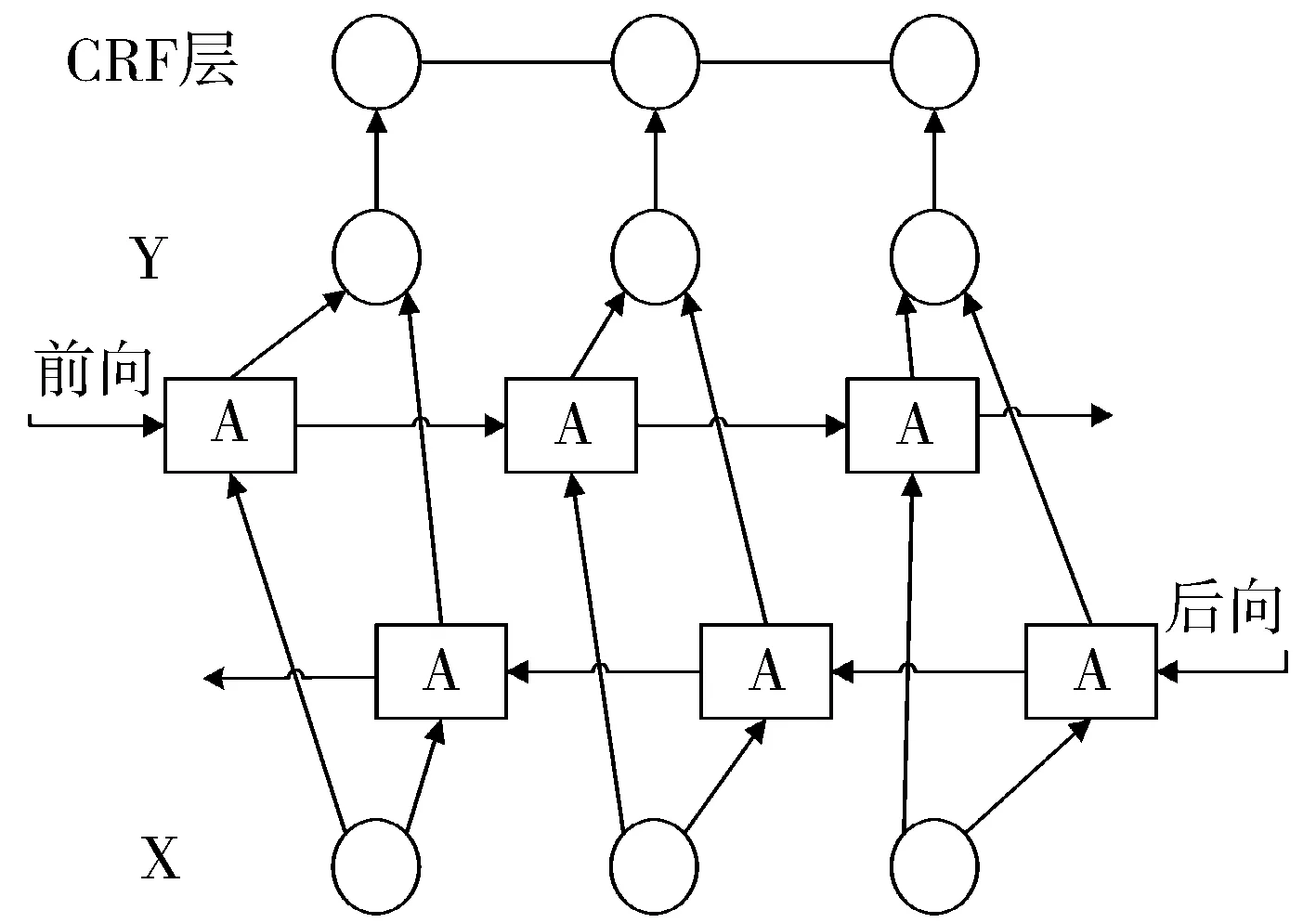
图3 BI-LSTM-CRF模型结构
对于输入的问句,利用CRF模型抽取实体和关系,将其映射到知识库中,寻找知识库子图,获取问题候选答案,再通过预处理向量化,送入BI-LSTM-CRF模型提取特征值,并对问题及候选答案进行评分,以此获取最终答案。
2.3.3 训练方法
首先将问题与候选答案构成问题—答案对文本,每一行是问题与候选答案组成的语句,并将候选答案是问题正确结果的标记为1,否则标记为0。以此作为训练文本,将其分为训练集和验证集。如此,将搜索新问题的答案变成了根据问题实体从知识库中查找候选答案,再与问题组成句子,并根据训练生成的模型进行分类。将“问题—答案”对形成的文本进行分词,并通过fastText训练的词向量模型,根据词典索引,表示为向量矩阵,作为神经网络的输入。将其分批量送进双向LSTM神经网络,对LSTM的输出结果再通过CRF根据标签序列调整参数,通过对验证集的预测值与真实值比较,降低训练总损失,完成训练。
3 实 验
3.1 词的向量表示
Hinton[15]于1986年提出词的分布式表示,其基本思想是通过学习训练数据将每个词映射成N维实数向量,并通过词之间的距离来计算语义相似度。本文使用Facebook于2016年开源的快速文本分类工具fastText的词表征功能来训练词向量,训练语料来自中文维基百科和机械行业文献资料,在去除多余标签后,语料大小约为950 MB,再用其训练生成150维的词向量。
3.2 实验语料
源数据主要由3部分组成,机械行业科技论文1000篇,基础技术资料800篇,行业技术规范400篇。依据哈尔滨工业大学社会计算与信息检索研究中心提出的中文问题分类体系,利用源数据,针对描述类、人物类、地点类、数字类、时间类、实体类(主要指物质、材料、术语等)等6大类问题,构建了问答系统的训练、测试语料。语料分布如表1所示。
表1 训练语料和测试语料的问题分布
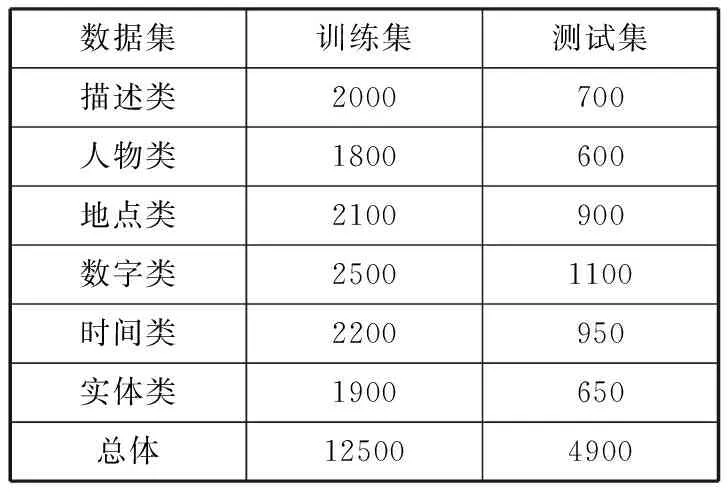
数据集训练集测试集描述类2000700人物类1800600地点类2100900数字类25001100时间类2200950实体类1900650总体125004900
3.3 评估方法
针对不同的问题类型,开放领域问答系统在评测时可以专门制定评测方法。目前,评测开放领域问答系统的国际会议主要有日语问答评测平台NICIR、英语问答评测平台TREC QA Track和多语言问答评测CLEF等。采用的评测指标主要包括准确率、平均排序倒数(MRR)、CWS等。其中:
(8)
当系统给出的排序结果中存在标准答案时,以第一个匹配结果计算得分;当系统给出的排序结果中不存在标准答案时,得分为0。最终分数为所有分数之和。
(9)
其中,N表示测试集中提问的个数。
上述指标是在开放领域问答系统中对输出答案质量进行评价的主要指标。而面向限定领域的问答系统的评测在开放领域问答基础上,增加了一些指标。Anne等[16]从构建航天工程领域问答系统出发,提出了以用户为中心,以任务为基点的限定领域问答系统评测方法,包括系统响应时间、系统可靠性、答案完整性、答案准确性、答案相关性、答案有用性等。由于系统可靠性、答案完整性、答案有用性等指标难以准确评估,因此,此次实验出于实用性考虑,主要使用准确率和消耗响应时间这2个指标来对系统进行测评。
3.4 实验结果
杨煜等[17]利用Google开源的Tensorflow框架实现了基于LSTM神经网络的人体动作分类系统。Tensorflow简化了机器学习模型的代码实现。此实验模型使用Python3.5和Google开源的Tensorflow框架实现。将训练语料经过分词和向量化处理后,送入BI-LSTM-CRF模型。为验证BI-LSTM-CRF模型在问答系统上的有效性,实验与上文相关工作中提到的LSTM方法进行了比较,结果如表2所示。
表2 问答系统模型实验对比结果
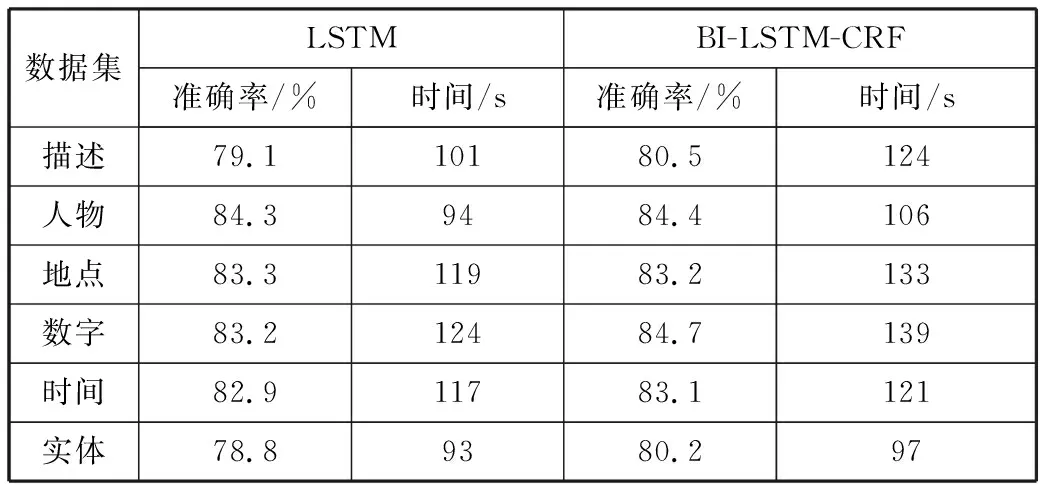
数据集LSTMBI-LSTM-CRF准确率/%时间/s准确率/%时间/s描述79.110180.5124人物84.39484.4106地点83.311983.2133数字83.212484.7139时间82.911783.1121实体78.89380.297
由表2可知,将LSTM与CRF结合起来构建的BI-LSTM-CRF模型,在实验数据中的准确率较通用的LSTM模型有所提升,但消耗时间略有增加。由于消耗时间是测试子集的总体时间,因此在实际应用中,平均响应时间增加不大,可以忽略。虽然BI-LSTM-CRF模型整体表现不错,但在地点类问题子集上,准确率却不如LSTM模型。经分析后发现,造成此种情形主要是由于此次训练样本不够多。在训练样本不足时,BI-LSTM-CRF相比LSTM优势并不明显。但在训练样本足够时,BI-LSTM-CRF能取得更大的优势。在地点类问题上准确率与训练样本量的变化趋势如图4所示。总之,BL-LSTM-CRF模型提升了限定领域问答系统的性能,取得了较好的效果。
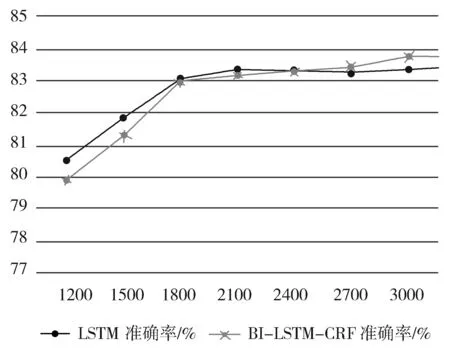
图4 模型训练样本量与准确率变化趋势
4 结束语
本文分析了问答系统的现状以及条件随机场、长短期记忆网络等机器学习算法的成功应用,提出用深度学习的方法来改善问答系统中存在的不足。本文尝试综合利用条件随机场与长短期记忆网络的优点,结合构造成新的模型对问答系统进行研究,以发掘一种提高问答系统性能的机器学习框架。借助实验,对混合长短时记忆网络和CRF的学习框架(BI-LSTM-CRF)与传统方法进行了比较,发现结合两者的优点,可以更好地理解问题,提高准确率。BI-LSTM-CRF模型在不制定繁琐的特征规则的情况下,也取得了较好的准确率。对于训练数据不足的问题,除了收集和标记更多数据之外,还有待利用更好的学习方法在现有训练数据基础上学习更多的特征,这也将是下一步的研究方向。
猜你喜欢
通信技术(2021年12期)2022-01-25
校园英语·月末(2021年13期)2021-03-15
智富时代(2019年6期)2019-07-24
智富时代(2019年6期)2019-07-24
制造技术与机床(2019年6期)2019-06-25
中国交通信息化(2016年9期)2016-06-06
图书馆研究(2015年5期)2015-12-07
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
中文信息学报(2012年2期)2012-06-29
