
一种LSTM-BP多模型组合水文预报方法
2018-08-07 10:47冯钧,潘飞
计算机与现代化 2018年7期
冯 钧,潘 飞
(河海大学计算机与信息学院,江苏 南京 211100)
0 引 言
我国是一个洪涝灾害发生十分频繁的国家,洪涝灾害不仅阻碍了我国的社会发展,而且严重地威胁着人民群众的生命及财产安全。为了减少洪涝灾害带来的损失,我国采取了许多防洪减灾手段,如对洪水进行水文预报,提前做好防御洪水的准备、修建各级大坝防御洪水和洪水调度等。在这些防洪手段中,对洪水的水文预报准确度是影响能否做好防洪减灾的一个至关重要的因素。传统的线性模型一般用于平稳序列的预报或模拟,但水文数据是具有高度不确定性和复杂性的非线性序列[1],因而传统的线性模型在水文预报中的表现往往不尽如人意。为了提高预报的精确度,本文探索将长短期记忆(LSTM)神经网络和BP神经网络组合建立多模型组合预报模型,并将所得结果与单一的BP神经网络模型进行对比分析,探讨方法的适用性。
1 相关研究
随着计算机技术的发展以及对预报精确度要求的提高,传统的基于统计学的诸如ARMA[2]等预报模型由于精度较低,神经网络逐步成为水文预报[3]中应用最广泛的方法。王竹等[4]运用神经网络方法,以大伙房水库补水期的径流状况作为研究对象,尝试使用神经网络模型进行预测,结果表明该方法的预测成功率较高,容错能力强,有望成为径流长期预报的有效手段。曹广学等[5]采用改进的自适应BP算法,结合山西岔口流域的实测数据进行了降雨径流预报的研究,结果表明该模型预测精度较高。张巧利等[6]则使用BP人工神经网络与水文机制有机结合,并与常用的径流量模拟时间序列分析方法和传统的水箱模型进行比较,在龙羊峡水库取得了较为满意的结果。
但在洪水预报中,由于水文系统的复杂性[1,7]和水文要素的不确定性,仅仅运用单一的神经网络模型往往过于局限,无法从根本上全面提高水文预报的可靠性。为了优化神经网络模型,提高洪水预报的准确率,通常选择将神经网络和其他相关理论进行耦合建立组合模型。基于此,本文提出LSTM-BP洪水预报模型。
2 方法介绍
2.1 LSTM-BP多模型组合预报模型概述
BP神经网络虽然已广泛运用于水文预报,但其本身并没有时序概念,而且收敛速度慢,容易出现梯度消失等问题。而LSTM神经网络可以较好地解决上述问题,本文构建的多模型组合预报模型的技术路线如图1所示,先分别构建基于LSTM的水文预报模型和基于BP的水文预报模型,再建立LSTM-BP的多模型组合预报模型,对2个单模型预测器的拟合结果进行训练,最后根据实验结果评价模型优劣。
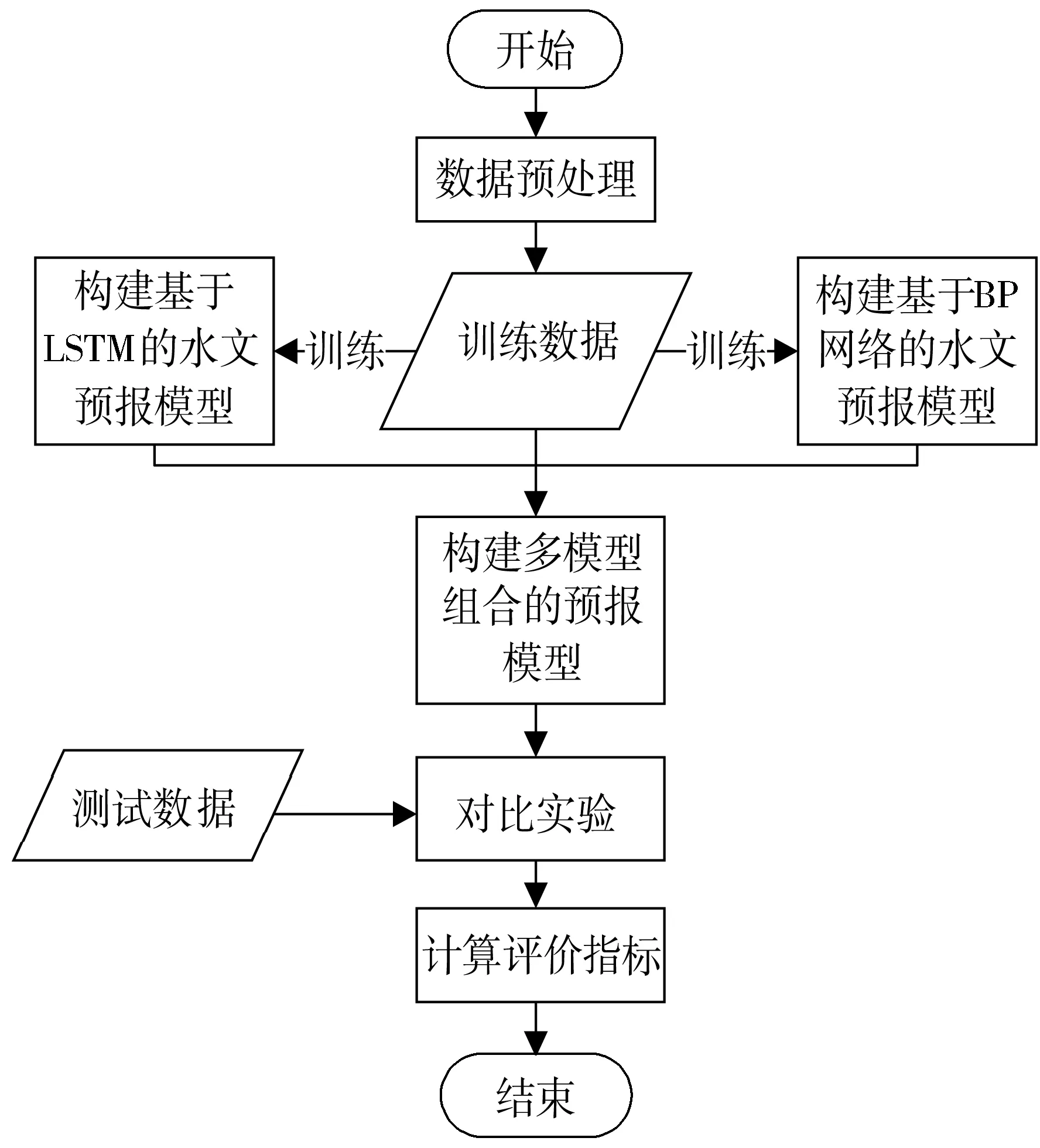
图1 技术路线图
2.2 模型数据准备及参数设定
本文以汉江子午河流域为中小河流代表流域进行研究,子午河系汉江上游北岸一级支流,分属宁陕县、佛坪县管辖。主源汶水河发源于宁陕、周至、户县交界的秦岭南麓,由东北向西南流经宁陕县境内,在宁陕县与佛坪县交界处与蒲河、椒溪河汇流后成为子午河,子午河由北向南于石泉县三华石乡白沙渡附近入汉江。其雨量站网图如图2所示。
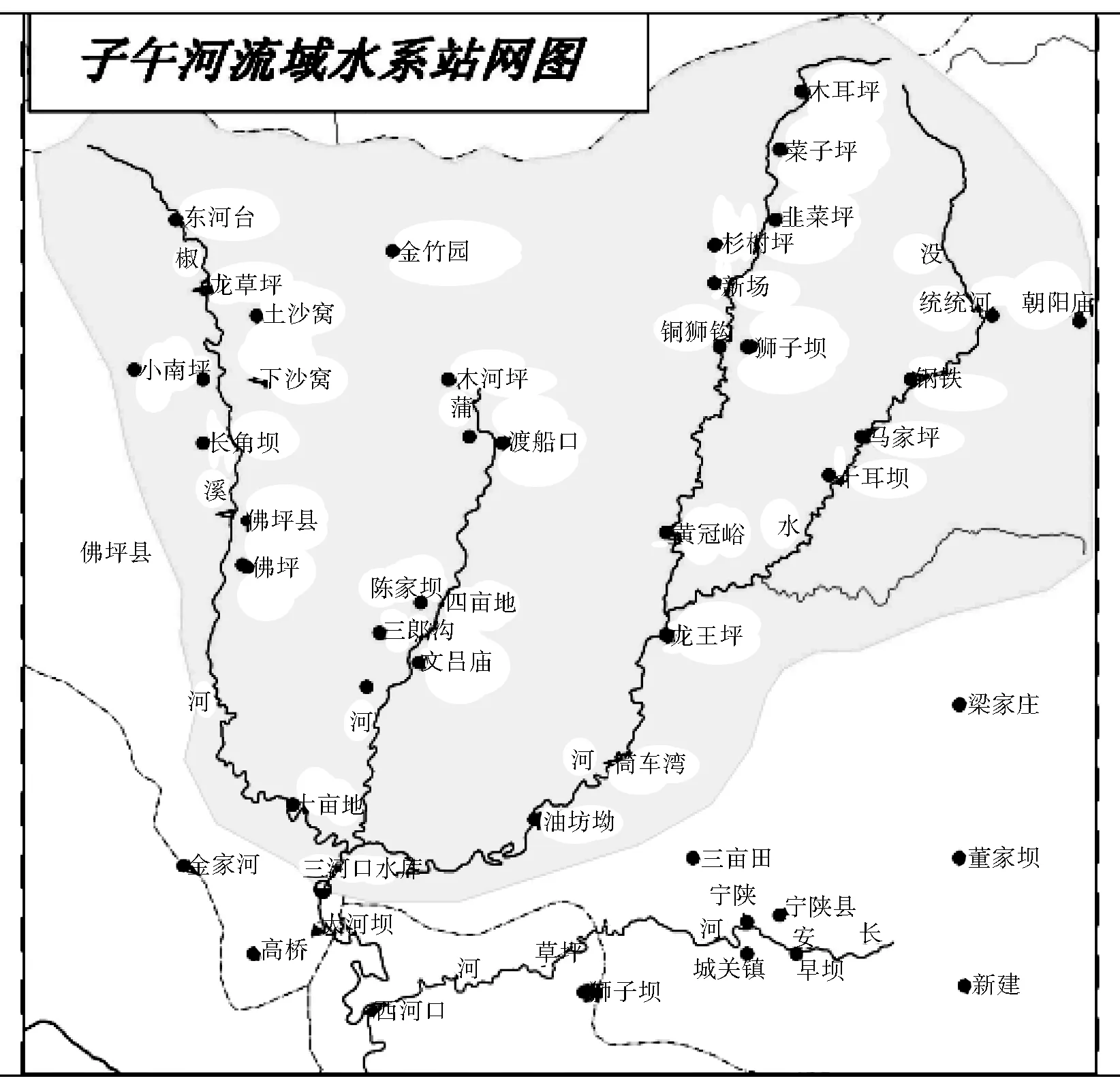
图2 子午河流域雨量站网示意图
本文选取子午河流域2008年至2014年每年汛期洪水数据,数据间隔1小时,共计43场洪水,预见期为12 h来对模型进行训练和验证。其中将前34场作为训练集,后9场作为验证集。
在洪水预报模型中,输入因子的选取是决定模型效果很重要的因素。考虑到降雨径流关系的复杂性,本研究除了子午河流域的径流量外,还将子午河流域上游6个气象观测站的降雨量作为预报因子添加入输入层变量。
模型参数的设定也是模型成功的关键,本文通过试错法,确定LSTM-BP神经网络的中间层数为3层,误差控制率为0.001,学习系数为0.1,节点数为200个,最大训练次数为1000次。
2.3 组合模型训练过程
设单模型预测器为fi(x)(i=1,2),多模型组合预报模型为F(x)。LSTM-BP神经网络训练过程如下:
Step1对N个样本数据进行归一化处理。
Step2从N个样本数据中抽取训练集S,用以训练单模型预测器fi(x)(i=1,2)。单模型预测器i在训练集S下的拟合结果为yic(SX)=fi(SX)(i=1,2)。
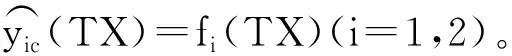
Step4用2个单模型预测器fi(x)(i=1,2)在训练集S下的拟合结果yic(SX)=fi(SX)(i=1,2),组合为多模型组合预报模型F(x)的训练样本输入:
SX′=[y1c(SX),y2c(SX)]
用训练集S的因变量SY作为多模型组合预报模型F(x)的训练样本的输出:
SY′=SY
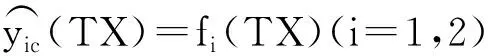
用测试集T的因变量TY作为多模型组合预报模型F(x)的测试样本的输出:
TY′=TY
Step6在多模型组合预报模型F(x)进行训练时,利用SX′与SY′作为多模型组合预报模型F(x)的训练数据的自变量与因变量,挖掘SY′,即SY与单模型预测器fi(x)(i=1,2)在训练集S下的拟合结果的隐含关系:
F:SX′→SY′
即F:[y1c(SX),y2c(SX)]→SY。
Step7在多模型组合预报模型F(x)的测试阶段,利用Step6中挖掘的隐含关系F,输入F(x)测试数据的自变量TX′进行预测:
上述训练过程中,具体的组合模型F(x)的训练集为:
组合模型F(x)的测试集为:
组合模型F(x)的自变量为单模型预测器fi(x)(i=1,2)的拟合结果或预报结果,因变量为原因变量。
组合模型F(x)的训练集自变量为:
SX′=[y1c(SX),y2c(SX)]
组合模型F(x)的训练集因变量为:
SY′=SY
组合模型F(x)的测试集自变量为:
组合模型F(x)的测试集因变量为:
TY′=TY
具体地,原始输入样本自变量X为当前径流量以及各观测站的降雨量,原始输出样本因变量Y为未来12 h的径流量。
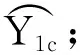
本文采用LSTM算法来进行多个单模型预测器的预报结果与原始因变量之间关系的挖掘,并进行单模型预测结果的组合挖掘,参数设定与第2.2节一致。
3 实验结果及分析
3.1 模型评判指标
根据《水文情报预报规范》可以采用绝对误差、相对误差、均方根误差、确定性系数等指标来进行评判,本文将基于此进行评价。
1)均方根误差。
在整个洪水预报的过程中,预测值yc(i)与真实值y0(i)之间的偏差的程度,值越小表明结果与真实值相差越小,其计算公式为:
2)确定性系数。
在洪水预报过程中,确定性系数越接近1,则说明预报准确率越高,其计算公式为:
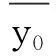
3)洪峰相对误差。
洪峰预报的准确性是衡量一个模型的重要指标,其计算公式为:
其中yfc为预测洪峰值,yf为实测洪峰值。
3.2 实验结果分析
根据《水文情报预报规范》,中长期水文预报允许误差应为变幅的20%,相对误差率=[(预测值-实测值)/实测值]×100%。由实验数据可知,LSTM-BP多模型组合预报模型的预报结果符合误差要求,预测结果符合实际情况,通过该模型进行预报完全可行。此处选取20130528场次洪水数据为例,具体数据如表1所示。
表1 20130528场次洪水实验数据
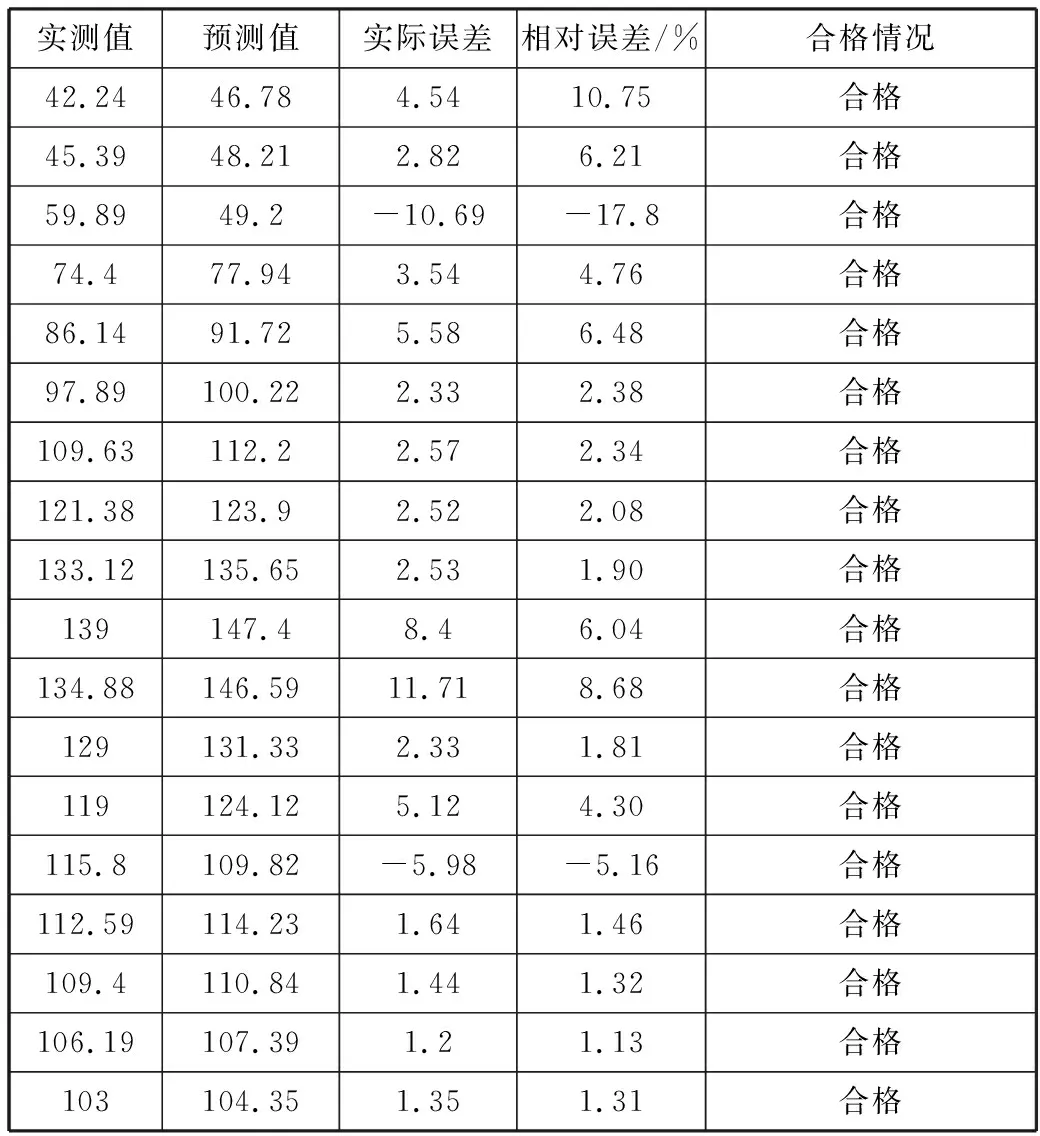
实测值预测值实际误差相对误差/%合格情况42.2446.784.5410.75合格45.3948.212.826.21合格59.8949.2-10.69-17.8合格74.477.943.544.76合格86.1491.725.586.48合格97.89100.222.332.38合格109.63112.22.572.34合格121.38123.92.522.08合格133.12135.652.531.90合格139147.48.46.04合格134.88146.5911.718.68合格129131.332.331.81合格119124.125.124.30合格115.8109.82-5.98-5.16合格112.59114.231.641.46合格109.4110.841.441.32合格106.19107.391.21.13合格103104.351.351.31合格
表2~表4则是多模型组合预报模型、单模型LSTM以及单模型BP在测试集上的实验结果。
表2 多模型组合预报模型实验结果
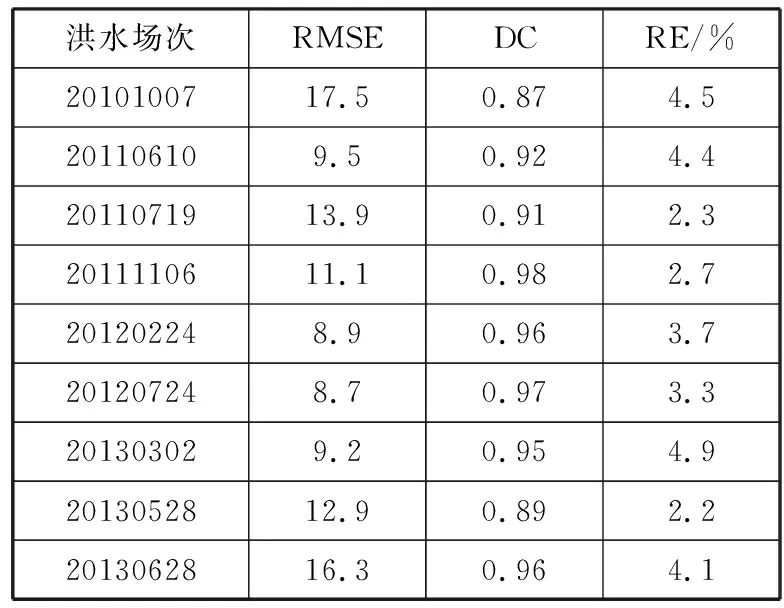
洪水场次RMSEDCRE/%2010100717.50.874.5201106109.50.924.42011071913.90.912.32011110611.10.982.7201202248.90.963.7201207248.70.973.3201303029.20.954.92013052812.90.892.22013062816.30.964.1
表3 单模型LSTM实验结果
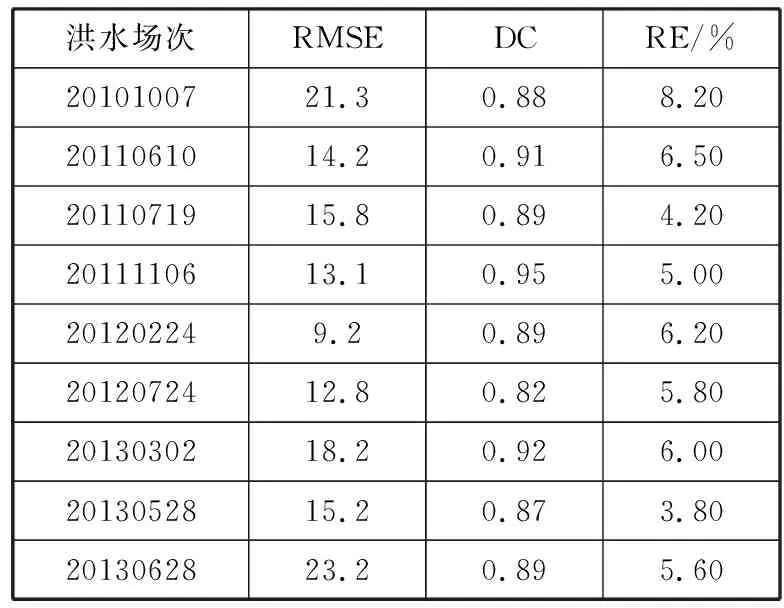
洪水场次RMSEDCRE/%2010100721.30.888.202011061014.20.916.502011071915.80.894.202011110613.10.955.00201202249.20.896.202012072412.80.825.802013030218.20.926.002013052815.20.873.802013062823.20.895.60
表4 单模型BP实验结果
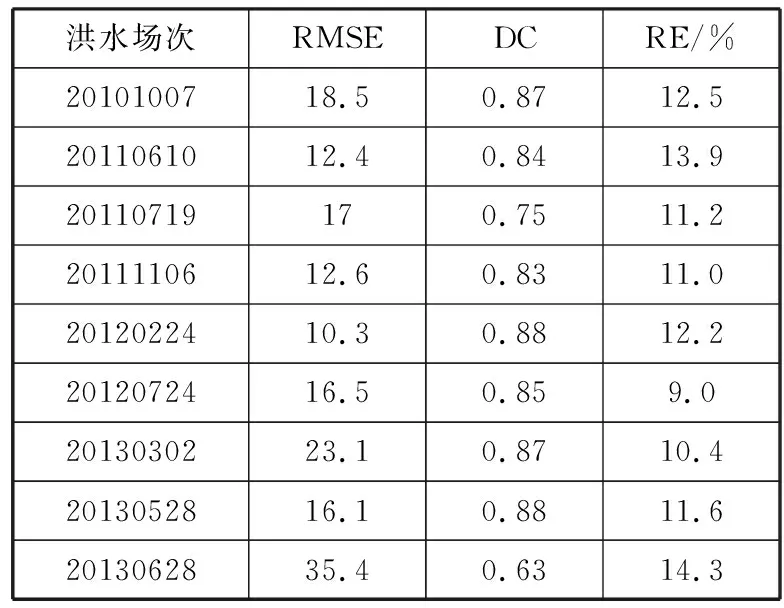
洪水场次RMSEDCRE/%2010100718.50.8712.52011061012.40.8413.920110719170.7511.22011110612.60.8311.02012022410.30.8812.22012072416.50.859.02013030223.10.8710.42013052816.10.8811.62013062835.40.6314.3
表5 不同模型的各指标的标准差对比
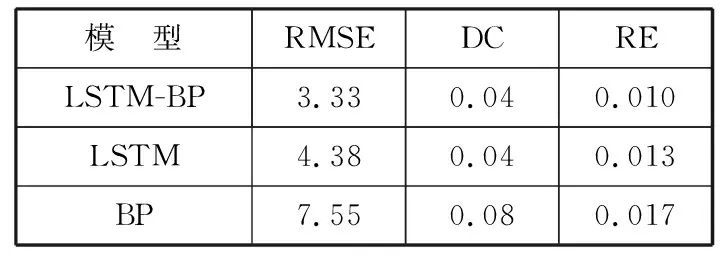
模 型LSTM-BPRMSEDCRE3.330.040.010LSTM4.380.040.013BP7.550.080.017
通过对实验结果进行分析和对比(表2~表4)后发现,LSTM-BP多模型组合预报模型得出的预报结果符合水文预报的要求,而且与单一的预报模型相比无论是在均方根误差或是确定性系数上,多模型组合预报模型得出的结果都更为精确,同时根据表5可知,多模型组合预报模型预报的结果相对更稳定。
通常使用T-test来检验模型效果是否得到显著提高,通过将测试集的RMSE结果进行T-test验证,一般认为T-test的值小于0.05即有显著提高。由表6可知,多模型组合预报模型能够较好地实现洪水预报,满足实际应用需要。
表6 T-test验证结果
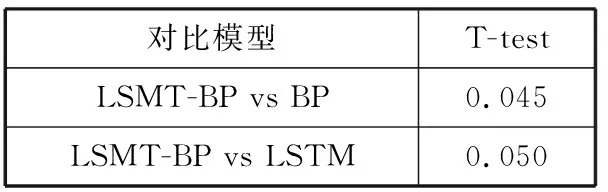
对比模型T-testLSMT-BP vs BP0.045LSMT-BP vs LSTM0.050
4 结束语
本文基于LSTM神经网络系统基本原理,结合BP神经网络构建LSTM-BP多模型组合预报模型对子午河流域洪水进行预报,相比单模型水文预报,有效提高了模型的精确度,为子午河流域洪水预报提供了更为科学的办法。
猜你喜欢
中国药房(2022年7期)2022-04-14
河北地质(2021年3期)2021-11-05
河北地质(2021年4期)2021-03-08
河南水利年鉴(2020年0期)2020-06-09
河南水利年鉴(2020年0期)2020-06-09
娃娃乐园·综合智能(2019年6期)2019-07-10
——与非适应性回归分析的比较
四川精神卫生(2019年2期)2019-06-18
天津诗人(2017年2期)2017-11-29
文理导航(2017年20期)2017-07-10
少儿科学周刊·儿童版(2015年7期)2015-11-24
