
负载均衡技术在并行化符号执行中的应用
2018-08-07 10:47李航,臧洌,甘露
计算机与现代化 2018年7期
李 航,臧 洌,甘 露
(南京航空航天大学计算机科学与技术学院,江苏 南京 211106)
0 引 言
符号执行技术是一种重要的程序分析技术,由King等[1]于1976年提出。路径爆炸和约束求解是目前制约符号执行效率和可扩展性的2大因素。目前针对提高符号执行效率主要有以下4个方面的研究。
1)解决路径爆炸问题。Wang等[2]通过消除冗余路径缓解了路径爆炸;Liu等[3]提出了探索符号状态缓存的方法来解决路径爆炸;Adachi等[4]提出了基于分布式控制流图(Control Flow Graph)的符号执行来解决传统符号执行不能处理含有循环的程序和易产生路径爆炸的问题。
2)研究约束求解,提高约束求解效率。Zhang等[5]提出了猜测符号执行减少约束求解次数;Zou等[6]通过消除冗余约束条件来化简约束;Li等[7]使用机器学习的方法来化简复杂约束;汤恩义等[8]使用线性拟合来处理带非线性约束、逻辑复杂的程序。
3)限制程序的分析范围,避免不相关的路径探索,主要用于回归测试[9-11]。
4)研究程序的并行性来并行化符号执行。Siddiqui等[12]提出了一种并行化符号执行的新技术,使符号执行的状态可以用测试用例简洁的编码;孙盼盼等[13]设计了分布式符号执行平台;Rakadjiev等[14]对KLEE符号执行引擎进行了扩展,增加了Z3求解器,实现了并发执行和异步约束求解。
符号执行可以系统地探索程序的路径并生成相应的测试输入,进行详尽的路径探索目的是为了发现更多的程序错误[16]。理论上讲,覆盖更多的路径通常意味着覆盖更多的程序行为,是更严格的软件测试[17]。然而程序中路径的数量通常随程序大小的增加呈指数增长,导致不能在可接受的时间内探索完整的路径空间。并行的思想是以空间换时间,能将整体耗时成倍地缩小,当程序过大且复杂导致符号执行时间不可接受时,并行方法是一个不错的选择。
并行任务的调度经常采用集中式调度策略和分布式调度策略。其中集中式调度实现起来简单,但会出现因信息交互或者临界资源的访问造成工作节点空闲等待的情况,这显然会影响并行的效率。本文分析集中式调度策略中造成工作节点空闲等待的原因,并对集中式模式进行了改进,在每个工作者节点与调度节点间设置了任务队列缓冲池,用来存放即将执行的任务和已完成等待返回给调度节点的任务。这样做是为了避免工作节点和调度节点的直接交互,使工作节点一直处于忙碌状态,提高并行效率。
本文分析并行的符号执行任务间的关系,发现任何时刻存在的待执行任务之间没有“先后”偏序关系,即并行任务的执行顺序可以随意。在此结论上,本文使用动态负载均衡技术来调度并行任务,以求各个目标处理机上的总执行时间最短。
1 符号执行的并行过程分析
1.1 并行路径搜索策略
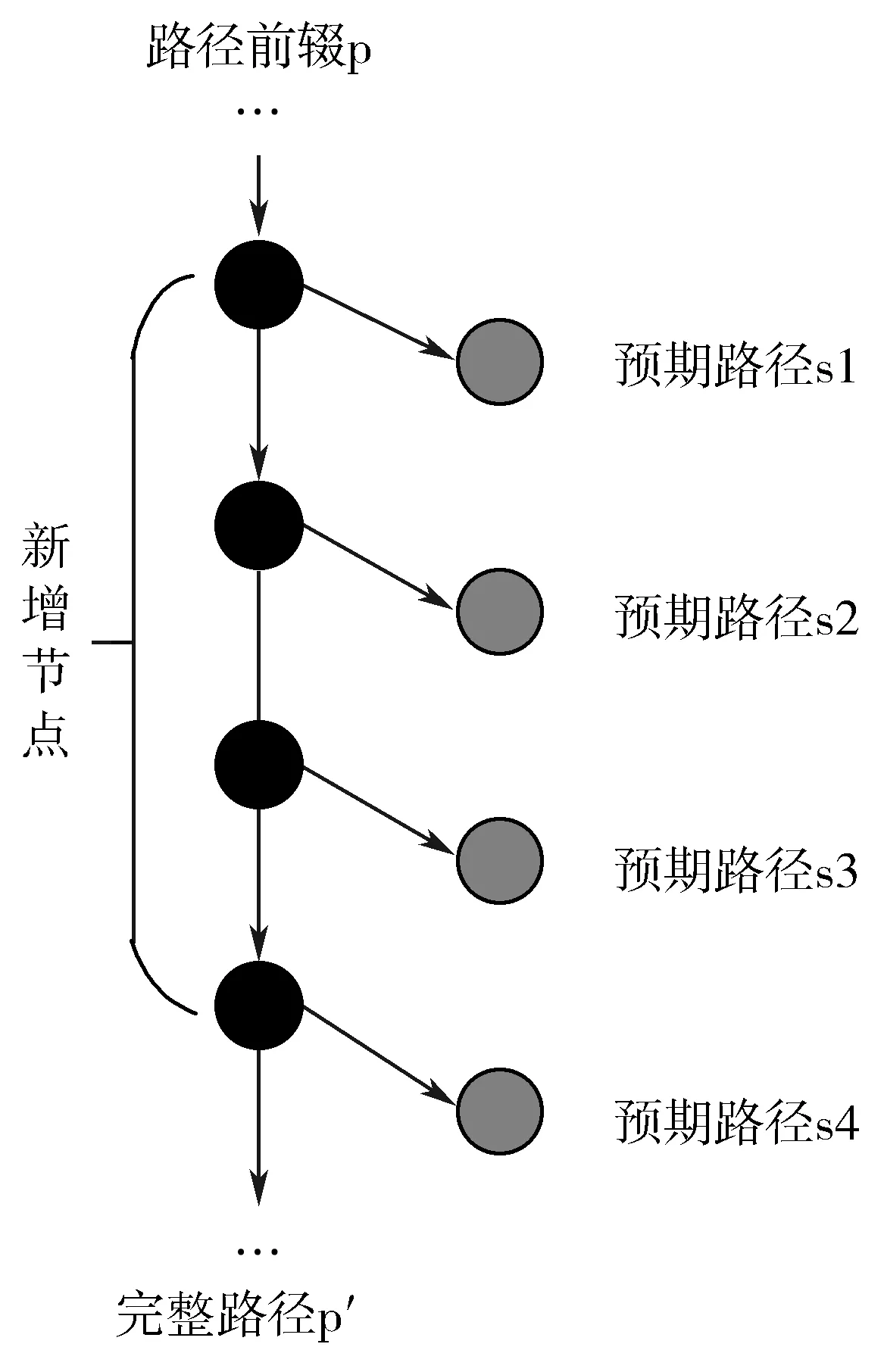
给定树上一条完整路径的前缀(代表了一次预期的执行,若这个前缀为空,则表示这是整个过程的首次迭代),非并行的动态符号执行会先通过路径约束并根据得出的测试输入执行待测程序,将路径前缀扩展成一条完整路径。之后尝试对此完整路径上的新增节点(不包括路径前缀)上的约束值取反,作为下一次迭代所预期的路径。假设新增的节点数为n,则约束取反的操作需要进行n次,产生n条新的预期路径。并行路径算法就是在一次迭代中将所有的后续预期路径全部生成,而这部分预期路径可以并行执行。本文设计了符号执行的并行算法GPP(p,p′),如算法1所示。
算法1GPP(p,p′)
输入:p是一个待测程序路径的二叉树上路径前缀的真值序列。
p′是一个待测程序路径的二叉树上完整路径序列,由p通过约束求解和实际执行扩展而来。
输出:一个包含预期路径(路径前缀)真值序列的集合。
1.TaskList={…}//Tasklist为任务列表
2.if |p|=|p′| then//拓展的路径没有新节点
3.return TaskList
4.end if
5.else
6.for i=|p| to |p′|-1
7.choice=<>
8.for j=0 to |p′|
9.if j
10.choice=choice ∪
11.else
13.end if
14.end for
15.TaskList=TaskList ∪ choice
16.end for
17.return TaskList
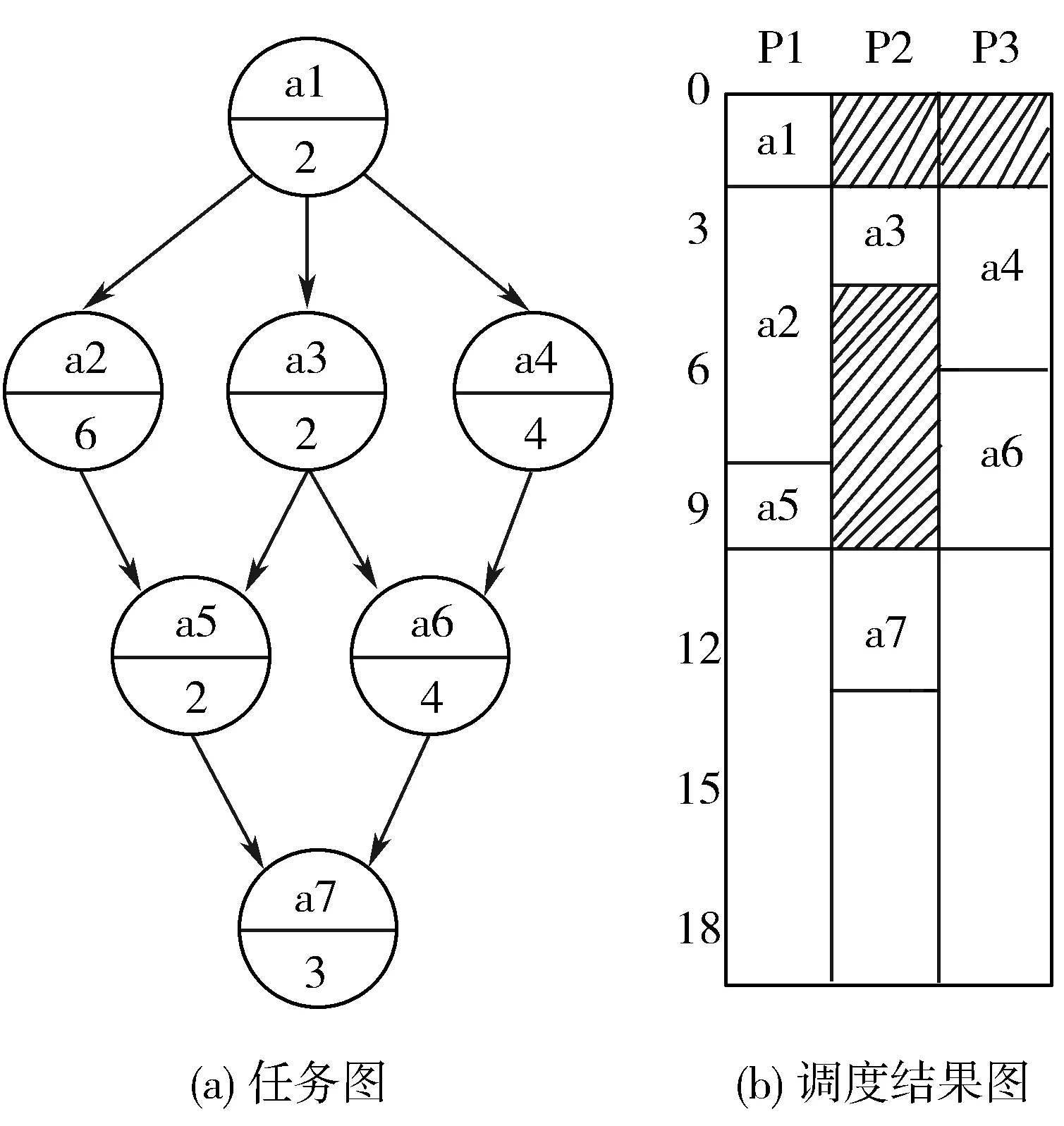
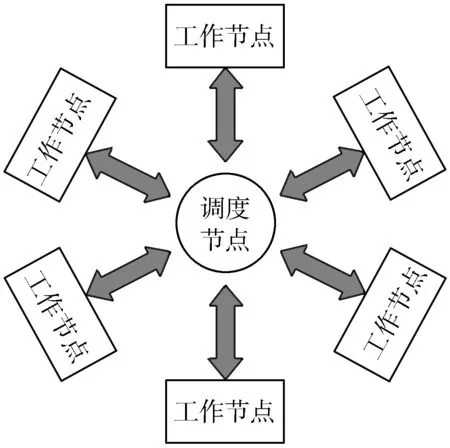
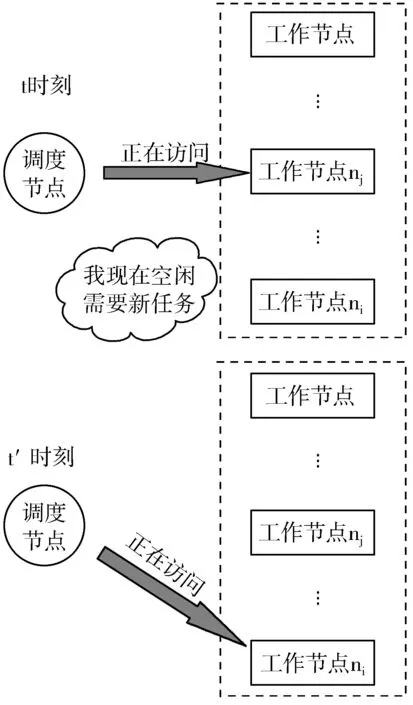
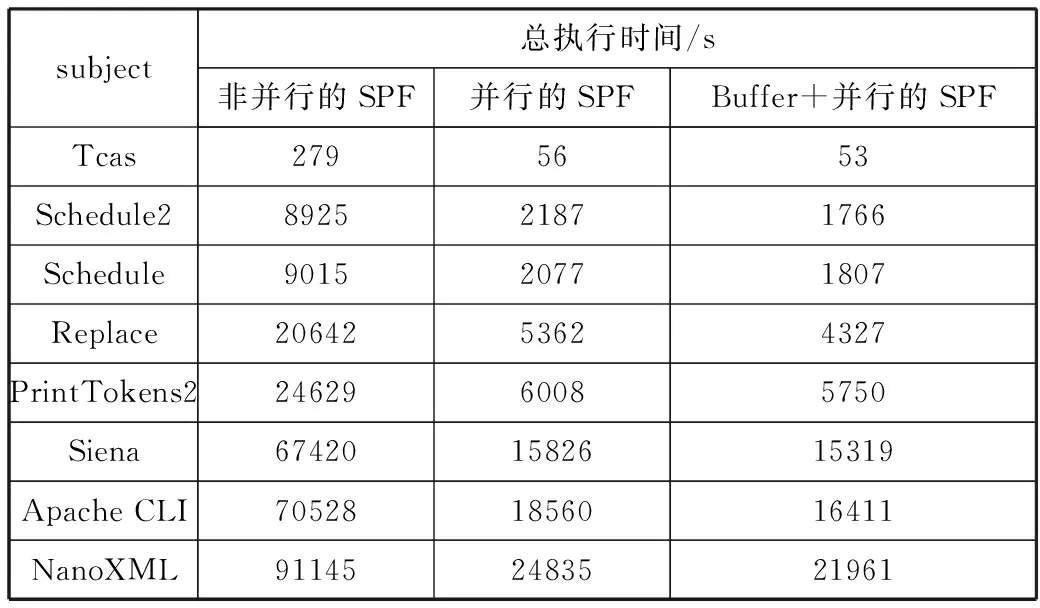
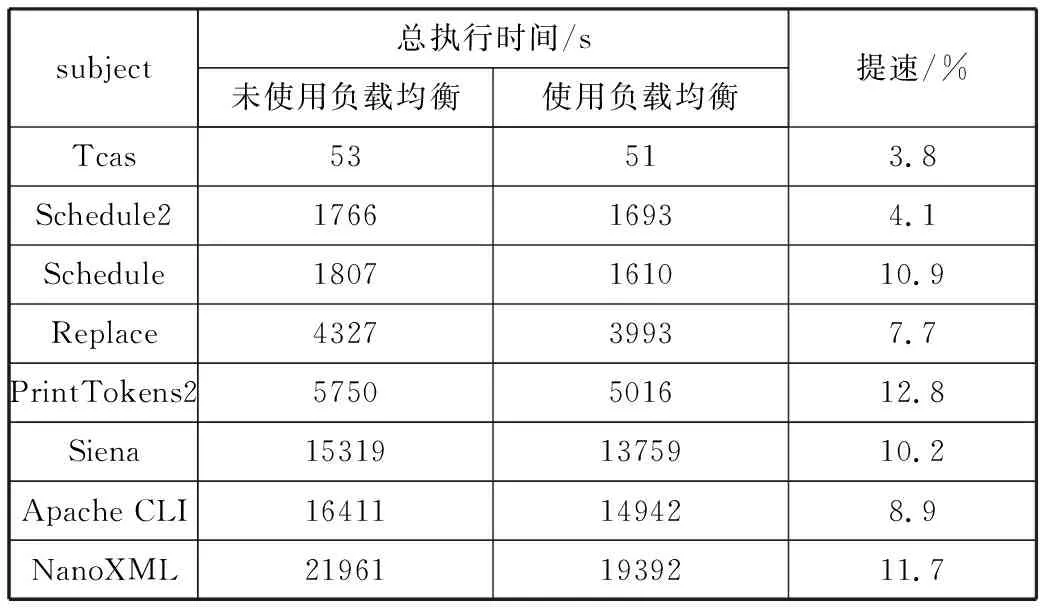
如果任务列表TaskList不为空,从中取出一条待拓展的路径p,动态符号执行拓展成p′。若p=p′,则直接返回任务列表。如果执行第6~17行的操作,其中第6行的外层for循环,i每次指向了拓展路径上的新增节点,第7行的内层for循环,j从路径p′的首节点开始,依次向下遍历路径上的节点,如果j 并行任务拆分完毕后,需要将这些任务并行执行。那么是挑选一部分任务优先执行,还是可以任意挑选执行?这涉及并行任务间的时序问题。那么算法GPP产生的后续路径搜索任务间是否存在执行顺序“先后”的偏序关系? 图1展示了GPP算法的路径搜索过程。路径p扩展成p′后,在新增的节点处取相反的约束条件,形成新的路径前缀。路径s1,s2,s3,s4就是此次迭代产生的新的预期路径,对它们进行扩展形成新的完整的路径p′。图2中,预期路径s4被扩展成完整路径s4′,在新增的第一个节点处取相反的约束条件得到后续预期路径s5。 将并行路径搜索任务间的“先后”作为任务集的一个偏序关系,可以得出,路径s1,s2,s3,s4的执行顺序晚于路径p,记为s1p,s2p,s3p,s4p;路径s5的执行顺序晚于路径s4,记为s5s4;而路径s1,s2,s3,s4之间的执行顺序不能确定,s5和s1,s2,s3之间的执行顺序也不能确定。假设t1时刻恰巧有未执行的路径s1,s2,s3,s4,t2时刻有未执行的路径s1,s2,s3,s5,那么这2个时刻的现有的任务都无法得出明确的执行顺序。通过分析,可以得出很直观的结论, 图1 路径p的扩展 图2 生成预期路径s5 对于任意一个未执行路径s,它只和产生它的路径存在执行“先后”的偏序关系,而对于任意时刻t,未执行的路径都不可能与产生它的路径同时存在,所以有结论1。 结论1任意时刻t,还未执行的并行任务之间不存在执行“先后”的偏序关系。 既然符号执行的并行任务之间没有执行“先后”的偏序关系,那么任务调度也就简单了许多。首先,了解带偏序关系的并行任务是怎么调度的。图3是一个任务间存在偏序关系的任务调度实例,图3(a)每个节点表示一个任务,横线下方为计算该负载的单位时间数,横线上方为负载标号。节点间的有向边代表任务间的偏序关系。图3(b)是任务在3个目标机P1、P2、P3上的一种调度方案。由于存在执行“先后”的偏序关系,a2,a3,a4必须在a1执行结束后才能开始,同理,a5必须在a2,a3之后执行,a6必须在a3,a4之后执行,a7必须在a5,a6之后执行。在考虑了执行“先后”的条件下,图3(b)给出了一种最优调度方案,最终执行完所有任务最短耗时为13。可以看出,偏序关系的存在,使得目标机P2、P3空闲了很长时间(图中的阴影部分)。 图3 带偏序关系的任务调度实例 符号执行的并行执行过程中,任务间没有偏序关系,即不用考虑某个任务要等其它特定任务执行完后再执行,这样目标机就不会有空闲时间,可以一直处于忙碌状态。假如图3中的任务不存在偏序关系,任务调度如图4所示,3个目标机P1、P2、P3一直处于忙碌,所有的任务执行完,花费的最短时间是8。 图4 无偏序关系的任务调度 从无偏序关系的任务调度图可以看出,任务调度简单了许多,只要把任务撒向目标机,保证各目标机一直工作而且每个目标机的总执行时间差异最小即可达到最优的任务调度。 虽然无偏序关系的任务调度可以简单地实现最优任务调度,但需要满足2个条件,一是目标机必须一直有任务可执行,二是如何均衡每个目标机的负载,以达到每个目标机总执行时间大致相等的目的。 集中式策略是在系统中设置一个中央节点,也称调度节点,负责任务的维护和分配。另有多个工作节点(等价于目标机)与之交互,接受运算任务。调度节点按照“轮询”或者“随机”的方法查看某一个工作节点的状态,如果该工作节点处于空闲,则分配新任务给工作节点,同时接收该工作节点已完成的任务;如果工作节点忙碌,则查看下一工作节点的状态。图5展示了集中式策略的工作模式,它由一个调度节点和n(n>1)个工作节点组成。 图5 集中式工作模式 集中式策略中工作节点有时会处于空闲状态,这是因为没有后继任务可执行,一直在等待调度节点分配任务。例如t时刻,工作节点ni处于空闲,需要调度节点分配新的任务,而调度节点正采用“轮询”的方式访问工作节点nj的状态,要等到t′(t≠t′)时刻才能访问到工作节点ni,导致工作节点ni不得不等待。图6给出了工作节点空闲情况的描述。 图6 工作节点空闲的情况 分析工作节点空闲的情况可以发现,调度节点繁忙,不能及时地响应工作节点的请求,是造成工作节点空闲等待的主要原因。集中式策略只有一个调度节点,在工作节点很多时,因为工作节点都要与调度节点交互,必然导致严重的冲突,工作节点的空闲情况就更加严重。如何解决交互时间的冲突,是消除工作节点空闲等待,提升并行效率的关键。 缓冲区又称缓存,是内存空间的一部分。这是在内存空间预留了一定的存储空间,用来缓冲输入或者输出的数据,这部分预留空间就叫做缓冲区。缓冲技术是为了协调吞吐速度相差很大的设备之间数据传送工作。在数据到达与离去速度不匹配的地方,就应该使用缓冲技术。缓冲技术好比是一个水库,如果上游来的水太多,下游来不及排走,水库就起到“缓冲”作用,先让水在水库中停留一些时候,等待下游能继续排水,再把水送往下游。 并行策略中的调度节点和工作节点,可以是处理速度相近的不同计算机,或者多核CPU的不同内核单元,两者的处理速度基本相同。但是调度节点分配任务的速率和工作节点的处理速度相差太多,也就是说,工作节点处理完一个并行任务需要时间Δt,而调度节点访问同一工作节点的时间间隔是Δt′,Δt≪Δt′,所以工作节点会因为等待新任务而处于空闲状态。 图7 带缓冲区的集中式模式 受到缓冲区作用的启发,本文在每个工作节点和调度节点之间增加了一个缓冲区,用来存放即将执行的任务队列和已经完成的任务队列,以此来缓解任务分配和接收速度与工作节点处理速度不匹配的问题。图7是加了缓冲区后调度节点与工作节点的交互情况。 调度节点仍然按照“轮询”或者“随机”的方式访问工作节点,不过它不直接跟工作节点交互,而是把新的任务放在缓冲区的未执行任务队列中,同时取走已执行的任务队列。工作节点也不直接跟调度节点交互,完成一项任务时,将完成的任务放置在缓冲区的已执行任务队列中,同时从未执行的任务队列中取新的任务执行。缓冲区的设置,使得工作节点不必等待调度节点访问到自己时才获得新任务和返回任务,保证了工作节点一直处于忙碌状态,提高了并行的效率。 集中式策略的改进解决了工作节点空闲等待的问题,但也带来了新的问题,即无条件地给每个工作节点发放任务导致各个工作节点负载不一致的问题。虽然各工作节点处理速度相当,但是任务大小的不同势必导致处理时间长短的不同。如何使各个工作节点的总执行时间大致相等,就要使用负载均衡技术。 为了改善系统的性能,通过在多台计算机之间合理地分配负载,使各台计算机的负载基本均衡,这种计算能力共享的形式通常被称为负载均衡或负载共享。一般来说,“负载均衡”要达到的目标是使各台计算机之间的负载基本均衡,而“负载共享”意味着只是简单的负载的重新分配。一个负载均衡算法包含以下3个组成部分[15]: 1)信息策略。放置策略所需要的负载或者任务量以及任务分配的方式,包括负载大小的判断标准和负载均衡的策略方式。 2)传送策略。基于任务和计算机负载,判断是否要把一个任务传送到其它计算机上处理。 3)放置策略。对于适合传送到其它计算机处理的任务,选择任务将被传送的目的计算机。 放置策略利用信息策略提供的负载信息,仅当任务被传送策略判断为适于传送之后才行动。 整个并行过程中,工作节点缓冲区中的未执行任务队列的长度是动态变化的,如果不采取一定的策略调控未执行任务队列的长度,可能出现未执行任务队列过长或者为空的情况。 本文对集中式策略进行改进,增加了任务缓冲队列,未执行任务队列中的任务数即代表了当前工作节点的负载。由于每个任务的执行时间很短,而且无法预测每个任务的执行时间,所以选用未执行任务队列的长度作为描述负载大小的信息。相应地,本文采用最短任务队列策略作为放置策略。 最短任务队列策略:调度节点遍历每个工作节点,查看它们的任务队列长度,任务被传送到具有最短任务队列长度的工作节点。如果遇到任务队列长度为0的工作节点,不再查看其它工作节点,直接分配任务给此工作节点。图8给出了具体算法流程图。M为比较变量,L为队列长度,工作节点数为n。初始化时变量M为遍历的第一个工作节点的任务队列长度L0,之后遍历其余工作节点,M根据式(1)更新: (1) 图8 最短任务队列算法 并行化的实验在1台含有1个2.66 GHz Intel Core i7处理器以及16 GB内存的计算机上进行,该处理器提供了8个逻辑处理器。使用的符号执行工具SPF(Symbolic PathFinder)的执行环境部署在Ubuntu 14.04 64位系统中,采用多线程编程,这里有7个工作节点和1个中央调度节点,除了中央调度节点外,还将为每个工作节点单独分配了1 GB的内存空间,作为缓冲区。实验选中的程序中,除了Tcas比较小,执行时间短外,其余程序普通符号执行下的时间都在2 h以上。本文做了2组对照试验,一组是在没有使用负载均衡技术的情况下,带缓冲区的集中式调度策略和传统的集中式调度策略的提速对比。另一组是在使用带缓冲区的集中式调度策略的情况下,使用了负载均衡技术和未使用负载均衡技术的效率对比。为了减少误差,每组实验的每个程序都做了3次符号执行,以3次的平均值为最终结果。 表1统计了在没有使用负载均衡的情况下,非并行的SPF、并行的SPF和带缓冲区的SPF这3种方法分别对8个实验程序的符号执行时间。表2统计了在使用带缓冲区的集中式调度策略的情况下,使用和未使用负载均衡技术的符号执行时间。可以看出,在不使用负载均衡技术的情况下,2种并行策略均成倍地缩短了符号执行的时间,而且带Buffer的集中式并行策略要比没有Buffer的集中式并行策略用时更短。使用了负载均衡技术后,能进一步提高并行效率。图9是普通的集中式调度、带缓冲区的集中式调度以及在带缓冲区的集中式调度上进一步使用负载均衡技术的3种并行手段,它们相对于非并行的符号执行各自加速的倍数。柱状图中的数字表示倍数,一共有8组程序,可以看出,改进的集中式模式,由于缓冲区的作用,使得工作节点空闲等待时间减少,整体效率提升。而负载均衡技术的使用能进一步提高并行效率,总体来说,本文的策略能再提高约1倍的加速。 表1 未使用负载均衡下的符号执行时间对比 subject总执行时间/s非并行的SPF并行的SPFBuffer+并行的SPFTcas2795653Schedule2892521871766Schedule901520771807Replace2064253624327PrintTokens22462960085750Siena674201582615319Apache CLI705281856016411NanoXML911452483521961 表2 负载均衡技术的使用对符号执行时间的影响 subject总执行时间/s未使用负载均衡使用负载均衡提速/%Tcas53513.8Schedule2176616934.1Schedule1807161010.9Replace432739937.7PrintTokens25750501612.8Siena153191375910.2Apache CLI16411149428.9NanoXML219611939211.7 至于为什么工作节点一直处于忙碌,而带Buffer的集中式策略却没有提速7倍(共有7个工作节点),这是因为本文的实验是在1台计算机上,在满负荷的状态下,计算机单核的处理速度有所下降。另一方面,任务队列也属于临界资源,工作节点和调度节点仍有可能因为同时需要修改任务队列而导致一方空闲等待。 图9 3种并行策略的提速对比 动态符号执行采用集中式策略进行并行执行,可以成倍缩短符号执行时间,但集中式策略中容易出现工作节点空闲等待的情况。受到缓冲区作用的启发,本文在原有的集中式策略中加入了缓冲区,用来存放即将执行的任务队列和已经完成的任务队列。这种方法解决了调度节点发放任务速度和工作节点执行任务速度不匹配的问题,减少了工作节点的空闲等待时间。 本文分析了动态符号执行的并行过程,发现任意时间点存在的并行任务之间没有“先后”的偏序关系,因此可以随意发送任务到任意工作节点。结合集中式策略的改进,缓冲区中任务队列的大小成为了影响并行执行时间的关键因素。本文使用负载均衡技术,采用简单的最短任务队列算法,实现了各个工作节点缓冲区中未执行任务量的均衡,使得所有工作节点的总执行时间大致相等。实验证明,使用带Buffer集中式策略和负载均衡技术,对比原有的集中式策略,可以再提速1倍左右。1.2 并行任务间时序关系的分析

1.3 无偏序关系的并行任务调度

2 集中式策略的优化
2.1 集中式策略的弊端
2.2 带缓冲区的集中式模式

3 工作节点负载的均衡
3.1 负载均衡技术
3.2 最短任务队列调度算法

4 实 验
4.1 实验设计
4.2 实验结果

5 结束语
猜你喜欢
湖南文理学院学报(自然科学版)(2022年4期)2022-10-13
环境工程技术学报(2022年3期)2022-06-05
能源(2018年8期)2018-09-21
天津师范大学学报(自然科学版)(2018年4期)2018-09-11
计算机系统应用(2018年3期)2018-04-21
汽车零部件(2017年4期)2017-07-12
浙江大学学报(理学版)(2016年5期)2016-09-16
中国工程机械学报(2016年5期)2016-03-07
中国交通信息化(2015年5期)2015-06-05
太阳能(2015年6期)2015-02-28
