
基于对数几率回归的函数级软件缺陷定位
2018-08-07 10:53周明泉江国华
计算机与现代化 2018年7期
周明泉,江国华
(南京航空航天大学计算机科学与技术学院,江苏 南京 211106)
0 引 言
在软件开发过程中,软件测试消耗大量的资源,软件缺陷定位是软件测试环节中的重要一环,也是比较困难的一步。为了提高软件测试的效率,研究快速定位软件缺陷位置的方法成为一个重要的研究课题[1]。
现有的缺陷定位方法大都是在语句或语句块级别进行的,主流的是基于频谱的缺陷定位方法[2-4]。这类方法主要是利用测试用例在语句或语句块上的执行信息,计算语句或语句块的可疑值大小,按照可疑值的大小依次进行缺陷检查。还有基于程序切片的定位方法[5-7],这类方法主要是将各种切片技术应用于软件缺陷定位,缩小定位范围;基于数据挖掘软件缺陷定位方法[8],利用关联规则挖掘执行序列与测试用例通过或失败的关联关系;基于状态依赖的软件缺陷定位方法[9],主要是将程序控制流图看成有向图,程序的执行是从一个状态转移到另一个状态,根据状态转移的概率确定状态的检查次序。
在软件开发过程中,系统测试缺陷位置的定位更为复杂:一个项目包含大量函数,其中语句的数量更为庞大,在这种情况下语句级别的缺陷定位技术难以适用。针对这种情况,一些人提出基于组件的软件缺陷定位方法[10-11],文献[12]在此基础上提出一种二次定位策略,其主要是对函数调用图和函数执行路径进行分析,得出可能包含缺陷的函数组合情况,并利用模型诊断的方法对这些组合进行可疑度衡量,按照可疑度的高低对这些组合进行缺陷查找,最后对确定的包含缺陷的函数使用DStar定位函数定位具体的缺陷代码行。文献[13]同样提出类似的方法,他们将整个定位过程分为函数故障定位和语句故障定位2个层次。这些方法的定位对象主要是函数,但是在系统测试的环境下,函数的数量大,定位的范围依然很大,直接定位到缺陷函数比较困难,采用“子系统-模块-函数”层次的缺陷分析思路能加快定位效率。同时,在系统测试时,可能需要大致判断出错的子系统或者模块,从而添加相应的测试用例。因此,本文提出一种系统测试环境的缺陷函数定位方法:首先通过分析失败测试用例在子系统和模块上的执行信息,将测试用例大致划分为不同缺陷类别;然后利用对数几率回归的思想,构建模块(函数)的执行对测试用例成功或失败的关联度,得出模块(函数)的可疑度值;最后按照模块(函数)的可疑度值的大小依次检查出含缺陷的模块(函数)。
1 基于对数几率回归函数级软件缺陷定位方法LRFLF
1.1 缺陷定位方法框架
在现有的故障定位方法中,少量函数中含缺陷的语句的定位问题已经有很多解决方案,本文主要解决的是在系统测试时,软件代码规模庞大情况下的缺陷函数定位问题。系统测试情况下,定位对象是整个软件代码,其规模比较庞大,例如,第一版Photoshop共有12.8万行代码组成,对整个系统插桩收集语句的执行信息较难实现,并会影响软件的执行效率,而且会导致目前的定位技术产生庞大的计算量,可操作性较小。另外,整个系统中函数交互关系复杂,增大了定位缺陷的难度。在系统测试时,测试人员进行缺陷查找的方法一般是按照测试用例的执行过程进行逐步检查,这种方法检查效率较低。因此,有必要对系统测试环境下的缺陷定位技术进行研究。
在缺陷原因分析的过程中,应该先分析出错的子系统,再分析出错的模块,然后是函数,逐步求精。基于上述的思想,本文提出一种逐层分析的缺陷函数定位方法,其整体框架如图1所示。首先,根据软件需求说明书和软件系统设计说明书,提取软件子系统、模块以及函数之间的构成关系;然后根据失败测试用例的函数执行轨迹,分析其相应的模块及子系统执行轨迹;根据失败测试用例的子系统执行轨迹和模块的执行轨迹对失败测试用例进行归类,将可能属于同一子系统和同一子模块的测试用例依次进行划分;最后对其中划分的每组失败测试用例进行缺陷函数定位。在确定存在缺陷的函数后,进行语句级缺陷定位,该模块完成对函数内的缺陷语句进行定位,本文采用基于频谱的定位方法,利用Tarantula方法计算每个语句的可疑度,根据语句的排序依次检查。因为语句级的定位方法相同,所以本文实验主要比较各种定位到函数层次的定位效率。
1.2 子系统、模块和函数描述
在软件设计的过程中,一般会将软件划分为多个子系统设计,每个子系统由多个模块构成,每个模块由多个函数合作实现。本文中一个软件系统记为Sys,子系统记为SubSysi(i=1,…,ns,ns为子系统个数,每个子系统对应一个编号),模块记为Modi(i=1,…,nM,nM为模块个数,每个模块对应一个编号),函数记为Funci(i=1,…,nk,nk为函数个数,每个函数对应一个编号)。
Sys={SubSys1,SubSys2,…,SubSysns}:表示系统Sys由SubSys1,SubSys2,…,SubSysns这ns个子系统构成。
SubSysi={Mod1,Mod2,…,Modj}:表示子系统SubSysi由Mod1,Mod2,…,Modj这j个模块构成。
Modi={Func1,Func2,…,Funck}:表示模块Modi由Func1,Func2,…,Funck这k个函数构成。
通过对软件需求说明书和系统设计说明的分析,描述出整个系统的子系统、模块的构成。对于一个测试用例,将其函数的执行信息映射为模块的执行情况和子系统的执行情况。因此,每个测试用例信息包含3个执行集合:子系统执行集合、模块执行集合以及函数执行集合。
1.3 测试用例归类
在系统测试时,一般会出现较多的失败测试用例,这些失败的测试用例分布在各个子系统或者模块中,在进行函数缺陷定位之前,需要先尽量将属于不同子系统和不同模块的失败测试用例分离开,减少它们之间的相互干扰,同时减小缺陷函数定位时的搜索范围。
定义1互异集合簇。对于一个集合簇C={S1,S2,…,Sn},其中S1,S2,…,Sn均代表集合,若集合簇C满足性质∀Si,Sj∈C,Si∩Sj=Ø,则称集合簇C为互异集合簇,记为Cd。例如,集合簇{{1},{2}}为互异集合簇,集合簇{{1,2},{2}}不是互异集合簇。
定义2互异数。对于一个互异集合簇Cd={S1,S2,…,Sn},其包含元素的个数n称为互异数。例如,互异集合簇{{1},{2}}的互异数为2。
定义3互异子集。对于一个集合簇C={S1,S2,…,Sn},若集合簇C的子集C′是互异集合簇,则称C′为集合簇C的互异子集。例如,集合簇{{1},{2},{2,3}},其子集{{1}}、{{2}}、{{1},{2,3}}均为互异子集。
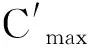
所有失败测试用例的子系统执行集合构成一个集合簇CSubSys,CSubSys={Fs1,Fs2,Fs3,…,Fsm},其中Fsi表示第i个失败用例执行的子系统构成的集合(子系统执行情况相同的只表示一次),例如Fsi={SubSys1,SubSys2}。求解集合簇CSubSys的最大互异子集即为子系统级别的分类结果,将最大互异子集中的每个集合作为一类。例如集合簇CSubSys={{SubSys1},{SubSys2},{SubSys3},{SubSys1,SubSys2}},其最大互异子集为{{SubSys1},{SubSys2},{SubSys3}},所以将失败测试用例分为3类,只执行SubSys1子系统的失败测试用例为一类,只执行SubSys2子系统的失败测试用例为一类和只执行SubSys3子系统的失败测试用例为一类。对于剩余的失败测试用例,将它们分配给所有与它们有交集的测试用例,例如{SubSys1,SubSys2},它与{SubSys1}和{SubSys2}这2类都存在交集,因为这种失败测试用例无法确定其存在缺陷的子系统,将{SubSys1,SubSys2}的测试用例同时归属于2类。这一步估计出每个失败测试用例对应的缺陷子系统。
取上述的一类分类结果,如{SubSys1},{SubSys1,SubSys2},所有属于这一类的失败测试用例的模块执行集合构成一个集合簇CMod,CMod={Fm1,Fm2,Fm3,…Fmi,…,Fml},其中Fmi表示第i个失败用例执行的模块构成的集合(模块执行情况相同的失败测试用例只表示一次)。同上所述,求解集合簇CMod的最大互异集合簇即可得出模块级别上的分类结果。
最大互异子集求解算法的伪代码如算法1所示,其主要是通过遍历集合簇,得出所有可能的互异子集,取其中互异数最大的子集为输出结果。求取互异子集最多有2n-1种可能组合,该算法的算法复杂度为O(n2),遍历过程中删减了一些不符合互异条件的子集,提高了搜索的效率。
算法1最大互异子集算法
输入:集合簇C={S1,S2,…,Sn},Si表示每个测试用例的子系统或模块执行信息集合。
1 for(all Si∈C)
2 C′={Si}
3 for(all Sj∈C)
4 if(isset(SjC′))//判断Sj与集合簇C′中的集合交集是否均为空
5 C′=C′∪{Sj}
6 save(C′,result)//将C′存储于解集result中
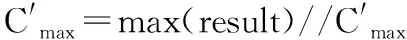
1.4 模块及函数级缺陷定位方法
若测试用例执行一个缺陷模块(函数),则测试用例失败的可能性较大;反之,则测试用例成功的可能性增大。对于一个失败的测试用例,其执行的每个模块(函数)都与测试用例失败关联,与测试用例失败关联大的模块(函数)其出错的可能性更大。函数级缺陷定位的目的是寻找与测试用例失败关联关系大的模块并进行检查。本节阐述模块的执行与测试用例的成功或失败之间的关联关系的度量方法。
完成模块级别分类之后,取分类结果中的一类构建缺陷定位信息。将模块级别缺陷归类的最大互异子集中的每个集合作为定位目标,添加与该类失败测试用例模块执行集合相交的成功和失败测试用例的模块执行信息,共同构成缺陷定位的初始信息。例如模块级别缺陷归类中求得的最大互异子集为{{Mod1,Mod2},{Mod3,Mod4}},取{Mod1,Mod2}这一类的失败测试用例,添加所有执行过模块Mod1和Mod2的测试用例的模块执行信息,构建缺陷模块的定位信息。
定义测试用例的成功与失败的关联关系如公式(1)所示,xi表示对应第i个模块的执行情况(取值1表示该模块被执行;取值0表示该模块未被执行),θi代表模块对测试用例执行结果的影响度。gθ(x)的值表示一个测试用例结果为失败的概率,该公式值域为(-∞,+∞),但期望的值域为[0,1]。
gθ(x)=θ0+θ1x1+…+θnxn
(1)
因此,本文将对数几率回归[14-17]的思想应用于函数级软件缺陷定位,如公式(2)所示,记测试用例的类别为0或者1(1表示失败,0表示成功),x表示测试用例各个模块的执行信息(1表示该模块被执行,0表示该模块未被执行)。在一次定位中,x1,…,xn的值为最大互异子集其中一类的模块执行信息,如{Mod1,Mod2},只根据x1,x2的值进行计算,n=2。公式(3)表示测试用例失败的概率,公式(4)表示测试用例成功的概率。然后需要通过已有的测试用例的执行信息求解θ值,即各个模块与测试用例的失败的关联度。
(2)
P(y=1|x:θ)=hθ(x)
(3)
P(y=0|x:θ)=1-hθ(x)
(4)
构造代价函数Cost(hθ(x),y),该函数表示概率计算结果与测试用例结果的偏差。由代价函数构造损失函数J(θ),即m个测试用例偏差的算术平均值。当J(θ)取最小值,即所有测试用例的平均偏差取最小值时,此时θ即为最佳权重。
(5)
(6)
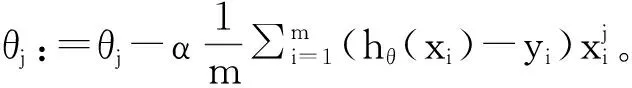
(7)
根据模块的可疑度值对模块进行排序,依次检查,确定出错的模块。将所有执行过该模块的测试用例构成函数级别的定位信息,进行函数级别的缺陷定位。该过程中x为该包含缺陷的模块中n个函数的执行情况,对于一个测试用例,xi表示对应第i个函数的执行情况(取值1表示该函数被执行,取值0表示该函数未被执行);yi值表示测试用例结果,若测试用例通过,则yi=0,若测试用例不通过,则yi=1。重复对数几率回归的计算过程,得出函数对用例执行失败的影响度θ′,再使用公式(8)计算出每个函数的可疑度值,得到函数排序列表,依次检查函数是否出错。
(8)
图2所示为一文件存储系统内的部分函数调用图,这些函数均属于同一个模块,其中函数Func10内存在缺陷。表1是针对该模块设计的测试用例,包括执行测试用例时各个函数是否被执行,以及测试用例的执行结果。例如测试用例t1包含一条定位信息:x=[1 1 0 0 0 0 0 0 1 1 0],y1=1。将表1中8个测试用例的信息运用对数几率回归的方法求解每个函数对用例执行失败的影响度θ′,再使用公式(8)计算每个函数的可疑度。在该例中,Sus(x10)=0.25,其它均为0,Func10可疑度最大,能较快地定位到含缺陷的函数。
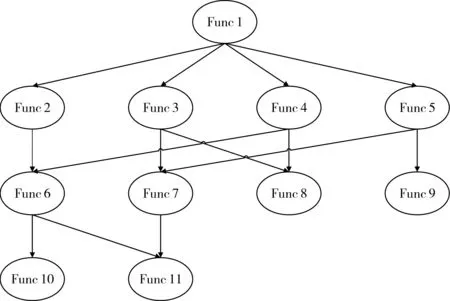
图2 文件系统某模块内函数调用图
表1 函数执行信息及测试用例结果
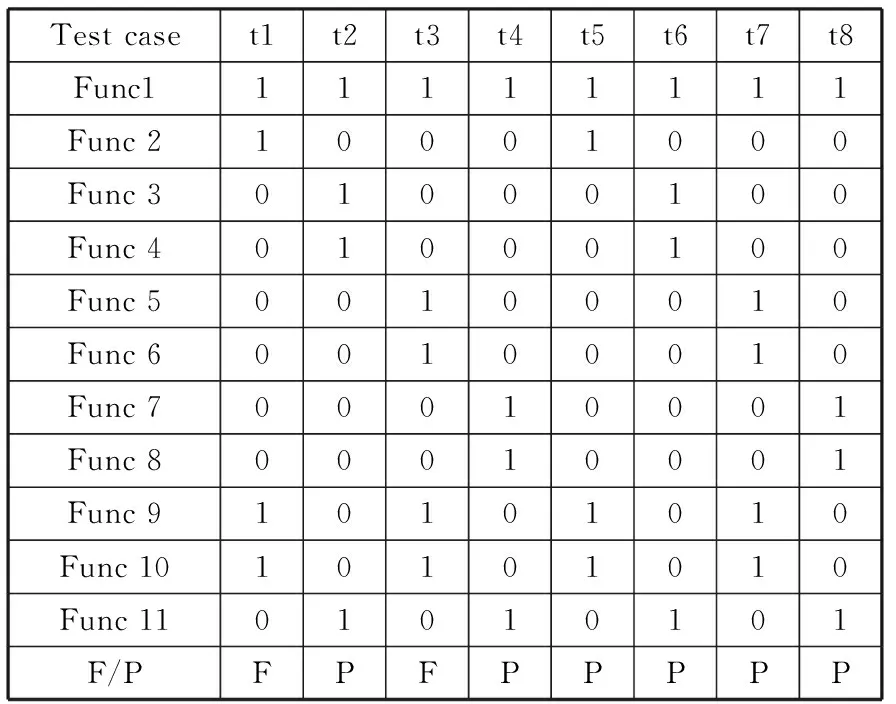
Test caset1t2t3t4t5t6t7t8Func111111111Func 210001000Func 301000100Func 401000100Func 500100010Func 600100010Func 700010001Func 800010001Func 910101010Func 1010101010Func 1101010101F/PFPFPPPPP
2 实 验
本文对某购物系统进行了实验,该系统包括消费者子系统,商家子系统和管理员子系统,如表2所示。通过对上述软件进行缺陷注入,控制代码中缺陷数量,每次测试用例的执行同时给出该测试用例的函数执行序列。本次实验与另外2种缺陷定位方法进行对比,一种为按照失败测试用例的函数执行顺序依次进行缺陷检查(Normal),另一种为直接计算函数的Tarantula可疑度值,按照可疑度的排序进行检查。
表2 购物系统主要构成
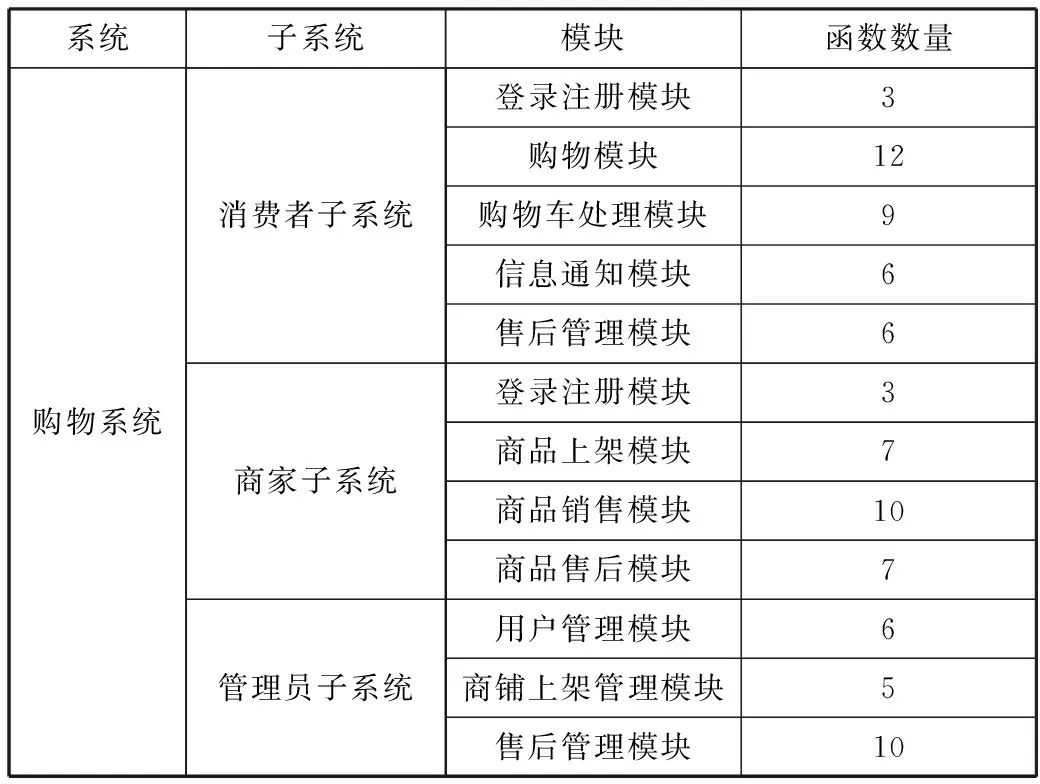
系统子系统模块函数数量购物系统消费者子系统商家子系统管理员子系统登录注册模块3购物模块12购物车处理模块9信息通知模块6售后管理模块6登录注册模块3商品上架模块7商品销售模块10商品售后模块7用户管理模块6商铺上架管理模块5售后管理模块10
本文采用的评价指标为EXAM,EXAM表示检查到缺陷函数时已检查函数个数占总函数个数的百分比。本文方法统计的已检查函数包括检查的模块数,即检查的模块数与检查函数的数目之和。实验结果如表3所示,其中实验1为只注入一个缺陷,实验2为在同一子系统的不同模块注入2个缺陷,实验3为在同一模块的不同函数中注入2个缺陷,实验4为在不同的子系统中注入2个以上的缺陷。
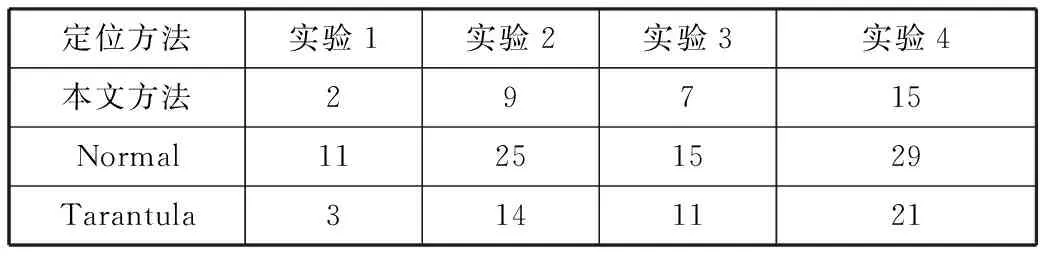
表3 实验结果对比 单位:%
实验1为在软件中注入了一个缺陷的情况,本文提出的定位技术和基于频谱的缺陷定位技术Tarantula定位效果都比较好,依函数执行顺序检查的方法Normal则需要检查较多的函数,定位效果较差。因为软件中只存在一个缺陷,本文方法在测试用例归类这一模块失去作用,其计算的可疑度值与Tarantula相近。
实验2为在同一子系统的不同模块注入2个缺陷的情况,本文的定位效果略优于Tarantula,Normal定位方法定位效果最差。由于不同模块存在缺陷,本文定位技术能够有效地根据失败测试用例在模块上的执行信息差异,初步判断出错的模块集合,缩小缺陷定位的范围,提高整体缺陷定位的效率。
实验3是在同一模块的2个函数中注入缺陷的情况,本文的定位效率略高于Tarantula和Normal。由于是在同一个模块内的2个函数存在缺陷,相互干扰,使得Tarantula可疑度计算方法在此情况下定位效果受到影响,本文采用的对数几率回归度量方法受到的影响相对较小。
实验4是在不同的子系统中注入2个缺陷的情况。该实验的效果与实验2相似,本文的测试用例归类模块的作用使得其定位效率高于Tarantula和Normal。
综上所述,本文提出的方法能够有效缩小缺陷定位的范围,提高缺陷函数的定位效率。
3 结束语
本文提出一种系统测试环境下的缺陷函数定位方法,通过分析失败测试用例在子系统和模块级别上的执行信息,对失败用例进行归类,缩小缺陷定位的范围;将对数几率回归的思想应用于软件缺陷定位中,计算出各个模块和函数与测试用例失败之间的关联度,并加入可靠性系数,有效度量了各个模块和函数的可疑值,提高了缺陷函数的定位效率。
笔者认为该方法还可以进一步研究:本文的实验对象规模不够大,需要在更为复杂的软件中进行有效性验证,同时,在模块和函数的可疑值度量阶段,若测试用例少会出现过拟合的现象,需要进一步完善。
猜你喜欢
安庆师范大学学报(自然科学版)(2021年1期)2021-11-28
科教导刊·电子版(2021年1期)2021-03-26
铁道通信信号(2020年6期)2020-09-21
黑龙江工业学院学报(综合版)(2020年6期)2020-08-11
南京大学学报(数学半年刊)(2020年1期)2020-03-19
吉林大学学报(理学版)(2018年4期)2018-07-19
科学家(2017年5期)2017-06-09
都市丽人(2015年4期)2015-03-20
浙江理工大学学报(自然科学版)(2015年7期)2015-03-01
火力与指挥控制(2015年2期)2015-01-08
