
基于云理论及熵权法的变压器潜在故障风险评估方法
2018-08-20 07:32熊卫红张宏志谢志成韩雄辉李正天林湘宁
电力自动化设备 2018年8期
熊卫红,张宏志,谢志成,韩雄辉,李正天,林湘宁
(1. 国家电网公司华中分部,湖北 武汉 430077;2. 华中科技大学 电气与电子工程学院 强电磁工程与新技术国家重点实验室,湖北 武汉 430074;3. 广东省电力公司梅州供电局,广东 梅州 514021)
0 引言
变压器作为电网枢纽设备之一,其正常运行是电力系统安全、可靠、优质、经济运行的重要保证。一旦变压器发生故障,将会导致系统供电中断,极大地影响工农业生产和人民的正常生活。另外,变压器的造价十分昂贵、结构复杂,若因故障而损坏,其检修难度大、时间长,将不可避免地导致严重的经济损失。因此,准确、可靠地发现变压器潜在的故障隐患,可以为及时制定合理的检修计划提供指导,避免变压器故障的发生,从而提高设备运行可靠性[1-2]。
针对变压器等电网枢纽设备的故障风险评估,国内外公认的有效方法有改良三比值法、Rogers法、Domerburg法等[3-4]。这些方法都是利用变压器油中溶解气体的比值进行编码,由编码结果查找对应的故障类型。然而,从实际应用来看,这些方法均存在“编码盲点”的问题。为此,国内外学者引入人工智能算法对故障样本进行学习,挖掘故障特征,进而形成知识库对变压器故障风险进行评估。常用的方法包括灰色理论、模糊理论、神经网络、Petri网、粗糙理论、支持向量机、Bayesian网络、证据理论等[5-11]。然而,由于设备状态数据(包括在线监测、带电检测、预防性试验数据等)具有体量大、类型繁多的特点,这些方法都存在一定的不足。
随着在线监测技术的日益成熟,变压器等充油设备状态量的监测也越来越精确,所得到的数据采集点也能覆盖设备的全寿命周期,数据种类、数据样本量是十分丰富和巨大的。近年来,如何从海量数据中挖掘有效的信息成为了热点问题之一,继而也出现了“大数据”的概念[12]。大数据分析技术通过寻找设备信息间的关联关系,为提高设备异常状态检测的准确性提供了全新的解决方法和思路。因此可以将大数据技术应用于设备故障风险评估中,充分挖掘状态数据的异常信息。国内外文献中在电网设备异常检测领域的大数据方法有时间序列分析、马尔可夫模型、遗传规划算法、分类算法、云理论等[13-16]。云理论是在对概率理论和模糊集合理论进行交叉渗透的基础上,通过特定的构造算子,形成定性概念与定量表示之间的转换模型。近年来,该方法已经在电力领域得到了较为广泛的应用,包括负荷预测、状态估计、故障诊断、调度决策等方面[17-18]。
目前,已经有学者采用云理论对电力变压器的绝缘状态和故障风险进行评估,文献[19]通过隶属云模型对变压器故障的模糊性与随机性进行了描述,结合温升及油中溶解气体含量数据,对设备的绝缘状态进行综合评价;文献[20]构建了基于云权重的电力变压器故障模式与影响分析(FMEA)评估流程,对电力变压器的重要度、故障发生度与可检测度等指标进了模糊化和随机化处理,提高了评估结果的准确性。
采用云理论进行风险评估时,需要获取大量的历史数据样本来确定不同故障情况下的概率分布云模型,然而工程实际中同一型号、相同容量设备的样本数据较少,现有方法中不同类型设备的样本又无法通用,上述情况导致该方法在应用时存在局限。为此,本文考虑提取油气特征量等风险评估通用特征量,将其与设备容量、型号、厂家等因素解耦,通过数据预处理,实现不同设备历史样本的共用,并构建通用的云理论模型,对现有方法进行了改进。
为了充分利用海量数据对变压器的潜在故障风险进行评估,本文提出了基于云理论及熵权法的变压器潜在故障风险评估方法。首先以变压器不同故障记录为训练样本,经过标幺化预处理,构建不同故障情况下所对应的概率分布云模型;通过熵权法确定各气体指标的权重系数,结合云分布隶属度系数,确定不同故障类型的隶属度系数;最后,通过算例比较该方法与改进的三比值法及已有云理论方法的评估效果,验证该方法的有效性及优越性。
1 基于云理论及熵权法的变压器故障风险模型
1.1 云理论指标
设U为由精确型数值构成的定量论域,C为论域U上的定性概念,对于论域U中任意元素x都存在一个具有稳定倾向的随机数u(x)∈[0,1]与之对应,称之为x对定性概念C的隶属度,该隶属度也称为隶属云,简称云。x在论域U上的分布形成隶属云C(x),而[x,u(x)]构成一个云滴。云是由许多云滴构成的,每一个云滴就是定性概念的定量化体现,它也表征了定性概念与定量化数值之间的不确定性映射关系。云模型的数字特征由期望Ex、熵En、超熵He这3个参数表征[18]。
a. 期望Ex。
期望是指云滴在论域空间分布的期望值,在该空间中最能够代表这个定性概念的坐标,可视为数域中所有云滴的重心。
(1)
其中,xk为训练样本值,在本文中表示预处理后的油中气体含量值;n为训练样本的个数。
b. 熵En。
熵是定性概念的不确定性度量,反映了数域中可以被语言值接受的模糊度和这些点所能代表的语言值的概率,它由事物的模糊性和随机性共同决定。
(2)
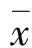
c. 超熵He。
超熵是熵的熵,它反映了云滴的凝聚程度以及每个数值代表这个语言值确定度的凝聚程度,是由熵的模糊性和随机性共同决定的。
(3)
由以上3个指标将数据的随机性和模糊性进行关联。
1.2 云发生器
确定了云的3个指标后,利用云发生器即可生成相应的云模型。云的生产方法称为云发生器,云发生器有正向云发生器、X条件云发生器(CGA)、Y条件云发生器(CGB)3种。正向云发生器是基于云的3个指标产生云滴的算法;X条件云发生器是基于给定云的指标(ExA,EnA,He)以及数值x0而生成云滴Cdrop(x0,μ1)的算法,如图1所示;Y条件云发生器是基于给定云的指标(ExB,EnB,He)以及确定度值μ1而生成云滴Cdrop(y0,μ1)的算法。
X条件云发生器生成的云滴位于一条竖线上,而Y条件云发生器生成的云滴位于一条水平线上。利用云模型构建不确定性推理机需要X条件云发生器和Y条件云发生器组合而成,如图1所示。

图1 基于云模型的不确定性推理机示意图Fig.1 Schematic diagram of uncertainty reasoning machine based on cloud model
利用云理论可以将所收集的油中溶解气体定量化数据转换为由3个云指标所描述的定性云概念。对于绝大多数人工智能方法而言,在建立相应模型之前,均需要对原始生数据(raw data)进行预处理,以便于模型预期效果的实现。文献[17]以所有样本中某一种数据的最大值作为归一化的基准值,对样本数据进行归一化处理。这样的方法也可以实现对不同设备数据的共享利用,但是当最大值所对应的数据样本为伪数据时,将会导致对应气体的归一化结果错误,继而影响云模型的准确性。因此,本文将归一化基准值修改为对应数据样本的所有气体值之和,即:
(4)
其中,ci为第i种气体归一化之前的值;Gi为第i种气体归一化之后的值;M为故障记录数据中气体的种类,本文所收集的气体数据有5种,即氢气(H2)、甲烷(CH4)、乙烷(C2H6)、乙炔(C2H2)、乙烯(C2H4),因此M=5。采用上述处理方法后,即使训练数据样本中出现伪数据,也可以将其对数据预处理结果的不良影响降至最低。
变压器部分故障情况记录数据经过预处理前、后的结果分别如表1、表2所示(表2中数据为标幺值)。
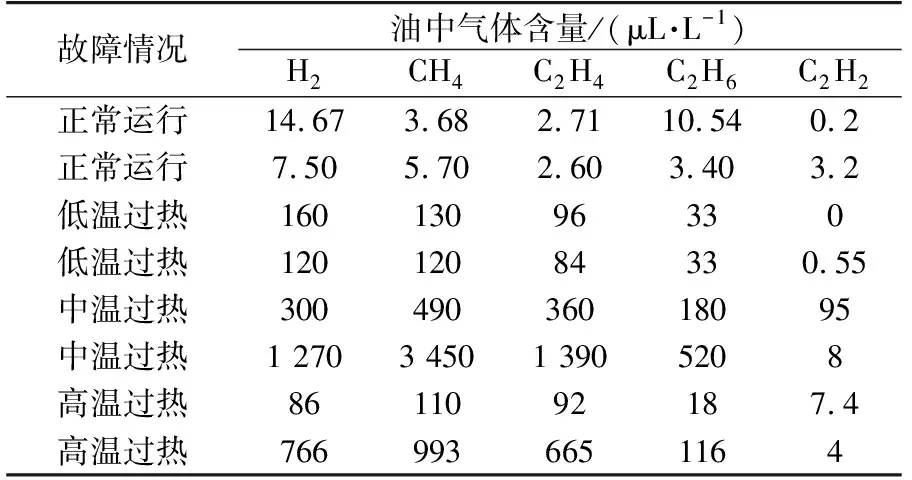
表1 预处理前部分故障记录数据Table 1 Recorded data of part faults before pretreatment

表2 预处理后部分故障记录数据Table 2 Recorded data of part faults after pretreatment
由表1、表2对比可知,对数据进行预处理之后,相同故障情况下气体含量的值相差不大,较好地展现了故障的特性。对于人工智能算法而言,数据是否经过预处理将在很大程度上影响故障诊断的准确度,数据经预处理前、后云模型的对比情况如图2所示(以低温过热故障数据为例)。
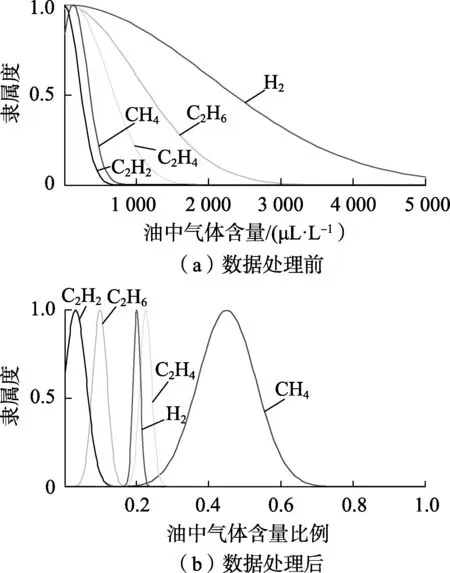
图2 数据预处理前、后特征气体云模型Fig.2 Cloud model of characteristic gas before and after data pretreatment
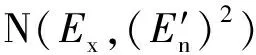
(5)
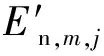
1.3 熵权法确定气体指标权重
熵权法[21]可以综合各评估指标的重要性和指标提供的信息量这两方面因素,更客观地确定各指标的最终权重。某个评估指标的信息熵越小,表示该指标的变异程度越大、所提供的信息量越多,即在整个评估过程中起到的作用越大,其权重也越大;反之越小。
根据式(5)可以计算得到待诊断样本对已有故障情况中不同气体云模型的隶属度,但还需要对评估指标(本文中评估指标为5种气体)进行权重系数的计算,继而推导得到对应不同故障情况的综合隶属度。
评价指标j的重要性熵值定义为:
(6)
(7)
(8)
k=1/lnMf
(9)
其中,Mf为故障情况数目(本文取7);N为评价指标的数目(本文取5);Nij为各评价指标参数值之间的接近程度,通过专家经验进行确定。
由于信息熵e(dj)可用来衡量评价指标j信息的有用程度,信息熵越小则评价指标j的有效程度越高,所以评价指标j的信息效用价值系数定义为:
hj=1-e(dj)
(10)
利用熵值法计算各评价指标的客观权重,实质上是利用该评价指标信息的效用价值系数计算得到,效用价值系数越高,该指标对评价的重要性就越大,于是得到评价指标j的权重值wj为:
(11)
本文采用上述的熵权法确定了评价指标的权重值W,如表3所示。
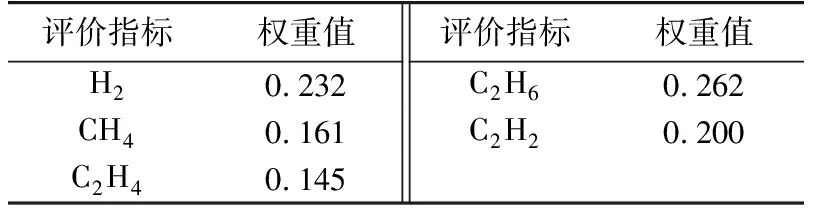
表3 评价指标权重值Table 3 Weight values of evaluation indicators
最后结合式(5)计算所得待测样本对不同故障情况下不同气体的隶属度及表3所示的评价指标权重值,即可得到待测样本对应不同故障情况的隶属度:
Um=μmW
(12)
其中,μm为待测样本对故障情况m中不同气体的隶属度组成的向量。
由式(12)可计算得到待测样本对应正常运行状态的隶属度U1、低温过热的隶属度U2、中温过热的隶属度U3、高温过热的隶属度U4、局部放电的隶属度U5、低能放电的隶属度U6及高能放电的隶属度U7。为了使得评估结果便于理解,本文定义异常系数α用以表征设备(即待测样本数据来源)处于异常状态的程度,如式(13)所示。
α=1-U1
(13)
最终评价结果的确定方法如式(14)所示。
(14)
利用上述模型就可以确定变压器潜在故障的性质。此外,随着训练数据样本的更新,不同故障情况所对应的标准云也可以进行动态更新。
2 实例分析
本文通过现场调研以及国内外相关研究文档收集得到了3 000余组不同故障情况的数据,选择2 000余组不同故障情况记录进行整理,作为训练样本,另外剩余1 300组样本进行验证。根据式(1)—(3)计算得到不同故障情况的改进云模型指标(Ex,En,He)的标幺值,如表4 — 6所示。
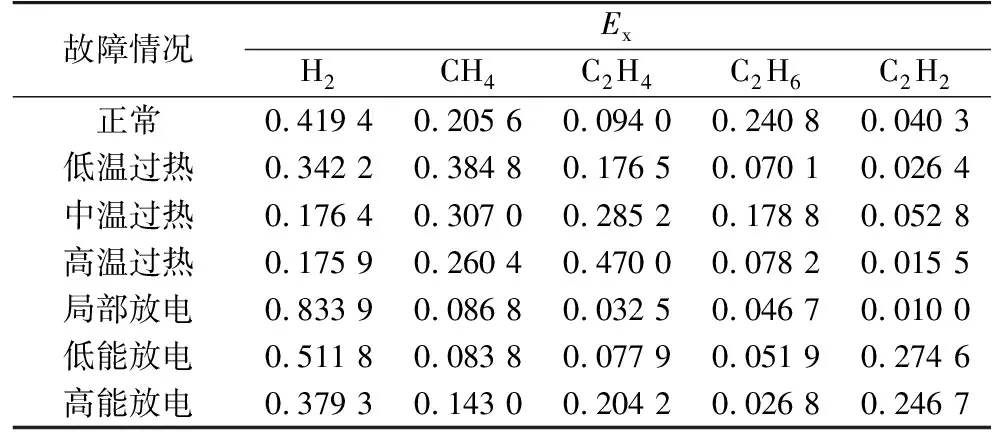
表4 改进云模型的期望Table 4 Ex of improved cloud model
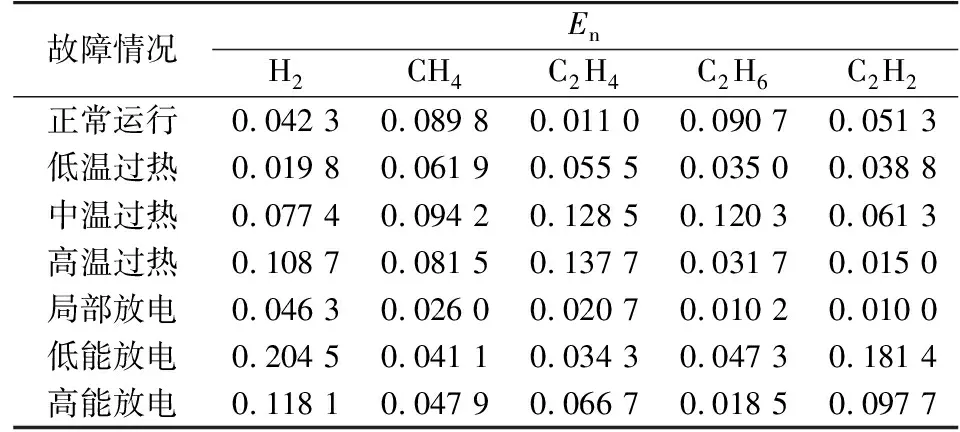
表5 改进云模型的熵Table 5 En of improved cloud model

表6 改进云模型的超熵Table 6 He of improved cloud model
根据表4— 6所得到的数据,建立不同故障情况的特征气体云模型,如图3—9所示。
由图3— 9可知,每种故障情况都有相对应的特征气体云模型,不同故障情况下气体含量有比较明显的差异,这也是区分不同故障情况的关键所在。
采用另外的1 300组数据作为测试样本,分别采用本文所提方法、已有云理论方法及改良三比值法进行故障风险评估,对比结果如表7所示。由表7的对比结果可知,本文所提基于云理论及熵权法的变压器故障风险评估方法在不同故障情况的判别上均优于改良三比值法及已有云理论方法,总体的准确判断率也更高。为了直观地阐述本文所提方法对数据的自学习能力,在不同训练样本数目下将3种方法的准确判断率进行了对比,如图10所示。
由图10中的对比结果可知,从50组样本逐次递增到1 000组样本时,改良三比值法的准确判断率保持稳定,维持在85%左右;已有云理论方法的准确判断率从85%上升到90.5%,700组样本之后,其准确判断率稳定在90%附近;本文方法的准确判断率从86%上升到92.5%,500组样本之后,其准确判断率稳定在92%附近。由此可知,改良三比值法对数据无学习能力,而已有云理论方法及本文方法均对数据有很强的学习能力。
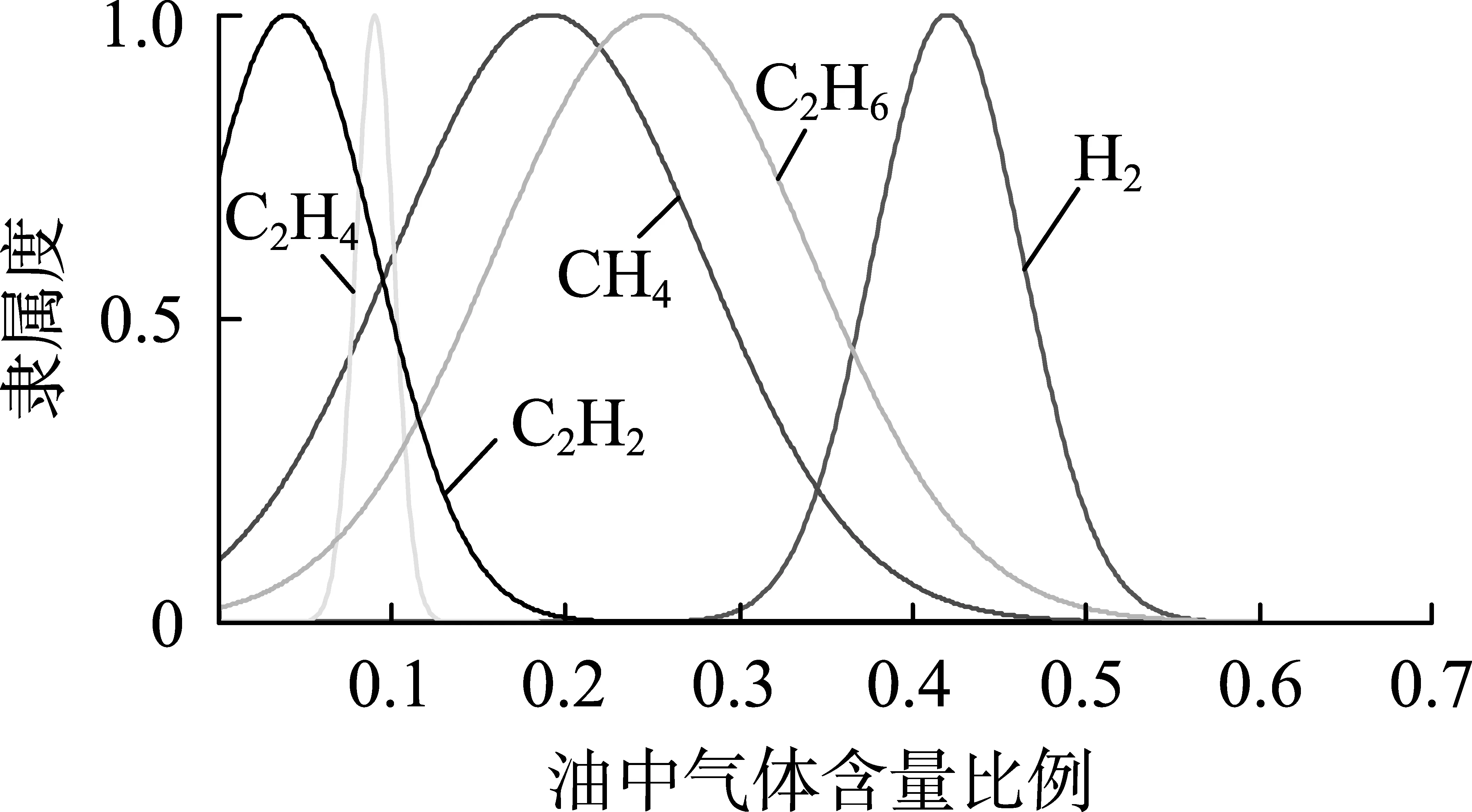
图3 正常运行状态下特征气体云模型Fig.3 Cloud model of characteristic gas in normal operation state

图4 低温过热状态下特征气体云模型Fig.4 Cloud model of characteristic gas under low-temperature superheated state
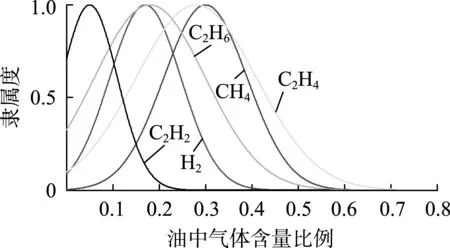
图5 中温过热状态下特征气体云模型Fig.5 Cloud model of characteristic gas under middle-temperature superheated state
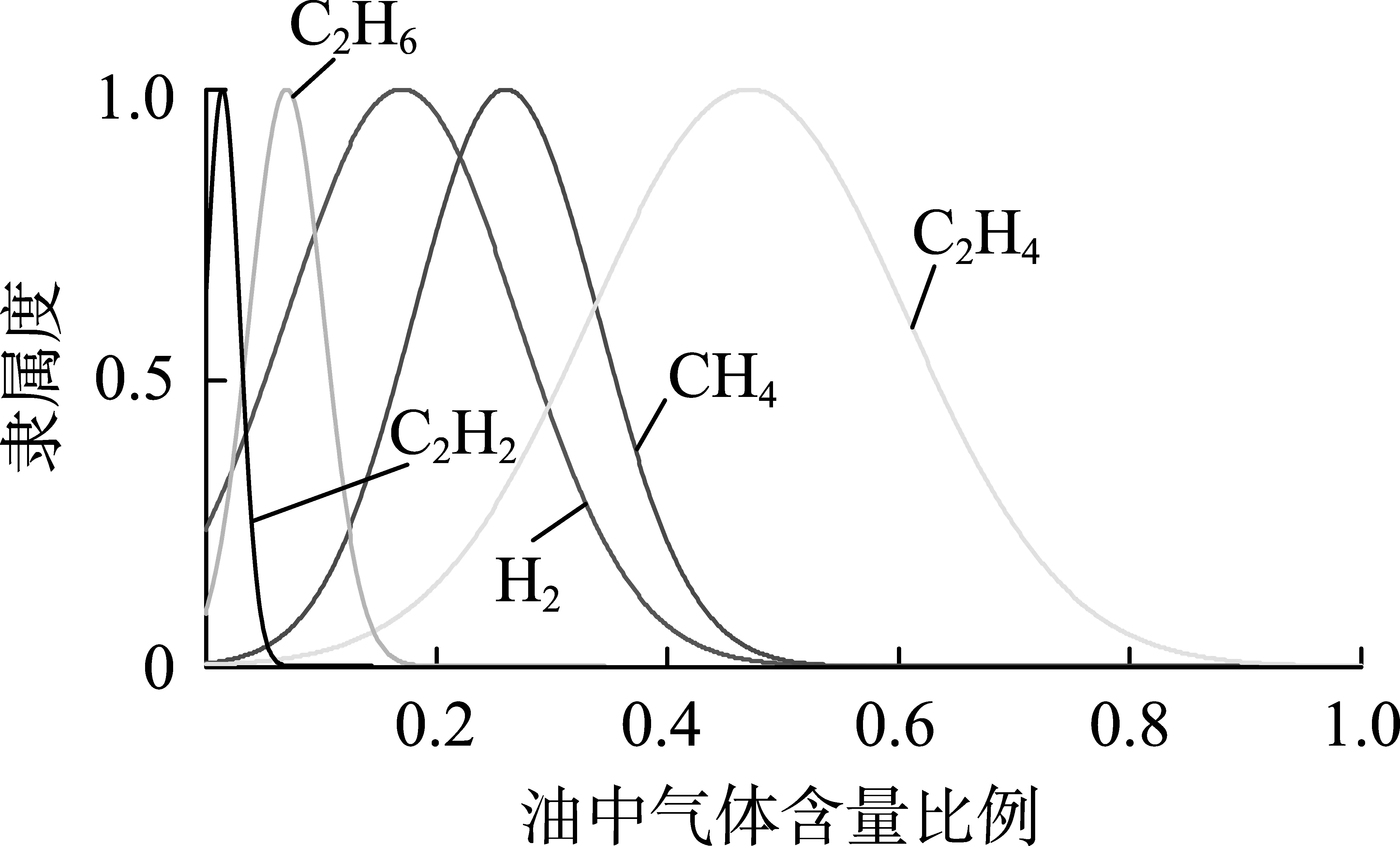
图6 高温过热状态下特征气体云模型Fig.6 Cloud model of characteristic gas under high-temperature superheated state
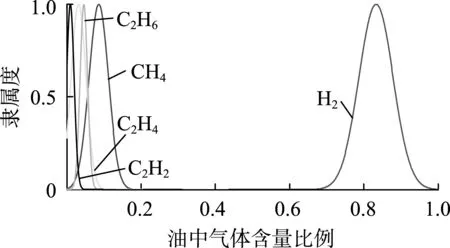
图7 局部放电状态下特征气体云模型Fig.7 Cloud model of characteristic gas under partial discharge state

图8 低能放电状态下特征气体云模型Fig.8 Cloud model of characteristic gas under low-energy discharge state

图9 高能放电状态下特征气体云模型Fig.9 Cloud model of characteristic gas under high-energy discharge state
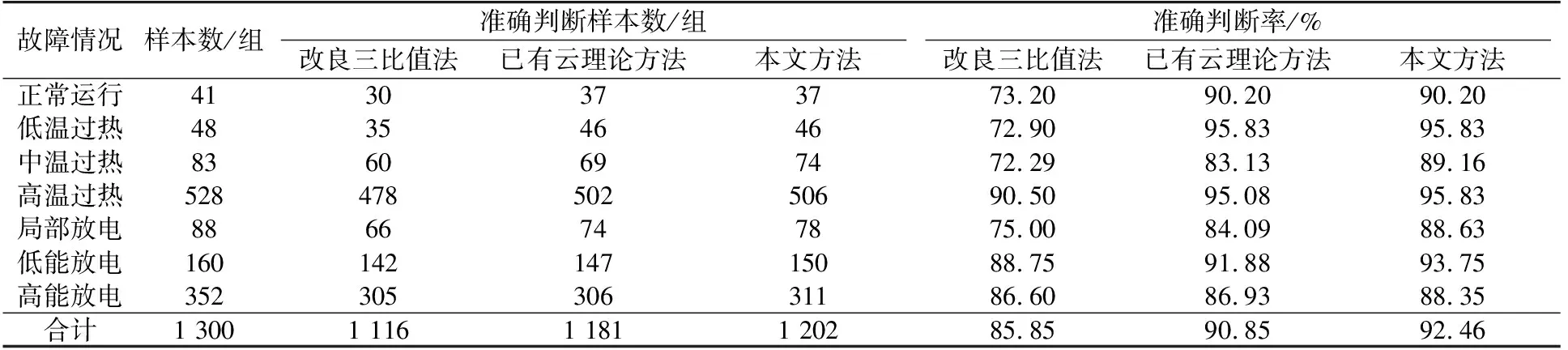
故障情况样本数/组准确判断样本数/组准确判断率/%改良三比值法已有云理论方法本文方法改良三比值法已有云理论方法本文方法正常运行4130373773.2090.2090.20低温过热4835464672.9095.8395.83中温过热8360697472.2983.1389.16高温过热52847850250690.5095.0895.83局部放电8866747875.0084.0988.63低能放电16014214715088.7591.8893.75高能放电35230530631186.6086.9388.35合计1 3001 1161 1811 20285.8590.8592.46
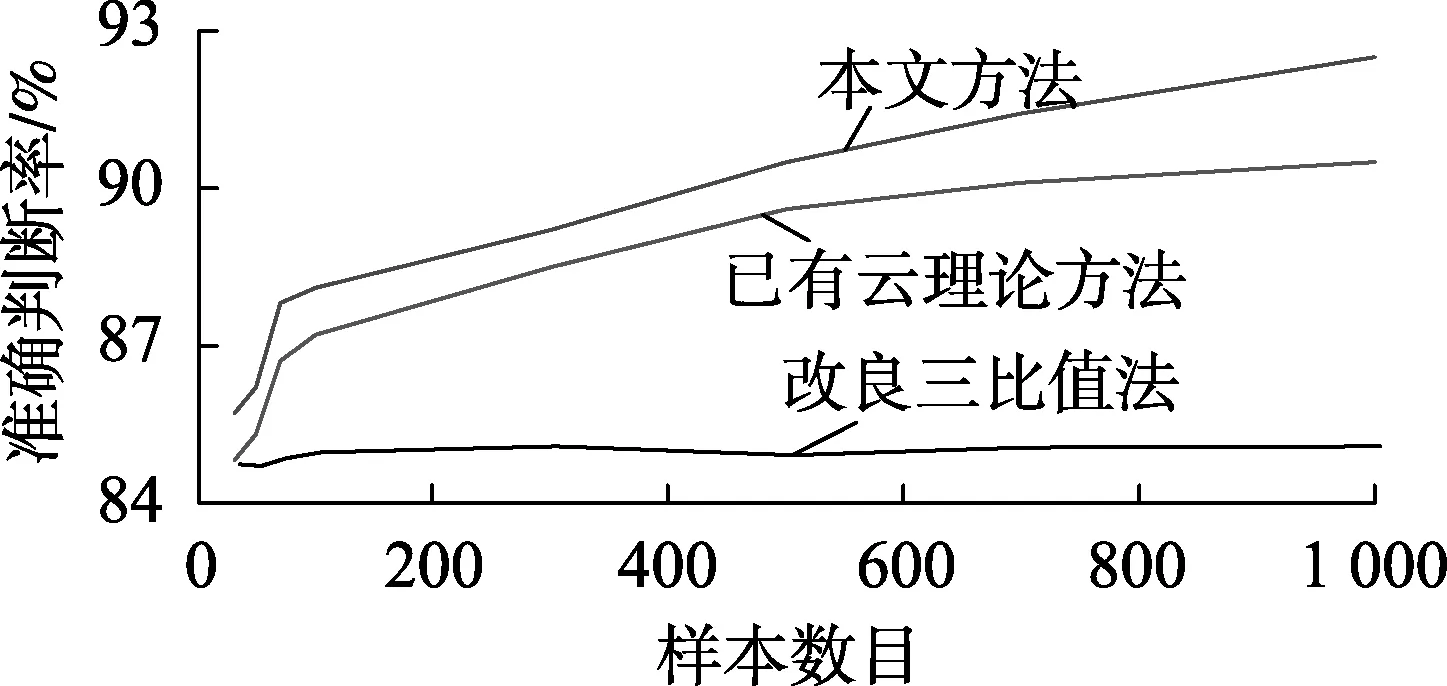
图10 不同数据样本数下3种方法准确判断率对比Fig.10 Comparison of accuracy rates among three methods with different data sample sizes
同时与已有云理论方法相比,本文方法的准确判断率上升趋势更快且提高了2%。准确判断率的提高将使得更多的具备故障隐患的设备得到及时的检修处理,避免变压器潜在故障在检修时被漏检。
3 结论
本文以不同变压器故障情况记录为训练样本,经过标幺化预处理,构建了不同故障情况所对应的概率分布云模型。并引入熵权法确定各气体指标的权重系数,结合云分布隶属度系数,确定不同故障情况的隶属度系数,即为最终的评估结果。通过与改进三比值法及已有云理论方法的对比,证明了该方法的有效性及优越性,研究结果能够为制定设备检修方案提供参考。
猜你喜欢
中学生数理化·高一版(2021年2期)2021-03-19
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
知识经济·中国直销(2018年8期)2018-08-23
通信电源技术(2018年3期)2018-06-26
制导与引信(2017年3期)2017-11-02
数学学习与研究(2017年3期)2017-03-09
现代工业经济和信息化(2016年4期)2016-05-17
工业设计(2016年11期)2016-04-16
通信电源技术(2016年3期)2016-03-26
中国老区建设(2016年1期)2016-02-28
