
深度学习下智能写稿辅助服务的设计与实践
2018-08-21 03:56任海平
传媒论坛 2018年4期
任海平
(浙江日报报业集团产品研发中心,浙江 杭州 310039)
一、引言
随着媒体大数据时代的到来,媒体用户获取信息的渠道变得越来越丰富,也越来越便利,而日益快速增长的新闻资源不仅给新闻出版行业发展带来巨大的机遇,更带来了前所未有的挑战。这些挑战是多层次、多方面的,本文聚焦其中的技术挑战——如何高效利用海量新闻资源提升新闻制作水平,立足浙报集团媒体出版特色,利用深度学习的模型设计并实现智能写稿辅助服务平台。
要实现高质量的智能写稿辅助功能,关键技术难点是如何快速有效地从海量新闻文本中把与当前撰写稿件相关的新闻资料汇聚起来,形成有价值的创作素材。由于这种汇聚要求在语义上是高度相关的,因此简单利用关键词搜索不仅费时费力,也无法取得汇聚的良好效果。利用机器学习的方法,实现新闻文本资源的自动聚类是一个较好的解决方案。传统面向文本聚类的机器学习方法主要包括:基于决策树、基于概率图模型和基于向量空间等各类方法。然而,这些方法都属于浅层模型,无法利用不断增长的文本数据来提高聚类效果,甚至会下降。因此,本文采用深度学习的模型,实现新闻文本资源的高质量聚类。具体而言,我们利用深度学习模型对文本进行层层特征提取并降维,最终获得较为精练的文本特征代码,使得在语义上相关度较高的文本代码,在语义空间中的距离也是相近的,从而实现相关资料的汇聚。
在内容创作过程中,利用训练好的深度模型,系统可以动态提取当前稿件内容(甚至只是一个标题),生成语义代码,并快速从海量媒资库中捕捉到与当前最为相关的文本素材,第一时间推送至写稿平台,供内容创作者参考使用,这便是本文阐述的智能写稿辅助服务。由此项技术衍生出“主题延展”“稿件背景”“自动摘要”甚至机器写作等场景应用,让内容创作者真正享受到人工智能时代的红利。
二、基于深度学习的文本聚类模型
写稿的智能内容辅助的关键技术难点在于如何根据写稿人当前录入的部分内容,在语义空间中生成相应的语义代码(向量),并快速在媒质库中获取和该语义代码距离最为接近的相关文本资料。因此,这在机器学习领域中是一个典型的文本聚类问题,即利用高效的算法实现针对在人看来语义相近的文本在虚拟语义空间中也是距离相近的。
为此首先我们要对文本进行建模,目前最为常用的建模方式是“文档-词”矩阵(简称“D-T”矩阵):A=(aik),其中aik是矩阵中的元素,目前大多采用TF-IDF权重法。在此基础上,本文利用深度学习模型从“D-T”矩阵中生成高质量的语义特征代码,利用这种代码,可以高效地获得和写稿内容相关文本资料。在阐述新方法之前,我们首先回顾一下传统文本聚类的主要方法。
(一)传统文本聚类的主要方法
为实现有效的文本聚类,机器学习领域已经做了长期的探索,并取得长足进展。从技术实现路线划分,传统文本聚类算法大致分为以下三种:
1.基于决策树的模型
决策树(Decision Tree)是一种利用树状结构来描述一个决定和其产生结果的模型,并且在树的结构中,赋予每个结果一定的可能性。其中主要典型算法包括:ID5、C4.5、QUEST、PUBLIC等。决策树的优势在于逻辑和规则的可解释性,对于非大量的强数据集,结合领域专家的经验,决策树可以取得较好的效果。
2.基于概率图的模型
概率图模型是文本挖掘中应用最为广泛的一种模型,它的基本假设是不同的文本拥有不同词的联合概率分布,换句话说,不同词的概率组合将产生不同类型的文本,其中典型模型包括:朴素贝叶斯分类器(Naïve Bayes Classifier),pLSA(Probabilistic Latent Semantic Analysis)和LDA(Latent Dirichlet Allocation)等。该类算法模型,能够发展各种更加复杂的模型,并在新闻文本语义分析中做出很大的贡献。
3.基于向量空间的模型
基于向量空间的模型立足“D-T”矩阵,每一行代表一个文档,它在向量空间中为一个向量,每一个分量代表词的权重。该类模型通过各种向量空间的变换来估算两篇文本的相似度,其中典型模型包括:支持向量机(Support Vector Machine,SVM)、k个最邻近(k-Nearest Neighbor,kNN)算法和支持向量聚类(Support Vector Clustering,SVC)模型等。
这三类算法模型均属于浅层模型,其主要局限性体现在,它们无法充分利用不断增长的文本大数据来提升其性能(甚至会下降),同时无法实现多层次隐含语义的高效分析。因此,本文采用深度学习的方法实现高效语义代码的提取并聚类。
(二)基于深度学习的文本聚类模型
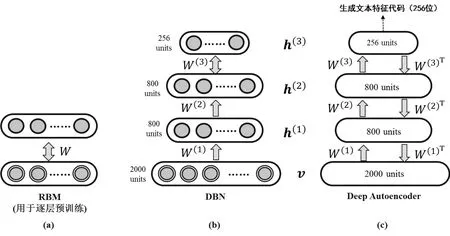
图1
为充分利用媒资库中海量的新闻文本数据,提升聚类的效果,本文采用了深度学习模型,生成蕴含有效语义的文本代码的基础上,实现高质量文本聚类。目前深度学习比较主流的模型有CNNs(Convolutional Neural Networks)、DGMs(Deep Generative Models) 和 RNNs(Recurrent Neural Networks)。由于文本聚类是非监督学习,因此我们采用属于DGMs中DBNs(Deep Belief Networks, DBNs),如图1(b)所示。
图1是基于DBN的文本聚类模型示意图,(a)是RBM,用于逐层预训练;(b)是DBN,为本文主模型[2000,800, 800, 256];(c)是在DBN精调过程中,展开的Deep Autoencoder。
DBNs是一种混合多层概率图模型,它可以利用RBMs(Restricted Boltzmann Machines)实现层层预训练(pre-training)来获得多层次特征的提取。而RBM是一种基于能量的模型,预训练的详细过程可详见Hinton的成果。
要提取文本的语义特征,并生成代码,首先要利用首层RBM对文本进行采样和建模。首先,我们利用传统方法获得文本“D-T”矩阵。由于每篇文本的长度不同,因此我们采用的方式是复制Softmax模型进行首层采样和预训练,具体采样公式如下:

公式(1)(2)
其中vik,为第i篇文本的第k个分量,h(1)为第1隐藏层,{W(1),a(1),b(1),}为第1层RBM的参数,g(x)=1/(1+exp(-x))为Logistic函数。在此基础上,利用多层RBM分别对{h(1),h(2),h(3),}进行训练,并在h(3)上获得文本的特征代码。此时的特征代码还不是最优化的,需要将DBN展开成为一个称之为Deep Autoencoder的深度编码器,并利用反向传播(Backprogation)机制,获得最优化的代码,如图1(c)所示。这里反向出传播的目标函数选择交叉熵的偏差(cross-entropy error)函数:

公式(3)
其中,vi(input)为第篇文本,vi(output)为第i篇文本通过层层采样后的输出,M为文本的数目。
深度编码器对DBN的参数做进一步优化之后,我们可以在深度模型的顶层h(3)获得文本较高质量的特征代码,我们将该特征代码存入媒资库的每篇文稿的记录中,并在智能写稿辅助服务中,用于语义相关性的聚类和搜索。
三、智能写稿辅助服务的设计
在确立了上述理论和技术模型后,接下来就是如何将其应用于媒体内容采编环节,赋予更多的智能。为此,我们选择了智能写稿辅助服务作为切入点。在传统的写稿功能设计中往往只实现了一些常规性功能,如:发稿单栏设置、内容编辑、文字修饰、字行统计、文章关联、检索等,这些功能只对成文方面提供了一定帮助。随着媒体对内容创作的数量、质量、效率以及非同质化要求越来越高,这些传统功能早已无法满足新的需求。创作者们渴望通过新技术手段来提升内容策划、内容组织、背景资料查找以及关联信息挖掘能力,为内容“编码”,实现知识增量,快速形成精品原创。
(一)数据源采集
要形成有效的智能写稿辅助服务,首先要构建一套海量的、存放高质量语义特征代码的媒资库,这也是内容基础。目前能为媒体所用的数据源非常广泛,就以浙报集团“媒立方”项目而言,数据的采集分为了资源圈与分析圈,覆盖了新闻、资讯、交互性内容范畴,包括但不局限于集团采编资源、历史媒资数据、全网重点新闻(如:媒体网站、政府门户、微博、微信、论坛、新闻爆料、数字报、APP)以及民众互动数据等,如图2。
(二)数据源处理
接下来就是对这些采集数据的清洗处理,包括脱敏(保留隐私性)、清理(保留有效数据)、加标签(分类)等前序工作,形成初始数据源(图2-[S1])。若计算资源充足,还可对初始数据源按信息阶段(信息发现、信息跟踪、信息挖掘、信息推荐、信息评估)和信息性质(速度、广度、准度、深度、流行度)两大需求方向进行二次结构化预处理,形成初始数据源(图2-[S2])。最后,利用深度学习模型,将预处理结果数据进行特征代码计算、提取、存储,形成真正可利用的优质信息,供智能写稿服务使用。
(三)功能应用
根据实际应用需要,我们设计了两类智能写稿辅助服务:主题延展和背景资料,并在浙报集团“媒立方”项目的融合写稿编辑器中应用,并取得了非常好的效果。
1.主题延展的实现与效果
主题延展可动态获取当前稿件相似主题、相似内容在其他媒体的报道文章。对于该场景设计,需要将智能辅助服务挂钩内容编辑的全过程,随着创作内容篇幅的越来越长,其文章主题也逐渐清晰,当完成整段内容输入,系统即可触发机器深度学习算法服务,对当前已输入内容进行分析并抽取语义特征代码。与此同时,该服务与后台媒资库海量语义特征码进行匹配,当超过预设的匹配值后,系统便可获取相似度最高的文章推送至用户端。
对于相似主题文章的展示,我们在设计上应包括:标题、摘要、来源、发布时间,具体控制如表1所示。

表1 各要素设计说明
在“媒立方”项目融合编辑器设计中,我们为编辑器的右侧栏专门设计了智能辅助页签栏,可别小看这几个页签,已经成为记者编辑在内容采编过程中不可或缺的助手。一旦创作者开始内容写作,“主题延展”服务便根据编辑器中的内容进行智能分析,并实时地将匹配到的信息推送至编辑窗右侧页签内,设计界面如图3:

图3:主题延展界面展示
(1)查阅结果:“主题延展”结果内容以瀑布流式显示,并分布在稿件编辑器右侧,用户点击任意一篇内容即可打开查阅原文。对于长标题,只需将鼠标放置标题位置,便会弹出浮动信息窗,完整显示标题内容。当结果文章数过多并超出本页,可单点击“展开更多”进行全量查阅。

图2:数据源采集与处理框架
(2)内容选取:内容选用方式在设计上要突出方便、快速,因此在本设计中,我们约定了鼠标拖拽方式,通过鼠标拖动即可将所选文章内容、图片、音视频,插入至编辑器正文光标位置。
(3)主题延展内容更新:每次触发“主题延展”功能,均会对当前正文内容进行一次深度学习,并同步更新“主题延展”结果内容清单。内容更新的触发机制有很多种,可以在内容增删改查时触发,亦可在换行、换段以及保存时触发,为了最大程度避免影响写作体验,同时又能达到主题延展效果,最终我们选定了“回车换行”作为主要触发机制。
2.稿件背景的实现与效果
“稿件背景”是从当前稿件内容中抽取人名、地名、机构名等关键词,加以解释,或列举这些关键词在历史重要媒体报道中的描述,为内容创作者提供稿件背景资料。同理,在该场景设计中,用户在内容创作到达一定篇幅后,系统会根据已输入内容触发机器深度学习服务,确立人名、地名、机构名等关键词以及语义特征代码,并与媒资库海量语义特征码进行匹配,获取相似度最高的文章推送给用户端,为内容创作者提供文章相关的高价值信息。对于稿件背景结果的展示,在设计上包括:标题、摘要、来源、发布时间,展示控制与“主题延展”相同。但不同的是,稿件背景的核心匹配目标是文章关键词,如:人名、地名、机构名以及其他关键词,通过不同组合的关键词选择,将会产生不同的背景资料呈现结果。
在“媒立方”项目融合编辑器设计中,我们同样为编辑器的右侧栏专门设计了“稿件背景”智能辅助页签。在内容创作过程中,系统会自动从当前稿件中抽取人名、地名、机构名等关键词,并列举这些关键词在各类媒体报道中的详细描述,为内容创作者提供文章相关背景信息。例如:一篇稿件中引用了某一句诗歌、典故,通过背景资料就可以快速定位到这句诗歌、典故的完整原创内容。设计界面如下:

图4:稿件背景界面展示
“稿件背景”以瀑布流方式显示关键词所定位的原文内容,用户可在稿件编辑器右侧“稿件背景”栏点击查阅。各类关键词间以“and”搜索关系约束,且同一类关键词约束为单选,不同类关键词允许多选。内容选用方式、内容更新与“主题延展”功能设计一致。
四、结束语
本文详细阐述了基于深度学习的智能写稿辅助服务的关键技术和设计方案,其出发点是让机器(服务器计算资源)充分进入内容信息源领域,帮助我们完成第一道最费时费力的数据收集和结构化处理工作,让海量的内容资源库成为真正有价值的知识库。当然对算法模型的优化与实践还需要一个过程,可以预见,在不久的将来,通过人工智能深度学习,必然会带来包含内容生产要素在内的衍生变化,甚至引发传统信息流生产方式的颠覆。
猜你喜欢
开放教育研究(2020年2期)2020-03-31
铁道通信信号(2019年6期)2019-10-08
动漫星空(2018年11期)2018-10-26
动漫星空(2018年2期)2018-10-26
动漫星空(2018年9期)2018-10-26
动漫星空(2018年5期)2018-10-26
雷达学报(2017年6期)2017-03-26
现代语文(2016年21期)2016-05-25
互联网天地(2016年1期)2016-05-04
电子设计工程(2015年6期)2015-02-27
