
基于USDR模型的云推荐方法研究
2018-08-24 07:51,,,
计算机测量与控制 2018年8期
,,,
(浙江工业大学 计算机科学与技术学院,杭州 310023)
0 引言
Web在科技的进步和信息的更新交替中进入了“2.0时代”,同时由于各种信息更新速度的加快,互联网的数据资源也同步进入了大数据云时代,在某种程度上,网络垃圾和无效资源也越来越多,当普通用户想要寻找某种有用的资源时,如何在海量数据中筛选出特定的资源变成一个急需解决的问题。
搜索引擎作为人们获取信息的渠道和关键,始终是各大互联网公司的一个争夺的热点。当人们坐下来,打开电脑,面对庞大的互联网世界时,第一件事情往往就是打开搜索引擎,输入关键字,从而以最快的速度找到自己想要的信息。但是同样存在明显的缺陷,即对用户的文化水平有一定程度的门槛,有一部分人不知道如何联想到并精确的概括自己的目标信息,从而错过很多实时信息;还有一些用户并没有绝对明确的目标,只是想浏览一些自己感兴趣的话题,并不想要通过某些关键字使得信息狭隘化,因为有些关键字之间的共同信息领域很小;还有一些用户对感兴趣的话题并不能用几个关键字去概括,因而无法定位到自己想要的数据资料。然而对数据信息的制造者而言,由于现在互联网的竞争非常激烈,希望自己的信息被关注被采纳、用户量节节攀升也不是一件容易的事情。在这种情况背景下,数据推荐应需而生。对于用户而言,数据推荐系统可通过云计算,在使用界面里主动跳出或许对用户有价值的信息,从而使用户达到自己的目的,得到更好地使用体验;而对于制造者,数据推荐可以在一定程度上合理地把信息推销给潜在用户,从而增加自己的点击量,这对于双方而言是一个共赢的局面。
现如今,数据推荐引擎适用范围非常广泛,尤其值得关注的就是近几年发展迅猛的电子商务平台,以淘宝为例:当使用者搜索过某类商品以后,它就会储存这个点击数据同时进行某种用户偏好的计算统计,结合商家的综合排位和对淘宝平台的广告买位,在使用者平台上进行个人化的反馈,使用者就会很容易的注意到自己感兴趣的信息,同时商家获取更多的点击量和利润,淘宝自身也获得巨额利润,这是一个“三赢”的结果。再如分享交互类的社交平台,以新浪微博为例,建立推荐的机制,向用户推荐好友的搜索热点和关注人分享的内容,使得每一个使用者的界面都是独特的个人化的,而且这都是使用者一手操办,所以这些信息对于使用者而言是感兴趣的有价值的。同时被关注者也可以利用这种关注量和影响力获得经济利益,平台作为秩序的维持者和信息资料的拥有者也可以获得巨大的利益。就目前而言,信息推荐系统在各大领域都产生了良好的效果和不可或缺的作用,用户也逐渐习惯和信赖信息推荐系统,可以说这是一个成功的机制。
1 相关工作
国内外学者和研究机构从不同的视角对多源异构数据和推荐方法进行了研究。
从RSS推荐技术方向出发的代表性工作主要有:Hao Han等人[1]在RSS推送的基础上构造网络新闻文章内容自动提取系统,可以从新闻网页中提取对用户有价值的文章内容;陈锋等人[6]对信息服务资源进行聚合需求分析,提出了一种基于RSS推送技术的信息服务内容聚合服务方式。
其次,协同过滤推送是目前主要使用的推送方式之一,协同过滤推送不仅可以实现信息的推送,而且可以根据用户的兴趣实现个性化推送。目前对协同过滤推送技术研究中具有代表性的有:郭艳红等人[7]提出了一种基于稀疏矩阵的个性化改进策略,能够避免用户之间相似度不密切的关系,提高了矩阵在稀疏情况的预测准确度。李聪、梁昌勇等人[8]提出了基于领域最邻近的协同过滤推荐算法,使数据的稀疏性得到了降低,提高了推荐准确性。
从数据传输方向出发的代表性工作主要是Menglan Hu等人[2]设计了一种分阶段获取云端分享数据的算法,能够有效地控制数据的传输成本。国内的许富龙、刘明等人[9]进一步提出了一种基于相对距离感知的动态数据传输策略,采用传感器节点到汇聚点的相对距离来计算节点传输概率的大小,并以此作为消息传输时选择下一跳的依据。
在利用推送技术实现系统的研究中,中国科学院软件研究所的刘鑫、陈伟[10]提出了一种基于AJAX和Server Push的web树组件,为用户提供了类似于在windows资源管理器中对目录树操作的基本功能和用户体验。
但以上方法均只是通过修改推送方式而实现对单一数据源进行推荐,并没有过多考虑多源异构数据的个性化推荐问题,也没能实现云推荐。本文提出的USDR模型面向多源异构数据,通过将用户数据和系统数据分类来快速得到用户和系统的不同推荐度,以实现数据的高效推荐。
2 USDR模型概念
在数据物流云推送平台中,各类云数据数量庞大,种类繁多,根据系统服务种类大致可以分为成绩查询服务、工资数据服务、排队服务、交通数据服务、购物信息服务、股票期货服务、多媒体数据推送服务等。
由于是基于云推送的数据物流服务平台,平台中许多系统会提供类似的服务,比如3种股票软件都通过本平台为客户提供金融数据推送,但是其中一款股票软件是收费软件,数据推送响应时间更快、推送的服务更多,但价格也是同类股票软件中最高的。除了相同类型的服务中出现的情况,用户数据信息之间也存在不同,用户将会根据自己的基础信息选择不同的服务。比如交通数据服务中,有些用户可能上班时间比较自由,那么他们可以选择上下班高峰期过后的道路数据推送服务,而有些用户需要准时到达单位,那么推送给他们当时的路况数据,可以使他们选择在上下班高峰期避开一些拥堵路段;同样,购物信息服务中,经济条件好的用户可能比较偏好奢侈品,而经济条件一般的用户则偏好于普通实用的商品,所以在推送数据时就会有一定的差异性,需要建立用户和系统的关系数据模型。
当用户请求获取一种类型的服务时,数据物流服务平台应该自动根据现平台中相同类型的系统和用户自身的数据,推送给用户最合适的服务,这样就既能满足用户的功能性需求,同时也满足了用户的个性化需求。
用户数据主要可以分为用户基础数据、时间数据、地点数据、用户偏好数据、历史数据等。
系统数据主要可以分为服务类型数据(如成绩查询服务、金融股票服务等)、服务介绍以及这些服务的范围(价格、位置)。这些系统中的数据结构多样,类型复杂,并且有些数据是动态变化的。为了能够有效的处理这些云数据,本文提出了USDR模型。
2.1 用户数据模型建模
根据上文中的分析可以看出,用户数据基本可以划分为五类:
用户基本数据(BasicData):包括用户姓名、性别、身份证、电话、出身日期、职业、毕业学校、爱好、出生地等。
时间数据(TimeData):记录用户使用系统的日期和时间,同时也记录用户所在的时区。
地点数据(LocationData):用于记录用户所在的位置,包括城市,住所和工作地。
环境数据(EnvironmentData):记录当日天气情况,温度等。
用户偏好数据(PerferenceData):记录用户的偏好情况,如运动、电影、理财、旅游、读书等。
历史数据(HistoryData):记录用户曾经使用的系统服务,常用的理财,消费记录以及日志数据等。
通过UML工具可以很清晰的看出用户各类数据之间的关系,并且通过设置主键显示出各条属性的重要程度,具体如图1所示。
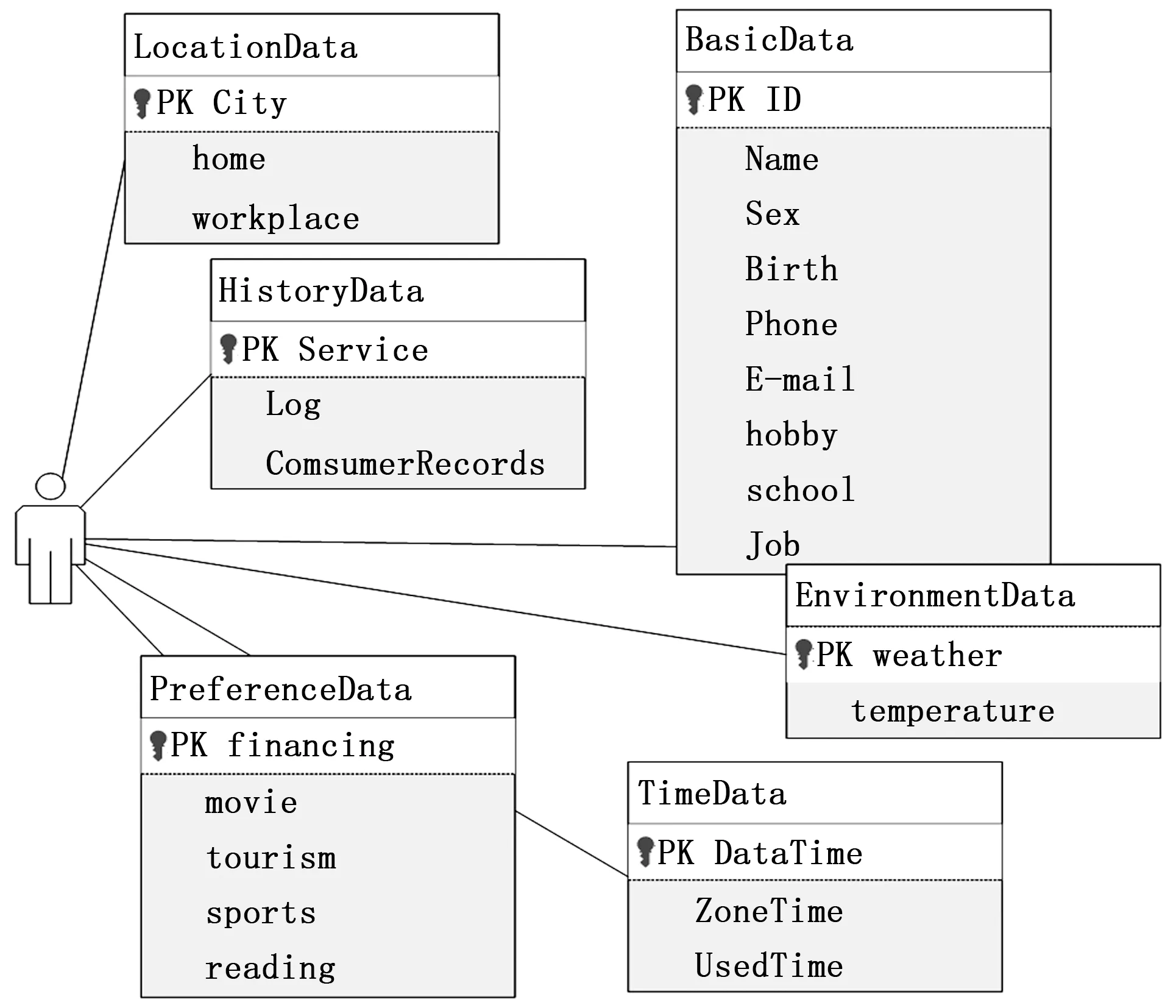
图1 用户数据模型
系统数据服务有成绩查询服务、工资数据服务、银行排队服务、交通数据服务、酒店预订服务、股票期货服务、多媒体数据推送服务。这些系统都属于不同的领域,这些系统的数据类型复杂程度高,数量大,若不进行建模将很难进行云推送,在对系统数据进行建模之后也更利于数据的个性化推荐,本章选择具有代表性的成绩查询服务系统和多媒体数据服务系统进行系统数据模型建模。
2.2 系统数据模型建模
2.2.1 成绩查询服务系统
成绩查询服务系统主要为在校学生提供每个学期结束之后的成绩查询服务,首先最高层应该为用户的类型,为本科生、硕士研究生还是博士研究生,确定了学生类型之后需要到各个学院中查询数据,由于很多学院中的必修课是相同的,所以为了避免重复的查询接下来模型中将分为必修课和选修课以及实践活动。最终得到各门功课的成绩。最后学生得到了该门课的成绩之后,还需要对老师进行评价。
系统数据模型再结合用户数据模型可以看出,在用户数据模型中的用户偏好,毕业院校就可以更加精确地给用户推送推荐数据,同时这种分层的结构能使云推送更加高效。
2.2.2 多媒体数据服务系统
多媒体数据服务相对于成绩查询服务将会复杂很多,多媒体数据服务各种系统中,可以将数据的类型分为文字数据、音频数据、视频数据、图文数据等。根据多媒体服务的不同类型和用户的偏好将分为新闻,体育,娱乐,游戏,电影等,然后再对具体需要推送的数据进行分类。
系统数据模型主要元素包括基本数据、功能数据和其他数据:
基础数据(SerBasicData):主要是对系统服务的基本描述,包括服务提供商,服务类型,服务ID,服务名称,服务简介等数据。
功能数据(SerFunctionData):主要对服务中的功能性参数进行描述,即服务输入输出参数,服务的接口参数,最终服务执行结果等。
其他数据:主要有些系统需要定位数据,天气数据等其他因素。
3 基于USDR模型的云推荐算法
传统的推荐算法有皮尔逊相关系数法、向量余弦法、斯皮尔曼相关系数法等等,在不同的领域中,需要选取不同的相似度计算方法。由于云数据的特殊性,本文重新设计了基于USDR的个性化云推送推荐算法,根据用户、系统的相似值来计算推荐的系统数据。本章的模型中存在用户数据和系统数据两种数据类型,针对该模型设计了基于用户的云推荐算法和基于系统的云推荐算法。
3.1 基于用户的云推荐算法
基于用户的云推荐算法主要目的在于计算两个用户的相似度,本算法中主要使用用户行为相似度来计算用户的类似喜好。本算法由两部分组成:一部分采用用户基础属性来决定用户的相似程度,通过计算得出的基本属性差异越小,则相似程度越高;第二部分是偏好、位置和服务记录数据等,通过查看用户的地理位置和历史感兴趣的系统的数值,该数值越大,则用户之间的相似程度越高,最后计算总相似度。
3.1.1 基础属性相似度
基础属性一般都是数值类型,如性别,年龄,毕业院校等。对于数值型属性,只需要计算绝对值之差|D|=|Attr1-Attr2|。对于名称型的基础数据,一般取值类型比较单一,就可以采用二进制编码的方式来表示,比如性别:男、女,分别对应00、01。其他以此类推。最终将用户全部名称型数据编码串联起来,行成一个二进制串。
不同的数值型属性的绝对值最大与最小的差距为[α1,αn],然后把这个区间划分为n-1个相等的区间{[α1,α2],[α2,α3],...,[αn-1,αn]},对每个区间给予相应的数值{0,1,2,3...n},当用户的数值型属性绝对值落在某个区间时,即可得出属性间的距离Dbnum。对于名称型属性,通过确定编码位数n,然后将每个取值通过格雷编码,然后依次链接起来,最后通过计算海明距离,得到名称型属性距离DH。定义用户A和B,每个基础属性的权重值为wi,则所有属性权重值满足:
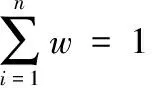
(1)
对于数值型的属性距离Dbnum,根据上面的解释,定义不同的取值区间:
若α∈[α1,α2],则dbnum=0;
若α∈[α2,α3],则dbnum=1;
.......
若α∈[αn-1,αn],则dbnum=n-1;
数值属性的距离计算为:

(2)
对于名称型的属性距离Dbnum,则对不同的取值进行编码。将用户的全部名称属性编码串联起来,形成二进制串At;采用At的海明距离来计算用户名称属性的距离。
DH=wDhm(DbnumA,DbnumB)
(3)
最终得到2个用户A与B的基础属性距离:
(4)
通过差值DA-B可以看出,DA-B越小,相似度则越大,DA-B越大,则相似度越小。
3.1.2 用户偏好相似度
若给定用户A和B,N(A)表示用户A的偏好相似度集合,N(B)表示用户B的偏好相似度集合(如时间,位置,系统使用情况等),运用余弦公式相似度计算公式:
(5)

表1 用户偏好表
从表1的用户偏好可以得出:用户A对{成绩,金融,酒店}方面的系统感兴趣,用户B对{成绩,工资}方面的系统感兴趣,所以可以计算出用户A和用户B的偏好相似度,如下所示:
用余弦公式计算用户间两两的相似度之后,算法通过综合分析基础数据相似度和用户偏好数据相似度后,再进行推荐,推荐度公式如6所示:
(6)
公式中,DA-B为基础数据的差值,N(i)表示对项目i有偏好的用户组,Re(u,k)表示存在与用户A偏好类似的用户组。Wab描述用户A与用户B的相似度,ybi表示用户B对项目i的偏好程度。
3.2 基于系统的云推荐算法
基于系统的云推荐算法和基于用户偏好的推荐算法有些类似,主要通过以下两步完成:首先计算系统之间的相似程度,然后根据相似度生成系统推荐列表。
根据余弦公式可得系统的相似度:
(7)
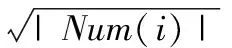
(8)
假设有a,b,c,d,e5个系统,同时存在A,B,C,D,E5位用户,对每位用户偏好的项目用矩阵表示:
用户A:偏好a,b,c系统,用矩阵表示为:

用户B:偏好a,b,d系统,用矩阵表示为:

用户C:偏好a,d系统,用矩阵表示为:

用户D:偏好b,c,e系统,用矩阵表示为:

用户E:偏好a,e系统,用矩阵表示为:

将A,B,C,D,E矩阵全部相加之后可得矩阵S,S[i][j]则表示同时对系统i和系统j都偏好的用户数量。

得到相似度矩阵之后,通过公式(7)计算用户a对系统i的推荐度:
Recommdsys(a,i)=∑i∈N(u)∩S(i,k)wij
(9)
公式(9)中表示当前用户的偏好集合,S(i,k)表示与系统i比较相似的K个系统的集合,wij是系统i与系统j的相似度。将该推荐度从大到小排列,采用TOP-N的方式取前N个系统推荐给用户。
3.3 基于USDR的云推荐算法运行过程
为了达到更好的用户体验,为用户提供个性化的推荐服务,基于USDR模型运行过程如图2所示,首先根据用户注册数据为用户建模,其次为平台中每个系统进行建模,当模型构建完成之后,分析用户注册数据中的基础属性数据,计算出基础属性相似度,再算出用户偏好属性相似度,最后同理算出基于系统的云推送推荐算法,最终为用户推送推荐数据。
通过分别计算用户和系统数据的推荐度会导致结果比较粗糙,为了使得云推荐算法更加精确,将用户数据推荐度加入到系统数据推荐度中,得出综合推荐度列表,将使推荐度的结果更加准确和方便,更加方便于下一步的云推送。如何使用基于USDR模型的云推荐算法得出用户推荐度列表的具体流程如图3所示。
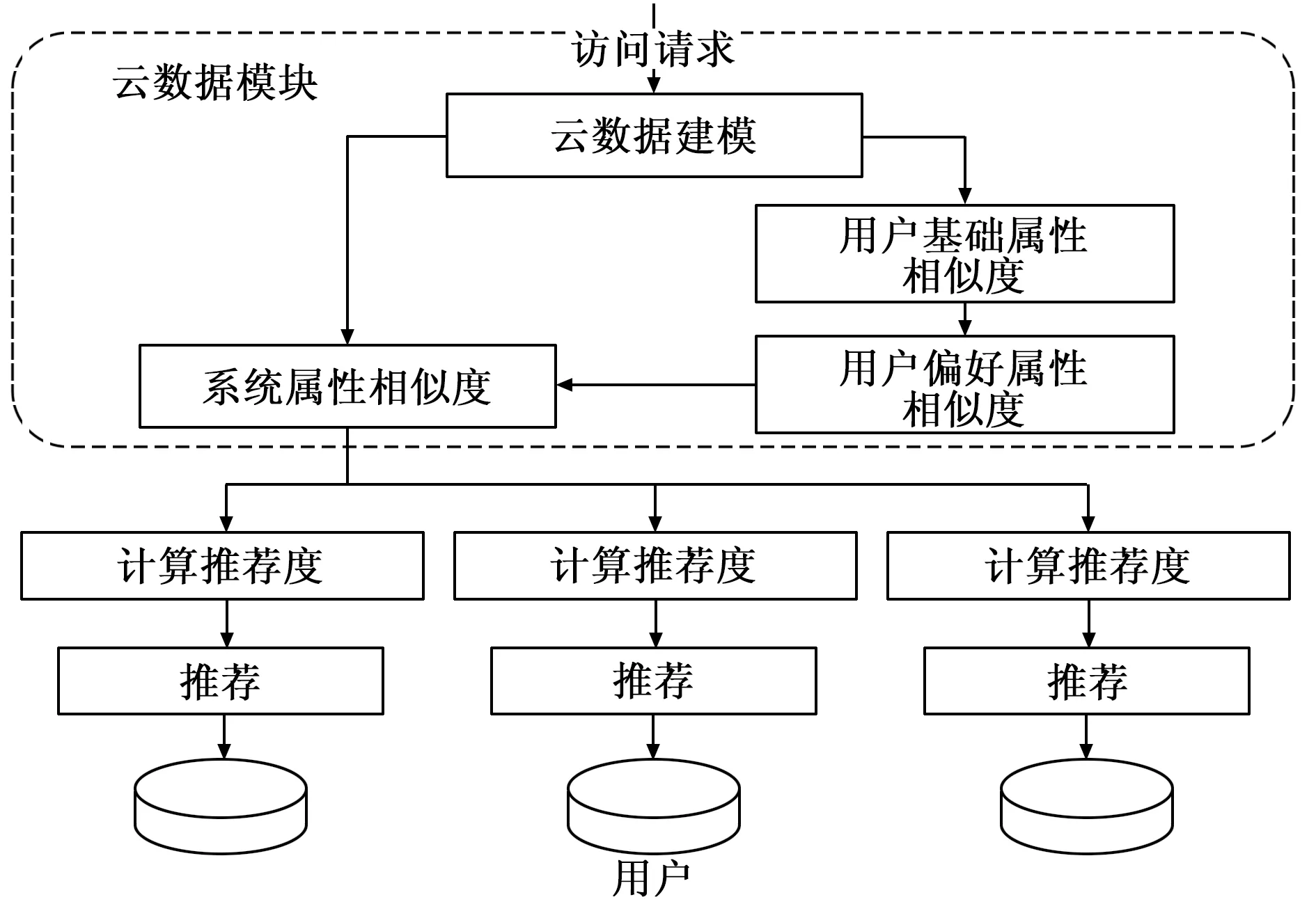
图2 基于USDR模型运行过程

图3 基于USDR模型的云推荐算法运行流程
1)查看用户历史记录数据表,若用户的历史数据为空,则说明为新注册用户,那么就执行步骤2),否则执行步骤5);
2)查看用户基础数据中的好友表,若有好友,则执行步骤3),若无,则执行步骤4);
3)使该用户分别与每位好友分别用公式DA-B进行计算,得出相似度,查看相似度在设定的权重值内的用户与该用户关系最密切的好友,执行步骤4);
4)使用公式(4)计算所有在权重值范围内的好友的偏好推荐度Recommenduser,加入用户推荐列表中,执行步骤5);
5)使用公式(7)计算的历史数据表中每个系统的推荐度RecommendSystem,将这些系统放入推荐列表,执行步骤6);
6)将步骤4)和步骤5)中的Recommenduser和RecommendSystem分别平方,再求和开根号得出综合推荐度:
Recommendgeneral=
(10)
7)根据综合推荐度,加入到综合推荐度列表。
4 案例分析与实验
本文使用云推荐方法在安卓和iOS中进行了测试,云数据来源于成绩系统,工资系统和微影视系统,采集到数据后将数据的主要权重值分为:用户权限,用户登录时间,用户发布/订阅的模式(一对多/一对一),用户登录数量,传输数据量。权重w是经过综合考虑而确定的。目前数据物流云推送平台中存在的系统如图4所示。
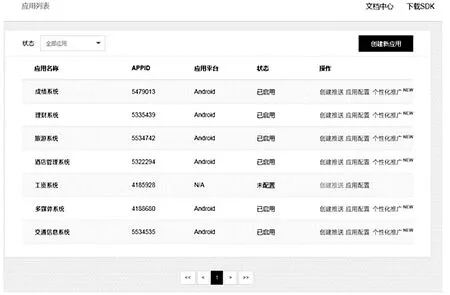
图4 用户登录平台选择偏好的系统
用户在手机端进行注册,主要需要将用户基础数据和偏好信息填写完毕,方便接下来的云推荐系统给用户推荐个性化内容。当用户基础数据、偏好数据和系统数据都进行绑定之后,得到如图5所示的界面,此时平台已经根据云推荐算法将推荐数据放入推荐列表中,等待下一步的云推送。

图5 用户功能页面
5 算法有效性分析
为衡量本文提出的USDR云推荐算法的能力,从算法效率、系统数量、平均传输率,通信率,静置时流量等方面来对算法有效性进行评估。
首先测试单机中的普通推荐算法和云推送平台中的推荐算法进行比较,单机使用Windows8 64位操作系统,8GB内存,10台虚拟机同样使用Windows8 64位操作系统,8GB内存,分别计算虚拟数据量为10~100万的数据量。
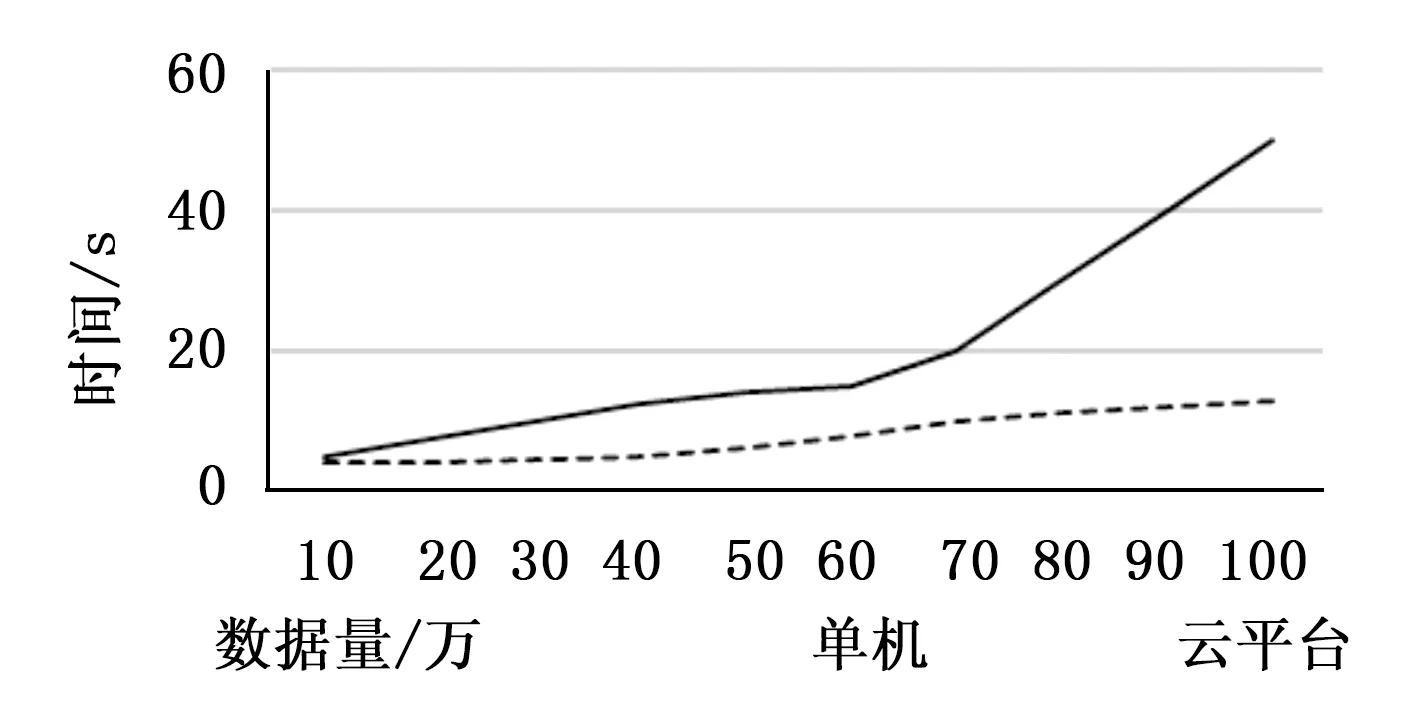
图6 单机与云平台中推荐算法效率对比
为了得到当在数据量相同时运算速度与虚拟机数据的关系,实验中使用50万的数据量,分别测试虚拟机数量为5~10台时云推荐算法运行的效率。
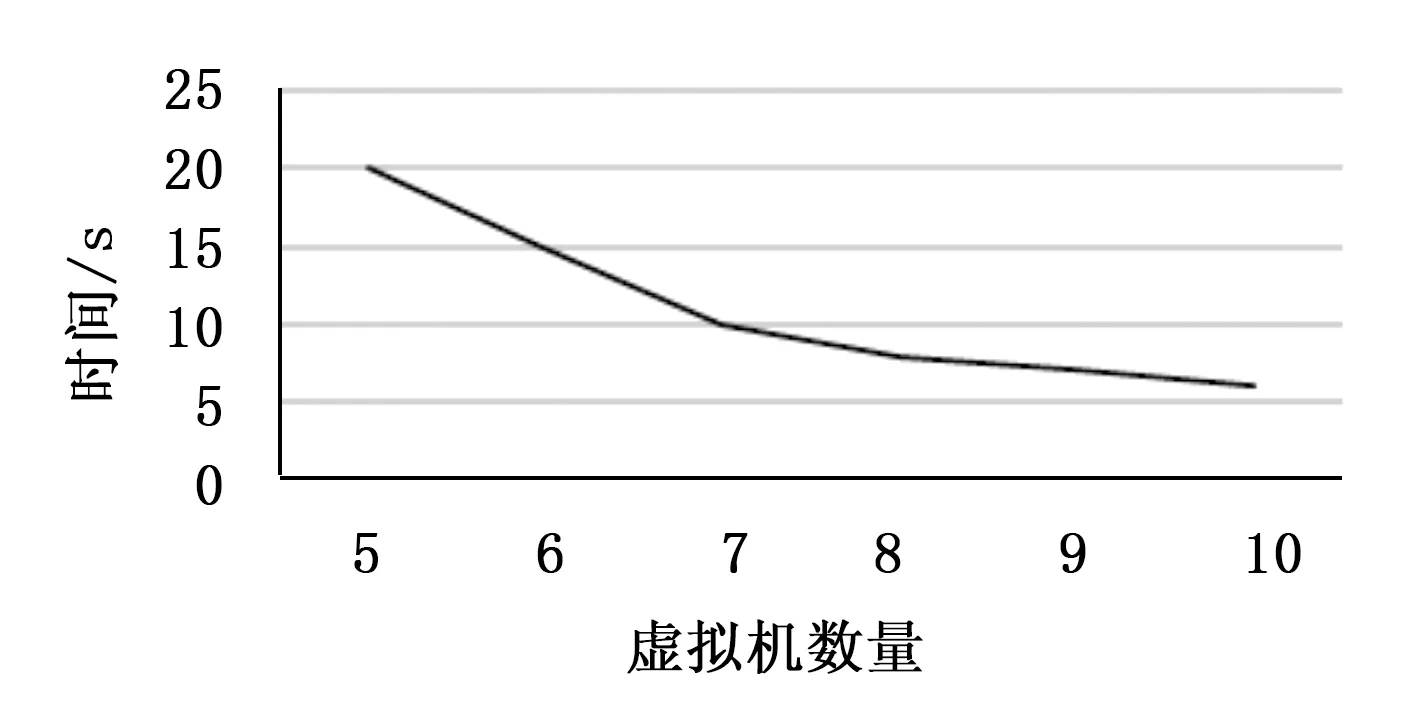
图7 虚拟机数量不同对推荐算法的影响
平均传输率是指数据传输平均的“倍速”数。单倍数传输时,即可记为1倍速,普通推送的平均传输率为10倍速,在数据量相同时,结果如表2所示。

表2 平均传输率数据表 %
通信率是指单位时间内用户与云推送平台的通信次数,测试用户是否愿意使用该平台进行数据推送,并同时测试了在通信次数高的时候会不会产生其他问题(结果如图8所示),普通的推荐算法通信率基本不变是由于在推送任务队列消息的整个过程中一直都会向服务器发送请求,而本文提出的云推荐方法处于信息收集阶段,随着系统的运行,任务数量增多,优势就逐渐显示出来,在任务数越多时,花费的通信量反而变少。
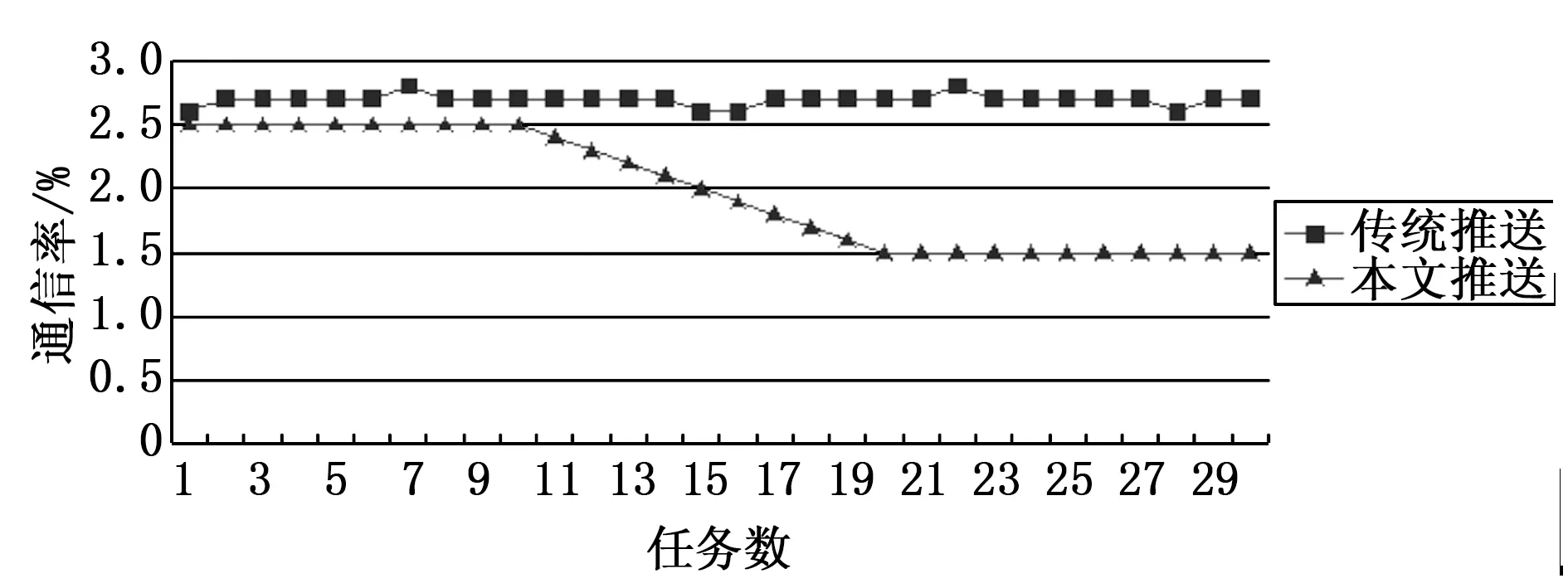
图8 通信率变化图
静置时流量是指在手机静置时由于推送而产生的额外流量,测试云推送平台是否会因为通信率的改善而产生大量流量,分别使用云推送平台和传统推送平台进行测试(如表3所示),实验结果表明云推送平台在移动设备静置时间较长情况下流量消耗少于传统推送平台。
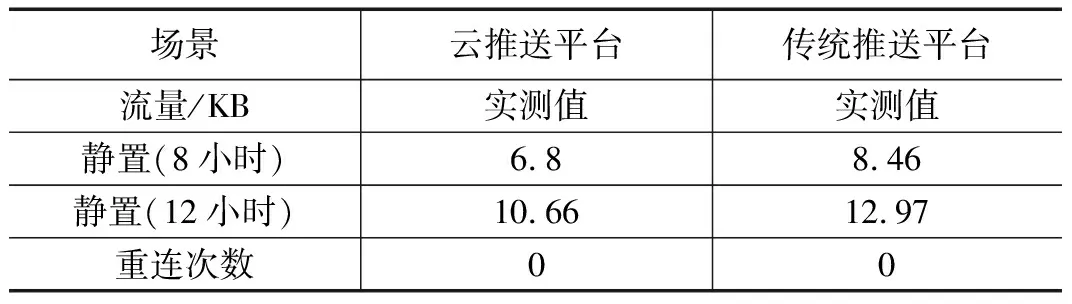
表3 静置时流量对比
6 结束语
本文针对传统的推送方式在推送多源异构数据时遇到的效率低,实时性差等问题,设计了面向多源异构数据的云推送平台来满足云推送环境,并通过USDR模型解决了多源异构数据推送问题,满足了用户需求。
然而,该平台能否满足所有的用户需求,能否供海量用户使用还需要进行验证,云推送平台本身的性能提升以及各种演化方式将是本文下一步的研究内容。相信随着这些关键问题的攻破,面向多源异构数据的云推送平台将为用户带来更好的推送体验。
猜你喜欢
工业设计(2022年8期)2022-09-09
小学生学习指导(低年级)(2021年12期)2021-12-31
军民两用技术与产品(2021年10期)2021-03-16
小学阅读指南·低年级版(2020年11期)2020-11-16
阅读与作文(英语初中版)(2019年8期)2019-08-27
智富时代(2019年7期)2019-08-16
智富时代(2019年7期)2019-08-16
小学生学习指导(低年级)(2018年11期)2018-12-03
小学生学习指导(低年级)(2018年11期)2018-12-03
商用汽车(2016年11期)2016-12-19
