
基于随机森林算法的土石坝压实质量动态评价研究
2018-09-13 12:42林威伟钟登华鄢玉玲任炳昱
水利学报 2018年8期
林威伟,钟登华,胡 炜,吕 鹏,鄢玉玲,任炳昱
(天津大学 水利工程仿真与安全国家重点实验室,天津 300072)
1 研究背景
随着土石坝工程规模的日渐庞大,加之其建设周期长、施工条件复杂等特点,土石坝工程的施工质量控制已成为其安全控制的重点。压实质量控制是土石坝施工质量控制的关键,干密度为土石坝工程心墙区压实质量的评价指标。施工现场通常利用试坑试验获取干密度来评价仓面的压实质量,该方法存在以下局限性:(1)有限的取样点难以全面反映仓面的压实质量;(2)试坑试验耗费时间甚至影响施工进度;(3)此压实质量评价方法为事后评价,难以对仓面的压实质量进行及时补救。针对上述问题,通过本课题组的土石坝碾压实时监控系统[1-3]能够有效、实时、快速地获取全仓面碾压参数,这极大地提高了土石坝施工质量事中控制的水平,然而碾压参数存在无法直接评价压实质量的不足。因此,有必要开展基于实时监控系统的土石坝压实质量全仓面动态评价研究。
压实质量主要受料源参数和碾压参数的影响。但是,通过随机选点获取料源参数的方式使料源参数存在不确定性,增加了压实质量评价的难度。近十几年来,国内外针对压实质量分析与评估的相关研究已经取得较为丰富的成果。David等[4-5]提出了IC(Intelligent Compaction)技术指标并据此评估了IC技术在土方施工中的应用前景;Mooney等[6]提出总谐波失真率指标THD(Total Harmonic Distor⁃tion),并且通过验证将这一指标成功用于土壤压实质量评价;刘东海等[7]提出压实监测值CV(Com⁃paction Value)作为土石坝料压实质量的实时表征指标,并通过工程实例验证CV值与压实度具有显著相关性;周龙等[8]基于土石坝填筑质量的不确定性分析将可靠度理论融入实际工程的干密度指标中,建立了坝体干密度-可靠度二元耦合评价模型,获得了土石坝坝面的压实度分布及其满足施工要求的可靠度;王瑞等[9]在考虑料源参数不确定性影响的基础上采用BP神经网络拟合压实度与各参数的非线性关系,并分析了土石坝的压实度分布;刘东海等[10-11]基于碾压实时监控系统获得的碾压参数建立了多元回归模型预测压实质量,利用Kriging插值法进行全仓面压实质量评估,从而降低了由于随机取点造成的质量检测不全面性;钟登华等[12]基于熵-盲数理论和非线性回归分析方法,提出了实时监控下考虑混凝土特性参数不确定性的碾压混凝土坝压实质量动态评价方法;吕鹏等[13]采用遗传神经网络算法,提出了基于孔隙度和可靠度的压实质量评价方法。
综上所述,在坝体压实质量评价研究工作中,针对碾压参数和技术指标等因素对干密度影响的研究已经较为成熟,但是缺乏考虑P5含量(Particle,简称P;P5含量即粒径小于0.5 mm的颗粒质量占颗粒总质量的百分比)、含水率等料源特性及气象要素对土石坝坝体压实质量影响的相关研究。周龙[23]研究表明,级配良好的堆石料颗粒经碾压后最有可能得到较高的干密度,其中P5含量是反映级配成分的重要参数;水分能够减少坝料间的摩擦,利于坝料的软化及浸润,便于棱角部位的压实,而湿度等气象要素对坝料含水率有明显影响[14];因此,P5含量、含水率和湿度是干密度的重要影响因素。通过随机选点取样进行试坑试验获得的料源参数,其样本数量少且存在不确定性,已有的少数涉及料源参数不确定性的研究仅提出了不确定性的概念,并没有进行深入的分析和量化。目前主要采用人工神经网络、线性回归和非线性回归等模型对压实质量进行评价,虽然这些评价模型对参数与干密度的线性或非线性相关关系进行了较精确的拟合,但是忽略了参数所具有的不确定性,拟合精度仍有待提高,并且神经网络过强的学习能力使得有用信息易被预测模型中的噪声湮没,导致其泛化能力差且易过拟合。因此,基于碾压实时监控系统,有必要建立一个能够考虑料源参数不确定性、且具有模型精确度高及不易过拟合特点的土石坝压实质量动态评价模型,从而实现对压实质量快速、有效、实时的全仓面控制。因此,本文开展了基于随机森林算法的土石坝压实质量全仓面动态评价研究。拟解决以下3个方面的问题:(1)如何定量分析和比较料源参数不确定性的大小,以验证考虑料源参数不确定性的必要性;(2)如何构建干密度评价模型,并在考虑干密度与影响因素之间的关系以及料源参数的不确定性影响的情况下进一步提高模型评价精度;(3)如何通过有限检测点实现对全仓面压实质量的评价,并提高未知点预测值的可信度。
针对问题(1),采用信息熵对土石坝料源参数的不确定性进行分析和量化。1948年,数学家申农将熵引入信息论,提出“信息熵”用于度量系统的不确定性,并得到了广泛的应用[15];针对问题(2),通过Pearson相关性分析方法分析各项指标参数与干密度之间的相关关系,并据此构建基于随机森林算法的压实质量评价模型。随机森林(Random Forest,RF)算法提出的十多年来,在国内外的水文、降雨等诸多领域得到了广泛应用,Gislason、Parkhurst、甄亿位等研究结果表明[16-20],随机森林算法的预测性能优于普通线性回归和神经网络模型,并且能够考虑参数不确定性,具有稳定性好、不易过拟合、对噪声不敏感、估计效果优及泛化误差小等优势。因此,建立基于随机森林的压实质量评价模型能够在考虑参数不确定性的前提下提高模型精度;针对问题(3),基于碾压实时监控系统,采用上述评价模型对仓面网格进行压实质量评价,结合插值结果可信度更高的普通Kriging空间插值法[21]对全仓面的干密度进行插值,从而实现土石坝全仓面压实质量的动态评价。
2 研究框架
结合钟登华等[1-3]研究开发的“土石坝碾压实时监控系统”以及现场试验资料和气象要素资料,在考虑料源参数不确定性条件下构建基于随机森林算法的土石坝心墙区压实质量评价模型。评价框架如图1所示,包括评价指标体系的建立、评价模型的建立以及工程应用实例。

图1 评价框架
(1)第一步:构建评价指标的原始数据集。通过土石坝碾压实时监控系统、坝体碾压初期的现场试验和气象站分别获取碾压参数、料源参数及气象要素等参数,在此基础上构建土石坝压实质量评价指标的原始数据集。如图1所示,第一层为评价的目标层,本研究中土石坝心墙区压实质量的评价指标为干密度,干密度样本通过试坑试验获取。第二层为影响干密度的参数类别,分别为碾压参数、料源参数以及气象要素。第三层为影响压实质量评价指标干密度的具体参数,包括碾压参数(碾压速度、碾压遍数和压实厚度)、料源参数(P5含量、全料含水率、坝料级配)和气象要素(温度和湿度)。在土石坝碾压实时监控系统获取碾压参数的基础上,结合P5含量等料源参数和气象要素构建土石坝压实质量评价模型的指标体系,使压实质量评价的考虑因素更加全面、评价结果更加精确。
(2)第二步:相关性分析。利用SPSS软件对干密度及其影响参数进行Pearson相关性分析,得到各个参数与干密度的Pearson相关系数和显著性水平,并基于此选取与干密度显著相关的指标参数作为模型的输入变量。
(3)第三步:不确定性的分析和量化。分别从料源参数中不可控因子的变异不确定性和评价过程的随机不确定性两个方面进行参数的不确定性分析,通过信息熵分析和量化土石坝料源参数的不确定性,验证在土石坝压实质量评价中考虑料源参数不确定性的必要性。
(4)第四步:建立基于随机森林算法的压实质量评价模型。在第一步构建的评价数据集的基础上,建立基于随机森林算法的压实质量评价模型,并对模型的评价精度进行五折交叉验证和F检验,验证评价模型的可行性。
(5)第五步:工程应用。应用上述模型对某水利工程土石坝心墙区的施工压实质量进行评价分析,验证基于随机森林算法的压实质量评价模型的有效性和可靠性,并通过对比分析表明模型具有的一致性、代表性和优越性。
3 基于随机森林算法的压实质量评价模型与方法
3.1基于信息熵的料源参数的不确定性分析在土石坝碾压施工过程中,干密度影响因素的不确定性主要来源于两个方面。一方面为不可控因子的变异性:以含水率为例,含水率虽然通过试验达到了控制标准,但在实际施工过程中通过洒水等措施无法精确控制坝料含水率,此外,气象要素也影响着坝料含水率,结果使得整个仓面的坝料含水率变异性较大,故坝料含水率具有不确定性。另一方面为压实质量评价过程中的随机性:现场料源参数仅能通过有限的试坑试验获得确定的值,对于仓面未检测点的料源参数值则通过软件生成正态随机数进行模拟,因此最终得到的干密度具有一定的随机性。
通过土石坝碾压实时监控系统得到的碾压参数在土石坝标准控制范围内,变异性较小;对历史的试坑试验数据进行统计分析,结果表明,获取的P5含量等料源参数在一定的概率分布函数范围内变化,不确定性较大;因此,本文主要研究料源参数变异不确定性,采用“信息熵”进行量化,其熵值越大,不确定性越大[15]。具体步骤如下:
(1)对料源参数的取值范围进行平均分组,得到每一组数值出现的频数n;
(2)通过式(1)得到每一组数值出现的频率P;

(3)根据熵的定义,利用式(2)计算料源参数的熵值;

式中:E为熵值;m为料源参数分组个数;k的取值为k=1/lnm;Pj为第j组数值出现的频率。
(4)重复以上步骤得到所有料源参数的熵值,并根据熵值的大小判断料源参数的不确定性程度。
通过对历史试坑试验数据进行统计分析得到料源参数的概率分布函数,基于该概率分布函数对仓面未检测点的料源参数进行随机模拟,得到的全仓面干密度评价结果具有一定的随机性,干密度评价结果的随机性必然导致压实质量评价结果的随机误差,而随机误差的大小决定了评价结果的精确度。因此,本研究通过100次的随机模拟取置信度在95%以上的评价结果作为最后的评价值,以降低随机误差,并使其结果更趋近实际情况。
3.2 基于随机森林算法的压实质量评价模型与方法随机森林(Random Forest,RF)的核心思想是将存在过度拟合和局部收敛问题的单个分类器决策树组合成多个分类器森林[21]。它利用Bootstrap重抽样方法从原始样本中抽取多个样本,并对每个Bootstrap样本进行决策树建模,然后将这些决策树组合在一起,最后通过对单棵树的预测值进行算术平均得到最终的评价结果[20]。大量研究成果表明[16-20],随机森林算法具有不易出现过拟合、能够很好地处理噪声和异常值、泛化误差低、估计和预测结果优良且对多元共线性不敏感等优点,被称为当前最好的算法之一。
节点分裂的随机特征数Mtry、随机森林树的个数Ntree以及叶节点的样本数Nodesize是影响随机森林模型性能和效率的3个重要参数。为了保证随机性,随机森林在每棵决策树的分裂节点需要从原始特征集合中随机抽取一个特征子集,子集中包含Mtry个候选特征(Mtry一经选定,则在建树过程中保持不变)。Mtry太小会导致分类器结果出现过拟合,预测分类的误差变大及精确度降低;Mtry太大则会使RF构建时间过长,运行速度减慢。Ntree太小会导致训练不够充分,降低RF的随机性;太大则会过于随机化,增加了模型的运算量,降低树的分类精度。Nodesize表示叶节点的最小样本数,RF的性能对Nodesize不敏感。
针对土石坝心墙区压实质量评价问题,本文建立了土石坝心墙区的压实质量评价模型。首先通过相关性分析选择显著性较大的指标作为影响因子,得到压实质量评价模型的原始数据集,然后采用随机森林算法对其进行求解。基于随机森林算法的压实质量评价数学模型如下:
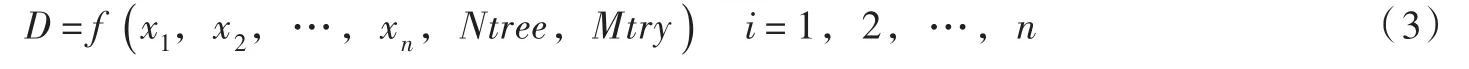
式中:D为干密度;xi为第i个参与评价的参数;n为参与评价的参数个数;f为随机森林算法的不确定映射关系;Ntree和Mtry分别为泛化误差最小时对应的决策树数量和随机特征数。
3.3 基于普通Kriging插值法的全仓面压实质量评价方法个别网格点的干密度评价值无法对全仓面的压实质量进行评价。本研究基于随机森林算法和实时监控系统,结合普通Kriging插值法建立了土石坝全仓面压实质量评价模型,评价步骤如图2所示。首先,出于对全仓面料源参数不确定性的考虑,将整个施工仓面划分成2 m×2 m的网格,并采用心墙土石坝碾压实时监控系统获取每个网格的碾压遍数n、压实厚度h;其次,对试坑试验得到的料源参数频率分布函数进行拟合;再次,基于拟合得到的料源参数的分布函数,通过随机法生成该分布函数的随机值,将生成的随机数代入随机森林算法得到干密度求解结果;进一步,重复上一步骤100次,取每一个点的100次求解结果中置信度在95%以上的求解结果作为最后的评价值;最后,基于各个网格坐标对应的干密度,通过普通Krig⁃ing插值法进行插值处理,得到可信度高的插值点结果,再通过MATLAB分析软件生成分布云图。

图2 全仓面压实质量评价步骤
根据样品空间位置和样品间相关程度的不同,D.G.Krege和H.S.Sichel于1951年首次提出Krig⁃ing插值法。该方法基于各个观测点之间的相互关系,对每个观测点赋予一定的权重系数,进行滑动加权平均,进而估计未知样点上的样本平均值。Kriging内插法根据无偏估计和方差最小两项要求来确定加权系数,故又称为最优内插法[21]。
4 工程应用
结合位于中国西南某省某水电站的黏土心墙土石坝开展应用研究。该电站的控制流域面积约6.57万km2,最大坝高为295.0 m,装机容量为300万kW,具有多年调节能力,开发任务以发电为主,兼顾防洪。根据土石坝碾压实时监控系统、试坑试验及气象站获得的101组土石坝下游砾石土心墙区压实质量评价指标数据,结合随机森林算法构建考虑料源参数不确定性的压实质量全仓面评价模型,实现了对施工质量的实时动态控制。虽然随机森林具有自评估功能无需交叉验证或单独测试,但为了将构建的随机森林模型与BP神经网络和线性回归进行对比分析,故采用五折交叉验证方法对随机森林算法的性能进行验证。通过随机取样方法将原始数据集均分为5份,其中4份为训练集,1份为测试集。
4.1 干密度影响参数分析通过土石坝碾压实时监控系统、试坑试验及气象站分别获取碾压参数、料源参数及气象要素等参数,并采用信息熵理论对料源参数不确定性进行量化,从而分析了料源参数的不确定影响程度。
(1)料源参数的不确定性分析。以含水率和反映级配性质的P5含量为例。将砾石土心墙区的101组现场试坑试验数据从小到大进行分组排列,统计其样本个数和频率,生成频率分布直方图如图3(a)(b)所示。由图3可知,料源参数中P5含量及全料含水率参数的取值以一定的规律满足正态分布,其存在变异不确定性,因而在进行土石坝压实质量评价时需考虑其不确定性。对选定砾石土心墙区的101组现场试坑试验的干密度数据进行分析,生成的频率分布直方图如图3(c)所示,从图中可知干密度指标基本服从正态分布。
按照3.2节信息熵的计算步骤,得到料源参数熵值的计算结果如表1所示。从表1可知,料源参数的熵值均大于0.5,即各个参数均具有较大的不确定性,因此,土石坝压实质量评价过程中需要考虑料源参数的不确定性。

图3 料源参数频率分布直方图

表1 料源参数的熵值
(2)碾压参数和气象要素的数据简析。在碾压参数中以振碾遍数为例,选定砾石土心墙区的149组的振碾遍数,通过统计分析发现振碾遍数仅有两例在10遍以下,其余均在10遍及其以上,碾压遍数的控制达到标准。
气象要素通过改变露天料场坝料含水率影响压实质量。以温度和湿度为例,选定心墙区气象站的106组现场数据。通过统计分析可知温度和湿度的取值跨度较大,分布较为离散,湿度处于40%以上居多。由于工期要求,碾压过程中存在低温作业的情况,但总体来说低温作业情况较少。
4.2 基于随机森林算法的土石坝压实质量评价模型的建立
4.2.1 相关性分析 全料干密度作为压实质量主要评价指标受到许多因素的影响,如碾压参数、料源参数及气象要素等。首先,获取下游砾石土心墙区的碾压参数、料源参数及气象要素等参数;然后,对各个参数与全料干密度的相关性进行分析;最后,构建相关系数矩阵图,如图4所示(其中圆的半径和颜色表示参数间皮尔逊相关性R的大小。|R|=0为不相关关系;|R|<0.4为弱相关;0.4<|R|<0.75为相关;0.75<|R|<1为强相关;|R|=1为完全相关)。显著性数值用于判断干密度与各个评价指标间是否存在显著差异,低于0.1可以认为不存在真实差异,即具有显著相关性。

图4 相关系数矩阵图
从图4和图例可知,全料含水率与全料干密度的R最大为-0.824,显著性为0.002,在1%的显著性水平之下,两者之间具有十分显著的负相关关系。P5含量与全料干密度的R最大为0.719,显著性为0.014,在5%的显著性水平之下,二者呈显著正相关关系。振碾遍数与全料干密度的R最大为-0.664,显著性为0.050,处在5%的显著性水平线上,二者显著相关。此外,全料干密度与总遍数、曲率系数和湿度的R均大于0.5,具有高度的相关关系。相关性分析结果表明所建模型输入参数的选取是合理的。
4.2.2 决策树的数量(Ntree)和随机特征数(Mtry)的确定 根据相关性分析结果,选择碾压遍数、全料含水率、P5含量、曲率系数及湿度作为影响参数输入压实质量评价模型。分析不同决策树数量下随机森林算法的求解结果,得到均方误差折线图如图5(a)所示,因此,为保证随机森林求解结果的精确度,减少计算量,提高运行速度,选择Ntree为200进行运算。设置Mtry为1,2,…,5进行多次评价取平均值,得到不同Mtry下随机森林求解结果的最小MSE折线图,如图5(b)所示,可以看出,当Mtry为3时均方误差达到最小值0.000 33。为了保证随机森林求解结果的精确度,故在压实质量评价模型中Mtry设置为3。
4.2.3 随机森林评价结果分析 现有研究通常采用交叉验证对模型的评价结果进行分析。有研究表明[25]五折交叉验证更为适用且结果更具有说服力,故本文采用五折交叉验证的方法对模型误差进行验证。首先,设置随机森林的初始数据,决策树数量(Ntree)为200,随机特征数取值为3;其次,选取碾压遍数、全料含水率、P5含量、曲率系数及湿度作为影响参数输入随机森林,并与输出变量(碾压干密度)进行拟合;然后,采用五折交叉验证对求解结果进行误差分析,计算相关系数R、RMSE、MAE和RPD等精度表征参数;最后,循环运行上述操作5次,将结果的均值作为对随机森林算法精度的估计。

图5 均方误差折线图

图6 五折交叉验证下干密度实测值与随机森林求解结果折线图
五折交叉验证下干密度实测值与随机森林算法求解结果的对比折线图如图6所示。通过计算分析可得Pearson相关系数为0.685,二者呈显著的线性相关关系;显著性为0.000,低于显著性水平0.05,故随机森林算法模型通过检验能够应用于压实质量评价。通过五折交叉验证得到平均绝对误差值为0.0104,平均标准均方误差值为0.000 172,该值低于平均值的0.0001,求解结果的精确度达到99%以上水平,模型的拟合度十分优良。
4.3 全仓面压实质量评价交叉验证和F检验的结果表明,随机森林算法可应用于压实质量评价领域。基于随机森林算法和实时监控系统,结合Kriging插值法建立土石坝全仓面压实质量评价模型,评价步骤图2所示。将某20 m×20 m的仓面划分成100个2 m×2 m的网格,采用土石坝碾压实时监控系统获取每个网格的碾压参数,然后按照4.1中得到的料源参数频率分布生成料源参数的随机值。在此基础上,采用基于随机森林的压实质量评价模型对该仓面的压实质量进行评价。
首先,选取100个2 m×2 m网格的中心点作为离散点,得到其X、Y坐标数据,以每个网格的随机森林最终求解结果作为Z坐标,将X、Y、Z坐标作为自变量输入云图生成软件。其次,采用Krig⁃ing插值法[21]进行插值,并考虑已知邻近坐标的求解结果及其空间分布结构特征,使插值结果更精确、更符合实际。最后,生成分布等值线云图(如图7所示)。该大坝工程《坝料设计要求及施工参数》中规定心墙区砾石土料的全料干密度达标率(即ρd≥2.18 g/cm3)不小于97%,由图7可知,该仓面干密度达标率为100%,大于填筑压实控制标准97%,故该仓面压实质量合格。在施工现场通过该模型实时计算出全仓面的干密度,若发现压实质量薄弱区域则由现场指挥人员通知施工人员进行补救,以此解决事后评价方法无法进行及时补救的问题。同时,该模型能够在考虑料源参数不确定性影响的基础上对全仓面任意位置的压实质量进行高精度评价,减少了试坑试验的数量。

图7 压实质量评价云图
4.4 压实质量评价方法的对比分析和讨论目前对压实质量进行预测评价的模型主要有人工神经网络、线性回归、非线性回归等,相关研究有效促进了对压实质量的事中实时控制。为进一步验证基于随机森林算法的压实质量评价模型的优势,应用BP人工神经网络[22]和线性回归方法[7,24]对研究区域的压实质量进行评价,并将求解结果与随机森林算法的求解结果进行对比分析。
通过分析求解结果的标准均方误差(MSE)、平均绝对误差(MAE)、百分比偏差率(RPD)和相关系数R等,对3种压实质量评价模型的优劣进行讨论。然而,衡量一个压实质量评价方法的好坏,不能仅通过误差分析对比就进行评判。本研究不仅对随机森林与BP神经网络和线性回归求解结果的误差进行对比分析,而且还增加了对平均值和标准差的对比分析,模型误差分析结果如图8所示。最后通过三Y折线图(即在一幅图上通过三个Y轴表征不同模型的评价值,如图9所示)将干密度实测值与评价方法求解结果进行更为直观的对比展示。
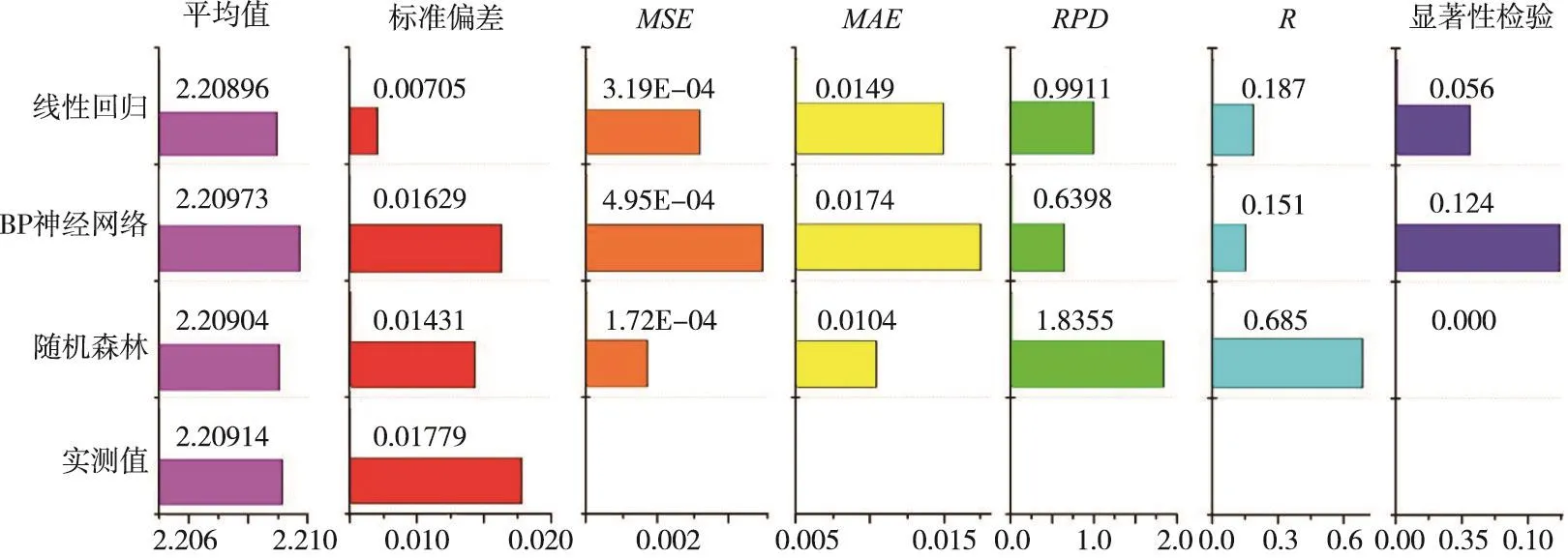
图8 三个评价模型评价值与实测值误差分析结果对比
根据图8、9可以得到以下结论:
(1)一致性:从图8可知,3种评价模型的求解结果是一致的。3种评价模型求解结果与实测值的平均值几乎一致,并且相对误差不超过0.05%;标准均方误差均小于1×10-3,且均位于10-4误差精度级别;平均绝对误差均处于0.01到0.02之间。此外,通过对模型结果进行分析可知,79%的随机森林求解结果与BP神经网络求解结果的误差低于1%;81%的随机森林求解结果与线性回归求解结果的误差低于1%。上述结果表明,随机森林算法与BP神经网络和线性回归具有较高的一致性。
(2)代表性:随机森林的相关系数R为0.685,其评价值与实测值呈强相关关系,求解结果相关性大于BP神经网络和线性回归;经F检验,唯有随机森林显著性为0.000在显著性水平0.05之下,通过检验;随机森林的MSE为1.72E-04、MAE为0.0104,均小于BP神经网络和线性回归,故随机森林的求解结果精度大于BP神经网络和线性回归;随机森林的RPD为1.8355大于BP神经网络和线性回归,表明其评价能力最佳;与其他评价模型的平均值相比,随机森林平均值更加接近实测值的平均值。以上结果表明,基于随机森林算法压实质量评价模型的求解结果泛化误差最小且精确度最高,能够代替BP神经网络和线性回归模型进行压实质量评价,具有代表性。

图9 模型评价值的三Y折线图
(3)优越性:综合图8和图9的三Y折线图可得,随机森林的求解结果分布情况与实测结果相似度最高。虽然BP神经网络的标准偏差最接近实测值的标准偏差,但其偏差的位置及大小与实测值相差较大;换句话说,BP神经网络为“黑箱”评价模型,考虑了参数与干密度之间的不确定拟合关系,但是神经网络具有易陷入局部极小值等问题,故其精确度最低。虽然线性回归的MSE和MAE误差小,起伏分布趋势与实测值最为相似,但是线性回归为“白箱”预测模型,只考虑了全料含水率及P5含量对干密度的影响,忽略了料源参数存在的不确定性以及其它参数不可测的不确定性影响,使得线性回归的起伏分布振幅明显过小,其标准偏差与实测值差距最大。从图9可知,“黑箱”运算的随机森林模型考虑了料源参数不确定性,其求解结果具有最小均方误差1.72E-04且与实测值的拟合分布情况最佳。因此,基于随机森林算法的压实质量评价模型在全面考虑参数不确定性的条件下,评价结果更为准确,具有优越性。
综上所述,相较于常用的压实质量评价方法BP神经网络和线性回归,随机森林算法为“黑箱”拟合评价模型,该模型不仅可以处理大数据量的输入参数,考虑参数与干密度之间的不确定拟合关系,并且在考虑料源参数不确定性的同时,其求解结果具有最小的泛化误差。通过与BP神经网络和线性回归评价方法的评价结果对比分析表明,随机森林算法具有一致性、代表性和优越性。
5 结论
结合碾压实时监控系统,本文基于随机森林算法提出了考虑料源参数不确定性影响的压实质量动态评价模型。首先,分析了料源参数因取样措施等方面的缺陷而具有的不确定性,并利用信息熵对料源参数的不确定性进行量化,结果表明料源参数存在不确定性,从而证实了考虑料源参数不确定性影响的必要性,考虑料源参数的不确定性可以使压实质量评价结果更加全面和精确。其次,根据相关性分析结果确定了土石坝压实质量的主要影响因子,并且引入气象要素等作为压实质量评价新的影响参数,建立了考虑料源参数不确定性的土石坝全仓面压实质量评价模型,并基于随机森林算法进行求解,实现了土石坝心墙区压实质量的实时评价,为土石坝工程提供了有效的压实质量评价方法。最后,在实际工程应用中将基于随机森林算法的压实质量评价模型与常用压实质量评价模型(BP神经网络和线性回归分析)进行了对比分析,结果表明本文提出的模型能够考虑料源参数的不确定性,具有更高的评价精确度,并且求解结果也更加符合实测值的分布趋势。因此,基于随机森林算法的压实质量评价模型具有考虑料源参数不确定性影响的优势,与传统模型相比具有一致性、代表性和优越性。
猜你喜欢
法律方法(2022年2期)2022-10-20
车主之友(2022年4期)2022-08-27
建材发展导向(2021年19期)2021-12-06
文苑(2020年8期)2020-09-09
中国外汇(2019年7期)2019-07-13
震灾防御技术(2019年3期)2019-06-02
东坡赤壁诗词(2018年5期)2018-12-17
水电站设计(2018年1期)2018-04-12
系统工程与电子技术(2016年4期)2016-08-24
中国工程咨询(2016年12期)2016-01-29
