
视觉问答技术研究
2018-09-21 03:25俞俊汪亮余宙
计算机研究与发展 2018年9期
俞 俊 汪 亮 余 宙
(杭州电子科技大学计算机学院 杭州 310018) (复杂系统建模与仿真教育部重点实验室(杭州电子科技大学) 杭州 310018) (yujun@hdu.edu.cn)
近年来,随着社交网络的普及,图像和视频等视觉对象数据正在以前所未有的速度增长并广泛传播.如何有效地理解这些视觉对象的内容是一个基础问题.深度学习的成功使得我们可以使用深度神经网络模型对图像进行准确地物体识别和检测,对视频中的事件进行准确预测,然而,我们常说“一图胜千言”,我们通常无法使用简单的话语描述清楚图像或视频中所有的信息.在这样的背景下,如何使用交互式的方法,对视觉对象数据中信息进行有效地过滤,并以合理地形式呈现是一个亟需解决的问题.
在自然语言处理领域,问答(question answering, QA)系统在学术界和产业界都被广泛地研究.问答系统的目标在于设计合理的模型,对任意自然语言描述的问题,系统在充分理解输入问题后,使用自然语言自动进行准确地回答.由于问答系统在自然语言处理的成功,人们开始考虑将这种交互式的问答方式引入计算机视觉领域,对视觉对象进行交互式内容理解.在这样的背景下,视觉问答(visual question answering, VQA)被提出.该任务旨在输入一张任意的图像(或视频)和一个自然语言描述的问题,模型自动输出一个由自然语言描述的答案.由于涉及计算机视觉与自然语言处理2个领域的交叉研究方向,视觉问答受到广泛的关注,成为当前研究的热点之一.
目前已有相关工作开始关注视觉问答,例如跨模态融合的视觉问答架构,基于注意力机制的视觉问答模型等.然而这些模型与方法大多只关注某一视觉问答数据集下的表现,而较少关注真实场景下视觉问答所需的逻辑推理能力,针对视频内容的视觉问答等研究.因此,为了满足日益增长的视觉问答任务需求,就需要结合深度神经网络和知识网络的结构优势,提出一系列实用的视觉问答理论和方法,提升模型的通用性和计算效率.为此,本文在详细分析现有的视觉问答相关技术的基础上,进一步讨论现有的视觉问答方法研究的不足,最后分析视觉问答任务的未来研究方向及需要解决的问题.
本文的主要贡献有3个方面:
1) 详细阐述了视觉问答的相关研究现状;
2) 分析了现有视觉问答算法的不足;
3) 提出视觉问答技术的未来研究方向及需要解决的科学问题.
1 背景和意义
目前,互联网技术飞速发展随之产生的数据类型愈加丰富,“跨媒体”数据逐渐成为一种主流的数据形式.谷歌研究主管Norvig博士曾在2010年应《Nature》杂志邀请,对下一个10年科技进行展望的报告中写道:“搜索结果不再是展示网页,而是以图表来表示更为形象具体的综合性知识”.在这段文字中,跨媒体的重要性不言而喻.跨媒体数据通常由具有天然共生关系的不同模态、不同来源、不同背景的媒体数据来共同表达统一的语义信息.以社交平台上用户上传的图片为例,在用户的个人页面,图片周围常伴有文本数据(用户上传的文本描述和其他用户发表的评论等),往往这些文本与图像紧密相关.利用这种跨媒体数据间的天然共生关系可以增强对跨媒体数据的语义理解.国务院在2017年7月发布的《新一代人工智能发展规划》中,将跨媒体智能列为新一代人工智能基础理论体系中的重要组成部分.跨媒体智能的关键技术包括:跨媒体统一表征、关联理解与知识挖掘、知识图谱构建与学习、知识演化与推理、智能描述与生成等技术.
跨媒体统一表征是多媒体领域的一个重要研究方向,旨在打通不同媒体(如图像、视频和文本)之间的“语义鸿沟”,建立统一的语义表达.对于自然场景或实际生活中的图片,其包含的语义内容可能非常丰富,即使是人也很难仅使用一两句话就对整张图像内所有的内容进行准确地概括.使用算法自动生成的图像内容描述可能会和用户期望的结果出现偏差.同理,如果算法对图像内容理解存在歧义,在跨媒体检索任务中,输入图像查询返回的相关文本也不能反映真实的检索意图.由于多媒体数据本身语义的复杂性和多样性,在深度学习出现之前,该问题一直没有得到很好地解决.近年来,深度学习迅速发展并在各个研究领域上都取得了惊人的成果.使用不同架构的深度神经网络在计算机视觉、自然语言处理以及语音识别等方面都取得了目前最好的结果.例如深度卷积神经网络在图像和视频分类、物体检测、语义分割等任务中的性能大大超过了之前基于人工特征的方法;深度循环神经网络也在机器翻译、语音识别等领域数次刷新标准测试集上的最好成绩.深度学习使用复杂的神经网络模型对需要解决的任务进行端到端建模,输入为原始的数据(如图像的原始像素),输出为最终的任务结果(如图像分类、语义分割或机器翻译的结果).基于特定的损失函数,不同结构的神经网络模型(如CNN和RNN)被灵活地组合在一起,实现联合优化.这种特性可以用来学习跨媒体数据的深度统一表达.由于深度模型强大的语义表达能力,深度跨媒体统一表达模型成为目前的主流方法.
在深度跨媒体统一表达的理论基础上,衍生出一些目前热门的分支方向,如跨媒体检索(cross-media retrieval)、视觉描述(visual captioning)以及视觉问答(visual question answering)等.跨媒体检索旨在给定一种媒体数据从海量数据库中找到最匹配的另一种媒体的相关数据;视觉描述的目标是给一张图像使用一句或几句自然语言对其内容进行有效概述.这些任务中,视觉问答涉及使用计算机视觉技术理解视觉媒体和使用自然语言处理技术理解问题文本,同时还需要结合两者进行深度知识挖掘与推理才能有效回答问题.传统上计算机视觉和自然语言处理领域分别使用不同的方法和模型来解决各自的问题,所以视觉问答相对而言更有挑战性.
针对不同视觉对象(图像、视频等),视觉问答的任务和算法也不尽相同.如图1所示,图像问答的任务目标是在给定一张图像的同时,通过一个由自然语言描述的查询条件来限定对图像的关注内容,并对图像进行细粒度地理解,输出满足查询意图的答案.视频问答的任务目标在于输入一段视频和一个自然语言描述的问题,算法基于该视频内容自动输出一个自然语言描述的答案.答案可以是以下任何一种形式:单词、短语、是/否判断、填空或多项选择.视频数据是更为复杂的一种大规模视觉数据,它可以看成是由图像序列、语音、文本形成的复合海量数据,对视频数据的内容理解需要同时考虑多视角、多模态等特性,以及视频语义在时序上的连续性和关联性.

Fig.1 Visual question answering sample diagram图1 视觉问答样例示意图
在实际应用方面,视觉问答算法具有非常广泛的应用前景.基于文本或语音的对话式问答系统已经作为一种人机交互的重要方式,被广泛应用在移动终端和PC的操作系统中,如苹果的Siri、微软的Cortana、亚马逊的Alexa等.随着可穿戴智能硬件(如Google glasses和微软的HoloLens)以及增强现实技术的快速发展,在不久的将来,基于视觉感知的视觉问答系统可能会成为人机交互的一种重要方式,改变人们当前的交流模式.这项技术的发展可以帮助我们,尤其是那些有视觉障碍的残障人士更好地感知和理解真实世界.
综上所述,视觉问答算法是一个值得深入研究的方向,本文对现有的视觉问答算法进行调研与分析,探讨现有视觉问答算法的不足,并结合深度网络模型优势,提出视觉问答算法的未来研究方向以及需要解决的科学问题.
2 国内外研究现状
近年来,跨媒体数据理解与分析一直是国内外的研究热点.国内的研究机构,如中国科学院、清华大学、北京大学、浙江大学、复旦大学,国际的研究机构,如卡耐基梅隆大学、加州大学伯克利分校、斯坦福大学等,形成了各具特色的研究成果.以跨媒体统一表达理论为基础,衍生出一系列目前重要的分支方向,如跨媒体知识推理和迁移[1-3]、语义理解[4-8]、排序与检索[9-13]、图像与视频自然描述生成[14-16]等.斯坦福大学人工智能实验室主任李飞飞教授提倡的“视觉基因组”(visual genome)计划中,跨媒体描述和问答是其中的主要内容.微软研究院启动的“语境中的公共对象”(COCO)项目中,基于图片视觉信息的跨媒体描述和问答也成为其中重要任务之一.

Fig.2 Current status of visual question answering task algorithm图2 当前视觉问答任务算法发展现状
视觉问答任务作为跨媒体研究方向上一个新兴的分支,其重要性和吸引力在于它结合了计算机视觉和自然语言处理领域.近年来,深度学习研究的迅猛发展,深度神经网络模型已经成为解决计算机视觉任务的常用方法.图2所示为当前视觉问答任务算法的发展现状.众所周知,深度学习的发展离不开数据驱动,在设计复杂的算法来组织多媒体数据时,优质的大规模数据集能显著提升模型的通用性和鲁棒性.根据输入视觉对象的类型划分,视觉问答任务可分为图像问答和视频问答.图像问答算法主要分为粗粒度跨媒体表达的图像问答模型、基于注意力机制的细粒度跨媒体表达模型和基于外部知识或知识网络的图像问答模型3类.由于视频数据本身的复杂性,视频问答算法目前研究还较少.视频中包含了有序的图像序列,因此解决视频问答不仅需要理解视觉内容,还需要兼顾视觉对象在时序上的相关性.现有的视频问答模型主要根据基于注意力机制的图像问答模型拓展得到.
本节将分别从视觉问答数据集、图像问答和视频问答这3个方面对现有的研究工作进行详细的介绍和分析.
2.1 相关数据集
近几年出现了8个大型的面向视觉问答任务的数据集.由于大多数现有的视觉问答算法是基于数据驱动训练模型,良好的数据集有助于训练出更具有泛化能力的模型.表1所示为各大数据集摘要内容,下面对他们一一进行介绍.

Table 1 VQA Datasets表1 视觉问答数据集介绍
1) 2015年发布的DAQUAR[17]是第1个针对视觉问答任务发布的数据集,它取自包含图像及其语义分割的NYU Depth Dataset V2数据集.这些图像均为室内场景且每张图像都被多个标签标记.基于图像的问题与答案组合由2种方式生成:①定义若干问题模板,根据图像标签自动生成问答对;②使用人工标注,由志愿者回答自动生成的问题.DAQUAR的缺点很明显,问题语句不够明确流畅,图像类型过于单调且数据量较少.因此,使问题语句更准确,提高图像数量和多样性是视觉问答任务制作数据集的目标之一.
2) Visual7W[18]是基于微软COCO数据集的图像生成的视觉问答数据集.与之前的方法不同,Visual7W中的问题也由人工生成,且由若干志愿者对生成的问题进行评分以去除质量较差的问题.与此同时,数据集还包含人工标注的问题相关实体的边界框作为参考来解决问题文本的模糊性问题.可以看出,Visual7W部分改善了DAQUAR存在的问题,但还存在问题类型不够多样等缺点.
3) Visual Madlibs[19]是一个基于微软COCO图像生成的包含填空和多项选择问题的数据集.其填空问题根据图像标签由模板自动生成并使用人工回答问题,答案可以为单词或短语.
4) COCO-QA[20]也是由微软COCO数据集中的图像制作.其问答对是根据图像描述自动生成的,主要包括4类主题:物体、数量、颜色和位置.该数据集的特点是每张图像只有一个问题且答案只能为单个单词.所以存在问题类型较少和回答内容较简单的缺点.
5) FM-IQA[21]数据集从微软COCO数据集中获取图像,并由人工生成问答对.其回答可以是单词、短语或完整的句子.值得一提的是,该数据集的问答对有中文和英文2个版本.
6) VQA[22]数据集是在视觉问答任务中使用最为广泛的数据集.它的图像内容丰富,既来源于基于真实场景的微软COCO数据集又包含由人和动物模型创建的抽象剪切画场景图片.数据集中的问题和答案均由人工生成,其中判断题约占四成且每张图片对应多个问答对.该数据集现为视觉问答竞赛的标准数据集.图3所示为2018年视觉问答竞赛目前公开排行榜得分.可以看出,该任务的得分相较于2017年冠军和2016年冠军的结果有了明显的提升,说明该领域的研究正在迅速发展.
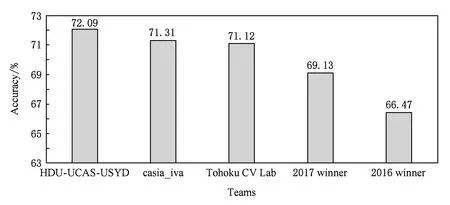
Fig.3 The accuracy of VQA Challenge 2018 leaderboard and comparison with the past champions图3 2018年视觉问答竞赛排行榜及与历年最好结果精度对比
7) CLEVR[23]数据集不同于其他数据集,它是针对视觉问答中的推理问题而构建的.数据集中的图像大多为一些简单的几何体而问题为复杂的逻辑推理题.CLEVR数据集有详细的注释,描述每个问题需要的推理类型.
2.2 图像问答
图像问答算法(image question answering, IQA)是Malinowski等人在2014年首次提出的[24],旨在使用跨媒体统一表达理论与方法解决普适环境下的人机交互问题.最初,他们对图像数据使用语义分割(semantic segmentation)算法得到图片内的主体和对应的区域,再通过贝叶斯算法将图像分割后的区域与经过语法解析后的问题关联,进而预测答案的概率.但该方法有个明显的缺陷,即只能回答数据集中已存在的问题,无法回答任意输入的开放性问题(open-ended questions),这大大限制了该图像问答算法的实用性.因此,后续的研究基本聚焦在开放性问题下的图像问答算法(open-ended image question answering, OE-IQA),并形成了许多经过机器生成或人工标注的包含不同场景图片以及不同问题种类的图像问答标准评测数据集,如DAQUAR[17],Visual 7w[18],Visual Madlibs[19],COCO-QA[20],FM-IQA[21],COCO-VQA[22],FVQA[25].这些标准评测数据集可用于衡量不同图像问答算法的性能.
按照方法分类,现有的图像问答算法可大致分为3类:1)粗粒度跨媒体表达的图像问答模型;2)基于注意力机制的细粒度跨媒体表达的图像问答模型;3)基于外部知识和知识网络的图像问答模型.将从这3个方面对国内外研究现状进行分析.
1) 粗粒度跨媒体表达的模型是图像问答算法中最基础的一类,通常被用来作为对照的基线算法.在该模型中,图像问答任务被视为一个多类别分类任务,即通过给定“图像-问题-答案”这样的三元组训练数据,将用于提问的图片和问题文本输入模型抽取高维特征,并使用特征融合策略把问题和文本特征融合为跨媒体表达特征,再将所有候选答案都作为一个相互独立的类别.最后使用线性或多层感知机(multi-layer perceptron, MLP)模型作为分类器,输出预测的答案.在此基础上,不同的特征表达方式、融合策略以及答案预测模型形成了一系列有特色的研究工作.
Zhou等人[26]使用GoogLeNet网络[27]抽取图像至全连接层的输出特征,使用最基本的词袋模型对自然语言描述的问题进行表征.再通过拼接这2种特征来形成图像-问题的跨媒体表达特征,使用Softmax损失函数训练一个线性分类器来预测答案.Kafle等人[28]使用152层的残差网络[29]来抽取图像特征,使用词向量(word vector)特征[30]对问题文本表征,并使用2层的MLP模型代替线性分类器来进行答案预测,在多个数据集上都取得了不错的结果.
一些图像问答方法希望学习文本中词与词在时序上的关联关系,尝试使用循环神经网络模型(尤其是带有记忆单元的循环神经网络结构,如长短时记忆模型(LSTM)[31]和门控制循环神经网络(GRU)[32])对问题进行特征表示,得到问题的细粒度语义特征.此外,MLP模型可与循环神经网络整合形成一个更大的网络,使得问题的特征也可以基于网络的端到端训练得到优化.例如Antol等人[22]将问题中每个词表达成One-Hot的向量,输入至LSTM网络,输出问题的表达特征,并使用GoogLeNet网络[27]将对应的图像表达成相同维度的特征.然后对2个特征进行哈达马乘积(Hadamard product),即矩阵对应维度值的点乘操作,将融合后的跨媒体特征输入给MLP模型进行答案预测.文献[20-21,33]相继提出了几种基于编码器-解码器框架的LSTM网络结构来解决图像问答问题.Noh等人[34]提出在抽取图像特征的卷积神经网络卷积层和全连接层之间插入一个“动态参数层(dynamic parameter layer)”的方法来解决图像问答问题,其中动态参数层的参数对应输入的问题经由GRU网络的输出表示.Kim等人[35]借鉴了残差网络的思想,提出了一种多模态残差网络(multi-modal residual networks, MRN)来对图像的CNN特征和问题的GRU特征进行深度融合.Fukui等人[36]提出了一种“多模态紧凑双线性池化(multi-modal compact bilinear pooling, MCB)”的方法来更好地描述不同特征维度之间的关联关系,进行深度跨媒体特征融合,获得了较好的结果.在文献[29]的基础上,Kim等人[37]改进了MCB算法,提出了一种“多模态低秩双线性池化(multi-modal low-rank bilinear pooling, MLB)”的方法,用更少的参数和计算量达到了和MCB类似的结果.Yu等人[38]借鉴了双线性池化的思想,提出了一种“多模态分解双线性池化(multi-modal factorized bilinear pooling, MFB)”的特征融合方法,在输出特征维数相同的情况下,MFB的表示能力比MLB更强.Ma等人[39]提出“多模态CNN网络(multi-modal CNN)”的结构使用CNN网络分别对问题和图像进行特征表达,然后对2个CNN输出的特征进行跨媒体融合,将融合后的特征进行联合网络训练.
综上所述,粗粒度跨媒体表达模型是一类最直接的图像问答模型.其中,跨媒体特征融合方法是这类模型的核心.从目前的研究现状可以看出,最新的一些方法,如MFB和MRN等,在引入复杂的融合模型后,在图像问答任务上的性能有了显著的提升.目前针对提高图像问答模型计算效率的研究并不多见.因此,研究如何在保证有效的特征融合情况下降低计算开销的算法是图像问答中一个重要的发展方向.
2) 当粗粒度跨媒体表达模型在处理内容相对复杂,存在很多主体的图像时,会不可避免地引入较多噪声,这些噪声会影响算法对答案的预测.问题文本的处理也同样存在这个的问题,当问题语句较长且存在多个与图像相关的词汇时,算法很难捕捉到提问者期望的关键词.因为一张图像能够对应许多问题,所以我们希望算法能先学习到图像中和问题语义相关的局部区域的特征,再和问题文本的特征融合进行跨媒体表达并预测答案.注意力模型(attention model)就是能处理这类问题的模型,最早由Xu等人[40]提出并应用在图像自然描述生成(image captioning)的应用中,注意力模型也被应用在自然语言处理领域,例如基于端到端的机器翻译任务[41].相比于没有施加注意力模型的方法,使用注意力模型的方法显著提升了实验结果.
Xu等人[42]提出了一种“问题引导的关注图(question-guided attention map, QAM)”的模块,将问题文本经过LSTM网络的输出特征处理形成卷积核,然后与处理图像的CNN网络输出的细粒度特征图(feature map)特征进行卷积操作后得到图像上空间区域上的关注图,并基于关注图的权重提取图像的局部特征,和问题的特征融合后预测答案.文献[43-45]相继提出一种“层次化图像关注图(hierarchical image attention map)”对不同级别的问题特征,如词、句子、短语等进行层次建模,分别形成关注图、结构化多层次的问题特征.文献[46-47]引入物体检测(object detection)的算法提取图像中出现的实体作为候选关注点,并基于问题的特征学习得到最终的关注图.文献[36-37]中提出的MCB和MLB方法在添加了注意力机制的模块后,对比基线模型显著提升了准确率.Anderson等人[48]使用目标检测网络得到图像内多个局部实体特征并将其作为图像特征输入,结合含注意力模块的深度神经网络,提升了模型的准确率与结果的可解释性.Yu等人[38]在问题和图像子网络分别添加了多个注意力模块,并联合2个子网络以增强图像特征与问题特征间的联系,极大地提高了基础模型的结果.文献[49-51]提出使用模块化单元构建神经网络来解决图像问答的问题.不同的模块化单元可以用于处理不同类型的问题.通过对问题文本的分析,搭建一个针对该问题的神经网络可以提升模型的可解释性,并且模块复用能有效减少冗余的参数量.
粗粒度跨媒体表达模型在引入注意力机制后,得到的细粒度跨媒体特征的表达能力大大提升,实验结果在图像问答的若干标准数据集上也都有了显著地提升.然而,目前图像问答模型中使用的注意力模型大多是基于问题的特征学习图像的关注区域,而忽略了问题特征本身的关注点学习,即学习问题中的关键词或短语.真实场景中包含大量经口语化描述的问题,如果不考虑问题特征上的关注点学习,会因为大量的噪声导致最终不能学习稳定的图像问答模型.
3) 上述图像问答模型的研究主要关注在图像和问题的统一表达和特征融合方法上,较少涉及挖掘问题中的潜在语义信息以及利用现有知识网络中的知识.例如,要想正确回答“图片中有多少动物?”这个问题,算法必须对“动物”的概念以及哪些类别的实体属于“动物”有明确的认识.如何利用已有的各种大规模知识网络,如DBpedia[52],NELL[53],Visual Genome[54],ImageNet[55]等,以便更好地理解问题,提升图像问答的结果,是一个非常有意义的研究方向.
Wang等人[56]提出了一种名为“Ahab”的图像问答框架,引入DBpedia知识网络来辅助理解图像中的语义和问题之间潜在的关联关系.但该方法需对文本进行特定格式的语法解析,故只能处理特定类型的问题,具有一定的局限性.此外,由于算法在引入知识网络后无法和基于跨媒体表达的图像问答算法进行公平的对比,因此需要构建了一个知识网络相关的图像问答数据集才能对算法的性能进行评价.Ray等人[57]引入了一个人工标注的数据集对问题和图片中的内容的相关度进行评估,让算法可以理解哪些问题是可以被回答的,哪些是无法回答的,提高图像问答算法的泛化能力,不至于被那些“过难”的问题影响.Wu等人[58]将知识网络的内容引入跨媒体表达图像问答的框架中,从图像中抽取“语义属性(semantic attributes)”,与知识网络中的知识形成关联,进而使用词向量技术形成固定长度的“知识向量”,在对问题特征进行融合后形成跨媒体统一表达,输入分类器预测答案.
基于外部知识和知识网络的图像问答模型的难点在于现有模型不易将外部知识同图像问答数据集上所有的问题映射,只能解决部分类型的问题,缺乏普适性.目前该类图像问答方法的评测一般是在特定的数据集上进行.因此,如何设计一种更通用的使用外部知识的策略是这类图像问答方法的一项重要的研究内容.此外,目前已有的方法大多使用训练集合中高频的答案作为候选集,并把这个任务形式化表达为多类别分类问题,使用图像-问题形成的跨媒体表达特征,训练一个分类器进行答案预测.但是这类解决方案的不具备较好的扩展性,即学习到的分类模型只能预测数据集中已出现过的答案,面对不同环境下的视觉问答任务,需要使用新的数据集重新训练模型.因此,如何设计一种能支持预测模型在不同数据集上(新的答案集)的增量式更新的策略是一个需要深入研究的问题.
综上所述,如何对不同模态的特征进行有效的融合、如何对图像和问题之间的“共同关注点”进行有效地理解与建模以及如何利用已有的外部知识或知识网络来更好地理解图像的语义以及问题的意图来提升图像问答算法的性能亟待进一步研究.
2.3 视频问答
视频问答任务的难点在于其兼顾视频数据理解和视觉问答这2个方面.其中,理解视频内容是解决视频相关问题的基础.视频内容理解的过程中,首先需要理解视频中每一帧图像的内容.当前图像内容理解的相关研究主要以图像分割和目标检测为主.当前图像分割方法大致可分为基于阈值的分割方法[59]、基于边缘的分割方法[59-60]、基于区域的分割方法[59,61]、基于图论的分割方法[62]以及基于能量泛函的分割方法[63]等.
基于图像分割的目标检测一直是计算机视觉的研究热点.如今,目标检测技术在人脸和行人检测方面的研究已经较为成熟.2012年前,目标检测中分类任务的框架就是使用人为设计的特征训练浅层分类器完成分类任务.Viola等人提出基于AdaBoost算法框架[64],使用Haar-like小波特征分类,然后采用滑动窗口搜索策略实现准确有效地定位.Dalal等人提出使用图像局部梯度方向直方图(HOG)作为特征,利用支持向量机(SVM)作为分类器实现行人检测[65].Felzenszwalb等人[66]提出了多尺度形变部件模型(DPM),继承了使用HOG特征和SVM分类器的优点.后续工作采用不同策略加速了DPM的穷尽搜索策略[67-69].
2012年,Krizhevsky等人[70]提出基于深度卷积神经网络(DCNN)的图像分类算法,使图像分类准确率大幅提升,同时带动目标检测准确率的提升.Szegedy等人[71]将目标检测问题看做目标mask的回归问题,使用DCNN作为回归器预测输入图像中目标的mask.Erhan等人[72]使用DCNN对目标的包围盒进行回归预测,并给出每个包围盒包含类别无关对象的置信度.R-CNN[73]采用选择性搜索策略而不是滑动窗口来提高检测效率.R-CNN利用选择性搜索方法在输入图像上选择若干候选包围盒,对每个包围盒利用CNN提取特征,输入到为每个类训练好的SVM分类器,得到包围盒属于每个类的分数.最后,R-CNN使用非极大值抑制方法(NMS)舍弃部分包围盒,得到检测结果.上述方法使用的DCNN结构基本源自Krizhevsky的7层网络结构设计,为了提高DCNN的分类和检测准确率,Simonyan和Szegedy等人分别设计了层数为16层和22层的深度卷积神经网络VGGNet[74]和GoogLeNet[27],采用的检测框架都类似R-CNN.目前,深度卷积神经网络是多个目标类别检测数据集上的最优模型.
当我们抽取视频中图像并分割得到目标实体后,为了更好地理解视频内容,我们希望能够得到不同实体在视频流中的运动发展趋势.因此,运动目标跟踪成为视频内容理解的一个重要基础.当前的运动目标检测的方法主要包括:背景差分法、帧间差分法和光流法.
综上所述,目前常用的视频语义理解框架是使用静态图像和动态光流输入的双路深度卷积神经网络模型,将视频表征为高维特征向量.
视频内容描述(video captioning)是与视频问答相似的任务,旨在生成描述视频内容的句子.文献[75]从视频中采样若干个帧并将其输入卷积神经网络抽取特征.之后,均值池化所有特征输入长短时记忆网络.模型将根据视频特征和上一个单词,每一个时间步输出一个单词,直到输出句尾标记.Zanfir等人[76]提出在关注视频中时空对象的基础上,将其与最新的图像分类器、目标检测器、高级语义特征(SVO)集成,并使用循环神经网络生成视频内容描述.Yao等人[77]使用三维卷积神经网络,提出一种新型结构来捕捉视频中的时空信息.文献[78]提出了一个增强记忆的注意力模型,该模型利用过去的视频记忆来思考当前时间步中要关注的位置.
视频问答时一个相对较新的任务.Zeng等人[79]首先根据现有的视觉描述和图像问答模型拓展出基于深度学习的视频问答架构.这项工作简单地扩展了其他任务的现有模型,如视频内容描述和图像问答.所有的扩展模型都使用长短时记忆网络提取问题特征,但所提取的特征比较粗糙,缺乏对关键词的关注,所以缺少对问题文本的关注能力.并且该方法将抽取出的视频与问题特征通过原始平均池化的方式融合,缺乏对跨媒体特征的细粒度理解.文献[80-82]将注意力机制引入视频问答架构中,并逐步优化模型,提升了视频问答的结果.Yu等人[83]使用语义注意力机制,将经编码-解码后的文字与视频结合生成回答.文献[84-85]利用时间注意力机制来选择性地关注视频中的某些时间段.Na等人[86]和Kim等人[87]在视频问答模型中引入了记忆力机制,然而他们的模型缺乏运动分析和动态的记忆更新机制.
综上所述,已有的视频问答框架采用卷积神经网络与双向长短时记忆网络分别对视频与文本进行特征抽取与语义映射,并重点采用注意力机制优化算法.但是目前的研究尚缺少对视频数据的多模态和多尺度特性的关注.因此,如何对视频进行多模态信息整合来形成层次化语义表征是一个关键问题.
3 未来研究方向
由于自然场景下的图像内容复杂、主体多样,自然语言描述的问题和答案自由度高,这使得对图像和问题内容的理解、统一表达,并基于表达后的结果进行有效地预测答案成为一项具有挑战性的任务.具体而言,未来的研究方向可能从图像中实体内在的相关性与深度跨媒体模型结构设计结合、视频问答模型的综合优化以及提升视觉问答计算效率并使之应用于移动端等轻量级开发平台这些方面研究视觉问答中的逻辑推理、基于外部知识和数据联合驱动的视觉问答系统、视频问答视觉问答移动端的发展等问题.
3.1 视觉问答中的逻辑推理
让计算机学会逻辑推理是实现通用人工智能的必由之路.从人类的角度出发,我们很清楚逻辑推理的过程通常需经过连贯的多步思考来得出结果.当前大多数的视觉问答模型并没有办法通过端到端的训练来具备推理能力,仅适合回答单步思考的直观问题(如雨伞是什么颜色的?),而不适合回答需多步思考的逻辑推理问题.(如长方体和球体的数量相同么?)目前,主流的推理过程是基于分布式表示的知识表示学习方法完成的.该方法将实体、概念和他们之间的语义关系表征为高维空间中的向量或矩阵,再经过数值计算完成推理过程.但这类推理方式难以实现知识的深度推理,现在尚不能满足实用的需求.因此如何将已有的基于分布式表示的数值推理结合深度神经网络,构造一个可解释的具备逻辑推理能力的模型是未来视觉问答问题的发展方向之一.
该问题的难点在于如何将逻辑推理模块和视觉问答模块融合在一个框架下表达.由于这2个模块之间本身相对独立,通常无法直接使用进行端到端优化.近年来,随着强化学习在计算机视觉领域的发展,人们尝试构建模块化的神经网络,使用策略梯度(policy gradient)来连接不可导的2个网络.如何在视觉问答任务中有效地利用该思想,使用神经网络模块化并结合强化学习方法进一步提升模型在逻辑推理能力是一个值得深入研究的问题.
3.2 基于外部知识与数据联合驱动的视觉问答系统
当前的视觉问答模型往往只关注图像视频数据集内的实体信息.在视觉问答任务中,并非所有问题的答案都能直接找到,由于语料库或知识网络的内容本身的覆盖度有限,故需通过调用外部知识来获取答案.面对互联网海量的图像视频数据,实体与实体间往往存在一定的相关性,合理整合这些相关性,可以提升视觉问答模型对问题和图像的理解能力,从而提升模型的准确率.例如图4所示为一张奥运会颁奖仪式的照片,问及“图中站着的是哪个国家的选手?”,图像知识库中可能包括了各个国家对应国旗的样式或各国运动员队服的资料,从而模型能通过关注相应的区域得到问题的答案.因此,近些年来,无论是学术界或工业界,研究者们逐步把注意力投向外部知识.其目标是把互联网文本内容组织成为以实体为基本语义单元(节点)的图结构,其中图上的边表示实体之间语义关系.视觉问答中可用的外部知识中可能包括实体大小位置等一元信息和实体间属性类别等二元信息.利用一元信息可以增强模型对图像中实体的理解,利用二元信息可以提升模型对整张图像实体相互关系的理解.合理利用外部知识能够提高视觉问答任务的效率和性能.所以如何发挥数据驱动的优势联合外部知识(如语义、大小和位置等)提升视觉问答任务的结果是当前研究的难题.

Fig.4 Photos of the Olympic awards ceremony图4 奥运会颁奖仪式的照片
目前已有的大规模知识网络提供给了丰富的语义层次信息.利用这些层次信息训练自然语言处理模型能将词汇聚类,增大不同类别词汇的向量距离,减小相同类别词汇的向量距离,产生更优质的问题文本映射,从而显著提升视觉问答模型的性能.未来如何将数据与知识更深入的耦合在一起,从2个方向协同的推理将会是人工智能推理系统潜在的研究方向.
3.3 视频问答
相比于图像问答,视频问答因为视觉数据本身的复杂性,使得该问题一直没有被很好地解决,分析原因,可以将其难点归纳为3个方面:
1) 复杂视频语义理解.视频媒体相比于其他多媒体数据,如图像、语音、文本等,它包含更复杂的语义信息,同时也包含更多的噪声.目前对视频内容进行特征表达的最有效的方法是使用卷积神经网络模型,用基于数据驱动的方式端到端学习视频深度表征.该方法尽管在一些视频内容理解任务(如视频分类、事件检测等)上取得较好效果,但仅限于语义较为简单的短视频,难以实现对包含复杂语义的长视频进行有效语义理解.因此,如何有效利用一些除了视觉信息外的天然多模态辅助信息(如伴随文本、语音等),提升复杂场景下视频语义理解精度是一个难点问题和主要研究方向.
2) 视频问答依赖先验知识.视频问答相比于别的跨媒体应用,如跨媒体检索或视觉描述,需要更为复杂的知识推理过程,这就需要引入外部知识网络.现有的知识网络往往是针对自然语言理解任务,并不适用于视频问答这样的跨媒体任务.因此,如何有效构建适合视频问答任务的跨媒体知识网络,以及如何基于构建的跨媒体知识网络进行跨媒体知识推理,从而提升视频问答的性能是一个难点问题和研究方向.
3) 外部信息和数据共同驱动下的视频问答模型.现有的视频问答模型大多基于特定领域数据训练得到的深度神经网络,泛化能力较弱.如何将2)中构建的跨媒体知识网络引入视频问答模型中,形成数据和知识共同驱动的视频问答模型,以提升视频问答方法的准确性和泛化能力是一个难点问题和研究方向.
3.4 移动端视觉问答的发展
卷积神经网络是现代视觉人工智能系统的核心组件.近年来关于卷积模型的研究层出不穷,产生了如VGG[74],ResNet[29],Xception[88]和ResNeXt[89]等性能优异的网络结构,在多个视觉任务上超过了人类水平.然而,这些成功的模型往往是以巨大的计算复杂度(数十亿次甚至更多浮点操作)为代价的.这导致这些模型只能运行在高性能的计算设备(如带有NVIDIA显卡的服务器),而无法在移动端硬件(通常最多容许数百万至数千万次浮点操作)实时运行.因此,需要研究能够在维持现有模型准确率的情况下,降低计算复杂度,提高模型运算效率或吞吐量的方法.
跨媒体神经网络的研究离不开基础网络模型的支持.大部分需理解语义信息的计算机视觉任务(如目标检测、物体识别等)都使用一个优质的基础网络模型作为特征提取器.在移动设备发展突飞猛进的当下,在其之上运行的视觉算法模型会越来越多、准确率要求也将越来越高.好的基础模型可以让此前无法在移动设备上高效运行的算法降低计算需求,从而降低视觉算法和应用的落地门槛.因此,研究在不牺牲模型准确率的基础上降低计算复杂度的基础网络,有助于视觉问答任务在移动端的应用.
4 总 结
本文针对视觉问答任务,首先详细分析了现有的视觉问答相关算法和技术,并进一步讨论了现有视觉问答算法研究的不足,最后分析了视觉问答任务未来的研究方向及需解决的科学问题.
猜你喜欢
——评《交互叙事与跨媒体叙事:新媒体平台上的沉浸式故事创作》
新闻爱好者(2022年9期)2022-10-14
北京航空航天大学学报(2022年8期)2022-08-31
中学生数理化(高中版.高考数学)(2022年3期)2022-04-26
初中生世界·七年级(2019年5期)2019-06-22
当代陕西(2019年10期)2019-06-03
出版广角(2017年7期)2017-06-02
长江学术(2016年4期)2016-03-11
人间(2015年21期)2015-03-11
长江学术(2015年1期)2015-02-27
出版广角(2014年1期)2014-02-17
