
带时间窗偏好的多行程模糊需求车辆路径优化
2018-11-12 10:26张晓楠范厚明
计算机集成制造系统 2018年10期
张晓楠,范厚明
(1.陕西科技大学 机电工程学院,陕西 西安 710021; 2.大连海事大学 交通运输工程学院,辽宁 大连 116026)
0 引言
车辆路径问题(Vehicle Routing Problem, VRP)是运筹学和组合优化领域的热点问题,为了使其更贴近实际,研究了VRP的各类扩展问题[1]。模糊需求车辆路径问题(VRP with Fuzzy Demands, VRPFD)是在VRP的基础上考虑客户需求符合模糊特征且确切需求信息往往在车辆到达客户点时才能获知的情况,在应急物流、邮递等领域具有应用价值[2]。
两阶段法是求解VRPFD的常用方法,即在客户需求未明情况下先设计一个预优化方案,当车辆按预优化方案逐一到达客户并获知客户的实际需求后,可能发生实际剩余车载量不足够服务该客户的情况,为避免预优化路径失败,对车辆是否需要返回配送中心补货进行实时调整[3]。相关研究从两方面进行:①构建预优化模型,例如Teodorovic等[4]运用模糊推理求解;Luci等[5]运用模糊集合求解;张建勇等[6]运用模糊可能性理论求解;曹二保等[7]运用模糊可信性理论求解;王连峰等[8]为避免可信性理论中置信水平的影响,建立失败事件的模糊期望值模型。②提出实时调整策略,Teodorovic等[4]提出一种基于失败点返回的调整策略,以发货为例,定义车辆按计划路径服务某一客户j后的实际剩余车载量为Qj,当Qj<0时标记j点成为失败点,车辆服务j点后返回配送中心补货,再回到j点服务剩余需求,继而服务剩余客户;实际上,依据三角形三边原理,在失败点的前序点返回一定比在失败点返回更优,为此Yang等[9]以随机需求VRP为例更改Qj<0的判断,即当Qj小于等于下一客户需求期望值时,车辆立即返回配送中心补货,但实验发现,该策略虽能降低失败点出现的概率,却可能增加不恰当的返回次数,造成运力浪费和成本增加;之后,张晓楠等[10]通过平衡失败点出现概率和车辆返回次数提出“基于调整成本期望值”的实时调整策略用于调整VRPFD。
然而,无论构建预优化模型还是提出实时调整策略,现有研究均假设车辆在预优化阶段只能从配送中心出发一次,完成配送后回到配送中心,不允许中途返回补货,而在实时调整阶段却允许车辆中途返回补货后继续服务。若定义车辆从配送中心出发后回到配送中心为一次行程,即预优化阶段的车辆单行程行驶方案可能会在实时调整阶段调整为多行程行驶方案。现实中的很多VRP存在允许车辆多行程行驶的情况,属于多行程VRP(Multi-trip VRP, MVRP)范畴。目前一些学者已在静态环境下证明多行程可有效减少车辆数量,降低发车成本,提高配送服务水平[11]。
为使VRPFD更贴近现实情况,获取更优的配送方案,本文基于前期文献[10],开放车辆行程限制,同时考虑客户的时间窗偏好,研究带时间窗偏好的多行程模糊需求车辆路径问题(Multi-trip VRP with Fuzzy Demands considering Time Window preference, MVRPFDTW),侧重MVRPFDTW的预优化模型构建和实时调整策略提出。为简化管理决策难度,确保司机对行驶路线和服务客户的熟悉度,这里的实时调整策略同文献[4,9-10]一样,假设车辆不改变计划方案安排好的客户集合和服务顺序。
相对于VRPFD,MVRPFDTW的求解存在以下难点:①车辆的计划路径可能包含多个起止于配送中心的单行程,每个客户只能由一辆车的一个行程服务一次,且在每个行程开始时,车辆容量还原,时间花费不还原;②对于包含多个行程的计划路径,在实时调整阶段,如何看待这些已计划好的返回点。③在考虑时间的前提下,车辆返回配送中心补货可能同时导致配送长度增加和客户到达时间延迟,因此实时调整成本不仅包括额外配送成本,还包括时间延迟成本。
1 问题描述及模型建立
1.1 问题描述
MVRPFDTW是在基本VRPFD基础上开放车辆行程限制,同时考虑客户时间窗偏好,解决的是确定一个满足客户模糊需求和时间窗偏好的车辆多行程计划路线和实时调整方案,使物流成本最低且客户总体满意度最高。开放车辆行程限制可描述为允许车辆多行程行驶,定义车辆从配送中心出发返回配送中心为一次行程,每辆车仅有一条服务路线,每条服务路线可包含多个起止于配送中心的单行程,每个客户只能由一辆车的一个行程服务一次。客户时间窗偏好可描述为客户存在期望服务时间窗和最大容忍时间窗,在期望时间窗内被服务的客户满意度为100%,随着服务时间与期望服务时间窗差距的增大,客户满意度降低,不允许在最大容忍时间窗外服务客户。


1.2 预优化模型
为解决“在每个行程开始时,车辆容量还原,时间花费不还原”的问题,模型添加决策变量的行程维度,令车辆容量按单行程核算,客户到达时间按多行程累加计算。为保证客户整体满意度,同时有利于在后续实时调整阶段核算时间延迟成本,定义客户满意度为到达时间隶属度函数[12],并设置目标函数为最小化物流成本和时间成本的总和。
具体预优化模型如下:
(1)
s.t.

(2)
∀i∈V,∀k∈K,∀r∈R;
(3)
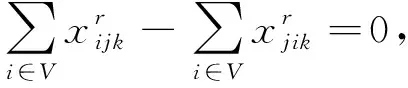
∀k∈K,∀r∈R;
(4)

(5)
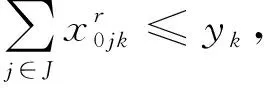
(6)
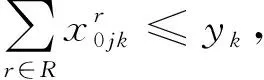
(7)

(8)

∀k∈K,∀r∈R;
(9)
∀k∈K,∀r∈R;
(10)

(11)
∀k∈K,∀r∈R1;
(12)

(13)
∀i∈V,j∈J,k∈K,r∈R;
(14)
yk∈{0,1},∀k∈K;
(15)

(16)
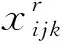
(17)
(18)

1.3 实时调整策略
为解决“实时调整阶段如何看待计划路径中的返回点”的问题,先列举两个简单例子说明。
例1以图1b中车辆1的可能计划路径为例(如图3a),设车辆容量限制CV=200,各点间距离和实际需求如表1所示。基于文献[4]的调整结果为图3b,路径长度为135;基于失败点前序点返回的调整结果如图3c所示,路径长度为125,优于图3b,原因在于c34+c40>c30必定成立;另外,从图3d所示的调整方案来看,路径长度为115,优于图3c,原因在于该网络中c23+c04>c20+c34。综上认为,“在失败点的前序点返回”的调整策略优于文献[4]的失败点调整策略,但仍未能实现最优调整,“提前柔性选择返回点”可能效果更好。
例2以图1b中车辆2的计划路径为例(如图4a),各点间距离和实际需求如表2所示(列举S1和S2两种场景)。S1情况下,若固定计划返回点,最优

调整如图4b所示,路径长度为110,调整结果次于图4c,路径长度为104,原因在于c67+c08>c06+c78;S2情况下,若固定计划返回点,则最优调整如图4d所示,路径长度为110,调整结果次于图4e,路径长度为66,原因在于c07+c08>c78。综上认为,计划的返回点可作为路径调整的借鉴,但不应完全局限和固定。

表1 各节点间距及客户需求

节点012345需求Q13001230354080220120202530503203020010153042035251008605154030158070

表2 各节点间距及客户需求
通过上述分析,本文基于以下两个原则:①返回点应根据情况柔性选择,提前判断,不一定是路径失败了才返回;②虽计划路径可能存在返回,但不应完全局限和固定,应适当调整,甚至取消。针对上述原则,本文综合考虑当前实际剩余车载量和未服务客户需求,以调整成本期望值衡量车辆是否返回补货,设计如下实时调整策略:
以发货为例,设车辆按计划路径服务某一客户j后的实际剩余车载量为Qj,当Qj>0时,决策者有两种选择,即直接服务下一客户和返回补货后再服务下一客户。设车辆未服务客户序列为{i,g,h,…},方案选择步骤如下:

(1)i点不失败
(19)
(2)i点失败
(20)


(1)g点不失败
(21)
(2)g点失败
(22)

逐一求解未服务客户的成本期望值,则方案一的整体期望为Cost1=E(Fiti)+E(Fitg)+E(Fith)+…。

(1)i点不失败
(23)
(2)i点失败
(24)

步骤3比较Cost1和Cost2,选择调整成本期望值较小的方案作为车辆在客户j的策略选择。
该策略的优点是具有全局思想,可避免文献[4]的盲目性,实现在不完全局限和固定计划返回点的基础下柔性选择返回点,避免因某一局部调整影响整体最优;缺点是车辆每到达一个节点都要判断,耗时较长。其他特性将在3.2.4中讨论。
2 种群进化算法
本文求解涉及种群进化算法和随机模拟算法,种群进化算法用以求解预优化模型,随机模拟算法用以模拟实时场景。由于随机模拟算法在很多VRPFD中均有涉及[3],这里仅介绍种群进化算法,算法流程步骤与遗传算法(Genetic Algorithm, GA)类似,不同的是将选择、交叉、变异等遗传操作更改为选择、全局搜索和局部搜索。
2.1 解的编码


2.2 初始种群

2.3 选择操作
结合轮盘赌策略[6]和参考集更新策略[14]选择,具体为:首先,采用文献[14]的参考集更新策略对当前种群构建包含精英解集B1(解集规模|B1|)和多样性解集B2(解集规模|B2|)的选择池;然后,根据适应度,采用轮盘赌策略从选择池中选择Psize个个体组成新种群。为保证多样性解能在轮盘赌中被选择,提高算法逃离局部最优的能力,这里对精英解集和多样性解集设计了如下不同适应度计算方法:
(22)
(23)
式(22)为精英解的适应度计算公式,式(23)为多样性解的适应度计算公式。式中:f为目标函数,fmax,fmin为精英解集中目标函数的最大值和最小值,系数α是避免目标函数最大的解的适应度为0,这里α=0.5;D为多样性距离,Dmax,Dmin为多样性解集中多样性距离的最大值和最小值,系数β是避免多样性距离最小的解适应度为0,这里β=0.5。为使目标函数最小解的适应度高于多样性距离最大解的适应度,人为赋予多样性解集的适应度一个权重系数r,r=0.6。
2.4 全局搜索
采用单点交叉法更新被选中的新种群。以待交叉解X1和X2为例,随机产生交叉点(σ,θ),σ表示行交叉点,是取值为[1,min(N1,N2)]的随机数,N1和N2为解X1和X2的实际使用车辆数;θ表示列交叉点,是取值为[1,min(find(X1(σ,:)~=0,find(X2(σ,:)~=0)]的随机数。交叉方法为:保留X1中(σ,θ)之前的基因位,其余基因按X2的编码顺序删除已服务客户点,再依次复制到相应位置,形成新解Y1;新解Y2类似。交叉后的解可以是不可行解,若属于不可行解则在目标函数中额外添加罚函数M。图6所示为交叉操作的简单例子。

2.5 局部搜索
针对全局搜索后的新种群,采用简化的变邻域搜索(Simplified Variable Neighborhood Search, SVNS)对每个个体进行局部搜索,以提高解的质量。SVNS是在VNS变更邻域结构时严格按照指定顺序变更,不重复回到最初邻域结构再次搜索。这里采用弧交换(2-Opt)、客户交换(1-1 Exchange)、客户插入(0-1 Exchange)3种邻域结构,并依次变更。每种邻域的终止条件为连续MAXCount次搜索到的最好解不变。流程如图7所示。


为提高搜索效率,引入邻域半径减少策略(Neighborhood Size Reduction Scheme, NERS)[13]改进上述结构:每次邻域操作均先任意选中某一客户j,令avgj为j与其他所有客户的距离平均值,meaj为j与配送中心和其他所有客户的距离平均值,选择满足cji 用当前最好解替代新种群中的最差解,保证算法的收敛性。 当迭代次数满足最大迭代次数MaxN次时,算法终止。 为验证模型和算法的有效性,本文采用两类算例:标准算例验证种群进化算法的求解性能;随机算例验证预优化模型和实时调整策略的有效性。 因MVRPFDTW属于VRPTW(vehicle routing problem with time window)的扩展,取VRPTW标准算例测试。采用MATLAB 10.0编译,在双核奔腾2.9 GHz CPU、4 G内存、Window 7 64位操作系统的PC机上运行。 实验1采用文献[15]中的无时间窗VRP算例进行测试,问题规模为7,可用车辆数为3,车辆容量为1。设置算法参数Psize=10,|B1|=5,|B2|=2,MAXCount=10,MaxN=10,M=200,运行结果与现有文献比较,如表3所示。结果表明:本文算法同文献[15]GA、文献[16]粒子群优化算法(Particle Swarm Optimization, PSO)均能搜索到最优解217.81,但本文算法实验50次的搜索成功率为100%,且平均求解时间较短。 表3 无时间窗VRP的求解结果比较 实验2采用文献[15]的软时间窗VRPTW算例进行测试。问题规模为8,可用车辆数为3,车辆容量为8,超出时间窗的单位惩罚为PE=PL=50。设置算法参数Psize=20,|B1|=10,|B2|=5,MAXCount=10,MaxN=20,M=800,运行结果与现有文献比较,如表4所示。结果表明:本文算法同文献[15-18]均能搜索到最优解910,但本文算法的搜索成功率为100%,明显优于文献[15]GA的24%、文献[16]PSO的46%、文献[17]改进PSO的97.4%、文献[18]Memetic算法的96%,且求解时间更短,可见本文算法性能优于文献[15-18]的算法。 表4 软时间窗VRPTW的求解结果比较 注:文献[19]给出的QACA最优解805,未包含时间惩罚费用265。 实验3采用文献[20]的带时间窗VRPTW算例进行测试,包括无时间窗VRP、软时间窗VRPTW和硬时间窗VRPTW。问题规模为15,车辆容量为5,车速为1,忽略在送货点卸货的时间。其中,软时间窗VRPTW的单位时间惩罚设置为a=b=20。设置算法参数Psize=20,|B1|=10,|B2|=5,MAXCount=10,MaxN=20,M=400,运行结果与现有文献比较,如表5所示。结果表明:本文算法求解无时间窗VRP的求解结果为509.86,软时间窗VRPTW的求解结果为539.36,硬时间窗问题的求解结果为562.11,结果均优于文献[20]的禁忌搜索算法及文献[21]的改进蚁群算法,且求解时间较快,可见本文算法性能优于文献[20-21]的算法。 表5 带时间窗VRPTW的求解结果比较 实验4采用文献[22]的硬时间窗VRPTW算例进行测试。问题规模为20,配送中心和客户分布在一个边长为200 km的正方形地域内,配送中心坐标为(145,130),车辆载重量为8 t,平均行驶速度为60 km/h,不考虑卸货时间。设置算法参数Psize=20,|B1|=10,|B2|=5,MAXCount=10,MaxN=50,M=1 000,运行结果与现有文献比较,如表6所示。结果表明:本文算法每次运行都能找到问题最优解1112.85,较文献[21]的1 266.01和文献[23]的1 249.27更优,求解时间也在可接受范围内,可见本文算法性能优于文献[21,23]的算法。 表6 带时间窗VRPTW的求解结果 注:文献[22]给出的结果并不满足客户15的硬时间窗要求,会超出时间窗0.05。 实验5采用Solomon标准算例[24](http://www.sintef.no/Projectweb/TOP/VRPTW/solomon-benchmark/)进行测试。该算例集属于允许等待的硬时间窗VRPTW问题,共计56个算例,涉及的问题规模均为100,包括客户点随机分布(R类)、群集分布(C类)和群集-随机分布(RC类)3个类别,且1类算例为紧时间窗约束、2类算例为松时间窗约束,车辆数最大均为25,车辆容量为200或1 000。这里取每类问题的第一个和最后一个算例求解,设置算法参数Psize=30~60,|B1|=10~30,|B2|=5~10,MAXCount=10,MaxN=100,M=400~1 500,不同算例的具体取值不同。运行结果与现有文献比较,如表7所示。结果表明:本文算法在7个算例中均能找到优于文献[21,25-27]的解,且平均误差为1.50%,低于文献[21]的10.19%、文献[25]的7.59%、文献[26]的1.79%和文献[27]的3.22%。另外,本文算法的最大误差为6.05%,误差较小,可以接受,求解时间亦可以接受。可见,本文算法性能优于文献[21,25-27]的算法。 表7 允许等待的硬时间窗VRPTW的求解结果 综合上述关于现有文献的VRPTW标准算例测试及比较结果可以看出,本文算法寻优能力强,求解精度高,求解时间可接受,是求解VRPTW问题的有效算法。 3.2.1 算例描述 表8 客户信息表 3.2.2 算例求解 实验环境同标准算例相同,实验参数取Psize=20,|B1|=5,|B2|=5,MAXCount=10,MaxN=20,M=1 000。表9所示为算法求解预优化模型的10次实验结果,平均求解时间为120 s,总成本均值为1 055.47,最大值为1 069.25,最小值为1 052.52,偏差在1.59%以内,较小可以接受,且6次均能找到最优解,说明本文算法求解质量好,稳定性高,能在可接受时间内找到问题的最优解。图8所示为最优计划路径图,图中共使用3辆车,车辆路径为0-3-9-19-11-8-12-0-18-0、0-10-13-16-6-15-5-2-0和0-1-17-14-4-7-20-0。 表9 算例的10次预优化结果 续表9 表10所示为最优计划路径可能的调整路径(以10 000次模拟的可能场景为例),调整之后的配送成本实际耗费1 063.54,调整成本为11.02。 表10 最优计划路径的实时调整 从表10的详细的调整路线来看:①该策略下失败点出现的概率较小,车辆1为3.83%,车辆2为0.5%,车辆3为0.01%;②该策略不完全局限原计划路径的返回,能够有效缩短配送长度,例如车辆1的计划路线须在拜访完客户12后返回配送中心,而实际调整路线却以83.78%的概率发生车辆无须在客户点12返回配送中心补货的情况。③该策略能柔性选择合适的返回点,如车辆2出现路径失败时,调整方案出现了在失败点前序点返回的方案0-10-13-16-6-15-5-0-2-0(配送成本777.17),甚至找到在拜访完客户13即返回配送中心的更优方案0-10-13-0-16-6-15-5-2-0(配送成本636.39)。综上认为,本文策略基本实现了设计前制定的两大原则,策略合理有效。 3.2.3 多行程策略有效性分析 表11比较了允许/不允许车辆多行程的最优计划路径,结果显示:允许车辆多行程虽增加了时间成本,却降低了车辆数和配送成本,总计划成本更低。结合表10,允许车辆多行程的计划路径经调整后的平均实际成本为1 063.54,低于不允许车辆多行程的计划成本1 134.59,可见多行程策略在预优化阶段意义显著。 表11 有无多行程策略的方案比较 续表11 为便于实际应用,进一步分析多行程策略的适用特性,表12~表15分别给出了偏好值α、服务水平β、车辆容量CV和派遣成本FV变动的求解结果,可见:随着偏好值α的增加(如α≥0.6),最优路径方案出现车辆返程,因此多行程策略在偏好值较高(风险喜好程度较低)的VRP中意义显著;随着β的增加(如β≥0.8),最优路径方案均未出现车辆返程,因此多行程策略在高服务水平(强时间窗约束)的VRP中意义较弱,而在低服务水平(弱时间窗约束)的VRP中意义显著;随着车辆容量的增加,最优路径方案中的车辆返程次数逐渐减少,因此多行程策略在有车辆容量限制的问题中适用于车辆容量约束较强的问题,如现实中的外卖配送服务;在车辆派遣费用不高的情况下,车辆返程的意义不大,这是因为当车辆派遣费用较少时,重新派遣一辆车服务客户所增加的费用不高,且不会因车辆返程造成后续客户的时间费用增加,因此多行程策略适用于车辆派遣费用较高的VRP,如撒雪车、废弃物回收车等专业车辆派遣,或车辆可用数量受限的配送。综上可知,当实际VRP中存在风险喜好程度较低、时间窗约束弱或车辆容量约束强,以及车辆派遣成本较高等特征时,多行程策略意义显著,可有效提高配送效率。 表12 偏好值α变动的求解结果(表中结果均为实验10次的平均结果) 表13 服务水平β变动的求解结果(表中结果均为实验10次的平均结果) 表14 车辆容量CV变动的求解结果(表中结果均为实验10次的平均结果) 续表14 表15 车辆派遣成本FV变动的求解结果(表中结果均为实验10次的平均结果) 3.2.4 实时调整策略有效性分析 表16所示为本文实时调整策略与文献[4](策略1)和文献[9](策略2)的调整结果对比。结果显示:①本文调整策略的失败点出现概率相对于策略1和策略2有所减少(如表中加粗部分),可见在“避免失败点出现”方面,本文策略优于策略1和策略2;②在策略1和策略2中,车辆1均以约95%的概率出现调整0-3-9-19-11-8-12-0-18-0,本文策略将该路径出现概率降低至12.08%,出现约83%的更优调整0-3-9-19-11-8-12-18-0,取消了计划路径中的返回(如表中下划线部分),因此,在“不应完全局限和固定计划返回点”方面,本文策略表现良好;③在策略1中,车辆2路径失败的调整路径为0-10-13-16-6-15-5-2-0-2-0,导致实际配送成本为859.53,策略2能对部分失败路径进行失败点前序点返回的调整,即0-10-13-16-6-15-5-0-2-0,实际配送成本为777.16,而本文策略又对部分失败路径进行更为合适的提前调整,如0-10-13-0-16-6-15-5-2-0,实际配送成本为636.39(如表中双下划线部分),因此在“提前柔性选择合适的返回点”方面,本文策略优于策略1和策略2。综上说明,相对于策略1和策略2,本文策略更能实现“避免失败点出现、避免不必要返回和柔性选择合适返回点”的原则。 表16 不同调整策略的实时调整结果 注:*表示3种策略中的最优调整。 表17所示为不同偏好值α下的计划路径实时调整结果,BK为3种策略的实际成本最小值,偏差为各策略的实际成本与BK的偏差。结果显示:本文策略总体偏差最小,仅为13.16,小于策略1的49.63和策略2的43.53,进一步说明本文策略整体上较文献[4,9]的策略更优。详细来看,当α≥0.8时,本文策略明显较优,可见本文策略适用于决策者风险喜好程度较低(α≥0.8)的情况,结合表16,参数值取ε1:ε2=1较好;当决策者风险喜好程度较高(α≤0.7)时,只需更改本文策略的“不固定计划返回”为“固定计划返回”,参数取值ε1:ε2≤1.1均优于策略1的求解结果,其中当0≤ε1:ε2≤0.8时和策略1结果相近,当0.8≤ε1:ε2≤1.1时优于策略1。表18所示为对表17中负调整成本的补充说明。 表17 不同偏好值α下最优计划路径的实时调整结果 表18 α=1.0且β=0.6下最优计划路径的实时调整 本文对MVRPFDTW的两阶段求解法进行了研究。首先,在需求未明的预优化阶段,建立了以物流成本和时间成本总和最小为优化目标的预优化模型,其中增加决策变量的行程维度,且车辆容量按单行程核算,客户到达时间按多行程累加计算,另外客户满意度定义为到达时间隶属度函数;其次,在已知实际需求的实时调整阶段,基于“提前柔性选择返回点”和“不完全局限和固定计划返回点”两个原则,提出一种基于调整成本期望值的实时调整策略;最后,设计了种群进化算法求解预优化模型,采用随机模拟算法模拟实时场景。算例分析证明:①种群进化算法性能表现良好,是求解这类问题的有效算法;②预优化模型能获得较优的计划方案,模型合理有效,且多行程策略在风险喜好程度较低、时间窗约束弱或车辆容量约束强,以及车辆派遣成本较高的VRP问题中效果显著;③实时调整策略是个兼顾全局且风险适中的策略,能实现“避免失败点出现、避免不必要返回和柔性选择合适返回点”,策略灵活且合理有效。 未来可考虑进一步开放“实时调整阶段车辆不改变计划方案安排好的客户集合和服务顺序”的限制,提出调整效果更好的实时调整策略。2.6 精英保留策略
2.7 终止条件
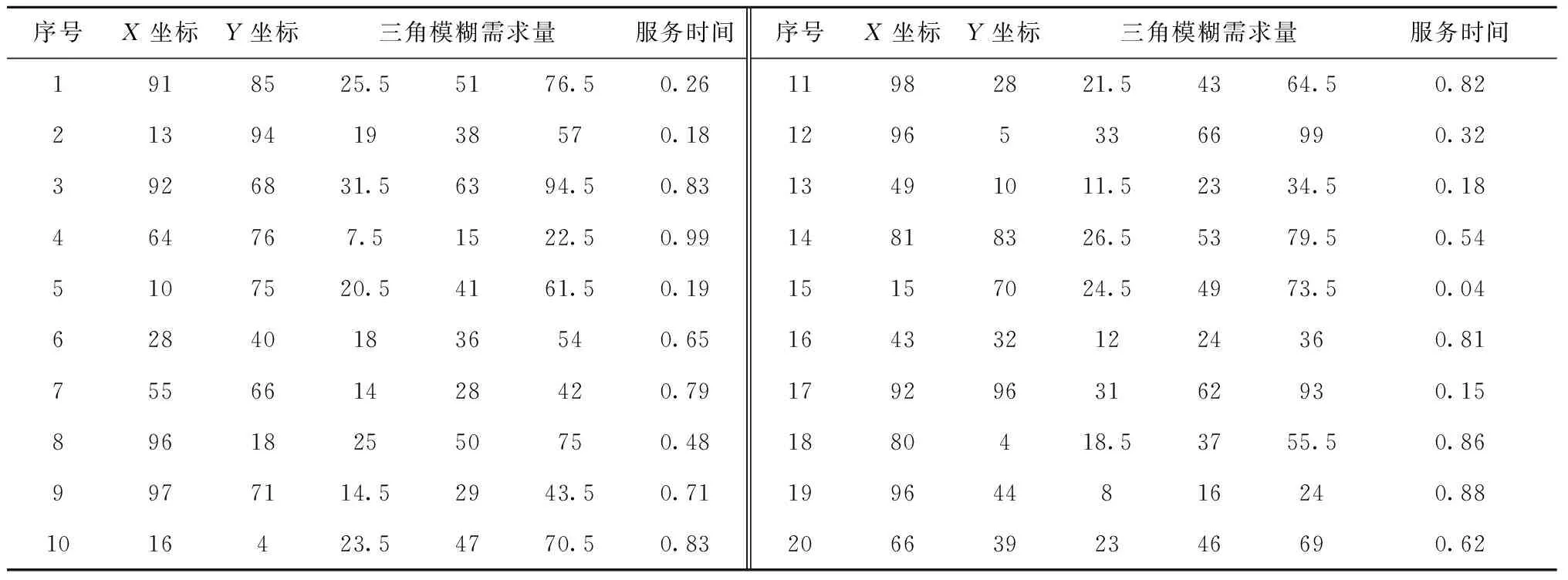
3 算例分析
3.1 标准算例





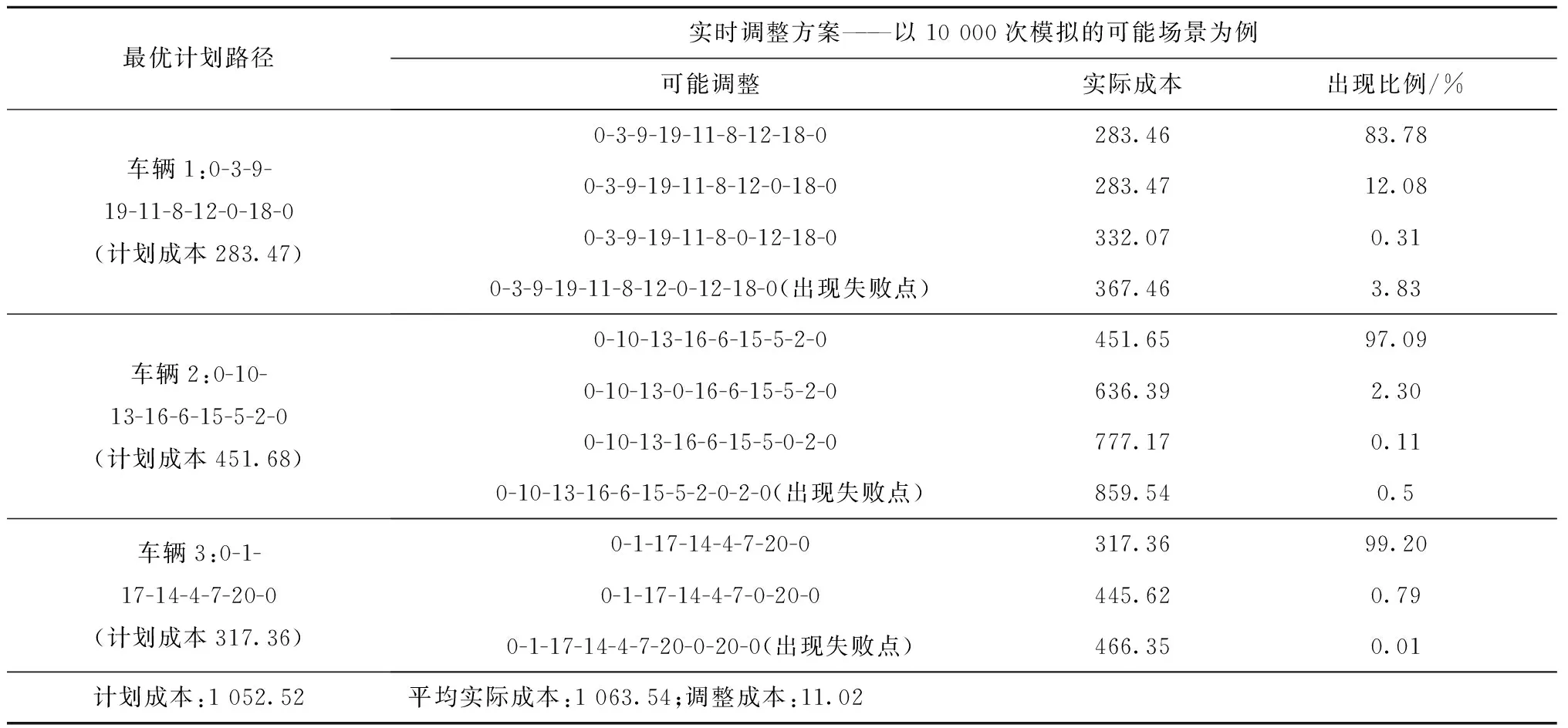
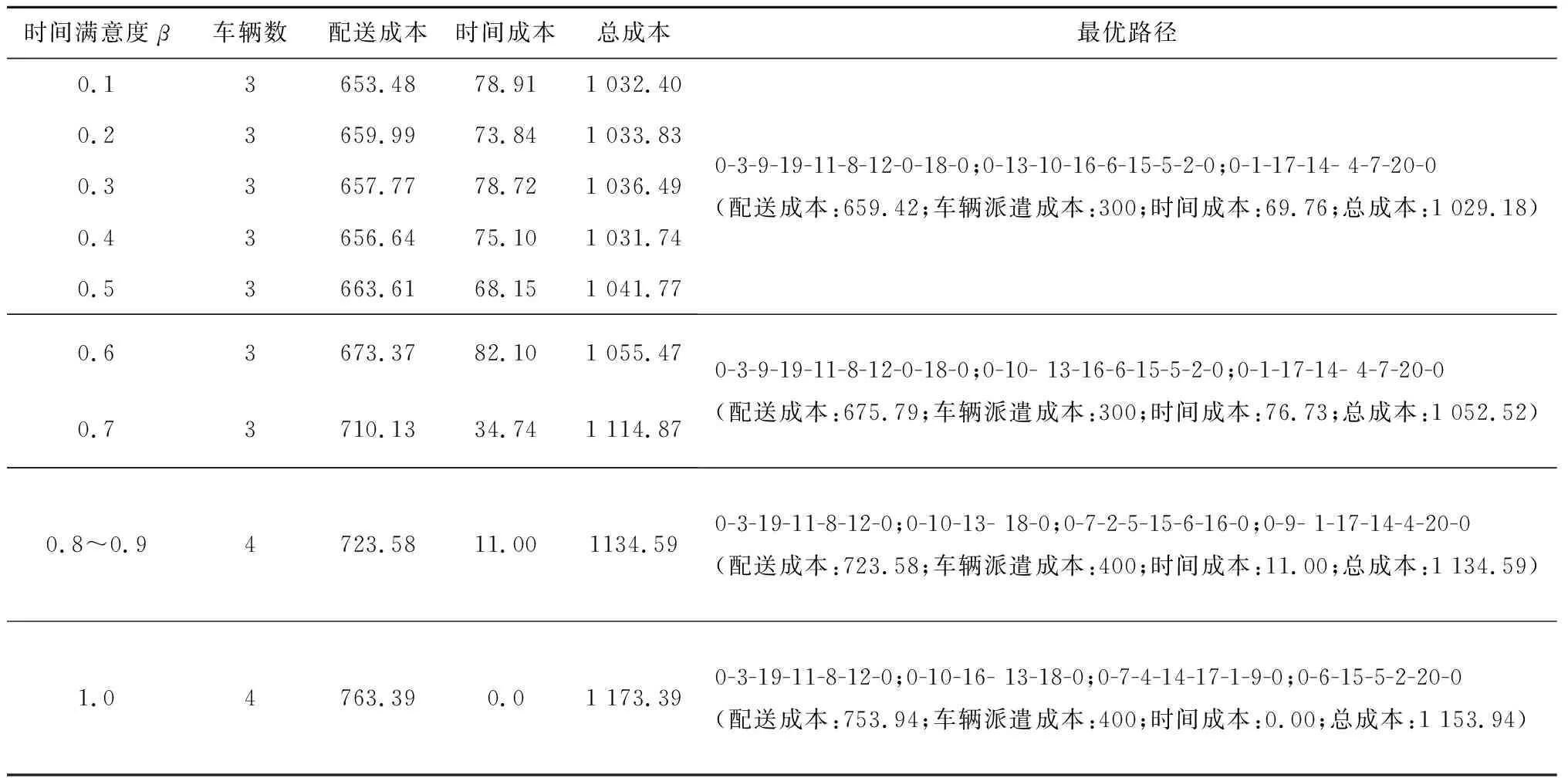
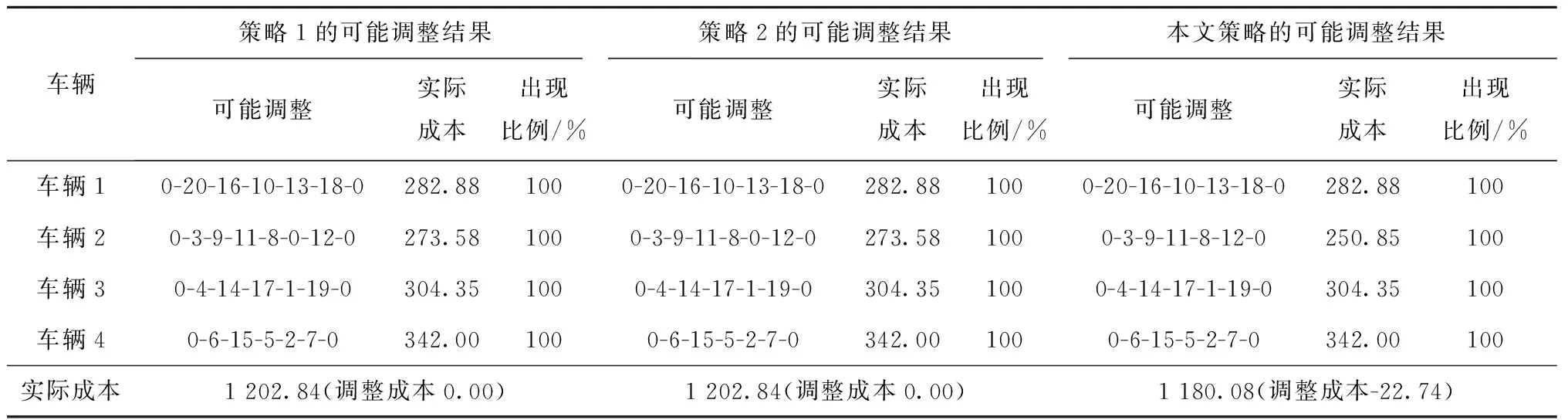
3.2 MVRPFDTW随机算例













4 结束语
猜你喜欢
今日农业(2021年14期)2021-11-25
意林(2020年10期)2020-06-01
小太阳画报(2018年3期)2018-05-14
证券市场红周刊(2018年5期)2018-05-14
阅读与作文(小学低年级版)(2016年12期)2016-12-22
中国学术期刊文摘(2016年2期)2016-02-13
汽车文摘(2015年11期)2015-12-02
新乡学院学报(2015年6期)2015-11-06
电网与清洁能源(2015年2期)2015-02-28
时代英语·高三(2014年5期)2014-08-26
