
IPv6融合树结构存储及快速查找
2019-01-24 08:26陈文龙唐晓岚
小型微型计算机系统 2018年12期
张 沛,陈文龙,唐晓岚
(首都师范大学 信息工程学院,北京 100048)
1 引 言
IPv4协议中每一个网络接口由长度为32位IPv4地址表示,其地址空间为43亿个.这一地址空间难以满足未来移动设备和消费电子设备对IP地址的巨大需求.截至目前,IPv4地址已全部分配完毕.
IPv6是下一代互联网NGI(Next Generation Internet)的核心协议,和当前计算机网络使用的IPv4协议相比.IPv6的地址空间长度由IPv4的32位扩展到128位,其中前64位为网络前缀,后64位为主机地址.这样庞大的地址空间可以满足互联网的指数型增长.随着互联网的进一步发展,IPv4地址短缺问题变得越来越紧迫,IPv6也因此得到了学术界和产业界的广泛关注和认可.由此,产生了许多由IPv4到IPv6的相关技术[1-3].然而,IPv6仍采取最长前缀匹配查找,而现有的大多数IPv4查找算法不能直接适用到IPv6.因此,设计高效可行的IPv6查找算法是当前面临的难题.
路由表查找算法大致分为硬件算法和软件算法.硬件算法:硬件三态内容寻址存储器(Ternary Content Addressable Memory,TCAM)算法[4],IPv6查找的时间复杂度为0(1).但TCAM功耗大、价格昂贵且路由更新比较复杂.软件算法:1)基于前缀长度的二分查找算法[5],查找时间复杂度为0(W/M*logW),其中M是机器的字宽,W是IP地址的长度.对于IPv4,W=32;对于IPv6,W=64(只考虑网络前缀).在32位机上,使用基于前缀长度的二分查找算法来完成IPv6的最长前缀匹配,则最多需要64/32*(log64)=12次哈希.由于在查找中需要添加mark标记位来确定其查找路线,在终点未查到匹配项时需要进行回溯处理,其最坏情况下的性能难以预测.2)基于前缀区间的二分查找[6],算法时间复杂度为0(log2N).最坏情况下,更新一个关键字会影响0(N)个地址空间.由此,二分查找算法的更新性能较差,且存储空间过大.3)基于Hash表的路由查找算法[7-11].算法[7]提出的算法采用哈希和树位图技术进行查找,采用硬件并行流水技术实现该算法时,能够很好地平衡IPv6路由查找空间和速度,但更新较复杂.4)多比特查找树算法[12,13],有时也被称为分段算法,查找性能和分段的层数成反比,内存消耗和分段的层数成正比.近期研究的查找算法[14-18]的主要适用路由前16位取值不多,且路由项较少的情况.如TSB[18]将所有的前16位取值按数量进行二叉树存储,对于前16位数量较多的路由项,添加段表以加快查找速率,对于前16位较少的路由项,则直接利用路由桶技术进行查找.
用Trie树结构来表示地址前缀是一种常用的方法,Trie树采用一种基于树的数据结构,它通过前缀中每一位比特值来决定树的分支.而多比特Trie树则是一种提高Trie树查找效率的方法,即查找每一步检查地址中的多个比特,而不仅仅是一个.多分支Trie树的查找过程与一般的二分支Trie树的查找过程类似,在每次节点访问过程中,记录下到目前为止已经匹配上的最长地址前缀,直到到达叶子节点,搜索过程结束.由于多分支Trie树采用的步宽大于1,所以它的搜索效率会有明显的提升.
本文设计了一种融合树结构的IPv6查找算法,将所有路由存放在节点中,查找时直接定位树节点,并通过回溯指针确保快速完成最长前缀匹配.该方案支持快速IP查找,并能有效的对路由前缀进行插入和删除操作.提出方案以多分支Trie树(Multibit Trie)为基础,以融合存储(Fusion Storage)与回溯指针(Backtracking Pointer)为核心,因此我们称该算法为MFB算法.
2 IPv6路由分布特点
IPv6的地址分配采用分级结构,因特网分配地址权威机构IANA(Internet Assigned Number-Authority)负责IPv6地址空间的分配,目前IANA从可聚合全球单播地址空间(格式前缀001)中将高位地址分配给RIR(Regional Internet Registries).RIR则将已获得的高位地址再次分配给下级地址机构:本地因特网服务提供商(Internet Service Provider)、本地因特网注册机构(Local Internet Registries).最终用户(End Users)再根据自身规模的需要向ISP/LIR申请所需的IPv6地址.IPv6的128位超大空间和灵活的地址结构也为IPv6制定更好的地址分配策略提供了前提.为了更好保证IPv6地址分配的可聚合性和节约性,IPv6明确规定了各级地址分配机构可以分配的前缀长度,这使得IPv6路由表呈现出更好的层次性.
以主干网1为对象,分析该路由表中的前缀长度规律,从图1和图2中可以看出:
1) 所有路由的前缀长度都在16~64之间;
2) 前缀长度为32和48路由占到整体数量的70.61%;
3) 路由表中路由前缀的前16位取值类型很少,“取值”是把前缀的1-16位作为整体转换成10进制后得到的一个值.对于该AS的主干网路由表,前缀1-16位取值仅有52个.
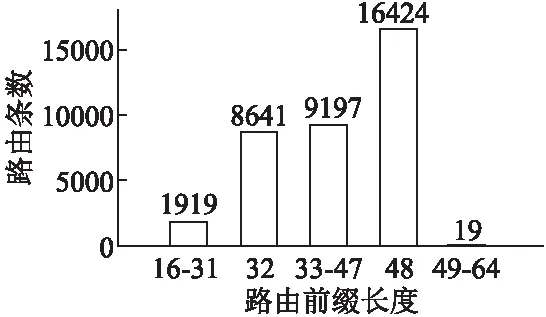
图1 IPv6前缀长度分布Fig.1 IPv6 prefix length distribution
将IP前缀的前16位取值相同的路由集合定义为一个路由域(rooting region),简称RR.例如:前16位是0x2001的路由集合称为RR(2001).

图2 Rooting region数量分布Fig.2 Rooting region number distribution
3 MFB算法
3.1 整体结构
基于前文所述的IPv6地址结构、IPv6地址分配策略和IPv6骨干网路由表特点,对于数量级为1-10(如图2)的rooting region域,直接使用二分查找,最大查找次数为4.对于数量级大于10的,本文设计了一种基于融合树结构的多分支Trie树模型.以节点为整体单位,将所有路由归属到某一节点,利用Trie树的三层节点实施路由查找.
路由表的整体结构如图3所示.根据主干网中IPv6的分布特点,IPv6主干网路由表中前16位取值较少,在查找时先对前16位进行第一次查找定位到具体的某一棵Trie树中.
3.2 自定义型Trie树结构
根据主干网中的分布特点,前缀长度为32、48的路由数量较大,占比70%以上.所以,本文针对同一region域,设计了16位步长的多比特Trie树进行路由存储.前缀长度为16、32、48的路由为节点(Backbone Node),分别存储在Trie树结构的第1-3层.每个节点包含3部分:主干路由(Backbone Routing Entry),附加路由(Addition Routing Entry),回溯指针
1http://bgp.potaroo.net/v6/as2.0/bgptable.txt.
(Backtracking Routing Pointer).
主干路由:前缀长度为16、32、48的路由.主干路由为节点的核心,每个节点有且仅有一个主干路由,但其可能为真实节点(如图4中B、C节点,图中所有灰色区域为真实路由,下同),可能为空节点(如图4中A、D节点).
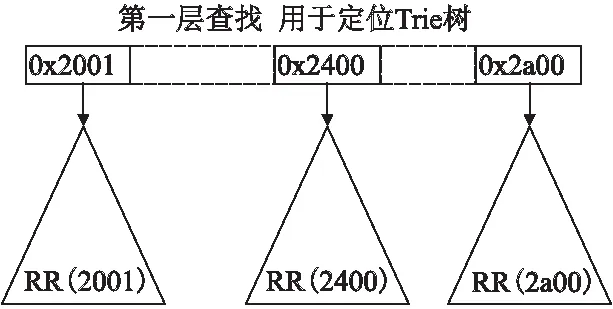
图3 MFB整体结构Fig.3 MFB whole frame
附加路由:所有前缀长度不为32、48的路由.我们首先给出如下定义.
定义1.对于两个给定的IP前缀IP1:address1/masklen1,IP2:address2/masklen2不妨设masklen2>masklen1.我们称IP1归属于IP2,当且仅当IP1的前缀地址address1补0至前缀长度masklen2后得到新前缀address1′与address2完全一致.
附加路由与主干路由的关系为上面描述的归属关系,若附加路由的前缀长度在17~31之间,则归属在前缀长度为32的路由上.(图4中A节点的附加路由2001:1200::/23将其补0至32位后存放在对应节点2001:1200::/32上).若附加路由的前缀长度在33~47之间,则归属在前缀长度为48的路由上.对于附加路由前缀长度在49~64之间的,路由表中极少.路由表[17]只有19个.具体操作时,我们将其链接在第三层节点下,使用链表查询,本文中不做重点.每个节点可能有一个或多个附加路由(图4中A、C、D节点),也可能没有附加路由(图4中B节点).在查找路由时,不直接查找附加路由,而是通过回溯指针间接查找到附加路由.
3.3 回溯指针
定义2.路由集合S中各路由项的目的IP前缀描述为IPi:addressi/maskleni,i=1,2,…,n.对于给定前缀IPx:addressx/masklenx,令集合S的子集S′,且IPx归属于S′中每条路由项的目的IP前缀,则S′中masklen最大的路由项被称为IPx的最近上游路由.
例如:路由表中有如下前缀2001:2300::/24、2001:2330::/28、2001:2333::/32、2001:2355::/32.则根据以上定义,2001:2333::/32的最近上游路由为2001:2330::/28.2001:2355::/32的最近上游路由为2001:2300::/24.
回溯指针为指向本节点下主干路由最近上游路由的指针.记为Rcon.添加回溯指针的主要意义在于使所有查找进程都在节点中进行.若没有回溯指针,则在查找节点且无匹配项后,则需要进一步在临近的节点中进行回溯查找,时间消耗过大.在添加回溯指针后,对于同一层中,若不匹配,则直接匹配到回溯指针上,并进行下一层查找,极大的提升时间效率.(图4中节点A的主干路由为2001:1200::/32,附加路由2001:1200::/23,2001:1200::/24都为其父节点,但路由2001:1200::/24的前缀长度最大,所以节点A的回溯指针为(2001:1200::/24).由于回溯指针指向的是其最近上游路由,而该节点下主干路由的最近上游路由不一定在本节点中,这是因为该路由与其最近上游路由只是前缀相匹配.例如路由2001:1200::/24与2001:1234::/32他们的前24位相匹配,2001:1200::/24是2001:1234::/32的最近上游路由,但是他们存储在两个不同的节点中.所以回溯指针指向的路由可能在本节点中(图4中节点A),也可能在其他节点中(图4中节点B).
3.4 Trie结构融合
在Trie树每一层节点查找过程中,采用直接寻址表,即建立一个216的段表(每一次查找16位),一次定位到对应树节点.在第一层根节点查找第二层节点时,构建一个段表.不过,在第二层节点查找第三层节点时,由于 每一个第二层节点都需一个段表,且所建段表极为稀疏,空间利用率极低.为提升存储效率,我们将第三层节点融合,具体融合方法是将所有主干节点中主干路由的33-48位一致的路由进行融合存储.如图5中的D、E、F节点,它们的主干路由第33-48位都为0x2200,记为Area(2200).
对于某一个Area来说,由于存储节点的主干路由的1-16位与33-48位完全一致,而17到32位不等,这就导致可能会发生冲突,如图5中Area(2200)与Area(2234).若所有1-16位与33-48位一致的主干路由少于或等于1个,就不会发生冲突,如Area(2256)与Area(3456).
在进行融合查找时,需将目的地址的17-32位与主干路由中的17-32位作比较,匹配后记录下匹配项.例如,收到目的地址为2001:1200:2200:f000::1的报文.根据目的地址的33-48位0x2200找到Area(2200),并顺序分析各所属节点.第一个节点D,其主干路由的17-32位0x1000与目的地址不匹配;继续向下查找节点E,主干路由17-32位与目的地址0x1200匹配,查找成功并记录下匹配项.
在同一Area中,若节点冲突较少(本文定为节点数量不超过3),则可用链表查询.在AS2.0路由表中,最大的冲突个数为region(0x2620)中的Area(0x4000)有98个节点(仅包括节点的主干路由为真实节点的情况),对于这种数量级,如果使用直接寻址表,则由于数据较少且数据跨度过大,造成空间利用率低.本文使用除法散列的方法来解决这一问题.
在用来设计散列函数的除法散列法[19]中,通过取x除以m的余数,将关键字x映射到m个槽中的某一个上,即散列函数为:
hab(x)=((ax+b)modn)modm
(1)
其中a,b为自定义参数.n为原数据的跨度,在这里都为216,(ax+b)的作用有两点:
1) 原数据先进行一次线性变换,再进行模n的归约,使原数据均匀散列,降低下一次模m归约时发生冲突的概率.
2) 若原数据通过除法散列法后发生冲突,则可通过对参数a,b的修改使其不发生冲突.
m为最后进行归约的空间大小,它与Area中的数量t相关,显然m>t.且对于数量t越大的数据,往往需要更大的空间来减小最后归约时的冲突概率,这里对于数量t小的数据不妨设m=2p+1-1,2p为大于t的最小的以2为底的幂.以图5中Area(2200)发生的冲突为例,这里冲突的数量t为3,p=2,设n=216,m=7,a=2,b=50.首先将发生冲突的16位二进制数转化为10进制,再进行除法归约,得到除法散列表(如图6所示).再根据得到的散列表找到对应的节点.需要注意的是,当查找到节点后仍需对17-32位进行一次比较(归约到最后出发散列表的地址会有多项,如0x1001经过散列公式(1)后关键字也为5),匹配后方可记录匹配项.

图5 融合Trie树示例图Fig.5 Fusion Trie tree sample graph

图6 除法散列算法示例Fig.6 Example of division hash algorithm
在查找节点时,可通过添加虚拟节点提升后续相同目的IP的匹配速度.如图5中的H节点,虽然它的主干路由不为真实路由,也无附加路由,但当接收到目的地址2001:1000:2234::1的时候,需要借助节点H中的回溯指针找到其匹配的路由2001:1000:2200::/40.对于2001:1000:2200::/40这一条附加路由而言,需要添加主干路由为2001:1000:2200::/48-2001:1000:22ff::/48的共计256个节点.显然,实际流量进行路由匹配时,由于实际流量遵循28原则,其中大部分节点我们不会用到,造成较大浪费.本文利用保活机制优化存储效率,所谓保活机制即在初始化路由表时,不添加任何空节点(空节点即该节点下无任何真实的主干路由与附加路由),当接收到目的地址时,才建立对应的空节点.以图5中的H节点为例,当接收到目的地址为2001:1000:2234::1的报文时,才会生成H节点,并添加2001:1000:2234::/48的回溯指针.回溯指针指向其最近上游路由,即2001:1000:2200::/40.此后,所有以2001:1000:2234::/48为前缀的目的地址都将通过H节点及回溯指针完成快速路由匹配.
虚拟节点的回溯指针生成方法是根据前缀长度从大到小查找与之匹配的上游路由.但在实际查找时,由于附加路由的特定查找形式,无需按位依次进行查找,只需根据查找数据中1的数量进行分组,同一组的附加路由存放在同一节点中,依次在组中进行查找即可.
以构建虚拟节点2001:1000:2208::/48的回溯指针为例.根据路由33-48位中1的数量对附加路由进行分组(0010 0010 0000 1000).附加路由2001:1000:2208::/45-2001:1000:2208::/47都存放在以2001:1000:2208::/48为主干路由的节点下;同理附加路由2001:1000:2200::/39-2001:1000:2200::/44存放在以2001:1000:2200::/48为主干路由的节点下;附加路由2001:1000:2000::/35-2001:1000:2000::/38都存放在以2001:1000:2000::/48为主干路由的节点下;附加路由2001:1000:0000::/33-2001:1000:0000::/34存放在以2001:1000:0000::/48为主干路由的节点下.依次查找以2001:1000:2208::/48,2001:1000:2200::/48,2001:1000:2200::/48,2001:1000:2200::/48为主干路由的节点.找到匹配项,建立虚拟节点,添加Rcon回溯指针信息.若无匹配项,则Rcon指向null.
该机制对于重合度不高的流量,该算法的查找时间会有所增加.但真实流量遵循28原则,该机制不仅能减少冗余空间的产生,并且极大的减少查找时间.
3.5 路由查找
查找路由时,根据该融合Trie树的特性,采用分层查找的方法进行查找.首先,通过目的地址的前16位定位到具体某一rooting region域中,后续操作在同一Trie树中完成.由于遵循最长前缀匹配原则,为了提高查找效率,先查找第三层节点.若找到匹配项,则无需查找第二层节点(第二层匹配项的前缀长度一定小于第三层匹配项的前缀长度),直接从匹配路由的对应出口转发即可.若第三层节点无匹配项,则需查找第二层节点.若第二层节点无匹配项,则利用默认路由出接口转发.在查找到的节点中,若主干路由为真实路由,无需查找回溯指针,因为回溯指针的前缀长度一定小于主干路由的前缀长度.故有如下结论:查找某一节点时,主干路由匹配,无需查找回溯指针.
具体路由查找算法如下,其中desIP为接收到的目的地址.NP为最长前缀匹配路由的下一跳地址.
1 search MFB(desIP){
2 NP=nexthop of default route;
3 num1=the 1-16 bits of desIP after decimal;
4 node=searchTreeNode(num1);
5 if(node==null) returnNP;
6 NP=node.nexthop;
7 num2=the 33-48 of desIP after decimal;
8 node1=searchArea(num2);
9 if(node1!=null){
10 if(node1.backbone_routing!=null)
11 NP=node1.backbode_routing.nexthop;
12 else NP=node1.rcon.nexthop;
13 return NP;
14 }
15 else{
16 num3=the 17-31 of desIP after decimal;
17 node2=searchArea(num3);
18 if(node2!=null){
19 if(node2.backbone_routing!=null)
20 NP=node2.backbode_routing.nexthop;
21 else NP=node2.rcon.nexthop;
22 return NP;
23 }
24 }
25 }
以图5为例.若查找目的地址2001:1000:2200:1234::1.首先查找目的地址的33-48位0x2200,找到Area(2200)中的D节点,D节点中的主干路由2001:1000:2200::/48为真实路由,记录下匹配项,结束查找.
若查找目的地址2001:1234:2200:ffff::1,查找目的地址的33-48位0x2200,找到Area(2200)中的F节点,F节点中的主干路由2001:1234:2200::/48不为真实路由,继续查找节点中的回溯指针2001:1234:2200::/39,记录下匹配项,结束查找.
若查找目的地址是2001:1234:ffff::1.查找目的地址的33-48位0xffff,没有找到Area(ffff).因此第三层节点无匹配项.继续在地址中查找17-32位0x1234.找到节点C,节点C的主干路由不为真实路由,继续查找节点中的回溯指针,找到匹配项2001:1200::/24.
3.6 路由维护
主干路由是节点的核心,主干路由的增加与删除并不意味着节点的增加或删除.仍以图5为例进行说明.
当增加主干路由2001:ffff::/32时,我们需要添加一个新的节点.若增加的主干路由为2001:1234:2200::/48时,我们只需将节点F的主干路由标记为真实路由即可.若删除路由2001:1000:2200::/48时,由于D节点中仍有附加路由2001:1000:2200::/40,所以不能删除整个D节点,只需将D节点中的主干路由标记为非真实路由即可.若删除路由2001:1234:3456::/48,由于节点J除主干路由外无其他路由信息,因此将J视为无用节点,删除整个J节点.
附加路由的维护与主干路由类似,若添加附加路由时,我们只需将附加路由补0添加到相应的位置上,在没有节点时添加节点.删除附加路由时,在对应的节点处删除路由,若在删除过后无任何路由项信息,则删除整个节点.
对于附加路由我们仍需添加前后继关系.优点在于当删除的路由为Rcon指针指向的路由时,需更新Rcon指针信息,此时无需再从附加路由里一一进行查找,而是查找删除路由的前继路由即可.在图7中,若删除的节点为2001:1200::/24,节点的Rcon路由直接指向2001:1200::/24的前继节点2001:1000::/20,极大减少路由更新时间.

图7 前后继关系维护示例图Fig.7 Example of relationship maintenance
在删除附加路由时,只需将该附加路由的后继路由的前继改为自身的前继即可,例如图7中删除2001:1200::/24.则直接将2001:12f0::/28的前继改为自身的前继2001:1000::/20即可.
在添加路由时首先需要找到自身的前继节点,这里采用移位法.例如若添加路由0x1C60/12 (0001 1100 0110 0000)则依次看向左移1,2,…,k位,查看路由0x1C60/12 (0001 1100 0110 0000),依次查看节点:0x1C40 (0001 1100 0100 0000),0x1C00 (0001 1100 0000 0000),0x1800(0001 1000 0000 0000),0x1000(0001 0000 0000 0000).
若添加路由时,若找不到前继路由,则其前继路由为根节点,但根节点不能作为Rcon指向的目标,若某一路由的前继路由为根节点,则Rcon指向null.在找到前继路由后,向下找后继路由,其方法是通过前继路由查找后继路由,因为添加路由的后继路由一定在前继路由的后继中.图7中,我们实施添加路由操作,目的前缀为2001:3400::/24.首先找到其前继路由2001::/16,进一步在2001::/16的后继路由中查找后继路由,并改变前后继关系.通过建立附加路由之间的前后继关系,在更新Rcon指向的路由时,极大的提高了更新速度,完善了数据结构的整体性.
4 实验分析
为了验证本算法的性能,在Windows操作系统下模拟算法的软件原型系统,测试用PC机安装win7操作系统,硬件配置为2G DDR内存,Intel Core i7-4790CPU @3.6Hz.本文以AS2.0 IPv6 BGP Table为基本路由表,本文以TSB[16]为对比实验对查找时间以及存储空间进行分析.随机抽取1k、2k、5k、10k、20k、50k条真实流量数据,其函数图在区间上为增函数,且逐渐收敛于某一数据,其平均查找时间结果如图8、图9所示.
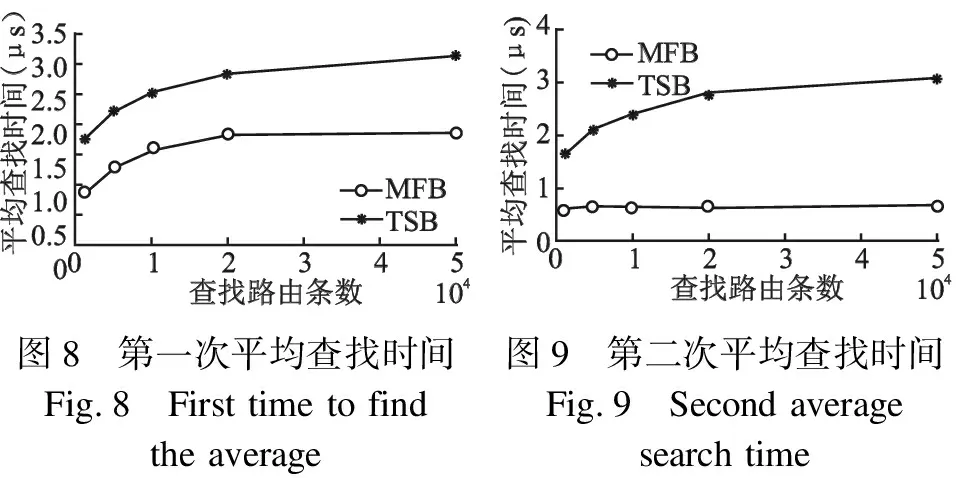
3.53.02.52.01.51.00.50012查找路由条数×104MFBTSB平均查找时间(μ)s34543210查找路由条数×104MFBTSB平均查找时间(μs)012345图8 第一次平均查找时间图9 第二次平均查找时间Fig.8 First time to find Fig.9 Second average the averagesearch time

图10 第一次平均以及最大查找次数Fig.10 First average and maximum number of lookups
查找真实流量,对于第一次查找时,MFB的平均查找时间较小于TSB,但MFB的第二次平均查找时间明显优于TSB,而且随着查找条数的增多,MFB的第二次平均查找时间没有明显变化.这是由于保活机制的存在,极大地减少了内存访问次数.此方法适用于流量较为集中的情况,由于真实流量符合二八定律,所以MFB在查找真实流量情况时,在查找速度方面有优势.

查找路由条数×104第二次平均查找次数第二次最大查找次数012345543210查找次数403020100占用内存大小)(MB005.10.15.20.25.30.查找路由条数×104MFBTSB图11 第二次平均以图12 占用内存空及最大查找次数间大小Fig.11 Second average andFig.12 Occupied memorymaximum lookups space size
第一次的平均查找次数与最大查找次数都较大,如图10所示.且最大查找次数不稳定.由于两次查找的是相同的流量,第二次查找时会直接根据第一次查找时建立的回溯指针直接定位到符合最长前缀匹配的路由.极大的减少了查找次数,如图11所示.
本算法由于多分支Trie树的建立,造成了一定空间的冗余.虽然进行了融合,但大部分段表上数据分布仍十分稀疏,空间略大于其他算法,整体呈线性增长,如图12所示.
5 结束语
充分分析了IPv6地址结构和IPv6地址分配策略和IPv6骨干网路由表的特点,设计一种自定义型Trie树结构,相比以往算法,具有查找速度快,扩展性好的特点.实验结果表明,算法在首次接收到流量时,内存访问次数以及查找时间可能较长,但由于保活机制与回溯指针机制的存在,后续查找时间大大降低.在查找大量流量时,大流量平均查找时间为:1.88μs/条.
猜你喜欢
小学生学习指导(低年级)(2020年10期)2020-11-26
软件学报(2020年6期)2020-09-23
计算机与网络(2020年9期)2020-07-29
网络安全和信息化(2019年11期)2019-11-25
传播力研究(2019年24期)2019-10-21
科技与创新(2018年1期)2018-12-23
作文大王·低年级(2017年11期)2017-12-05
广东第二课堂·小学(2017年9期)2017-09-28
学苑创造·A版(2017年1期)2017-01-19
软件工程(2014年3期)2014-03-15
