
词间关系的不确定图模型与关键词自动抽取方法
2019-02-15 09:21黄睿智黄德才
小型微型计算机系统 2019年2期
黄睿智,黄德才
(浙江工业大学 计算机科学与技术学院,杭州 310023)
1 引 言
关键词可以高度凝练文本的主题,快速获取文本的核心内容,在信息检索、自然语言处理、情报学等领域都起着重要的作用.随着数据信息化及大数据时代的到来,大量文本信息涌现,采用早期的手工标注关键词方法将消耗大量人力及时间,如何自动高效并准确地从文本中抽取关键词逐渐得到了人们的关注,成为了自然语言处理领域的一个重要课题,同时广泛应用于人工智能、推荐系统、机器翻译等工业领域.
关键词抽取指的是通过计算机程序从文本中自动抽取具有重要性和主题性的词或短语的自动化技术.主流的关键词抽取方法可以分为监督方法及无监督方法,其中监督方法往往会把关键词抽取看作一个二分类问题,通过对已标注的语料库训练分类器来判断文本的某个词是否为关键词,其中分类器包括基于决策树算法[1]、基于朴素贝叶斯方法[2]等. 监督学习的关键词抽取准确率较高,但其需要对大量语料信息进行人工标注,需要花费大量人力时间,同时,语料的质量也会直接影响模型的准确性;无监督方法中采用的技术包括统计法、基于主题的方法、基于网络图法等,其中TF-IDF[3]算法是一个经典的基于统计法的关键词抽取算法,其中TF(Term Frequency)指的是词频,IDF(Inverse Document Frequency)指的是逆向文件频率,算法基于这样一个假设:当一个单词在一个文本中出现多次,而在其他文本中出现较少,则该单词可以作为关键词,该算法简单快速,但在很多短文本中,高频词并不一定是关键词,且很多词的词频相近致使TF项无法起到作用,同时该方法无法体现词间的语义关系.
针对TF-IDF的改进包括,文献[4]通过提高特征值权重一定程度克服TF-IDF中IDF带来的问题;文献[5]引入了情感判断来提高TF-IDF的准确性;文献[6]引入了词语关联度来避免单词TF-IDF带来的误差;文献[7]通过引入规则对候选词进行评分结合TF-IDF来抽取关键词.综上,许多关键词抽取的研究都将TF-IDF作为基础特征,并结合词性特征,候选词评分等方法提高关键词抽取的准确率,但很少结合词间语义的关系,本文将首先将词转为词向量,并结合不确定图提出一种词间相似度公式来表示词间语义上的关系.
TextRank[8]是一个经典的基于网络图的关键词抽取算法,它将每个词看作图中的一个节点,采用随机游走法来计算每个词的分值,通过分值的高低来判断该词的关键程度. TextRank作为一中无监督学习方法,无需标注训练数据,速度快适应性强,但其通过共现频率来构建网络图的方法,针对短文本时往往会形成链式的图结构,从而致使准确率降低,同时TextRank也无法体现词间语义上的关系.
综上,传统的关键词抽取算法单纯依靠统计或词的关联信息[9]及词的文本位置无法体现文本中各次语义间的关系,而如果加入人为制定的规则对候选词进行评分来来提高算法准确率的方法,在实际应用中针对不同的业务需求需要相应改变规则,同时也需要人为维护一定数量的候选词库,使得该方法一定程度转化为了半监督学习. 同时,工业上诸如商品介绍、用户评论、新闻等文本信息很多均以篇幅较短的文本为主,传统关键词抽取算法在长文本关键词抽取时可以取得尚可的准确率,但针对短文本时往往效果较差.
本文结合word2vec首次提出了一种词间的文本局部相似度公式,并通过词间关系建立了不确定图模型,参考文献[10]的图聚类相关方法及定理提出了顶点密度概念及候选关键词评价指标DEN,并提出了基于不确定图的候选关键词抽取算法,最终结合IDF提出了一种全新关键词评价优化标准DEN-IDF. 这种关键词抽取的新方法在每个过程均不依赖于外部人工标注数据,能够实现全程无监督. 通过大量文本实验仿真发现,DEN-IDF的准确率比TF-IDF提高了8%左右,比TextRank提高了12%左右,其中DEN-IDF在面对短文本时准确率比TF-IDF提高了9%左右,比TextRank提高了13%左右.
2 相关工作
2.1 词的向量化
词的向量化目的是将语料库中的每个词数值化一个指定长度的向量,最早由Hinton[11]提出,它可以将词映射到一个低维、稠密的实数向量空间中,使得词义相近的词在空间上的距离越近.通过借鉴文献[12]中的NNLM,Mikolov等提出了Word2vec模型[13].

图1 CBOW模型Fig.1 CBOW model
Word2vec模型通过优化NNLM中的神经网络,大大提高了训练效率,其模型包括图1的CBOW模型及图2的Skip-gram模型. 两个模型的网络结构都包括:输入层、投影层、输出层,其中CBOW利用词w(t)及文本中该词周围的n个词来预测当前词,skip-gram则利用从w(t)来预测它周围的n个词以CBOW模型为例,假设context(w)为w(t)周围的n个词,训练过程将(context(w),w(t))作为输入,输出为p(w(t)|context(w)),通过极大似然估计最大化输出. 当模型训练完成后,对语料库中的每个词可以得到一个相应的向量.通过比较两个词向量的空间距离,可以得到两个词在语义上的差异,如本文实验得到的word2vec模型中,"贫穷"与"贫苦"的词向量余弦相似度为0.89,"住所"与"住处"的词向量余弦相似度为0.87,表示这两对词在语义上为近义词.

图2 skip-gram模型Fig.2 skip-gram model
2.2 不确定图
不确定图最早由Gao&Gao[14]提出,表示为一个三元组G=(V,E,p),其中V={v1,v2,…,vn}为所有顶点的集合,E={e1,e2,…,em}为所有边的集合,p={p1,p2, …,pm}表示相应的边存在的概率,当pi=0时表示边ei不存在.本文中的每条边存在的概率假设是相互独立的.
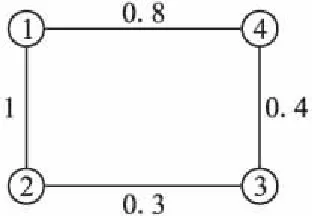

图3 不确定图及其邻接矩阵Fig.3 Uncertain graph and the adjacency matrix

3 基于不确定图的关键词抽取
本文的关键词抽取方法的主要步骤为训练词向量、文本预处理、构建不确定图、关键词抽取,流程图如图4所示. 采用维基百科中文语料库作为词向量训练集,在文本预处理阶段,采用jieba(https://github.com/fxsjy/jieba)作为分词工具,去除停用词后可以将文本转化为一个有序词组,接下来将就构建不确定图及关键词抽取做详细介绍.
3.1 构建不确定图
文献[7]中提出,对于短文本,由于文档本身没有首尾段落,本身首尾句的重要程度与其他句子没有明显的区别. 在实验中对一些新闻、评论、商品介绍等短文本研究发现,当一段文本转化为一个有序词组时,关键词一般不会出现在首尾位置;同时,关键词可以表达文本的主题意思,那么一般情况下关键词与文本中的其他词语义相近,如果使用词向量余弦相似度来表示词间的语义相似程度,那么一段短文本的关键词将具有以下两个特征:

图4 算法流程图
Fig.4 Flow chart of algorithm
1) 关键词的位置一般不位于文本的首尾且在文本中可能出现多次.
2) 关键词与文本中其他词的词向量余弦相似度较高.
根据这两个特征,可以构建词与词之间的相似度,一个文本经过分词及去除停用词的过程称为预处理过程,一个文本通过预处理过程可以得到一个长度为n的有序词组W={w1,w2,w3,…,wn},对于每个词之间做以下定义:
定义1.文本间隔:对于词wi、wj,其间隔的词数为a,则其文本间隔tDis(wi,wj)=1+a.
例1.已知短文本例文及预处理结果如下所示,由于"元宵节"在文中出现多次,因此"传统节日"与"元宵节"的文本间隔为1、25,这种情况下,将取最小值作为两个词的文本间隔,即本例中tDis("传统节日", "元宵节")=1. 因此,当某个词在文本中多次出现时,该词与其他词的文本间隔将会较小,如果首尾词在文本只出现很少次,那么其与其他词的文本间隔将会很大.
例文:每年的阴历正月十五是中国人很重视的传统节日,元宵节.正月十五日是一年中第一个月圆之夜,加上吃元宵的习俗,这个节日就和团圆两个字牢牢的联系起来.元宵节是春节之后的第一个重要节日,不管是南方北方都对这个节日比较重视,举行很多的活动来庆祝这个节日
预处理结果:每年/阴历/正月十五/中国人/重视/传统节日/元宵节/正月十五/日/一年/中/第一个/月圆之夜/加上/吃/元宵/习俗/节日/团圆/两个/字/牢牢/元宵节/春节/第一个/节日/南方/北方/都/节日/重视/很多/活动/庆祝/节日
定义2.文本局部相似度:根据前文提出的关键词特征,定义词wi、wj的在当前文本下的文本局部相似度LocalSim定义为:
(1)
其中consinSim(wi,wj)表示词wi与wj词向量的余弦相似度,规定wi与自身的文本局部相似度定为0. 例1中"传统节日"与"元宵节"的词向量余弦相似度为0.757,LocalSim("传统节日", "元宵节")=0.757.
利用文本构建不确定图的步骤如下:
1) 首先,我们定义不确定图G=(V,E,p),其中将W中的每个词作为顶点,即V={w1,w2,w3,…,wn},同时将所有顶点间加上连边,即E=V×V,边概率为两个顶点所代表的词之间的文本局部相似度,定义为:
(2)
2) 对边概率小于或等于0的边进行剪枝,剪枝完成后,删除没有连边的顶点,最终得到文本不确定图DG.
3) 若此时DG的顶点V′={w1,w2,…,wm},其邻接矩阵A表示为:
(3)
3.2 顶点密度及候选关键词评价指标

定义3.顶点密度:在指定步长l下wi的顶点密度为:
(4)
定义4.候选关键词评价指标DEN:一定步长下wi的顶点密度在利用min-max函数归一化后称为DEN(wi).
将DEN作为候选关键词的评价指标,通过计算每个词在一定步长下的DEN,可以得到候选关键词的排序.
3.3 自适应候选关键词抽取算法
结合定义3提出自适应候选关键词抽取算法,该算法通过步长自适应自动的计算得到每个词对应顶点的顶点密度,算法1给出了详细过程.
算法1.自适应候选关键词抽取算法.
输入:文本不确定图DG=(V′,E′,p)及迭代上限ul
输出:wi及DEN(wi)集合S={(w1,d1),(w2,d2),…,(wm,dm)}
1. 由DG得到边概率矩阵A
2. 令l=1
1) 计算每个顶点的密度,并按递减顺序排序
2) 当顶点密度排序与上次循环一样时,退出循环;否则l=l+1
4. 将顶点密度利用函数min-max函数归一化,其中DEN(wi)记作di
5. 输出集合S={(w1,d1),(w2,d2),…,(wm,dm)}
算法初始化步长为1,在每次循环过程中计算当前各个顶点密度并排序,随后依次增加步长,当某次循环中,顶点密度排序次序不再发生变化时,或迭代次数达到上限时则退出循环,并将所有顶点密度归一化后输出所有顶点对应的词及其DEN值.
3.4 带权重的DEN-IDF
在经过算法1处理后得到的候选关键词排序中,仍然有一些常见词排名较前,即IDF值较大的词. 因此,本文提出DEN-IDF作为关键词评价的优化标准.
对于W={w1,w2,…,wm},我们首先将其IDF值利用min-max函数归一化,定义IDF*(wi)为词wi归一化后的IDF值. 提出以下定义:
4.4 合理施肥 芝麻施肥应依据芝麻各生育阶段需肥特性、土壤肥力、品种特性、栽培条件等因素进行配方施肥[8-9]。
定义5.DEN-IDF:我们定义一个词wi的DEN-IDF值为:
DEN-IDF(wi)=a·DEN(wi)+(1-a)·IDF*(wi)
(5)

图5 关键词抽取算法对比Fig.5 Comparison of keyword extraction algorithms
关于权重a的取值,通过对训练集数据的实验得到a的近似取值为0.6,具体实验方法及过程在第4章介绍. 图5显示的例1中的文本分别使用TF-IDF、TextRank及DEN-IDF得到的top-5关键词. 可以看出例1中例文的关键词应为"元宵节",相比TF-IDF及TextRank,DEN-IDF可以得到更准确的结果.
4 实 验
4.1 实验数据及评价指标
本文使用维基中文百科作为词向量训练数据,使用搜狗实验室新闻语料集作为关键词抽取算法测试数据,其中维基中文百科文档数在40万左右,搜狗实验室语料集中,选取10个领域,每个领域随机选取10篇文档,一共100篇作为测试文档集,并人工为每篇文档设置5个关键词. 其中本文将字数在350字以下的文档作为短文本,测试文档集中短文本一共有36篇,非短文本一共有64篇. 利用此文档集进行关键词抽取实验,评价指标包括准确率P(precision)、召回率R(recall)、F值F(F-measure),其中具体公式如下:
(6)
(7)
(8)
4.2 DEN-IDF权重选择
为了获取最为合适的权重a,我们取a值分别为0.15、0.3、0.45、0.6、0.75、0.9,分别每个权重对测试文档集每篇文档抽取DEN-IDF最高的5个词作为关键词,并计算其各自的准确率. 实验结果如图6所示.

图6 权重准确率对比
Fig.6 Precision of different weight
通过图6可以发现,在权重取0.6时,其准确率达到最高,因此,本文将a近似取值为0.6.
4.3 关键词抽取实验
为了考察DEN-IDF关键词抽取方法的有效性,实验中使用传统的TF-IDF、TextRank及DEN-IDF对测试文档集每篇文档进行关键词抽取,分别抽取top3、top5、top7个词作为关键词,计算各自准确率、召回率及F值.实验结果如表1、表2和表3所示.

表1 关键词抽取准确率实验Table 1 Keyword extraction experiments about precision
分析上述实验结果可得以下结论:
1) 算法抽取关键词的个数对关键词抽取的效果影响较大. 由表1及表2可以发现,TF-IDF、TextRank及DEN-IDF在选取top3词作为关键词时其准确率均最大,召回率最小,随着选取关键词数量的增加,准确率逐渐下降,而召回率逐渐增加.
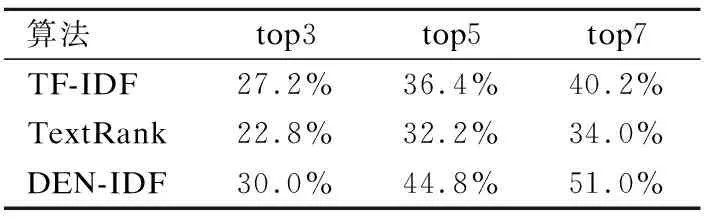
表2 关键词抽取召回率实验Table 2 Keyword extraction experiments about recall
2) 传统的关键词抽取算法整体效果较为一般. 由表1、表2及表3可以发现,对于抽取不同个数的关键词,TF-IDF的准确率平均值为36.8%,召回率平均值为34.6%,F值平均值为34.6%;TextRank的准确率平均值为31.5%,召回率平均值为29.7%,F值平均值为29.7%. 可以看出,对于中短篇幅的文档,基于词频统计的TF-IDF效果略优于基于网络图的TextRank,但总体效果一般.

表3 关键词抽取F值实验Table 3 Keyword extraction experiments about F-measure
3) DEN-IDF较传统关键词抽取算法,能显著提升关键词抽取效果. 由表1、表2及表3可以发现,对于抽取不同个数的关键词,DEN-IDF较TF-IDF,准确率平均提升8%,最大提升11%,召回率平均提升7%,最大提升9%;F值平均提升7%,最大提升9%;DEN-IDF较TextRank,准确率平均提升12%,最大提升17%,召回率平均提升12%,最大提升17%,F值平均提升11%,最大提升14%.同时,DEN-IDF的准确率平均值达到了43.7%,召回率平均值达到了41.9%,F值平均值达到了41.6%.
4) DEN-IDF针对短文本抽取关键词时也能得到良好的效果. 表4为分别对测试文档集中的短文本及非短文本抽取top5词作为关键词时的准确率数据,其中TF-IDF及TextRank在短文本数据下的准确率分别为31.2%及27.1%,说明其在面对短文本时的效果较差. DEN-IDF在面对短文本时准确率比TF-IDF提高了9.3%,比TextRank提高了13.4%,达到了40.5%. 说明DEN-IDF在针对短文时同样能保持良好的效果.

表4 短文本/非短文本关键词抽取实验Table 4 Keyword extraction experiments about short text/ non-short text
综上,在未加词性、主题等外部标签的情况下,本文提出的基于不确定图的无监督关键词抽取算法较传统算法效果提升明显,面对短文本及非短文本都能取得良好的效果. 如果结合例如文[7]中的候选词方法将会进一步提高关键词抽取效果.
4.4 算法优势分析
DEN-IDF通过构建全新的词间关系不确定图模型及两层关键词评价方法来改进传统关键词抽取算法存在的缺点. 首先结合词向量余弦相似度及词间的文本间隔定义了新的词间关系,这种关系不仅能体现词间语义关系也能体现词间的句中相对位置关系及词频. 随后将一个句子转化为词间关系的不确定图模型,并通过顶点间的转移概率提出了顶点密度概念,当某个词具有高密度时代表了该词与其他词的关系紧密,因此将顶点密度作为候选关键词评价标准,最后通过IDF得到了关键词的优化标准. 合理的词间关系不确定图模型转换方式及两层式的关键词评价标准使得DEN-IDF较传统的无监督关键词抽取算法大大的提高了准确率.
5 结 论
本文主要研究了基于不确定图的中文关键词抽取算法,首先利用word2vec构建词向量模型,结合词向量余弦相似度提出了词间的文本局部相似度,以此为基础构建不确定图,并将归一化后的顶点密度DEN作为候选关键词的评指标,最后使用IDF来过滤常用词,提出了DEN-IDF作为关键词评价的优化标准.相比传统的关键抽取方法,DEN-IDF兼顾了词义、词频及词的文本位置等因此,关键词的P、R、F值相较基于网络图的TextRank各提升了13%左右,相较TF-IDF各提升了7%左右,在短文本及非短文本测试集下准确率都达到了40%以上.在实验过程中发现,提高word2vec模型的质量可以提高关键词抽取的效果,在未来的工作可以考虑,通过主题划分的方式来提高word2vec模型,以改进本文关键词抽取算法及其他领域的推广研究.
猜你喜欢
客联(2022年3期)2022-05-31
中等数学(2021年9期)2021-11-22
中等数学(2021年8期)2021-11-22
中国新闻周刊(2021年26期)2021-07-27
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
健康体检与管理(2021年10期)2021-01-03
电脑爱好者(2017年7期)2017-05-06
