
基于FPGA动态重构的卷积神经网络硬件架构设计*
2019-03-22 08:36何凯旋
网络安全与数据管理 2019年3期
何凯旋,袁 勋,陈 松
(1.中国科学技术大学 微电子学院,安徽 合肥 230026; 2.中国科学技术大学 微纳电子系统集成研究中心,安徽 合肥 230026)
0 引言
卷积神经网络是一种多层神经网络,通常由卷积层、池化层和全连接层组成。在图像处理领域,卷积神经网络主要用于对输入图像的特征进行提取分类,以识别位移、缩放与其他形式扭曲不变的二维图形,比如应用于手写数字与车牌的识别[1-2]。ImageNet数据集的推出,使卷积神经网络在计算机视觉应用方面取得巨大成功,更加推动了卷积神经网络的发展[3]。
卷积神经网络具有很高的并行性,其间的运算操作由大量的乘法与加法组成,是一种运算密集性很高的网络。FPGA设计灵活,大量的片上资源可以满足卷积神经网络的运算要求,不仅可以充分发挥卷积神经网络的并行性,还可以有效降低设计成本。
随着卷积神经网络的发展,其深度和复杂度都在上升。从大量的前人工作中可以发现,卷积神经网络识别的正确率与其层数规模基本成正比,在硬件实现的阶段,便对FPGA的片上资源需求提出了更大的挑战。因此,本文提出动态重构的设计方法来降低卷积神经网络所需的硬件资源。
基于FPGA的动态重构技术就是利用“时分复用”的思想,将FPGA的配置区域划分为静态区域与重构区域。在重构控制器的控制下,重构区域从存储器中加载不同的配置文件,经过一定的配置时间,重构模块加载完成,之后重构区域可以开始执行不同的逻辑功能。如果重构区域的配置时间大于两个重构模块使用时间间隔,便会延长系统的执行时间,反之,便可以隐藏在执行时间中。当一个重构区域重配置时,FPGA内部其他区域的正常运行不受影响。通过应用FPGA可动态重构的特性,可以实现FPGA上资源的“时分复用”,对部分模块进行动态重构,提高了系统的灵活性,充分利用了FPGA的硬件资源,节约了成本。动态重构技术具有很高的拓展性,可以应用于航天、国防等众多领域[4]。
1 基本原理
1.1 卷积神经网络的基本原理
卷积神经网络通常由卷积层、池化层与全连接层组成。卷积层与池化层交替连接构成卷积神经网络的前几层,一个或者几个全连接层构成卷积神经网络的后几层,作用是对前面的网络层产生的特征进行识别与分类。通过局部连接和神经元的共享权重,可以大大减少卷积神经网络所需的参数,且卷积神经网络的执行效率高于全连接神经网络。结合池化层的功能,使得图像特征具有较好的平移、缩放和扭曲不变性[5]。
本文使用的优化Lenet-5手写体识别卷积神经网络是一个典型的多层感知网络[1],由三层卷积层(C1、C3、C5)、两层池化层(S2,S4)与一层全连接层(F6)组成,如图1所示。

图1 优化的Lenet-5网络
其中,C1层为单卷积层,实行卷积运算,有6个卷积核,输入1幅32×32的图像,输出6幅28×28的特征图像。S2层为2×2的平均池化层,输入6幅28×28的特征图像,输出6幅14×14的特征图像。S2与C3之间有一个激励层。C3为卷积层,输入6幅14×14的特征图像,输出16幅10×10的特征图像,每个输出由若干个输入图像卷积后相加再加偏置得到。S4层为2×2 的平均池化层,输入16幅10×10的特征图像,输出16幅5×5的特征图像。C5为卷积层,输入16幅5×5 的特征图像,输出120幅1×1的特征图像。F6为全连接层,输入为1×120的特征图像,输出为1×10的特征图像,值最大的即结果。
卷积层生成的输出特征图可由(1)式计算得到:
Aki=f(Wki⊗Aki-1+bki)
(1)
其中,Aki表示第i层的第k个特征图,第i层的第k个卷积核的特性由权重矩阵Wki和偏置项bki决定。
卷积神经网络由于其自身算法的运算密集性,在硬件实现阶段对LUT、DSP等资源提出了很高的要求,所以降低卷积神经网络的硬件资源占用量势在必行。
1.2 FPGA动态重构的基本原理
基于FPGA动态可重构技术就是利用“时分复用”的思想,将设计从一个纯空间的数字逻辑系统转化为在时间、空间混合构建的数字逻辑系统。这种技术使FPGA资源利用率成倍提高,实现系统功能所用的硬件规模大大下降[6]。
本文采用模块化设计方法实现FPGA的动态部分重构,其原则是将重构逻辑和静态逻辑划分到不同的区域中。根据要求从重构区域中替换需要更改的模块,从而实现动态重构的功能,如图2所示。

图2 模块化设计示意图
动态重构的流程需要使用动态重构控制器来进行控制。动态重构控制器接收静态区域中产生的重构触发信号,然后对相应的重构区域进行重配置。
动态重构控制器从非易失性存储器(例如Flash)中检索部分比特流文件,将其传送到内部配置端口ICAP(Internal Configuration Access Port)。动态重构制器可以置于外部设备(例如处理器)中,也可以放在需要重构的FPGA设备中。与静态区域中的其他逻辑一样,动态重构控制器在整个动态重构过程中不间断地运行。
Vivado设计套件对动态重构的设计进行了软件上的支持。在Vivado中,提供了动态重构设计的专用流程,并且提供了动态重构控制器(Partial Reconfiguration Controller,PRC)IP核[7-8],用户可以直接使用此IP核来进行动态重构流程的设计。
2 硬件架构设计
2.1 静态卷积神经网络加速器
静态卷积神经网络加速器的总体硬件架构图如图3所示。在第一层(C1)、第三层(C3)与第五层(C5)卷积层阶段,分别采用了6个、6个、10个卷积模块并行运算。其中第二层池化层(S2)与第四层池化层(S4)分别与之前的C1和C3构成流水线结构。最后一层全连接层(F6)直接复用C5层的10个卷积模块。

图3 总体架构图
在第一层卷积层(C1)中,输入为32×32的输入图像,输出为6个通道的输出特征图。所以在C1中,设计了6个卷积模块并行地对6幅输出特征图进行计算。在每个卷积模块中有5个PE单元,它们将25个乘加运算分解为5个1×5的乘加运算并行计算。
C1之后的是第一层池化层(S2),输入为6幅28×28的特征图,输出为6幅14×14的输出特征图。所以在S2中,设计了6个池化模块并行地对6幅输入特征图进行池化运算。C1与S2采用流水线结构,S2阶段首先对C1阶段生成的像素点进行缓存,当缓存的像素点可以形成一个2×2的池化区域时,开始S2层的运算。
第二层卷积层(C3)在S2之后开始运算。C3层的输入图像为6幅14×14的输入特征图,输出为16幅10×10的输出特征图(与6幅输入特征图部分连接)。所以在C3层中设计了6个卷积模块对6幅输入特征图进行卷积操作,串行地输出16幅输出特征图。卷积模块中的PE设计同C1层。
第二层池化层(S4)采用一个池化模块对串行输出的16幅输出特征图进行下采样,输出16幅5×4的输出特征图。流水线设计同上。
第三层卷积层(C5)的输入为16幅5×5的输入特征图,输出为120幅1×1的输出特征图。所以设计了10个卷积模块循环12次对这120个输出特征图进行计算。
最后一层全连接层(F6)输出为1×10的数组,代表着手写体的识别结果。这里复用了C5层的10个卷积模块来对这十个值并行计算。
卷积神经网络涉及的一个核心运算是图像的卷积运算。由于Lenet-5网络卷积层的卷积运算规模为5×5,本文的设计将卷积运算分成等量的5组,每组中的5个乘加运算采用二级流水线的结构。每一组的乘加运算都会输出一个结果至下一组,下一组将自己的乘加运算结果加上上一组的结果后,再继续对下一组输入。最后由第五组累加前面4组的乘加和进行输出。本文设计的PE结构图如图4所示。PE工作时乘法器每个周期都有输入数据,既提高了吞吐率又提高了硬件的利用率。

图4 PE架构图
2.2 动态重构卷积神经网络加速器
本文设计的动态部分重构方案把FPGA片上区域分为静态区域(Static)与四个动态重构区域(PR1、PR2、PR3、PR4)。每个重构区域都分配了三个不同的重构模块用于分时配置。
将重构模块分配给不同的重构区域时,遵循了配置进同一个重构区域的不同模块,其占用的片上资源数目要尽量相近的原则,以降低对片上资源的浪费[9]。本文的设计对重构模块的分配情况如表1所示。在不同的阶段,相应的重构模块被配置进对应的重构区域中,与静态区域中的其他模块共同完成这一阶段的运算。
如表1所示,整个神经网络的识别过程分为C1-S2(第一层卷积层与第二层池化层)、C3-S4(第三层卷积层与第四层池化层)与C5-F6(第五层卷积层与第六层全连接层)这三个阶段。

表1 重构模块分配
在第一个阶段,四个重构区域将会配置C1层与S2层所需的功能模块。在S2层的输出特征图存储结束之后,部分重构控制器通过ICAP接口读取C3-S4阶段的配置文件,对四个重构区域进行新的配置。C5-F6阶段同理。在C5~F6阶段的运算完成后,卷积神经网络输出一个识别结果,此时开始新的C1-S2阶段的重构模块配置。
重构设计硬件架构图如图5所示。对于重构流程的控制、配置文件的扫描提取、配置文件的存储,分别使用了:

图5 硬件架构图
(1)Xilinx®PRC(Partial Reconfiguration Controller) IP:Xilinx提供的PRC IP为部分动态重构提供了管理功能,它可以监测到重构触发信号,并对重构的流程进行控制[8]。
(2)ICAP (Internal Configuration Access Port):Xilinx FPGA的动态部分重构设计要基于ICAP接口来实现,它用于检索与传送存储于非易失性存储器中的配置文件,并且可以通过部分重构控制器来控制[9]。
(3)BPI(Byte-wide Peripheral Interface) Flash:本文的设计中采用了FPGA开发板上的BPI Flash来进行所有配置文件的存储。BPI Flash在存储结构上属于Nor Flash,其×16位宽的数据总线可以提供比SPI闪存更快的配置,并且拥有比SPI闪存更大的容量[10]。
当重构区域需要重配置时,会产生一个特定的触发信号。PRC捕捉到触发信号后,通过ICAP端口提取存储至BPI Flash的配置文件。ICAP作为FPGA的内部配置端口,和SelectMap端口功能相似,它会在PRC的控制下对FPGA进行动态配置。
3 实验与评估
本文对Lenet-5手写体识别网络的动态重构设计,采用了Xilinx-VC707开发板上进行硬件实现。代码编写采用Verilog硬件描述语言,使用Vivado IDE 2018进行仿真实现,软件环境为Windows 10。
3.1 硬件资源评估
对Lenet-5卷积神经网络的静态设计(不使用动态部分重构)与动态部分重构设计进行了对比。使用了动态部分重构方法的设计相比静态设计,在片上资源的使用量上,尤其是DSP的使用量上有了极大的降低。具体评估结果如表2所示。
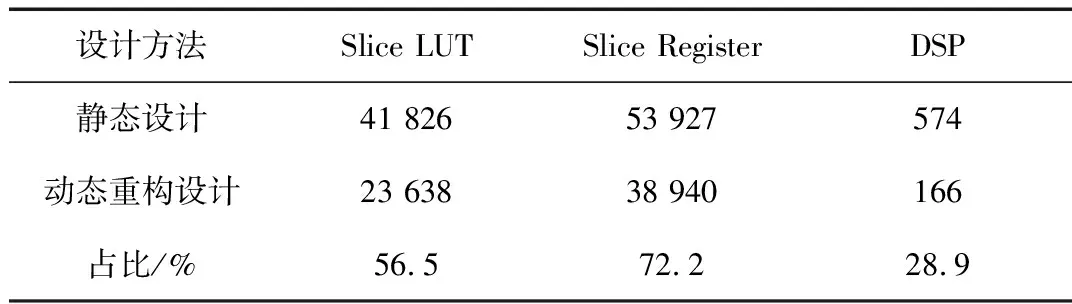
表2 资源占用情况
在动态重构设计后,卷积神经网络加速器所用Slice LUTs资源降低至静态设计的56.5%,Slice资源降低至静态设计的56.5%,Slice Register资源降低至静态设计的72.2%,DSP资源降低至静态设计的28.9%。可见,动态重构设计可以有效地减少卷积神经网络加速器占用的硬件资源,提升资源利用率,节约硬件成本。
3.2 时间功耗评估
FPGA动态重构的配置速度基本由配置文件的大小和ICAP端口的带宽所限制[9]。
在本文的设计中,共划分了四个重构区域,每个重构区域有三个分时配置的重构模块,所以一次完整的手写体识别网络共需要1个静态配置文件与12个部分配置文件。总的配置文件大小约为27 MB。
VC707所属的Virtex系列开发板,ICAP配置端口在100 MHz的最大时钟频率下的最大带宽为3.2 Gb/s[9]。加上卷积神经网络本身的识别时间,计算得出总时间为20.3 ms。对比基于ARM Cortex A9处理器的软件实现,如表3所示,在时间与功耗上有着很大的提升。

表3 不同实现方式识别100次的用时与功耗
由于ICAP内部配置端口的带宽限制,动态重构之后完成一次手写体识别所需的时间,相较在FPGA上直接进行静态实现所需的时间会有所延长。这是因为在重构模块需要工作时,重构区域还未重配置完成,这些等待重构区域而配置完成的时间拉长了整个系统的执行时间。
在未来的设计中,为了更好地发挥动态重构的优势,可以选取更大规模的卷积神经网络,并将重构粒度缩小,使配置时间可以隐含在执行时间当中。当然,相信未来的科研工作者们会对配置端口带宽进一步提升,增大动态重构的优势。
4 结论
本文介绍了动态部分重构的思想与设计方法,对Lenet-5手写体识别卷积神经网络进行了动态重构设计。在文中对部分动态重构设计中要用到的ICAP接口与BPI Flash进行了简要的说明。在文章的最后,给出了本文的设计在Xilinx VC707上实现所需的资源、时间与功耗。实验表明,动态重构设计可以有效降低卷积神经网络硬件实现阶段所需的片上资源,大大提升硬件资源利用率,使卷积神经网络的硬件实现更加通用灵活。
本文首次将动态重构技术应用于卷积神经网络的硬件实现中,可以有效解决卷积神经网络因所需硬件资源过多而不能完整放置于硬件的问题。
限制动态重构配置速度的主要为ICAP配置端口的带宽,希望未来科研工作者可以对此进步一提升,更好地推动动态部分重构的发展。
猜你喜欢
当代陕西(2022年4期)2022-04-19
摄影世界(2022年1期)2022-01-21
北京航空航天大学学报(2021年9期)2021-11-02
西安交通大学学报(2021年6期)2021-06-07
中国生殖健康(2020年7期)2020-12-10
无线互联科技(2020年15期)2020-11-10
科技传播(2020年6期)2020-05-25
电子制作(2019年13期)2020-01-14
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
