
基于云芯一号的分布式文件系统设计与实现*
2019-03-22 08:36王界兵王文利董迪马
网络安全与数据管理 2019年3期
王界兵,王文利,董迪马
(深圳前海信息技术有限公司,广东 深圳 518000)
0 引言
网络技术的飞速发展带来了数据量的指数级增长,互联网传统的C/S架构(客户端-服务器)也面临着各类数据高峰和偶有发生的数据爆炸的挑战。Google首席执行官于2006年8月9日在SES San Jose 2006搜索引擎大会上首次提出云计算[1]的概念,云计算技术应运而生,其中又以开源的分布式系统架构Hadoop[2]最为著名。自发布后世界上多数互联网公司和数据库厂商已支持使用,其中多家公司进行了更高效率的改进和研发[3]。
然而,随着大数据现代化的逐步推进以及各类大数据处理技术的快速发展,现有的超大数据集甚至大数据集的应用程序在基于原有的低廉、低性能服务器及硬件上的Hadoop架构上的处理效率已大幅度降低。为了解决上述性能耗损的问题,各企业不得不重新购置高性能服务器、部署相关实验环境,这无疑会带来新的经济挑战和各类资源适配问题。
本文基于上述问题,提出基于自主研发的云芯一号DX硬件加速卡的分布式系统设计,在无需改变现有X86架构上进行硬件扩充和优化,并在此基础上采用Hadoop分布式文件系统对大量数据进行处理。
1 相关技术简介
1.1 Hadoop
众所周知,Google研发的Apache Hadoop是基于Google云计算技术的开源实现,其独特的分布式架构让物理隔离上的低廉(low-cost)服务器可以通过互联网传输自身的计算能力,并同时具有高可靠性、高扩展性、高效性、高容错性、低成本等优点[4]。Hadoop的核心组件主要包括Google GFS、BigTable、MapReduce。其中,Google GFS也同时提供一定程度的容错功能[5],其开源实现就是分布式存储模型——HDFS[6](Hadoop Distributed File System)。在完成分布式数据库和分布式文件系统后,一种分布式的计算模型——MapReduce也应运而生,其运行原理是将需要执行的任务进行分割并分配至各个节点,分配的任务由各个节点分别执行,最后将执行结果合并形成总体计算结果。接下来分别对HDFS和MapReduce两个组件进行介绍。
1.2 分布式存储模型(HDFS)
分布式存储模型HDFS是Google File System(GFS)的开源实现[7]。作为最底层的组件,HDFS的体系结构是一个主从结构,如图1所示。

图1 HDFS架构图
如图1所示,在HDFS架构中,主节点Namenode只有一个,而从节点Datanode可以有一个或者很多个。主节点作为一个管理的主服务器,系统中文件的命名空间由其来管理,同时各终端对文件的访问协调工作也由它负责。当存储的文件通过用户请求发送到HDFS中时,该文件被分成多个数据块并将这些数据库块并行复制到多个DataNode数据节点中。分割的数据块大小及数量是在创建文件时由客户机决定的(可以通过配置进行适宜调整),最终由NameNode主节点来控制所有文件操作。在HDFS中,各类节点都可以部署在配置普通的硬件上,通常运行HDFS的服务器上运行Linux操作系统,其开源的属性和对Hadoop的友好性是其他系统无法比拟。Hadoop基于最流行的Java语言来开发,且HDFS内部的所有通信都基于标准的TCP/IP协议,最大程度减轻了开发成本和部署成本。
1.3 分布式计算模型(MapReduce)
相比功能较为单一的文件系统HDFS来说,MapReduce则被称为是到目前为止最为成功、最广为接受和最易于使用的大数据并行处理技术。
简单来说,MapReduce中的算法模型就是一种简化并行计算的编程模型。继承了分布式的设计理念的MapReduce将具体应用切分为多个小任务,分配至各个节点并行执行,利用集群服务器的并行计算能力来并行处理,完美解决了传统单机环境中并行能力和计算能力不足的缺点[8]。
MapReduce的主要组成是函数性编程中的Map和Reduce函数,其中Map函数转换一组数据为Key/Value列表,而Reduce函数则根据Map函数产生列表的Key值来缩减这个列表,再将最终生成的列表应用于另一个Reduce函数,得到相同的结果,具体流程如图2所示。
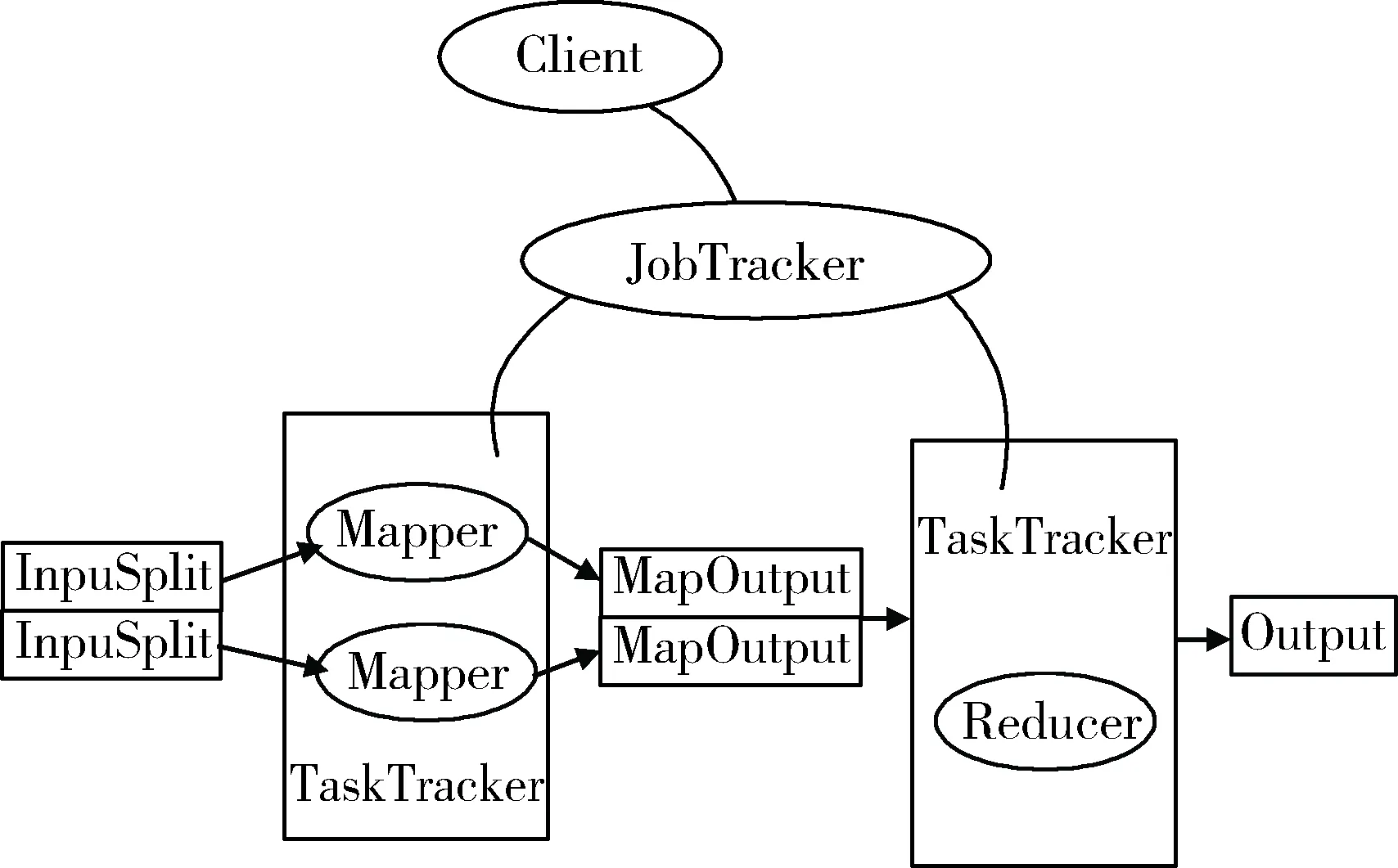
图2 MapReduce数据处理流程图
MapReduce中的每个元素都是被独立操作的,且原始列表没有被更改,然后再创建了一个新的列表来保存新的答案。基于以上原理,Map操作是可以高度并行的,这对高性能要求的应用以及并行计算领域的需求非常有用。而化简操作指的是对一个列表的元素进行适当的合并。
2 云芯一号——DX SDK硬件加速卡
云芯一号是一张我们拥有自主知识产权的硬件加速卡,可以使用任何可用的12V PCle插槽供电,如图3所示。云芯一号支持8路双工收发器,可插入x8或更大的PCle 3.0插槽。所有和云芯一号之间的通信都通过PCle接口进行。

图3 云芯一号硬件加速卡
在软件架构方面,云芯一号主要由以下几个软件模块组成,如图4所示。

图4 云芯一号软件架构图
具体结构如下:
(1)服务助理基础设施(SAI):为其他模块提供基础服务。SAI由OS抽象层(OSAL)、日志和文件解析器组件组成。
(2)API层:云芯一号提供Raw加速(原始)API来连接用户应用程序。Raw Acceleration API利用云芯一号上的所有功能,包括压缩、加密、认证、RNG和PK操作。
(3)Frontsurf服务框架:Frontsurf Service Framework(FSF)为API层提供算法加速。所有与芯片组无关的代码都位于FSF中,而所有与芯片组相关的代码位于设备专用驱动程序中。FSF模块管理所有使用设备特定驱动程序注册的会话、密钥和设备,从而实现硬件加速和软件库操作。FSF从API层检索操作,将这些操作转换为硬件命令,将命令提交给硬件,检索完成的命令,并将完成的操作返回给API层。FSF还管理负载平衡、会话上下文和密钥池。如果硬件不可用于数据操作,则FSF与软件库一起工作以提供软件支持以进行各种操作,例如压缩、认证、加密和PK操作。
(4)设备专用驱动程序:设备专用驱动程序(DSD)是一个与芯片组相关的模块。设备专用驱动程序为Exar服务框架(ESF)提供统一的硬件接口。DSD将每个设备的特定结构格式转换为ESF的统一结构。
目前,云芯一号支持用于XR9240协处理器的DSD,用于软件库的DSD以及用于传统820x处理器的DSD。DSD的单个实例将管理系统中安装的该类别的所有设备。
(5)软件库:软件库执行软件中的压缩、认证、加密和公钥操作等操作。如果云芯一号发生错误或正在从错误中恢复,或者系统中没有可操作的Exar设备,则软件库将作为设备特定的驱动程序来实现,以模拟硬件。
3 基于云芯一号的分布式文件系统
在分布式文件处理系统中,文件的存储和传输性能是由组成该存储系统的多个模块相互作用所决定的。而传统HDFS中,文件在存储前并不会进行相关的压缩,即使有也是依赖CPU进行软压缩处理。在基于云芯一号的分布式文件处理系统中,对文件进行分布式存储前,将使用云芯一号对文件进行硬件压缩,在大幅度减少了文件大小的同时避免了传统存储过程中因需要对文件压缩而产生的CPU额外使用压力。另外,通过硬件上的独立压缩,文件的安全性和完整性上也得到了稳定的提高。显然,压缩后的文件在磁盘中IO时间、HDFS的各个节点之间的传输时间得以大幅减少,其架构图如图5所示。

图5 基于云芯一号的分布式文件系统
具体流程包括:
(1)客户端将需要存储的文件发送给云芯一号进行压缩处理。
(2)云芯一号返回压缩处理后的文件给HDFS Client。
(3)Client调用DistributedFileSystem的create方法创建一个新的文件。
(4)DistributedFileSystem通过RPC调用Name Node节点上的接口,创建一个没有blocks关联的新文件。创建前,Name Node会做各种校验,如果校验通过,Name Node就会记录下新文件,否则就会抛出IO异常。
(5)前两步结束后会返回FSDataOutputStream的对象,FSDataOutputStream被封装成DFSOutputStream,DFSOutputStream可以协调Name Node和Data Node。客户端开始写数据到DFSOutputStream,同时DFSOutputStream会把数据切成一个个小packet,然后排成队列data queue。
(6)DataStreamer会去处理接收data queue,它先问询Name Node这个新的block最适合存储的在哪几个Data Node里,把它们排成一个pipeline。
(7)DFSOutputStream还有一个队列叫ack queue,也是由packet组成的,等待Data Node的收到响应,当pipeline中的所有Data Node都表示已经收到的时候,akc-queue才会把对应的packet包移除掉。
(8)客户端完成写数据后,调用close方法关闭写入流。
(9)DataStreamer把剩余的包都刷到pipeline里,然后等待ack信息,收到最后一个ack后,通知Data Node把文件标示为已完成。
4 实验对比
通过上文描述,完成了基于云芯一号的分布式系统的设计和实现。接下来通过纯压缩测试对比实验和HDFS数据存储速度对比实验来验证所提出的分布式文件系统的性能和优越性。
4.1 纯压缩测试
纯压缩测试是为了对比传统的基于CPU的各类HDFS软压缩特性和基于云芯一号芯片的硬件压缩能力。为此测试了一组随机大小(从最小数据大小7.27 MB到最大数据大小100 MB),总共88 132 MB的数据集的压缩速度,测试环境如下:CPU:Intel(R) Core(TM) i5-4590 CPU @ 3.30 GHz;MEM:DDR3 -1 333 MHz 64 GB。
基于云芯一号的硬件压缩的进程压缩速度在1 508.7 MB/s(>1 500 MB/s)。与此同时,也将该数据集在传统HDFS上的各类软压缩软件上进行了相同实验,得到压缩性能对比表如表1所示。
从表1可以清楚地看出,基于硬件加速的云芯一号芯片在同样大小的原始文件上,无论是压缩速度、解压速度还是压缩后的文件大小都占据绝对的优势地位,尤其是压缩速度和解压速度两个指标更是较普通的软件压缩高10倍左右。为了更直观地体现压缩速度的对比性,将测试的随机大小文件集群的压缩速度进行了同一坐标对比,如图6所示。
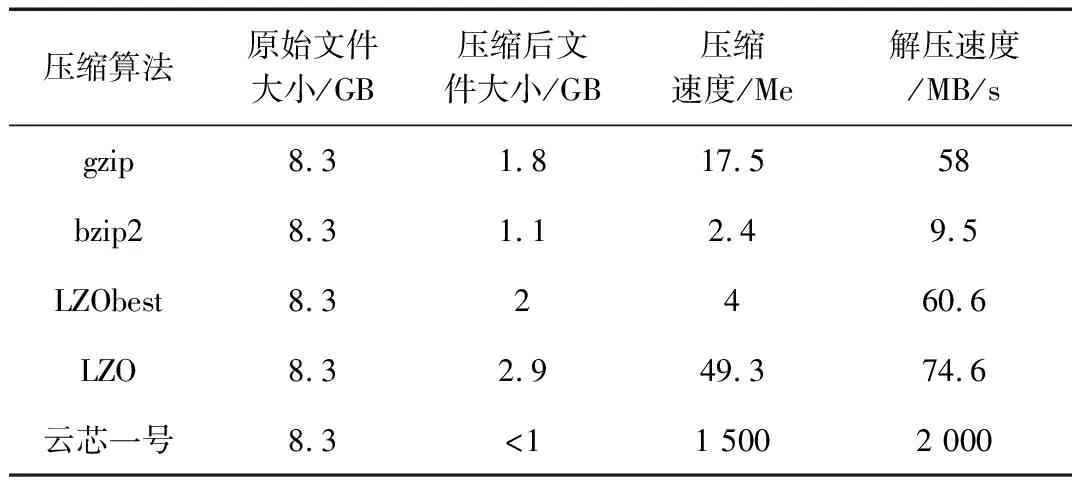
表1 各类压缩软件和云芯一号的文件压缩性能对比
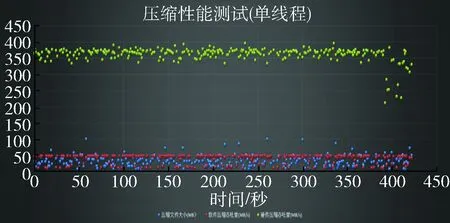
图6 压缩速度位于同一坐标上对比
4.2 HDFS写入和读取测试
在完成了纯文件压缩对比后,进行了在HDFS平台下的各类文件基于不同压缩渠道的写入和读取对比测试。
搭建了一个5节点的HDFS平台,包括一个Client Node、一个Name Node、三个Data Node,其中云芯一号部署在Client Node上。分别测试了10 MB、100 MB、1 GB、10 GB的文件在不同压缩方法下基于HDFS平台的写入和读取速度,如图7所示。

图7 HDFS上基于各类压缩方式上写入读取平均数据对比
选取了各类大小的文件,并测试了其在HDFS上经过各类压缩方式后的写入和读取的速度,然后取其平均值。通过对比可知,基于云芯一号硬件加速卡的HDFS系统在各类大小文件的写入和读取速度上都远远优于传统的软件压缩方式。从而在分布式文件系统的最基础的功能上完成了实质性的优化和性能提升。
5 结论
本文着力于提高分布式文件处理的效率和性能,在从数据结构以及算法应用上进行优化外,也思考从数据处理的平台和依托的硬件环境进行思考和创新。因此,本文提出基于云芯一号硬件加速卡的分布式系统设计,在传统的X86架构上进行硬件扩充和优化,在此基础上采用Hadoop分布式文件系统对大量数据进行处理。通过不同环境的实验结果对比,得出无论是在纯文件压缩上还是HDFS平台中文件的写入读取速度上,本文提出的系统在性能上都远远优于传统压缩方式,为后续工作带了更好的创新方向和架构支撑。
猜你喜欢
河南科技学院学报(自然科学版)(2020年2期)2020-05-22
小型微型计算机系统(2020年5期)2020-05-14
火力与指挥控制(2020年1期)2020-03-27
电子制作(2019年22期)2020-01-14
电脑报(2019年10期)2019-09-10
World Journal of Diabetes(2019年3期)2019-04-16
电子制作(2018年17期)2018-09-28
制导与引信(2017年3期)2017-11-02
燕山大学学报(2015年4期)2015-12-25
汽车电器(2014年5期)2014-02-28
