
整体车牌图像超分辨率重建研究
2019-04-19 05:18倪申龙曾接贤周世健
计算机技术与发展 2019年4期
倪申龙,曾接贤,周世健
(南昌航空大学,江西 南昌 330063)
0 引 言
随着车辆保有量的增加,在给人们出行带来方便的同时也极大增加了交警执勤的任务。因此,车牌识别任务已经成为交管部门对车辆管理的重要工作之一,而准确、有效的识别车牌将为交管部门的交通执法和破案带来了极大的便利。准确、有效的车牌识别的前提是所获取到的车牌图像具有很高的分辨率。然而现实生活中,由于摄像设备、拍摄角度、光线、天气和车辆运动等因素,往往得到的车牌图像是模糊的,大大降低了对车牌的识别率。因此,针对车牌图像分辨率低的问题,文中通过超分辨率(super resolution,SR)重建[1-2]的方法来增强整体车牌图像的空间分辨率。
图像超分辨率重建技术是一种采用信号处理和图像处理的方法,通过软件算法的方式从一幅或多幅低分辨率(low-resolution,LR)图像中重建出一幅高分辨率(high-resolution,HR)图像的图像处理技术。随着图像超分辨率重建理论和技术的日益成熟,超分辨率重建技术已经广泛应用于卫星遥感、军事侦察、医学影像、视频监控和数字电视等领域。
车牌识别[3-6]是图像处理领域中一个经典并具挑战性的难题,而车牌图像的分辨率高低最能影响车牌识别的成功率。
传统的车牌识别方法采用分割字符的方式,即将车牌图像上的字符单个分割出来进行单独识别,这样不仅增加了识别难度,而且增加了车牌识别的时间。近年来,基于深度学习[7-10]的卷积神经网络算法在行人检测[11]、目标跟踪[12-13]、人脸识别[14]等图像处理领域应用广泛,取得了非常好的效果。Dong等[10]提出了SRCNN(super resolution convolutional neural network),将深度学习应用在图像超分辨率重建领域,取得了显著效果。
鉴于深度学习在图像处理领域取得的显著效果,文中重点研究利用SRCNN网络来重建高分辨率整体车牌图像,提出一种基于卷积神经网络的整体车牌图像超分辨率重建算法(LPSRCNN)。该算法不需要通过单独分割车牌字符单独识别,而是直接学习网络映射重建出高分辨率车牌图像,从而达到识别整体车牌图像的效果。
1 算法描述
基于深度学习的卷积神经网络直接学习低分辨率车牌图像和对应的高分辨率车牌图像之间的映射关系F。这里所说的映射就表示为一个深层的卷积神经网络,该映射将低分辨率车牌图像Y作为网络输入,然后输出对应的高分辨率车牌图像F(Y)。假设原始高分辨率车牌图像表示为X,目的是希望输出的高分辨率车牌图像F(Y)尽可能地接近原始高分辨率车牌图像X。
在建立模型之前,首先要做的是获取低分辨率车牌图像作为模型输入图像Y,这是该模型中唯一的一个预处理过程。对原始的高分辨率车牌图像先利用双三次插值法Bicubic进行下采样,然后再利用相同的缩放因子上采样到跟原始图像一样的尺寸,得到的低分辨率图像即为网络模型的输入。针对输入图像是RGB图像的情况,先将图像从RGB颜色空间转换到YCbCr颜色空间,并且只对其中的Y通道(亮度通道)进行重建,因为人眼对亮度比对颜色更敏感。其余的Cb、Cr通道均采用双三次插值法Bicubic缩放到目标尺寸大小。
1.1 网络模型
提出的LPSRCNN模型由三层卷积层构成:特征提取层、非线性映射层和重建层。网络模型如图1所示。
对网络的前两层,文中选用修正线性单元(rectified linear unit,ReLU)[15-16]作为网络模型的激活函数,因为ReLU形式简单,计算简便,运算量小,能加快模型的收敛速度,并且可以有效避免在训练网络过程中产生的“梯度爆炸/消失”的问题[17]。ReLU模型如图2所示。
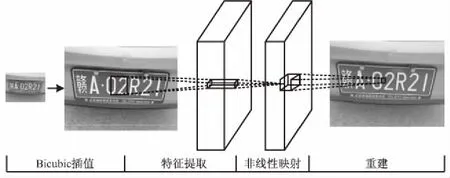
图1 LPSRCNN模型示意

图2 ReLU模型
ReLU数学计算公式为:

(1)
在卷积层中,前一层输出的特征图和一个卷积核进行卷积再经过激活函数后形成这一层的特征图。每一幅输出的特征图与不同的卷积核进行卷积后再经过激活函数,又形成下一层的特征图。
1.1.1 特征提取层
为了获得车牌图像的边缘和纹理特征,在输入的低分辨率车牌图像上密集地提取特征小块,并将每个提取到的特征小块表示为一个个高维向量,然后将这些高维向量组成一组特征图,该特征图的数量等于向量的维度。该过程表示为F1(Y):
输入:
Z1=W1*Y+B1
(2)
输出:
A1=f(Z1)
(3)
F1(Y)=A1=max(0,W1*Y+B1)
(4)
其中,W1为该卷积层的滤波器组,且每一个滤波器的大小是f1×f1,数量是n1,所以W1的大小就是n1×f1×f1×c,c表示输入图像的通道数(因为文中只对Y通道进行处理,所以c=1);B1表示该卷积层的偏差(是n1维的);“*”表示卷积运算。每一个滤波器提取一种特征,所以经过卷积层卷积后输出的结果是由n1个特征组成的特征图。
1.1.2 非线性映射层
如图1所示,为了获取高维特征向量,将第一层提取出的低维特征图非线性地映射到另一个高维矢量上,即在该层将第一层提取到的n1维特征向量映射到n2维上。这一过程表示为F2(Y):
输入:
Z2=W2*F1(Y)+B2
(5)
输出:
A2=f(Z2)
(6)
F2(Y)=A2=max(0,W2*F1(Y)+B2)
(7)
其中,W2表示该层的滤波器组,每一个滤波器大小为n1×f2×f2,数量为n2,所以W2的大小为n2×n1×f2×f2;B2表示n2维的偏差。非线性映射层输出n2维的特征图,且这些特征图都是高分辨率图像小块,这些生成的高分辨率图像特征小块将用于第三层的重建。
1.1.3 重建层
将第二层获得的特征图即高分辨率图像特征小块进行平均融合得到最终的高分辨率重建图像。该过程表示为F(Y):
F(Y)=W3*F2(Y)+B3
(8)
其中,W3表示为c个大小为n2×f3×f3的滤波器组,网络的输出层没有采用激活函数,并且W3可以看作是一个均值滤波器,整个重建过程是一个线性操作过程;B3表示一个c维的偏差。
1.2 损失函数
期望获得的重建车牌图像F(Y)和原始高分辨率车牌图像X越接近越好,即它们之间的差值(损失函数)越小越好。由以上分析可知,学习到的端到端的映射函数F需要学习各层中的网络参数W和B,将各层网络参数组成一组参数向量Θ={W1,W2,W3,B1,B2,B3},整个网络的训练就是对这组参数向量的估计和优化,通过最小化F(Yi;Θ)和Xi之间的差值得到参数最优解。
文中通过均方误差(MSE)来计算网络的损失函数:
(9)
其中,n为训练样本数量;Yi为输入的低分辨率图像块;Xi为对应的原始高分辨率图像块。
1.3 反向传播算法
为了使损失函数最小化,文中采用反向传播算法进行训练,主要利用随机梯度下降法去最优化每一层的网络参数。权重Wi和偏差Bi的更新公式如下:
(10)

(11)
其中,Wi表示第i层的权重;Bi表示第i层的偏差;α表示学习率。
然后通过计算参数的偏导数来更新权重参数,计算公式如下:
ΔW(l)=ΔW(l)+W(l)L(Θ)
(12)
ΔB(l)=ΔB(l)+B(l)L(Θ)
(13)
得到更新后的权重参数之后,重复梯度下降法使目标损失函数达到最小,直至收敛,使得最终重建出来的图像更接近于原始的高分辨率图像。
2 实验与分析
2.1 图像质量评价指标
在超分辨率算法评价标准中,有主观评价和客观评价两类标准。其中主观标准主要是通过人眼判定,查看重建的图像是否有充分的细节信息、边缘是否模糊,或者重建的图像是否有严重的其他缺陷、图像的整体效果是否符合审美标准等。客观评价是计算重建后图像和原始图像之间的相似程度。将提出的深度卷积神经网络算法应用到车牌图像超分辨率重建中,旨在提高车牌图像的视觉效果,为了比较算法的公平性,将其与传统的双三次插值Bicubic算法以及基于字典学习的K-SVD算法[18-19]进行比较。采用峰值信噪比(PSNR)作为车牌图像重建的质量评价指标。PSNR表示信号的最大功率和噪声功率的比值,单位为dB,是目前广泛用于评价图像质量的评价指标之一,公式如下:
PSNR=10×log(2552/MSE)
(14)
其中,MSE是重建后图像和原始图像之间的均方误差。峰值信噪比PSNR值越大,重建效果越好。
2.2 实验设置
为了初始化不同的参数,选用均值为0、标准差为103的高斯分布来初始化每一层的滤波器权重。然后使用随机梯度下降法求得目标损失函数的最优解。经过经验性的参数调整,最终设置参数如下:f1=9,f2=5,f3=5,n1=64,n2=32,并设置放大因子为3倍,获得的图像视觉效果最佳。对于输入的彩色RGB图像,文中首先将图像从RGB颜色空间转换到YCbCr颜色空间,并且只对亮度通道Y进行超分辨率重建,剩下的两个Cb、Cr通道均采用双三次插值法Bicubic缩放到目标尺寸大小。
2.3 实验结果与分析
为了验证LPSRCNN算法的有效性,选取了部分车牌图像进行实验。在放大因子为3的情况下,将文中算法分别与传统的双三次插值Bicubic算法和基于字典学习的K-SVD算法进行重建效果对比,如图3所示。其中,图像1~3中从左至右分别是原始高分辨率图像以及算法Bicubic、K-SVD、LPSRCNN重建后得到的图像。

图3 放大因子为3的重建效果对比
从人眼视觉的美观角度分析,文中算法相比于上述两种方法能够获得更加清晰的重建效果。与Bicubic算法相比,文中算法得到的图像边缘更加清晰、平滑,整体图像视觉感较好,符合人眼的美学要求。而与K-SVD算法相比,文中算法能够有效抑制K-SVD算法产生的振铃现象。值得一提的是,虽然车牌图像经过文中算法得到的整体重建效果较好,但重建后的车牌图像中的中文文字部分不清晰,细节信息难以恢复,与原始真实的高清车牌图像中的文字存在一定的差距。
从客观角度分析,表1是不同算法对所选车牌图像重建后的PSNR值比较,PSNR值越大,表示重建的效果越好。由表1可知,文中算法得到的PSNR值高于其他两种算法,说明文中算法重建质量有效。双三次插值法和K-SVD算法虽然提高了车牌图像的质量,但重建后的图像仍然存在边缘模糊的缺点。与传统的双三次插值法和基于字典学习的K-SVD算法相比,LPSRCNN模型重建后的车牌图像边缘、纹理更清晰,并且得到的PSNR值均高于双三次插值和K-SVD算法得到的PSNR值,整体效果更接近原始的高分辨率图像。表明了卷积神经网络能够有效地直接学习高分辨率车牌图像和低分辨率车牌图像之间端到端的映射关系,重建后的车牌图像视觉效果更加明显。
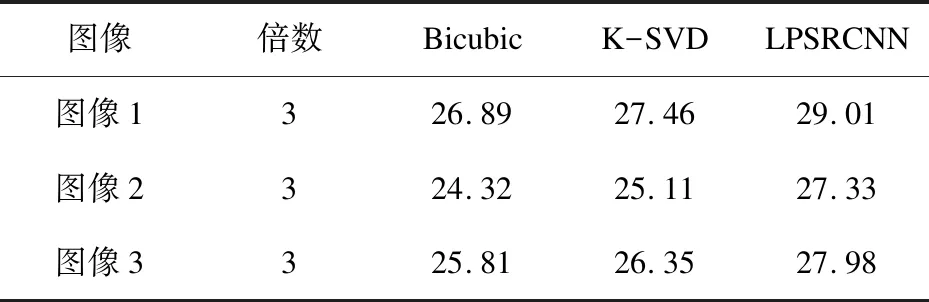
表1 不同算法对车牌图像重建后的PSNR值 dB
3 结束语
针对整体车牌图像超分辨率重建这一问题,将卷积神经网络的方法应用到整体车牌图像超分辨率重建中,直接学习高分辨率车牌图像和低分辨率车牌图像之间端到端的映射关系。实验结果表明,LPSRCNN算法处理后的图像边缘、纹理等细节信息更加丰富,视觉效果得到了提升,有效提高了整体车牌图像的质量,达到了预期实验效果。但该算法中输入的不是原始的低分辨率车牌图像,而是将原始的高分辨率车牌图像进行Bicubic插值得到的低分辨率车牌图像,这增加了算法的计算复杂度,并且得到的图像有人工操作的痕迹。因此,下一步将重点研究当输入图像是原始的低分辨率车牌图像时,能否改进算法的优越性,以及网络深度、滤波器大小、滤波器数量等因素对车牌图像重建效果的影响。
猜你喜欢
动漫界·幼教365(中班)(2021年4期)2021-05-23
天津医科大学学报(2021年2期)2021-03-29
健康体检与管理(2021年10期)2021-01-03
计算机应用(2020年7期)2020-08-06
艺术科技(2018年2期)2018-07-23
小猕猴智力画刊(2017年5期)2017-05-25
计算机应用(2016年10期)2017-05-12
科技创新导报(2016年32期)2017-04-22
发明与创新·中学生(2017年1期)2017-01-20
太空探索(2016年3期)2016-07-12
