
基于改进SSD的果园行人实时检测方法
2019-04-29 02:20张礼帅
农业机械学报 2019年4期
刘 慧 张礼帅 沈 跃 张 健 吴 边
(江苏大学电气信息工程学院, 镇江 212013)
0 引言
随着精准农业理论的提出以及智能化机器人的发展,智能农业车辆的自动导航越来越受到国内外的关注[1]。为了保证智能化车辆在无人工干预时在田间操作的安全性,必须有实时的障碍物检测,当需要人机共同协作完成一些任务时,对田间行人的检测更是首要考虑的问题。在室外田间环境下,自动导航时存在很大的不确定性,常用的障碍物检测方法有激光雷达传感器检测[2]、超声波传感器检测[3]、红外传感器检测[4]和计算机视觉检测[5]等。
田间环境下的障碍物检测,由于其复杂的自然环境、障碍物形态的多变性、光照等外部条件的大范围变化等,实施起来具有一定难度。田间环境下,超声波传感器存在检测障碍物空间位置准确性较差、易受干扰等缺点,激光雷达传感器可以较直观地检测障碍物,但雷达系统的造价昂贵[6]。计算机视觉检测相比于其他障碍物检测方法具有成本低、能够有效利用环境中的颜色与纹理信息等优点。
近年来由于深度学习相关理论的快速发展及计算能力的提升,深度卷积网络在计算机视觉方面取得了很大的成功。在目标检测方面,基于深度学习的方法准确率大大超过了传统的基于HOG、SIFT等人工设计特征的检测方法[7]。基于深度学习的目标检测主要包括两类,一类是基于区域生成的卷积网络结构,代表性的网络为R-CNN[8]、fast R-CNN[9]、faster R-CNN[10];另一类是把目标位置的检测视作回归问题,直接利用CNN网络结构对整个图像进行处理,同时预测出目标的类别和位置,代表性的网络有YOLO[11-13]、SSD[14-15]等。行人检测是目标检测的子问题,基于卷积网络的目标检测模型由于不需要手动设计特征,可通过深层卷积网络结构自动学习图像的高阶特征,从而可生成更加可靠的检测结果[16]。针对深度学习模型参数众多导致其难以部署在嵌入式设备的问题,很多学者提出了各种相应的模型压缩方法[17-19]。
本文在LIU等[14]提出的SSD目标检测模型基础上对其进行改进,使用MobileNetV2[19]网络架构作为SSD的基础网络进行特征提取,并对辅助层的卷积结构使用反向残差结构并结合空洞卷积进行位置预测,在利用多尺度信息的同时可以减少计算量和参数量,使其能够部署在移动端设备中,通过迁移学习对训练好的网络模型进行调优,从而减少模型训练时间并使得模型更容易收敛。本文采用计算机视觉方法结合深度学习进行农业车辆自动作业过程中的行人障碍物检测,从而为进一步实现田间行人避让提供理论基础。
1 田间行人识别模型
1.1 SSD网络结构
SSD目标检测模型由于不需要耗时的区域生成及特征重采样步骤,直接对整个图像进行卷积操作并预测出图像中所包含物体的类别及对应的坐标,从而极大提高了检测速度,同时通过使用小尺寸的卷积核、多尺度预测等使得目标检测的精度得到很大提升。
SSD网络结构分为基础网络(Base network)和辅助网络(Auxiliary network)两部分:基础网络为在图像分类领域具有很高分类精度且去除其分类层的网络;辅助网络为在基础网络基础上增加的用于目标检测的卷积网络结构,这些层的尺寸逐渐减小从而可以进行多尺度预测。每个添加的辅助网络层都会通过一系列卷积核产生一个固定的预测集,对于一个m×n×p(p为通道数,m、n为尺寸)的特征层,每个辅助层会使用3×3×p的卷积核对其进行预测并产生某一类别的得分值,或者是物体相对于默认边界框的位置偏移量,且在m×n个位置都分别预测出相应的值。
SSD模型在特征图的每个位置预测k个边界框,并且同时预测某一物体类别出现在此位置的得分和物体位置相对于边界框的偏移量,从而在每个特征图的位置分别预测c×k(c为类别数)个得分和4×k个位置偏移量,对于一个尺寸为m×n的特征图,总体会预测出(c+4)kmn个输出量。最后对输出结果进行非极大值抑制来得到最终的关于图像中物体类别及位置信息的预测值。
1.2 改进的SSD田间行人检测模型
SSD目标检测模型使用VGG网络[20]作为基础网络,但VGG网络模型参数众多,在特征提取过程中占用了大部分运行时间,且在前向传播过程中由于存在非线性变换导致变换过程中信息的损失。
SANDLER等[19]在流形学习理论的基础上提出非线性激活函数ReLU在高维度下会较好地保留信息,而在低维度下会造成较大的信息丢失,故在输入层应该增加特征维度之后再对其进行非线性变换,而在输出层应该对特征进行降维后使用线性激活函数以减少信息的丢失,据此提出反向残差结构(Inverted residual block)。
反向残差结构中的下采样操作在增大卷积核感受野的同时会造成特征信息的丢失,所以考虑舍弃卷积结构中的下采样操作并引入空洞卷积[21-22]来解决此问题。空洞卷积是在原始卷积操作的基础上增加一个扩张参数,将卷积核扩张到相应的尺度中,同时在原卷积核中未被占用到的区域填充0,应用空洞卷积可以在不用下采样操作的情况下增加卷积核的感受野。但空洞卷积的使用会令卷积核对数据操作不连续以及对于小物体不能较好识别,本文考虑使用层级特征融合[23](Hierarchical feature fusion) 来解决引入空洞卷积所带来的问题。
层级特征融合是对空洞卷积层的每一个卷积单元的输出依次进行求和,并且把每个求和后的结果都通过连接(Concatenate)操作得到最后的输出结果,如图1所示。相比于其他通过使用较小的扩张参数使得学习参数变多的方法,此方法具有操作简单且不增加卷积结构复杂性的优点。空洞卷积层结构表示为(输入通道,感受野,输出通道),其中空洞卷积核的有效感受野为nk×nk,nk=2k-1(n-1)+1;k=1,2,…,K。
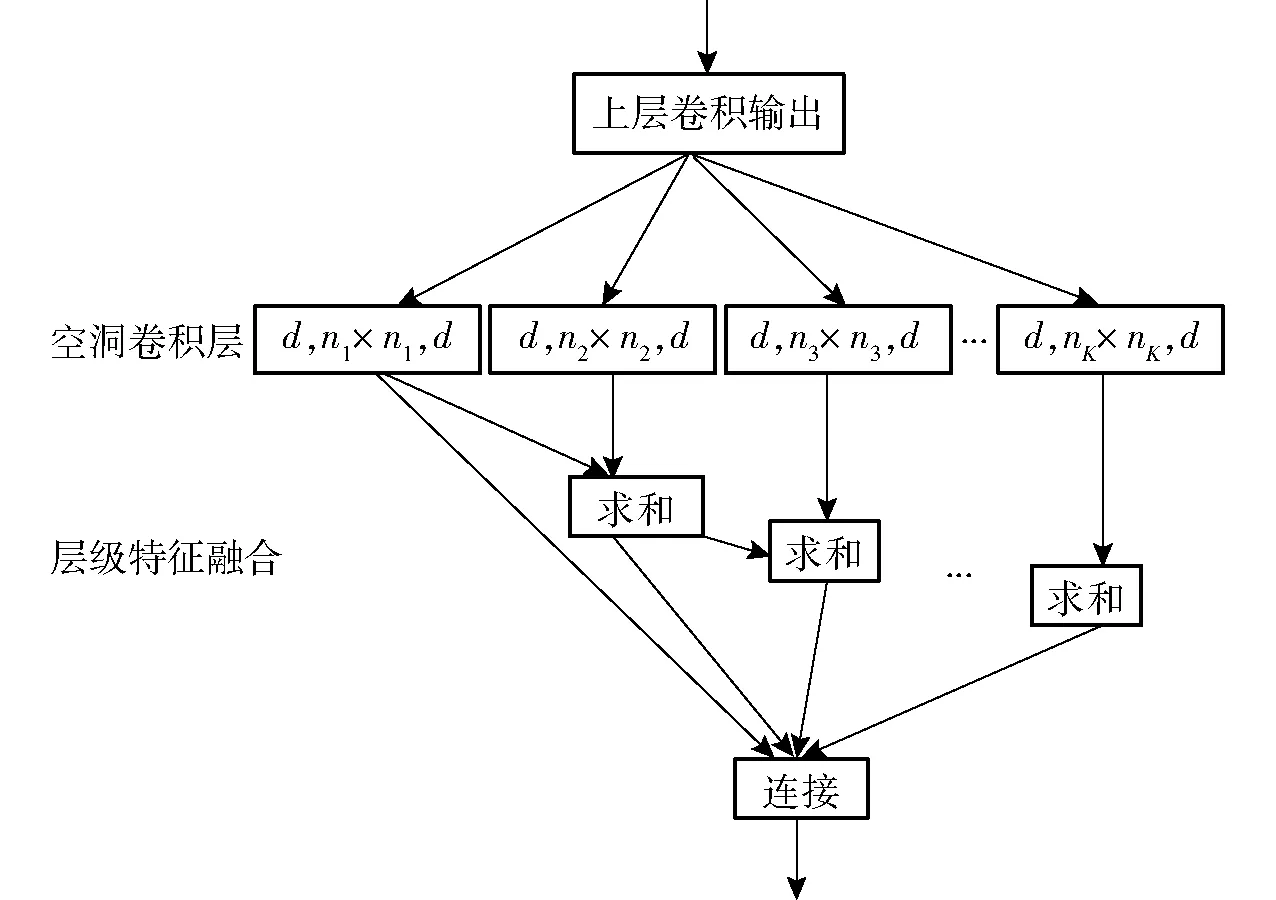
图1 层级特征融合Fig.1 Hierarchical feature fusion
反向残差结构使用ReLU6为激活函数,其输出为
Y=min(max(X,0),6)
(1)
式中Y——ReLU6激活函数的输出
X——输入特征值
ReLU6相比于ReLU[24]在低精度运算场景中具有更好的鲁棒性,另外,使用3×3的卷积核,并且在训练网络过程中使用dropout[25]和batch normalization[26]以减少训练过程中的过拟合。改进前后的反向残差结构如图2所示。其中Dwise表示基于深度可分离的卷积结构[27],Dilated表示卷积方式是空洞卷积,Linear为线性激活函数,HFF表示层级特征融合。
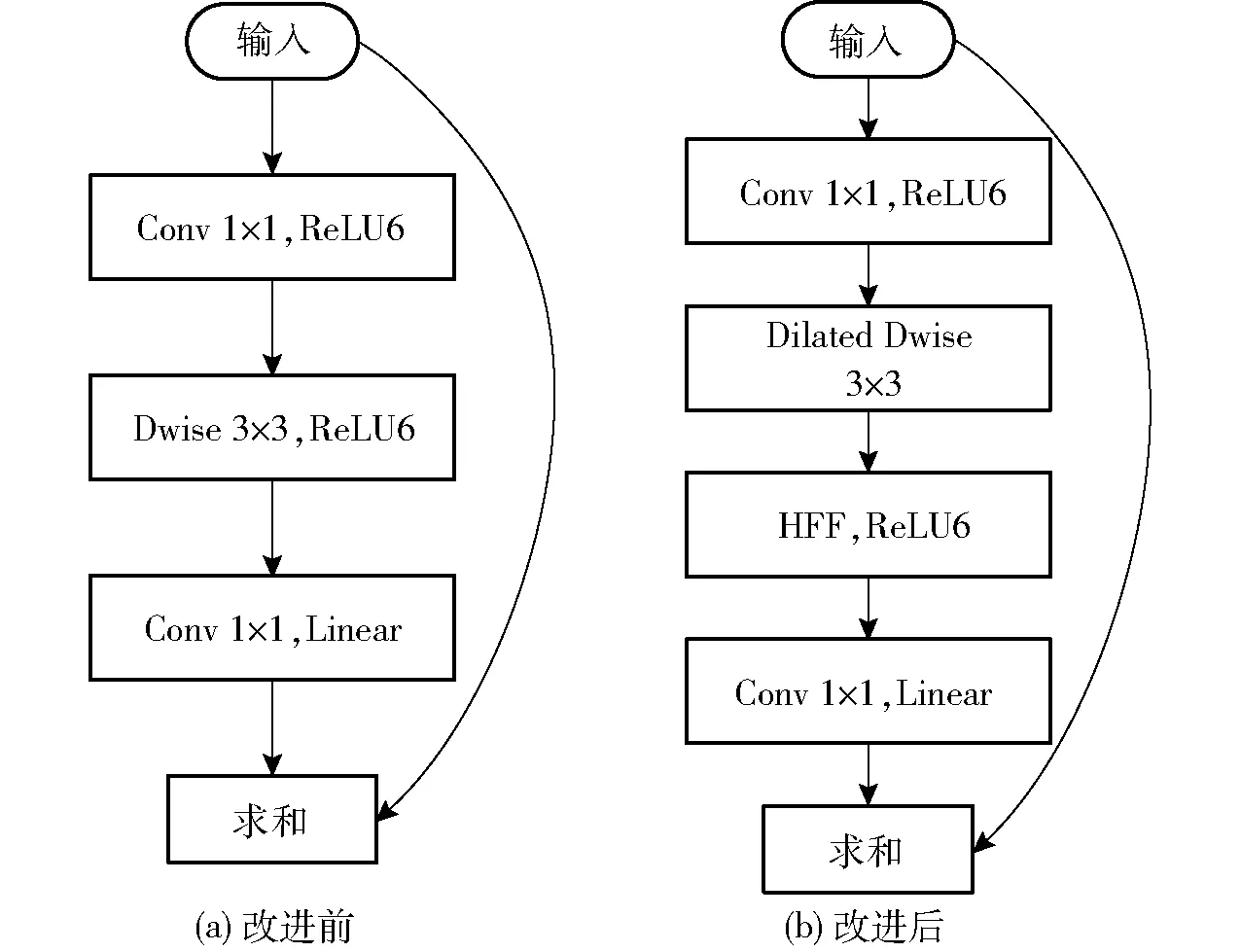
图2 改进前后反向残差结构Fig.2 Inverted residual block before and after improvement
结合改进后的反向残差结构对SSD目标检测模型的基础层和辅助层进行改进:①原始SSD使用VGG网络作为基础层进行特征提取,但VGG网络模型不适合在移动设备上部署运行,把其替换为SANDLER等[19]在反向残差结构基础上提出的MobileNetV2网络,其具有参数少、占用空间小且运行速度较快的优点,以此作为SSD的特征提取网络可以加快运行速度并且减少模型的尺寸及运算量。②SSD辅助层使用传统的卷积网络结构导致其参数量和运算量较大,本文使用改进后的反向残差结构作为辅助层的基本结构,改进后的辅助网络层可以减少学习过程中非线性变换造成的信息损失且卷积核具有多尺度的感受野。改进后的SSD网络结构如图3所示。基础网络为去除预测层后的MobileNetV2网络,辅助网络层使用改进后的反向残差结构进行位置及相应类别概率的预测,其中19×19×1 280为输出的特征尺寸,其余类似。
2 目标函数
训练过程中所使用的目标函数为

图3 改进后的SSD网络结构Fig.3 Improved SSD framework
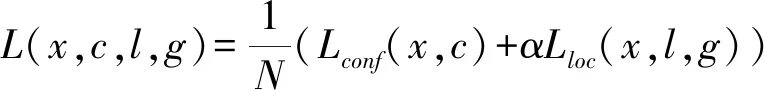
(2)
其中

(3)

(4)
(5)
式中N——匹配的默认边界框的个数, 当N为0时,设置L为0
x——预测框与真实框是否匹配
c——标注类别
α——位置预测误差与分类预测误差的加权系数
SL1——平滑L1误差函数
l——预测的边界框坐标
g——标注的边界框坐标
Lloc——位置预测误差,为平滑L1误差函数
Lconf——对应的softmax多分类误差函数
xij,k——第i个预测框与第j个真实框关于类别k是否匹配
Pos——样本中的正例
Box——预测框中心坐标及其宽和高的集合
Neg——样本中的负例
xij,p——预测框i与真实框j关于类别p是否匹配
ci,p——第i个预测框中目标属于类别p的得分值
3 苹果园行人识别试验
3.1 试验平台
采用32GB内存、NVIDIA GTX1080TI型GPU、AMD锐龙5-2600X CPU作为硬件平台,操作系统为Linux Ubuntu 16.04,并行计算框架版本为CUDA 8.0,深度神经网络加速库为CUDNN v7.0。采用Python编程语言在Tensorflow[28]深度学习框架上实现本文的SSD目标检测模型并完成对模型的训练及验证。
3.2 试验数据
针对已开放的行人检测数据集都是在城市道路等结构化环境中,PEZZEMENTI等[29]制作了农业环境下行人检测数据集以促进深度学习技术在农业环境下的应用,包括苹果园和橙园环境下的已标注图像。本文使用苹果园环境下的数据,分为训练集、验证集和测试集。训练集包含行人图像有15 526幅,不包含行人的图像有4 570幅;验证集中包含行人图像有8 124幅,不包含行人图像有1 981幅;测试集中包含行人图像有7 691幅,不包含行人图像有1 949幅。其中包含行人的图像分为静止状态和移动状态;按照行人目标所占像素区域面积分为小目标、中等目标、大目标;按照行人所处的姿势分为正常姿势、非正常姿势,其中正常姿势是正常站立姿势,非正常姿势包括躺、坐、蹲和跌落姿势。
3.3 数据预处理
由于样本中各种情形下的图像样本并不一致,为了避免样本分布不均导致训练出的模型泛化性能不佳问题,对样本中数量较少的分类进行水平翻转和平移等操作进行数据增广,使得各种情形下的样本数量基本一致。同时由于苹果园自然光照下,特别是在光照很强时,由于行人被植株遮挡或受植株阴影的影响,使得处于此环境下的行人相对于自然光照射下表面会有较大变化,从而会影响行人检测的精度。本文采用自适应直方图均衡化来对图像进行增强从而提高图像的质量,减少光照变化对图像的影响。
3.4 模型训练
为了节省训练时间及加快收敛速度,本文使用迁移学习来训练深度学习模型。首先加载已经训练好的MobileNetV2分类网络的参数,除去最后的分类层,其余参数值赋给SSD模型中对应的参数,其余各层参数是以0为均值、0.01为标准差的高斯分布进行随机初始化。
本文使用批量随机梯度下降算法,设置batch-size为128,冲量为0.9,权值衰减系数为2×10-3,最大迭代次数为8×105次,初始学习率为0.004,衰减率为0.95,每10 000次迭代后衰减一次,每间隔10 000次迭代后保存一次模型,最终选取精度最高的模型。训练过程中使用困难样本挖掘(Hard negative mining)策略[30],即训练过程中先用初始的正负样本训练检测模型,然后使用训练出的模型对样本进行检测分类,把其中检测错误的样本继续放入负样本集合进行训练,从而加强模型判别假阳性的能力。
4 结果与分析
4.1 评价指标
通过在测试集中分析模型改进前后的检测精度、检测速度和参数量以对比模型的性能。把测试集图像输入训练好的网络,对田间行人位置进行检测并记录检测结果,当模型预测的目标边界与测试集对应的标注数据中的边界框的交并集比(IOU)大于等于设定的阈值时,认为检测结果正确,否则视为检测错误。检测精度的评价指标选取准确率(Precision,P)、召回率(Recall,R)和调和均值F1,各个评价指标的定义为
(6)
(7)
(8)
式中TP——正确检测到行人的数量
FP——误把非行人目标检测为行人目标的数量
FN——误把行人检测为背景的数量
F1——对准确率和召回率的调和均值,越接近于1,表明模型表现越好
4.2 改进SSD模型对田间行人的识别结果
在测试集中分别对改进前后的SSD目标检测模型进行测试,并统计其检测结果和检测速度,结果见表1。改进后的网络模型准确率和召回率分别提高了0.82个百分点和1.62个百分点。通过对卷积网络的改进使得网络模型参数量相比于原始模型减少至原来的1/7,且其检测速度提高了187.5%,使得目标检测模型更适合在移动机器人中部署,实时性更好。
4.3 IOU阈值对检测结果的影响
前述结果分析中默认选择IOU阈值为0.5,当检测结果与标注结果的IOU阈值大于等于0.5时,认为检测结果正确,否则视为未检测出行人目标。当IOU阈值在0.6及以下时,行人检测模型的表现

表1 改进前后SSD模型果园行人检测结果比较Tab.1 Comparison of detection results between improved SSD and original SSD
对IOU阈值的变化并不十分敏感,当IOU阈值在0.6以上时,行人检测模型会受到很大影响,其漏检率将快速上升[31]。不同于城市环境下对检测到的行人采取的避障策略有很多种选择,在果园田间环境下,由于受到地形的限制,农机所采取的避障策略可能只有减速或者停止,而不能采取规划路径从而避开行人的决策,故而其对田间行人检测的位置精度要求不高。通过比较IOU阈值在0.3~0.7之间时准确率和召回率,选择出较为合适的IOU阈值。不同IOU阈值下,改进前后模型检测结果如表2所示。根据结果得出改进前后的SSD目标检测模型在果园环境下行人检测的IOU阈值均在0.4最合适,改进后模型的准确率和召回率比阈值在0.5时分别提高了0.33个百分点和1.93个百分点,改进前模型的准确率和召回率比阈值0.5时分别提高了0.56个百分点和0.41个百分点,故而在IOU阈值为0.4下进行改进前后模型检测性能的对比试验。
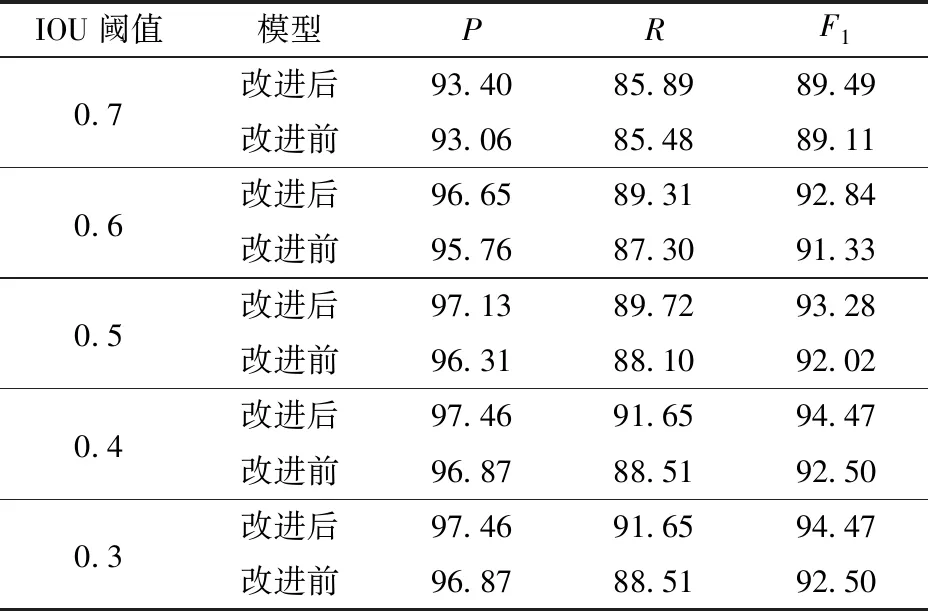
表2 不同IOU阈值下改进前后模型的检测结果Tab.2 Detection statistic results on various IOU thresholds %
4.4 不同运动状态模型识别结果
NREC开放田间行人识别数据集中记录了拍摄图像时田间的行人是处于静止状态还是连续运动状态,故而可以根据标注把行人按照运动状态分为静止、运动状态,测试模型在这两种情形下识别性能的变化。当行人处于静止状态时,改进后的SSD检测结果的F1为93.88%,运动状态时为90.09%,在运动状态下的行人检测性能比静止状态降低了3.79个百分点。根据试验结果可知MobileNetV2网络架构相比于原始SSD模型中的VGG网络在运动目标的特征提取上稍弱,故而改进后的模型在运动目标的检测中性能稍弱,但MobileNetV2网络的计算量要远低于VGG网络,因此,可大大提高模型的运算速度。检测结果见图4a。

图4 改进SSD模型对不同情形下的行人识别结果Fig.4 Detection results of improved SSD model on pedestrian in various conditions
4.5 不同行人姿态下模型识别结果
数据集中包含果园行人处于多种姿态下的图像,把其分为两类:一类是正常姿态,即行人处于正常站立状态;另一类为非正常姿态,包括行人处于躺、坐、蹲和跌落的状态。在正常姿态下改进后SSD模型识别结果的F1为92.66%,非正常姿态下F1为89.88%。行人不同姿态对模型检测结果有较大影响,检测结果见图4b。
4.6 不同目标面积下模型识别结果
按照田间行人目标占区域像素面积的比例分为大目标、中目标、小目标,其中像素面积在3 501像素以上的为大目标,面积在1 301~3 500像素之间的为中目标,面积在1 300像素以下的为小目标。改进后SSD模型在目标为大、中、小情况下的F1分别为95.07%、92.64%、84.09%。由于行人所占区域像素面积一定程度上反映了行人与摄像机的距离,故而可以分析出当行人处于近、中距离时检测性能较高,而在小目标情况下即行人距离较远时检测性能较改进前稍弱,这是由于层级特征融合并不能完全消除空洞卷积带来的影响,从而影响了小目标的检测性能。由此可见,空洞卷积的引入提高了模型检测近、中距离目标的性能,检测远处目标的性能稍微下降,符合障碍物检测任务中不同障碍物检测的优先顺序,即近、中距离处的障碍物是优先需要处理的目标。检测结果见图4c。
表3为不同情形下改进前SSD模型与改进后SSD模型的准确率、召回率和F1的统计结果,其中IOU阈值取为0.4。改进后的SSD模型在除行人处于运动状态下检测准确率和召回率有下降外,其余情形均有所提高。

表3 不同行人状态下的检测结果Tab.3 Detection statistic result on pedestrian in various status %
5 结论
(1)基于卡耐基梅隆大学国家机器人工程中心开放的用于农业环境下行人检测的数据集,采用改进的SSD目标检测模型,进行田间环境下的行人障碍物检测,模型占用空间较小且轻量化,适合于在移动设备上部署,试验结果表明,模型具有较高的准确性,准确率和召回率分别达到了97.13%和89.72%,每幅图像的平均检测速度为62.50帧/s。在对IOU阈值进行合理调整后最终平均准确率和召回率分别达到了97.46%和91.65%。
(2)通过迁移学习技术,把MobileNetV2在Imagenet分类表现较好的参数移植到SSD的特征提取网络模型中,从而简化了目标检测模型的训练过程并缩短了训练时间。
(3)通过改进原始SSD的特征提取网络,使用更加轻量化的MobileNetV2网络模型进行特征提取,辅助层使用改进后的反向残差结构进行卷积运算,从而可以利用多特征信息并且减少运算量,当IOU阈值为0.4时,较原始SSD网络模型的准确率和召回率分别提高了0.59个百分点和3.14个百分点,参数量减少至原来的1/7,检测速度提高了187.5%。
(4)根据果园环境下和城市环境下对避开行人所采取的决策不同,提出在果园环境下合适的IOU阈值为0.4左右,在此阈值下,模型的准确率和召回率比阈值在0.5时分别提高了0.33个百分点和1.93个百分点。
猜你喜欢
今日农业(2022年14期)2022-09-15
建材发展导向(2021年19期)2021-12-06
今日农业(2021年8期)2021-11-28
意林(2021年5期)2021-04-18
今日农业(2021年2期)2021-03-19
临床骨科杂志(2020年1期)2020-12-12
金桥(2020年9期)2020-10-27
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
汽车与安全(2016年5期)2016-12-01
