
对2018年前三季度我国各地区社会服务水平评价
2019-04-29 06:23
福建质量管理 2019年9期
(东北大学秦皇岛分校 河北 秦皇岛 066000)
一、绪论
(一)研究背景
近年来,随着我国经济的持续增长,国家对改善民生越来越重视,因此我国的社会服务水平得到很大的提高。然而随着社会服务需求的日益增长,我国的社会服务已经不能适应人们日益增长社会服务需求。我国社会服务发展的“短板”愈来愈明显。因此,建立有效的社会服务指标体系,对我国各地区社会服务情况进行分析,找出社会服务建设较弱的地区进行有针对性地完善提高已经成为迫切需要。
(二)数据来源和指标确定
本文数据源自于中国民政部官网的2018年度各地区社会服务情况统计表。根据我国国家基本公共服务体系中涉及的社会服务内容确定指标体系,通过查询数据剔除一些数据缺省的指标,根据国务院2017年公布的《“十三五”推进基本公共服务均等化规划》[1]对基本社会服务的定义,选取了具有代表性的9项指标:民政事业费累计支出(万元)、社会服务机构数(个)、孤儿数(人)、城市低保人数(人)、农村低保人数(人)、临时救助人次数(人)、结婚登记(对)、离婚登记(对)、火化遗体数(个)。
二、聚类分析
(一)聚类分析模型
类平均法是一种使用比较广泛、聚类效果比较好的系统聚类方法。本文使用SAS软件调用CLUSTER过程来对各地区进行聚类分析。
通过反映社会服务水平的各项指标对不同地区进行聚类,使用类平均法聚类得到树状图及聚类历史图如图2.1所示。

图2.1 类平均聚类法的谱系聚类图
树状图2.1展现了聚类分析中每一次合并的情况,横轴代表个案样本间的距离,纵轴代表的31个样本,即31个省市。
从聚类历史中我们可以确定31个样本分为几类比较合适。首先指定类数NCL6,然后综合R2统计量、半偏R2统计量、伪F统计量、伪t2统计量分析,最终确定分为两类或四类比较合适。
分为两类的结果:

分为四类的结果:


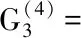

(二)聚类结果分析
不同的聚类方法得到的结果或多或少都有些差别,在实际应用中应综合各种计算结果,所以我们可以计算出各类地区社会服务平均水平(见表2。1)。由表2。1可见第一类地区民政事业费支出、社会服务机构数等社会服务水平正向指标均较高,说明这些地区服务水平较高,第二类的地区社会服务水平其次,但是孤儿数和低保人数较多,说明虽然社会服务支出高但是社会弱势群体数也较多,第三类社会服务水平居中,第四类地区社会服务水平在全国看来还较低,要提升这些省市的社会服务,要从多方面入手。
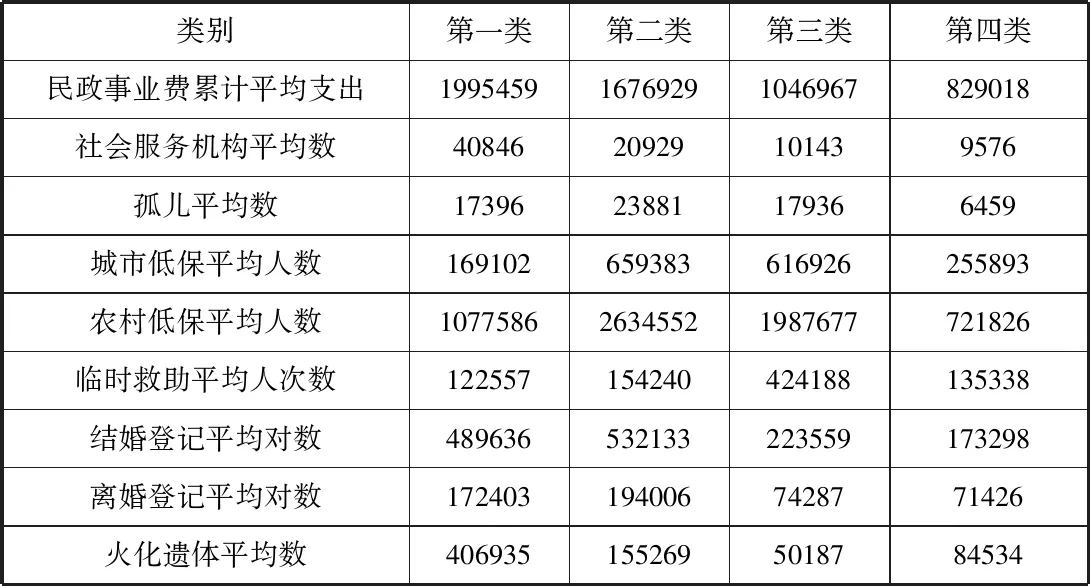
表2.1 各地区的分类及社会服务平均水平
三、主成分分析
设法将原来变量重新组合成一组新的互相无关的几个综合变量,同时根据实际需要从中可以取出几个较少的综合变量尽可能多地反映原来变量的信息的统计方法叫做主成分分析或称主分量分析,也是数学上用来降维的一种方法[3],
把31个地区作为样本,将民政事业费累计支出(Xl),社会服务机构数(X2), 孤儿数(X3),城市低保人数(X4),农村低保人数(X5),临时救助人次数(X6),结婚登记数(X7),离婚登记数(X8),火化遗体数(X9)作为变量。为消除量纲影响,在SAS代码中对数据进行标准化。
本问题中,p=9,n=31,调用SAS软件PRINCOMP过程从相关阵出发进行主成分分析,把九项指标综合成几个互不相关的综合变量。
(一)主成分分析结果
SAS输出的相关阵和特征向量如图3.1、图3.2所示。

图3.1 相关阵特征值
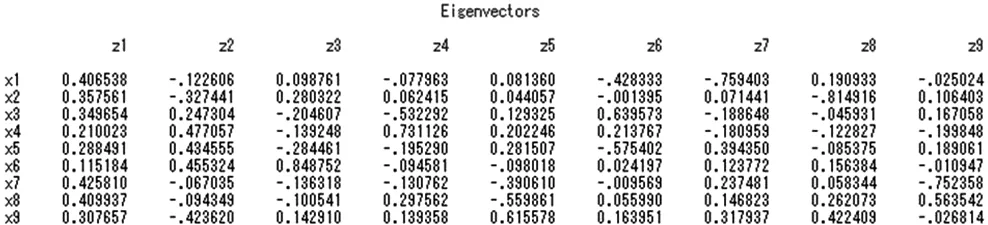
图3.2 相关阵特征值对应的特征向量
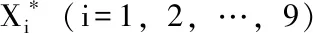
由最大的两个特征值对应的特征向量可以写出第一和第二主成分:
利用特征向量各分量的值可以对各个主成分进行解释。
第一大特征值对应的第一个特征向量的各分量都是正值,且相差不大,说明这九项指标对第一主成分的贡献相差不大,即第一主成分代表各项指标的综合情况,所以本文把第一主成分定义为社会服务的综合水平。
第二个主成分中X4、X5、X6系数都是正值,而且值很大,它们分别对应城市低保人数、农村低保人数及临时救助人次数,而X1、X2、X9系数均为负,而且绝对值较大,分别对应民政事业费累计支出、社会服务机构数及火化遗体数,综合起来说明第二主成分是在这样的情况下:生活保障人数较多,民政事业费累计支出和社会服务机构个数较少,所以本文把第二主成分定义为地区政府的补助和救助。

图3.3 第二主成分对第一主成分的散布图
(二)第二主成分对第一主成分散布图
输出第二主成分对第一主成分的散布图如图3.3所示。
从图中可以直观地看出:按社会服务综合水平,这31个地区应该分为两组(以第一主成分得分值2。5为分界点)。按地区政府的补助和救助可将这些地区分为3组(以第二主成分得分值-2和1为分界点)。另外,由图还可以得知:横坐标第一主成分代表着社会服务综合水平,其值越靠右代表社会服务综合水平越高;纵坐标第二主成分反映的是地区政府的社会补助和救助,其值越靠上代表着地区政府社会补助和救助越到位。纵观全图,发现四川的社会服务综合水平最高,新疆的政府补助和救助做的最好,但是其社会服务综合水平偏低。
(三)按主成分得分排序
对各地区社会服务水平分别根据第一主成分得分和第二主成分得分排序综合成一个表如表3.1所示。
由表可知,按第一主成分得分和第二主成分得分排序结果差异明显。我国社会服务做得最好的地区是四川省,河南省、湖南省、云南省社会服务也很到位;江苏省、广东省、山东省、浙江省社会服务的综合水平较高,但是政府救助和补助投入过少;北京、上海、天津、福建省、西藏自治区、青海省、宁夏省的社会服务综合水平较低,政府救助和补助也较少;河北省、湖北省、安徽省、江西省、陕西省、新疆维吾尔族自治区的综合水平和政府救助投入都还不错;内蒙古自治区、吉林省、重庆市、广西壮族自治区的社会服务综合水平和政府救助和补助投入都处于居中状态;江苏的政府救助 和补助状况最弱,西藏的社会服务综合水平最差。

表3.1 各地区按第一、第二主成分得分排序
四、时间序列预测模型
为了预测未来四个季度内的全国民政事业费累计支出,本文从民政部官网上搜集并整理了到了从2014年第三季度至2018年第三季度关于全国民政事业费的累计支出[4]见表4.1所示,利用SAS时间序列预测模型去预测未来四季度数据。

表4.1 全国民政事业费累计支出序列表
(一)数据预处理
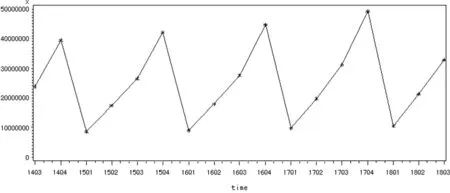
图4.1 时序图
使用SAS绘制时序图和自相关图如图4.1所示。观察时序图发现从2014年三季度至2018年三季度的数据周期性特别强,而且整体具有长期递增的趋势,得出该序列明显是非平稳序列。
综上所述,我们可以采用非平稳序列的确定性分析方法[5]去预测,这种方法认为任何一种时间序列都可以用长期趋势、循环波动、季节性变化、随机波动这四个因素的某个函数进行拟合。由时序图可知民政事业费累计支出序列既有长期趋势,又有周期效应,即可确定本次预测应该选用Holt-Winters三参数指数平滑模型。
(二)Holt-Winters三参指数平滑预测模型
使用SAS软件利用 Holt-Winters三参指数平滑预测加法模型[5]对民政事业费累计支出序列进行拟合预测,得到拟合值与预测值,绘制拟合和预测效果图如图4.2所示。红线为拟合预测值,黑线为已知序列值,绿线为预测值95%的置信区间。但由于观察值较少,所以拟合效果并不是很精确。在观察值个数较多时该方法更具优势。
对未来四季度的民政事业费累计支出预测值如表4.2所示。结果显示,全国民政事业费累计支出在未来四个季度的值会比之前每一年对应季度的值都要高,这说明在未来我国财政在民政事业上的支出会越来越多。

表4.2 未来四季度预测值
五、结论
本文从聚类分析和主成分分析两个角度对各地区的社会服务水平做了较全面的分析,并对未来民政事业费的支出进行了预测。最终得出这样的结论:我国大部分地区社会服务水平处于中等,四川省、河南省、湖南省社会服务做得相对最好,北京、上海、西藏、海南、天津等地区社会服务水平较低,需要从多方面需要改善。而且以后国家财政在民政事业上的支出会越来越多。
总之我国大部分省市在社会服务水平上都存在或多或少需要提高的地方,要基于各地区的实际情况从多方面入手来提高社会服务水平。
猜你喜欢
北京教育·高教版(2023年2期)2023-03-07
中国民政(2022年5期)2023-01-08
中国民政(2022年3期)2022-08-31
四川劳动保障(2021年8期)2021-12-02
石油化工管理干部学院学报(2021年5期)2021-08-06
活力(2019年19期)2020-01-06
中国民政(2019年12期)2020-01-02
昆明医科大学报(2019年6期)2019-09-10
中国粮食经济(2018年11期)2018-12-27
中国卫生(2014年10期)2014-11-12
