
基于DNA变形能的核小体定位预测方法研究进展
2019-07-05 09:43刘国庆
生物信息学 2019年2期
刘国庆
(内蒙古科技大学 生命科学与技术学院,内蒙古 包头 014010)
核小体是真核生物染色质的基本结构单元,是DNA双螺旋缠绕在组蛋白八聚体上形成的复合物。标准的组蛋白八聚体由进化上高度保守的H2A、H2B、H3和H4各两个拷贝组成[1]。并非所有的核小体都由标准的组蛋白组装,全基因组范围内还富含一些组蛋白变体,如H2A.Z,H3.3等。组蛋白变体与标准组蛋白间存在一定的序列差异,对染色质结构和基因转录有不同的调控作用[2-4]。标准组蛋白和非标准组蛋白均由基因组上的若干个基因表达[3-4]。核小体核心DNA的长度约为147 bp[5-9],而相邻的核小体之间的链接DNA的长度并不恒定(约20-80 bp)。核小体核心颗粒在组蛋白H1的作用下形成30-nm结构,进一步组装成更高级结构[10],使基因组DNA包装到狭小的细胞核中。核小体占据真核基因组的绝大部分(约75%~90%)[11-12]。
核小体区域的DNA缠绕于组蛋白上,相比链接DNA不易于相关蛋白因子与之相接触并结合,从而导致核小体参与基因转录、DNA复制、修复、重组以及RNA剪接等众多生物学过程[11-15]。核小体在DNA序列以外的因素(如重塑蛋白、组蛋白修饰酶、细胞微环境变化等)或内在信号(DNA序列突变)的扰动下其位置时有发生变化并参与上述生物学过程[11-22]。体外的核小体定位只决定于DNA序列和相邻核小体之间的空间位阻效应[12]。而在体内,核小体则与一些DNA结合蛋白竞争结合基因组DNA,可能会导致DNA序列信号在核小体定位中的作用受到不同程度的影响;而且染色质重塑酶的作用也不可小觑,有时发挥单纯的催化功能影响核小体的组装效率,而有时ATP依赖的染色质重塑酶能使核小体发生位移[21-22]。尽管DNA序列的内在性质和序列以外的因素(如染色质重塑酶、蛋白因子与DNA序列的竞争结合等)在核小体定位中的重要性存在一定的争议[23-24],但体内和体外核小体定位图谱的高度相似性足以说明DNA序列是影响核小体定位的重要因素[12]。
过去几十年间发展了不少核小体定位的理论预测模型,这些模型与核小体实验图谱相结合促进了核小体定位机制与功能的研究[11-12,18,25-27]。理论预测模型中最常见的是基于DNA序列的预测模型,而这类预测模型又可大致分为基于DNA序列的生物信息学模型[12,18,28-36]和基于DNA变形能的生物物理学模型[37-45]。生物信息学模型中利用机器学习算法构建的模型不占少数。机器学习模型的建立与预测效果依赖于训练集数据,而生物物理学模型的建立主要借助于DNA物理特性和核小体晶体结构数据,并不需要训练集。生物物理学方法能够计算出DNA双螺旋缠绕组蛋白八聚体的变形能,从而预测DNA序列形成核小体的能力、全基因组水平上的核小体占据率和核小体形成自由能[37-45],也能够预测出核小体在DNA序列上的较为准确的位置(或中心位置)[40]。核小体的准确位置涉及核小体的两种定位方式,即平移定位和旋转定位[46],前者描述DNA序列与核小体核心区相对线性位置,而后者描述DNA双螺旋与组蛋白八聚体相对方向。一般来讲,旋转定位信号强的DNA区域具有较高的弯曲各向异性,即容易朝某一个特定方向弯曲缠绕组蛋白八聚体形成核小体。显然,旋转定位信号强的区域也是平移定位较稳定的区域。两种定位方式紧密关联,因此核小体在单碱基水平上的精确位置可借助旋转定位信息来预测。本文介绍预测核小体定位的生物物理学方法及其应用,旨在帮助人们更好地理解核小体定位,并建议选择性地使用这些模型。
1 基于DNA变形能的核小体定位预测方法
结合核小体的晶体衍射结构数据,可以计算任意一条147 bp DNA片段在形成核小体的假定下的DNA变形能,并以此判断该DNA片段形成核小体的能力:变形能越小,DNA越容易弯曲,形成核小体的可能性越大。
为了计算变形能(或弹性能),首先得科学描述DNA的几何结构。描述DNA构象的方法主要包括(见表1):自由连接链模型[47-48]、蠕虫链模型[48-52]、圆形截面弹性杆模型[53-56]和碱基对梯阶模型[57-58]。自由连接链模型视高分子为由自由铰链(即连接处的弯曲方向与角度不受任何约束)连接多个独立的刚性片段而形成的分子。双链DNA分子中存在碱基对的氢键作用和碱基堆积作用,因此自由连接链模型不太适用于双链DNA。该模型本身也有一些缺陷,导致其应用受限[48]。蠕虫链模型被认为是更加接近真实高分子的粗粒化高分子链模型,其应用较广,但对于短于持久长度的DNA分子适用与否存在争议[51,58]。国际上公认的另一种描述DNA结构的方法是碱基对阶梯模型(即剑桥协议方法[57]),即每一个碱基对上建立直角坐标系,并以相邻的坐标系之间的三个线位移和三个角位移描述DNA双螺旋结构(见图1)。研究DNA结构的传统弹性杆模型(如虫链模型)中,将DNA看作是沿着序列连续弯曲的柔性杆,以DNA螺旋的骨架位形大致表示DNA的结构。而剑桥协议方法则极大地丰富了DNA结构的几何学,促进了DNA柔性估计[58]、DNA结构预测[59]、核小体定位[31,37,39-45]、启动子识别[60-62]、剪接位点识别[63]、重组热点识别[64-65]等多个与DNA结构相关的生物学问题的研究(见表1)。
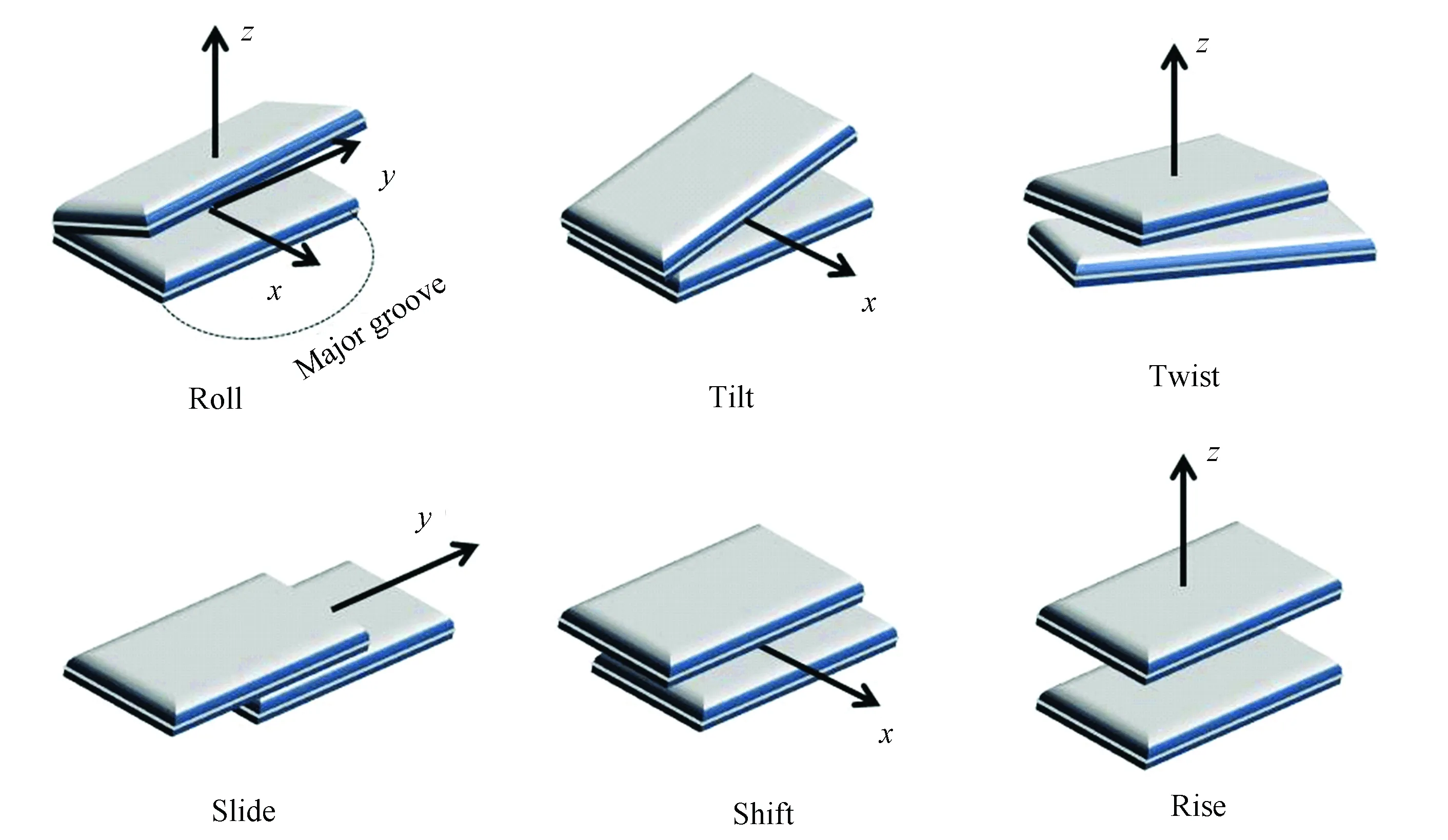
图1 DNA双螺旋结构的碱基对梯阶模型Fig.1 Base-pair step model for the DNA double helix structure
注:两个平板表示两个相邻的碱基对,其中一个板相对于另一板绕三个轴旋转的角位移(Tilt, Roll, Twist)和沿着三个轴方向平移的线位移(Shift, Slide, Rise)是模型中的六个结构参数.

表1 常用的DNA构象描述方法与应用
计算DNA变形能需预先知道描述二核苷酸弯曲能力的力常数。不同的二核苷酸有不同的力常数,同一个二核苷酸的不同的结构变化(如Slide, Shift, Rise, Roll, Tilt, Twist的变化)对应不同的力常数。力常数的计算主要有三种方法:基于DNA解链温度的测定[37-38]、基于DNA结构数据的计算[40,43,66-67]和分子动力学模拟方法[45,68],下面重点介绍其中最常用的一种,即基于DNA结构数据的力常数计算[67]。
令θn代表剑桥协议下参数符号,n=1,2,3,4,5,6分别对应Ω、ρ、τ、DX、Dy和DZ。利用晶体结构数据库(如DNA-蛋白复合物的晶体结构数据)[69]计算每一种二核苷酸的结构参数相对于所有二核苷酸的结构参数平均值的涨落:
Δθn=θn-θ0
力常数的逆与结构参数涨落的协方差之间的关系为[52]:
[F-1]nm=<ΔθnΔθm>/kT
(1)
其中k为玻尔兹曼常数,T为室温(单位为开尔文),<ΔθnΔθm>=<θnθm>-<θn><θm>。
根据式(1)计算力常数矩阵。力常数矩阵中对角元表示各种结构参数对应的力常数,而非对角元反映同一种二核苷酸的不同结构参数间的耦合关联,是属于二阶微量。
弹性杆模型中,任一147 bp长度的DNA序列的弹性能可近似用平衡态附近的二次势能函数表示为[52]:
(2)
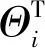
Tolstorokov等利用该模型预测了体外组装的4个核小体在DNA序列上的位置,发现能量最低值(能量越低,越容易形成核小体)与核小体位置非常吻合[42]。他们的研究又表明roll和slide是决定核小体DNA超螺旋结构的最主要参数。
Morozov等提出的预测核小体定位的弹性能模型中[43],核小体DNA可从最初的超螺旋结构进一步调整(微调)。故核小体DNA的自由能由两部分组成,
E=Eel+wEsh
(3)
其中Eel表示序列特异的DNA弹性能,Esh表示组蛋白与DNA的相互作用能,即由组蛋白与DNA的相互作用导致的核小体DNA相对于理想超螺旋结构的偏离所对应的能量。在此基础上定义核小体起始概率和占据率[43],成功预测了6个体外核小体的中心位置(能量的最小值较好地吻合核小体的中心位置)。
Miele等的基于能量的核小体定位预测模型[41]是依据与核小体晶体衍射结构(1kx5)最吻合的理想超螺旋结构建立的。假定DNA序列是不可伸长且不发生切变的弹性棒,而核小体形成时DNA的变形只由twist, roll和tilt造成,变形能表示为:
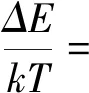
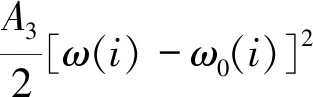
(4)
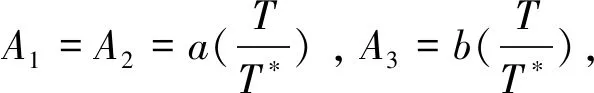
(5)
用该模型预测酵母和果蝇核小体占据率时,能够准确预测转录起始等调控区域的核小体缺乏区,但对整个基因组范围的核小体占据率的预测精度不是很高(如酵母第3号染色体的核小体占据率的预测结果与实验数据[70]的相关系数R=0.45,P<10-15)。
De Santis等提出的预测核小体形成自由能的统计热力学模型[37-38]与Miele的模型[41]相似,同样是计算twist, roll和tilt对应的自由能,但不包含核小体形成对应的熵变这一项。用该模型预测的一些酵母基因组区域的形成核小体的自由能与实验测定的核小体占据率相吻合,而且预测的100个核小体DNA的自由能与实验测定的自由能之间有很强的正相关性(R=0.92,P<0.001)[37]。
Deniz等建立的DNA变形能模型[45],形式上与式(2)相同,但其物理意义与前几种模型不同。该模型计算的变形能是用来表示使自由DNA片段的结构变为核小体DNA结构的变形能。这里,所谓的核小体DNA的结构指的是描述核小体DNA结构的每个碱基对梯阶(Base-pair step)对应的六个坐标自由度(见图1),这些坐标通过对多个X射线晶体衍射核小体DNA结构进行平均后获得。而初始的平衡态自由DNA结构则通过对少量的双链DNA(但包含所有约化的10种二核苷酸)在水环境中的分子动力学模拟获得。相关的力常数通过计算平衡态自由DNA结构参数的协方差获得(注:力常数矩阵是协方差矩阵的逆)。利用该模型,作者发现核小体缺乏区域的DNA变形能明显高于其侧翼序列,说明该区域从DNA序列的物理特性对核小体的形成有重要影响。
我们的模型[40,71-74]中主要考虑DNA弯曲和切变对应的变形能,称之为弯曲能和切变能。
缠绕组蛋白八聚体时DNA的弯曲主要取决于roll和tilt。假定导致DNA弯曲的扭力Fb均匀分布在DNA链上,则roll和tilt角的偏离平衡态的程度用下式表示:
(6)
其中i表示碱基对出现的位置,ρ0表示DNA的平均转角,τ0表示DNA的平均倾角,kρ和kτ分别是转角和倾角对应的力常数,均由DNA-蛋白复合物的晶体结构数据获得[40]。Ωi表示从核小体中心位置(二分轴)向两侧计算的累加的扭角,其中每种碱基对梯阶对应的扭角是来自大量DNA-蛋白复合物的平均扭角。其实,所有碱基对梯阶的扭角均取为w(i) =360°/10.4(核小体结构NCP147的平均扭角)对结果的影响微乎其微。
在第i碱基对梯阶中DNA的弯曲能为:
(7)
长度为L碱基对的DNA片段弯曲时,总的弯曲能为:
(8)
其中扭力Fb通过以下约束条件获得[9,40]。在核小体上,扭力Fb的作用下129 bp长度的DNA(注:核小体DNA两端各9 bp的区域是相对直的[9],计算弯曲能时不考虑)在组蛋白八聚体上缠绕579度。而这579度(α)的弯曲(或缠绕)是由描述DNA双螺旋结构的ρ和τ角共同造成的。因此形成核小体的约束条件为:
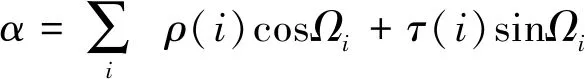
(9)
结合式(6)可得
(10)
同理,结合核小体DNA的另一结构约束条件(螺距)可得DNA切变能。
基于变形能可用玻尔兹曼分布近似估计序列形成核小体的潜能[40]。更普遍的做法是,将每一条染色体上的核小体分布看作是多个全同粒子(组蛋白八聚体)在一长链DNA分子上的分布,以变形能为基础,用巨正则系综理论计算出核小体在每一个147 bp序列片段上形成的概率,再通过概率加和计算出DNA位点上的核小体占据率[40,43]。具体计算方法如下:
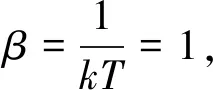
(11)
其中conf表示与DNA结合的非重叠粒子的任一构象,μ表示化学势,E(conf)和n(conf)分别表示任一构象对应的总能量和总粒子数。
巨配分函数由一系列正向配分函数(从DNA序列的某一端开始计算)的递进求解计算:
(12)
用同样的方式计算反向的配分函数(从DNA序列的另一端开始计算):
(13)
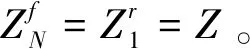
粒子(核小体)从第j个位点起始的概率(考虑了空间位阻效应)为:
(14)
第j个位点被核小体占据的概率为:
(15)
核小体占据率的计算以统计物理学巨正则系综理论为基础,考虑相邻核小体空间位阻效应。核小体占据率的另一种估算方法以Percus方程为基础[75]。若s位点的核小体DNA的变形能为E(s),分析核小体的组装(即组蛋白八聚体沿DNA链的组装)过程时,可将染色质模拟为在外势场E(s)中的有限长度l(核小体核心DNA长度,约等于147)的一维杆系统(流体)。热力学巨正则系统描述中,系统被视为处于温度项为β的热浴环境和化学势为μ的组蛋白八聚体热库中,系统在外势场E(s)中达到热力学平衡时其密度服从非线性积分方程(即Percus方程):
(16)
获得核小体密度的基础上利用窗口大小为147 bp的矩形函数计算核小体占据率:
OCC(s)=ρ(s)·Π147(s)
(17)
我们的变形能模型能较好地预测体外核小体占据率、体外组装的核小体在DNA序列上的准确位置、以及体外组装核小体的自由能(即核小体的稳定性)[40,72]。尤其是DNA弯曲能在核小体准确位置[40]和核小体滑动模式[72]的研究中有很好的应用前景。模型中用到的描述DNA结构的碱基对梯阶参数也能较好地区分核小体富含区和核小体缺乏区[76]。
还有一些模型中除了DNA序列依赖的简谐能以外还考虑了组蛋白和DNA之间的物理接触位点上的相互作用[77]。另外,有一些模型中虽然用到DNA螺旋结构参数[30]或其他DNA物理特征[31],抑或是涉及DNA弯曲度[33],但这些模型本质上是属于生物信息学方法,因为模型中主要是利用从序列提取的特征信息或DNA物理特征预测核小体的位置,而不涉及DNA变形能的计算。
2 讨 论
预测核小体定位的生物信息学方法和生物物理学方法的主要区别在于:(1)生物信息学方法通常是使用大量的可靠数据来训练模型[28-30],但生物物理学方法是基于DNA的物理化学性质(如二核苷酸的弯曲特性等)[37-45];(2)由于体内核小体定位还与其它非DNA因素有关,而且这种非DNA因素也可能是物种特异的(如物种特异的核小体定位模体),基于不同物种核小体数据训练的生物信息学方法的预测结果可能会优于单纯基于DNA物理化学性质的生物物理学方法;(3)生物物理学方法能够很好地预测核小体的中心位置及其可能的旋转定位[40],但只有少量的、设计巧妙的生物信息学方法才能做到这一点[34];(4)与生物信息学方法相比,生物物理学方法的物理意义更加明了,有助于理解问题本质。总的来说,生物信息学方法和生物物理学方法各有利弊。
各种生物物理学方法的主要差异包括:(1)使用的力常数不同,如有的用DNA-蛋白复合物的结构数据基础上计算的力常数[40,43],而有的用二核苷酸的解链温度表征其力常数[37];(2)使用的DNA结构参数不同,如有的用twist, roll, tilt, 有的用twist, roll, slide, 有的用roll, tilt, slide, 而有的用所有6种结构参数;(3)预测核小体形成能力的最终指标中所包含的成分不同,如有的包含变形能和熵变,有的包含变形能和DNA-组蛋白相互作用能,有的只有变形能成分;(4)使用的核小体模型不同,如有的用核小体核心颗粒的真实DNA结构模型[43],而有的用与核小体核心颗粒DNA拟合最好的理想的超螺旋结构模型。
我们认为,预测核小体定位时有以下问题值得注意:(1)力常数、平衡结构参数的估算准确与否直接影响模型的预测结果,而这些参数的估计中需要注意DNA螺旋不同结构参数之间的耦合相互作用[78-79],计算原理的可靠性(如基于核小体DNA结构的实验数据的力常数计算和基于分子动力学模拟的力常数计算)和计算用的实验数据量(如DNA-蛋白复合物或核小体DNA的晶体结构数据);(2)预测能力从以下三个角度评价:核小体占据率的预测、核小体中心位置的预测、核小体装配自由能的预测和核小体移动位置的预测,而不能只看其中一方面;(3)基于DNA序列的核小体定位预测模型应该用体外核小体定位序列训练模型,预测结果应与体外核小体定位数据相比较,这样能够挖掘核小体定位对DNA序列的依赖本质;(4)核小体定位预测模型的最终目标应该是准确预测体内核小体的位置,因为只有这样才能使我们的预测本身更具有生物学意义。
总体而言,基于DNA序列预测酵母核小体定位的生物物理学方法取得了很大的进展,而且该类方法相对机器学习类生物信息学方法而言其物理意义清晰,但仍存在一些问题有待解决,例如:模型中的参数强烈依赖于DNA序列片段的物理性质,不同长度、不同序列模式其物理意义可能存在很大的差异,这些都会直接地影响模型中参数的准确估计以及模型的应用效果;模型中的有些近似假设需要更坚实的依据;不同的模型其侧重点不同,适用问题(如核小体占据率的预测、核小体在序列上准确位置的预测、核小体稳定性的预测以及核小体形成能力的预测)也略有不同;特定环境或过程中(如RNA聚合酶竞争性结合、组蛋白的化学修饰、染色质重塑等)核小体定位会发生变化,这需要更专一的生物物理模型才能回答。
猜你喜欢
天天爱科学(2022年9期)2022-09-15
中学生数理化·七年级数学人教版(2022年6期)2022-06-05
天天爱科学(2022年4期)2022-05-23
当代水产(2022年3期)2022-04-26
导航定位与授时(2020年5期)2020-09-23
中华诗词(2020年1期)2020-09-21
铁道通信信号(2020年9期)2020-02-06
航空世界(2020年10期)2020-01-19
小学生作文(中高年级适用)(2018年5期)2018-06-11
知识经济·中国直销(2018年3期)2018-04-12
