
基于信息融合的小麦粉品质快速检测
2019-08-26 03:25陈嘉叶发银赵国华
食品与发酵工业 2019年15期
陈嘉,叶发银,赵国华,2,3*
1(西南大学 食品科学学院,重庆,400715) 2(重庆市甘薯工程技术研究中心,重庆,400715)3(重庆市农产品加工技术重点实验室,重庆,400715)
我国是小麦生产与消费大国,国家统计局相关数据显示,2017年我国小麦总产量13 433.39万t,占全国粮食总产量的20.3%。小麦粉制品营养丰富,蛋白质含量高,在很多地区都被作为人们的主食,对国民的健康与营养有着举足轻重的作用。
由于小麦品种、磨粉工艺、配粉比例、强化配方等的差异,不同品牌、厂家小麦粉中各化学成分的比例均不同,食品企业在收购原料、加工产品前均需要进行小麦粉品质指标检测。小麦粉品质是一个综合概念,小麦粉的蛋白质含量、湿面筋含量以及面团流变学指标等常被用来表征小麦粉的品质。传统的小麦粉品质评价过程非常繁琐,如使用凯氏定氮法测定蛋白质含量需要进行样品消化,蒸馏与吸收装置复杂且有刺激性气体释放;传统面团流变学品质测定更为耗时,通常进行1次粉质检测所耗费的时间(包括仪器设备清洗)约为50~60 min、1次拉伸检测所耗费的时间约为150 min[1],且操作过程有很强的经验性,测定结果重复性差,波动较大[2];基于近红外光谱(near-infrared spectra, NIR)的快速检测方法多集中于小麦粉的理化指标(如蛋白质含量、含水量等)的检测,对流变学指标(如粉质、拉伸等)的预测效果不佳[3-5]。因此,开发一种能对小麦粉多个品质指标进行快速检测的方法意义重大。
信息融合是将多个来源的信息进行合并或集成,以得到更完整、更精确、更可靠的推论或结果。不同传感器采集的信息存在互补性,这种互补性经过适当处理,可以补偿单一传感器的不精确性和测量范围的局限性,进而增加系统的可靠性。近年来,基于信息融合的快速检测技术已被用于食品掺假检测[6-8]、产地鉴别[9-10]、风味检测[11]、品质检验[12-15]、加工过程控制[16]等领域中。从某种程度上讲,近红外光谱与中红外光谱(mid-infrared spectra, MIR)具有一定的互补性,绝大多数有机化合物和无机化合物化学键的振动均会在MIR区产生基频吸收,在NIR区产生倍频吸收和合频吸收;NIR反映化学组成的综合信息,波峰重叠严重,MIR则反映特定基团或组分的特征吸收峰,光谱信号灵敏。BRS等[17]对比了NIR及MIR对黄豆粉品质的检测能力,发现虽然NIR模型的预测能力优于MIR模型,但MIR中包含NIR中未检测到的额外信息,2种光谱融合后可以提升模型的预测效果。LI等[18]融合MIR与NIR信息对三七粉的产地进行鉴别,结果显示,高层信息融合策略的识别准确率可达98%~100%。CASALE等[19]融合MIR与NIR光谱对特级初榨橄榄油的产地、品种进行鉴别,发现交互验证识别率可以达到90%以上。目前,基于信息融合的小麦粉品质快速检测方法尚未见报道。因此,本研究拟采用信息融合技术构建一种能同时检测多个小麦粉品质指标(蛋白质含量、湿面筋含量、吸水量、形成时间、稳定时间、弱化度)的快速检测模型,以期为信息融合技术在小麦粉品质检测方面的应用提供参考。
1 材料与方法
1.1 材料
小麦粉样品购自国内各地区的超市及农贸市场,共收集到不同产地、不同厂家及品牌的各类型市售小麦粉样品96份。样品采集后保存在自封袋中,在冷藏条件下保存备用。
1.2 仪器与设备
布鲁克MPA近红外光谱仪,德国Bruker公司;FTIR Spectrum 100傅立叶变换红外光谱仪,美国Perkin Elmer公司;Farinograph-E电子型粉质仪,德国Brabender公司;Glutomatic 2200面筋数量和质量测定仪,瑞士Perten公司;K-360全自动凯氏定氮仪,瑞士Buchi公司。
1.3 试验方法
1.3.1 小麦粉品质指标检测
蛋白质含量按照《谷物和豆类氮含量测定和粗蛋白含量计算凯氏法》(GB/T 5511—2008)规定的方法和试验条件进行检测。湿面筋含量按照《小麦和小麦粉面筋含量第2部分:仪器法测定湿面筋》(GB/T 5506.2—2008)规定的方法和试验条件进行检测。
粉质指标(吸水量、形成时间、稳定时间、弱化度)按照《小麦粉面团的物理特性吸水量和流变学特性的测定粉质仪法》(GB/T 14614—2006)规定的方法和试验条件,采用Farinograph-E电子型粉质仪,使用300 g揉面钵,30 ℃恒温条件下进行揉混检测。
1.3.2 红外光谱采集
近红外光谱的采集参考CHEN等[20]的方法,小麦粉样品在室温中平衡温度后,放入石英样品杯中,采用样品杯旋转式扫描,扫描范围12 000~4 000 cm-1,分辨率8 cm-1,扫描次数16次,PbS检测器,光谱使用自带的OPUS 7.0采集。
中红外光谱的采集参考LIU等[21]的方法,小麦粉样品在105 ℃烘箱中干燥24 h后,与无水KBr按1∶25(m∶m)比例研磨并进行压片,然后扫描,扫描范围4 000~450 cm-1,扫描次数20次,分辨率1 cm-1。扫描时应即时去除水分和CO2的背景干扰。采集到的光谱信息由仪器自带的Spectrum 6.0软件系统收集和处理。
1.3.3 异常样品检测与数据集的划分
异常值的判别参考SIGNES-PASTOR等[22]的方法,使用箱图法(boxplot)进行检测。删除异常样品后,采用SPXY法[23]从原始样本集中挑选72个样品作为校正集,剩余样品作为验证集,样品详细划分情况见表1。
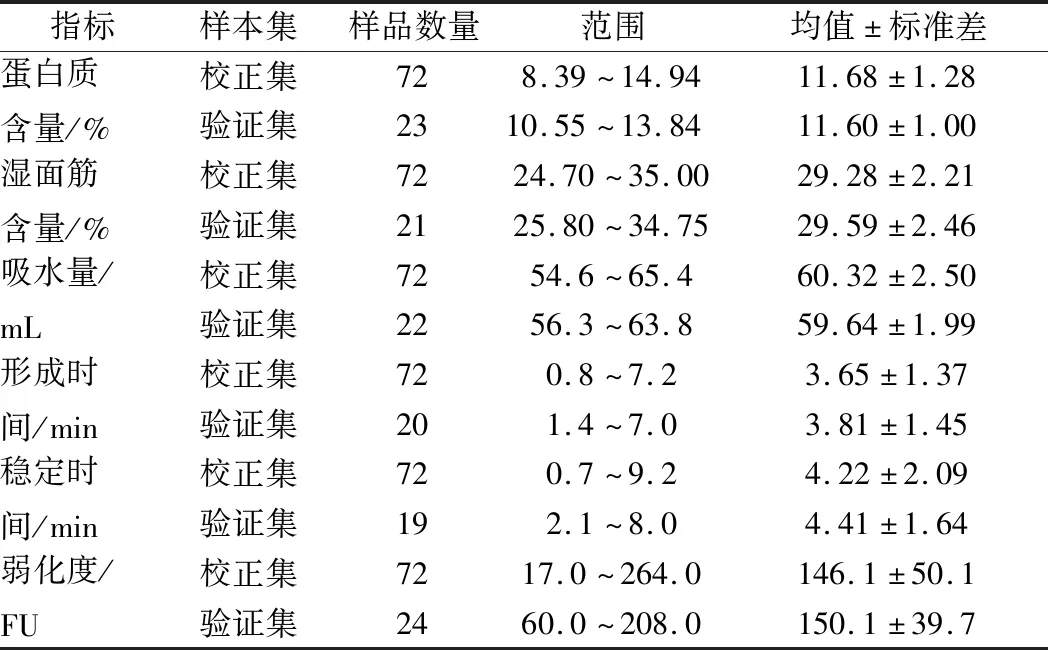
表1 小麦粉各品质指标校正集和验证集数据统计表
1.3.4 数据处理及建模
数据处理及建模采用Matlab 2016a(美国MathWorks公司)软件。在构建模型前,光谱须经过适当的预处理,以消除固体颗粒大小、表面散射以及光程变化对近红外光谱的影响,提高光谱的分辨率和灵敏度。试验中采用标准正态变量变换(standard normal variate transformation,SNV)、一阶导数(1stDer)、二阶导数(2ndDer)、SNV+1stDer及SNV+2ndDer 5种方法进行光谱预处理,以考察不同光谱预处理方法对模型预测能力的影响。
采用偏最小二乘法(partial least squares regression, PLS)构建信息融合模型,模型的预测能力采用模型对验证集样品的预测误差均方根(root mean square error of prediction, RMSEP)和预测值与实测值间的相关系数r考察。RMSEP主要用于评价模型对于外部样本的预测能力,其值越小,表明模型对外部样品的预测能力越高,反之则预测能力越低;相关系数r用于衡量验证集样本的预测值和实测值之间的相关程度,r越接近于1,表明预测值与实测值之间的相关程度越好。
为了进一步增强模型的预测能力,首先采用前向区间(forward interval,FI)变量筛选算法对信息融合(data fusion,DF)模型进行优化(记为FI-DF-PLS),其基本步骤是:将NIR与MIR同时分割为n个等长子区间,一共可以得到2n个子区间;在每个子区间上建立PLS局部模型,计算各局部模型的RMSEP值;选取RMSEP值最小的模型对应的子区间为第1固定子区间,将余下的子区间逐一与第1固定子区间组合建模,选择其中RMSEP值最低的模型对应的区间作为第2固定子区间,如此循环,直至所有剩余的子区间都进入模型;对比以上各步骤模型的RMSEP值,其中RMSEP最小者对应的区间组合即为n个子区间划分条件下的最佳区间组合。在FI-DF-PLS的基础上,再使用遗传算法(genetic algorithm,GA)对模型进一步优化,其操作步骤为:对模型进行20次GA变量筛选,统计各光谱波数点总的被选频率,然后按照频率由高到低的顺序,将各波数点变量依次加入模型中并计算RMSEP值,RMSEP值最低时对应的模型即为最优模型,记做FI-GA-DF-PLS模型。
2 结果与分析
2.1 小麦粉近红外光谱及中红外光谱
图1为小麦粉样品的近红外光谱与中红外光谱图。
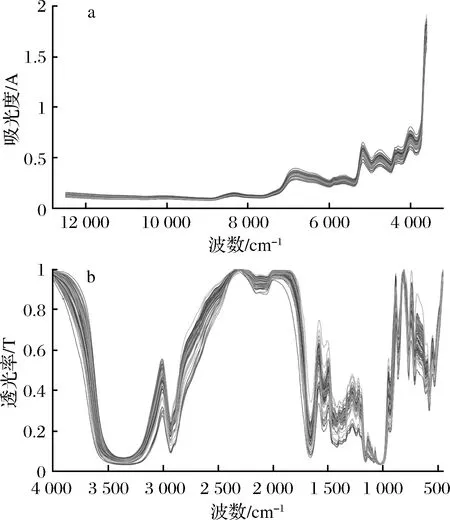
图1 小麦粉样品近红外光谱(a)与中红外光谱(b)图
Fig.1 NIR(a) and MIR(b) spectra of wheat flour samples

2.2 光谱预处理方法的选择
光谱预处理方法对建立预测能力强、稳定性好的分析模型至关重要,有时甚至起决定作用[26]。分别采用SNV,1stDer,2ndDer,SNV+1stDer和SNV+2ndDer 5种方式对NIR及MIR光谱进行预处理并建立PLS模型,对比各预处理方法对NIR及MIR模型的影响,结果见表2。
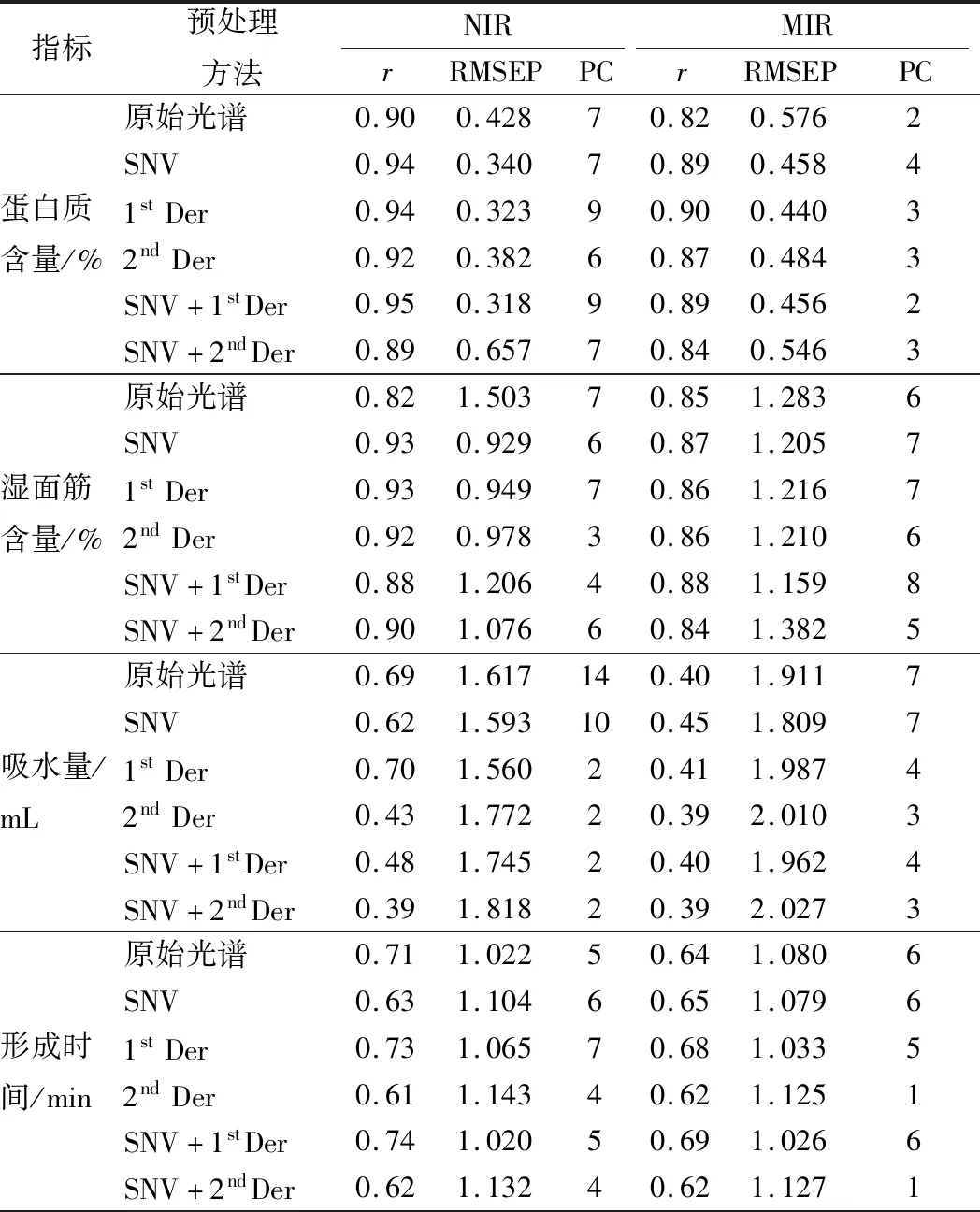
表2 光谱预处理方法对近红外和中红外模型的影响
续表2

指标预处理方法NIRMIRrRMSEPPCrRMSEPPC稳定时间/min原始光谱0.651.13940.281.5734SNV0.421.48230.331.56861stDer0.791.09080.251.67612ndDer0.751.10470.211.8212SNV+1stDer0.671.22960.211.6635SNV+2ndDer0.791.10160.201.8152弱化度/FU原始光谱0.5932.92520.1241.5812SNV0.5534.90230.1041.74511stDer0.6131.54650.4138.74772ndDer0.6233.10680.2140.9311SNV+1stDer0.5333.97660.3838.7616SNV+2ndDer0.5834.99190.2140.9951
注:PC,主成分数。
可以看出,对同一指标,NIR与MIR最佳的光谱预处理方式不同。由于仪器、样品特征和测量环境、条件的变化,光谱预处理尚无通用的解决方法,需要针对每个指标分别进行最优光谱预处理方法的筛选,以提高模型的预测精度。依据RMSEP最优原则,分别选择各指标最优的NIR及MIR光谱预处理方法,蛋白质含量模型NIR及MIR最优预处理方法分别为SNV+1stDer和1stDer,湿面筋含量模型NIR及MIR最优预处理方法分别为SNV和SNV+1stDer,吸水量模型NIR及MIR最优预处理方法分别为1stDer和SNV,形成时间模型NIR和MIR最优预处理方法均为SNV+1stDer,稳定时间模型NIR和MIR最优预处理方法分别为1stDer和SNV,弱化度模型NIR和MIR最优预处理方法均为1stDer。
2.3 基于前向区间算法的变量筛选
将NIR及MIR预处理后进行信息融合并构建预测模型。为了提高模型的预测精度,将NIR及MIR分别划分为10~50个子区间,采用前向区间变量筛选算法筛选NIR及MIR光谱中的有效变量区间,构建前向区间信息融合模型(FI-DF-PLS),结果见表3。
可以看出,与单光谱模型相比(见表2),采用全光谱直接进行信息融合建模后,模型的预测精度并未提高,甚至略有下降。这是因为2种光谱融合后,光谱中的噪声及干扰信息互相叠加,影响了模型的预测精度。因此,需要使用适当的化学计量学方法进行光谱变量筛选,消除部分冗余、干扰信息,再进行信息融合,以提高模型的预测精度。
总体上,FI-DF-PLS模型的预测能力随着光谱子区间划分数量的增加而提升,对于蛋白质含量、湿面筋含量、吸水量、稳定时间和弱化度,光谱子区间划分为50时预测精度最高;对于形成时间,光谱子区间划分为40时预测精度最高。
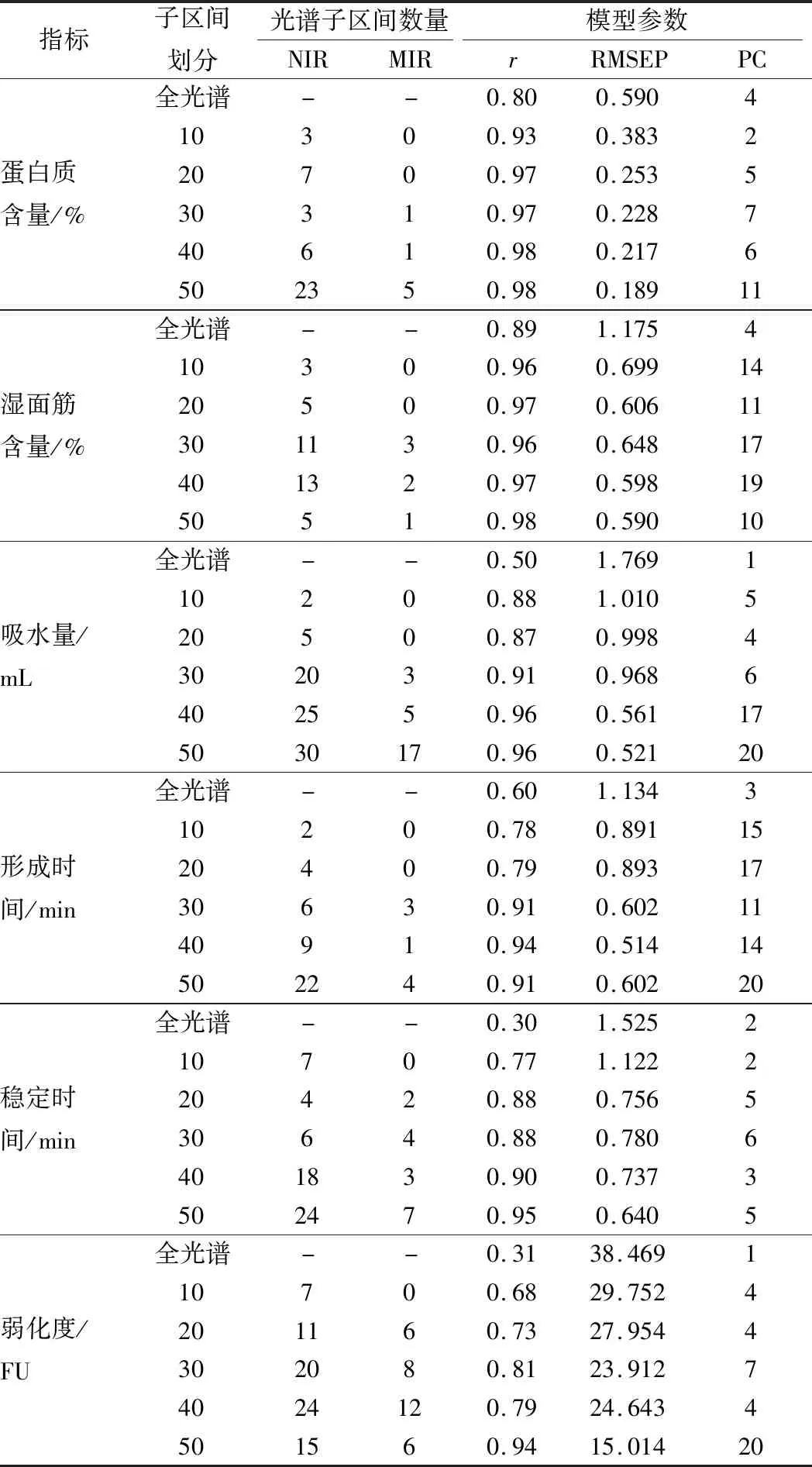
表3 光谱子区间划分对信息融合模型的影响
从表3还可以看出,当光谱子区间划分数较小时,FI-DF-PLS算法筛选出的最优模型不包含MIR光谱子区间的数据,这是因为对每个指标,NIR模型预测效果均优于MIR模型(表2),当光谱子区间划分数量较少时,一个子区间内包含的变量数量较多,其中有用信息与干扰噪声无法进行有效的区分,MIR子区间的引入反而可能降低模型的预测效果。当光谱子区间划分数量较大时,单个光谱子区间中包含的变量数量较少,有用信息与干扰噪声得以区分,有效信息子区间又通过FI-DF算法的排列组合而得以集中,从而提高了模型的预测精度。因此,当光谱子区间划分数量增加时,FI-DF-PLS模型可以充分利用MIR及NIR中的有效信息。从表3可以看出,最优蛋白质含量FI-DF-PLS模型中包含了23个NIR子区间和5个MIR子区间;最优湿面筋含量FI-DF-PLS模型中包含了5个NIR子区间和1个MIR子区间;最优吸水量FI-DF-PLS模型中包含了30个NIR子区间和17个MIR子区间;最优形成时间FI-DF-PLS模型中包含了9个NIR子区间和1个MIR子区间;最优稳定时间FI-DF-PLS模型中包含了24个NIR子区间和7个MIR子区间;最优弱化度FI-DF-PLS模型中包含了15个NIR子区间和6个MIR子区间。各模型的光谱子区间选择见图2所示。

图2 最优信息融合模型近红外及中红外光谱子区间选择
Fig.2 Selected subintervals in the optimist data fusion models
注:图中灰色部分为最优FI-DF-PLS模型所用子区间;a和b,蛋白质含量NIR和MIR子区间;c和d,湿面筋含量NIR与MIR子区间;e和f,吸水量NIR与MIR子区间;g和h,形成时间NIR与MIR子区间;i和j,稳定时间NIR与MIR子区间;k和l,弱化度NIR与MIR子区间。
最优FI-DF-PLS模型的r和RMSEP值随固定子区间数量增加而变化的趋势见图3。预测形成实际的模型中最多有80个光谱子区间(即MIR与NIR子区间数量之和)时精确度最高,所以图3-d横坐标轴最大值为80;其余模型均在光谱划分为50个子区间时预测精度最高,因此横坐标轴最大值为100。可以看出,在算法运行之初,由于筛选出的固定子区间数量较少,用于模型校正的光谱有效信息不足,FI-DF-PLS模型预测能力较低;随着固定子区间数量增加,模型中的有效信息不断积累,FI-DF-PLS模型预测效果不断提升,r不断上升,RMSEP不断下降;当固定子区间积累到一定数量时,RMSEP达到最小;随后RMSEP随着固定子区间数量的增加不断升高,这是因为加入更多的光谱区间引入了过多无用和干扰信息,从而引起了模型预测效果的下降。
2.4 基于遗传算法的模型进一步优化
遗传算法基于对生物界自然选择和自然遗传机制的模拟来解决实际问题,是一种具有高度的并行、随机和自适应性的搜索方法。为了进一步简化模型,提高模型的预测精度,采用遗传算法对FI-DF-PLS模型进一步优化,结果见表4所示。

a-蛋白质含量;b-湿面筋含量;c-吸水量;d-形成时间;e-稳定时间;f-弱化度;Δ-RMSEP值;■-r值
图3 FI-DF-PLS模型r和RMSEP值变化情况
Fig.3 Changes of r and RMSEP values in FI-DF-PLS model

表4 遗传算法对FI-DF-PLS模型的优化结果
对于蛋白质含量、吸水量、形成时间、稳定时间和弱化度,最优FI-DF-PLS模型经过遗传算法进行变量二次筛选后,模型使用的变量数量降低的同时,预测精度均有所提升。特别是稳定时间模型,经遗传算法进行变量二次筛选后,模型所用的变量数量由698降低至245,大大降低了模型的复杂程度。对于湿面筋含量模型,遗传算法二次变量筛选前后模型使用变量数量无变化,这是因为湿面筋含量最优FI-DF-PLS模型中的光谱变量数量已非常少(186个),再使用遗传算法进行变量二次筛选对模型的影响程度有限。经遗传算法进行二次优化后,所得的FI-GA-DF-PLS模型对验证集蛋白质含量、湿面筋含量、吸水量、形成时间、稳定时间和弱化度的预测相关系数r分别达到了0.98、0.98、0.97、0.94、0.95和0.95,RMSEP分别为0.181、0.590、0.455、0.502、0.557和13.047。
3 结论
本试验采用信息融合技术,融合小麦粉的MIR及NIR光谱信息,建立了基于信息融合的小麦粉品质快速检测模型,并采用前向区间-遗传算法对信息融合模型进行了优化。结果显示,与MIR或NIR预测模型相比,未经变量筛选的信息融合模型的预测精度并未提升;经过前向区间算法进行变量筛选后,信息融合模型的预测能力大幅度提升;遗传算法可以对模型进一步优化,提升模型的预测精度并简化模型所用变量数量。试验构建的最优FI-GA-DF-PLS模型对验证集蛋白质含量、湿面筋含量、吸水量、形成时间、稳定时间和弱化度的预测相关系数r分别达到了0.98、0.98、0.97、0.94、0.95和0.95,RMSEP分别为0.181、0.590、0.455、0.502、0.557和13.047,达到了较好的预测精度。采用信息融合技术与前向区间-遗传算法变量筛选构建小麦粉多品质指标的预测模型时,样品不需前处理,操作简便迅速,为小麦粉品质快速检测提供了一种新的思路与方法。
猜你喜欢
粮食加工(2022年5期)2022-12-28
今日农业(2022年14期)2022-11-10
中学生数理化·八年级物理人教版(2022年9期)2022-10-24
温州大学学报(自然科学版)(2022年2期)2022-05-30
食品安全导刊(2021年21期)2021-08-30
潍坊学院学报(2020年2期)2021-01-18
中国外汇(2019年13期)2019-10-10
制导与引信(2017年3期)2017-11-02
北京信息科技大学学报(自然科学版)(2016年6期)2016-02-27
海军航空大学学报(2015年4期)2015-02-27
