
基于全卷积神经网络复杂场景的车辆分割研究
2019-09-10 07:22张乐张志梅刘堃王国栋
青岛大学学报(工程技术版) 2019年2期
关键词:深度学习
张乐 张志梅 刘堃 王国栋






摘要: 针对目前存在的复杂交通场景中车辆分割精度不足的问题,本文提出了一种基于全卷积神经网络对图像中车辆进行分割的方法。在VGG16Net基础上,将全连接层改为卷积层,为获得更精细的边缘分类结果,减少了部分卷积层,并融合浅层和深层特征,同时,为提高交通环境下车辆的分割精度,减少其他类别目标的干扰,将对车辆目标的分割问题改为基于像素的二分类问题,为提高网络的训练速度,采用Adam优化算法对网络进行训练。实验结果表明,与现有的全卷积神经网络分割效果相比,该网络对复杂交通场景下的车辆分割精度明显提高。该研究在智能交通方面具有较好的应用前景。
关键词: 全卷积神经网络; 车辆分割; Adam优化算法; 深度学习
中图分类号: TP389.1 文献标识码: A
随着科学技术的发展,交通智能化成为当今研究的必然趋势[13],在智能交通系统中的车辆追踪识别和自动驾驶等方面,车辆分割精细程度起到关键性作用。将图像分为背景和车辆子区域的过程被称为车辆分割。目前,车辆分割方法主要是基于传统方法和基于深度学习的方法。在基于传统方法方面,吴忻生等人[4]提出一种结合最优分割雙阈值法和条件随机场模型等对车辆分割的算法;F. Cloppet等人[5]提出用分水岭分割算法来分割车辆;A. Zaccarin等人[6]构建后验概率模型并利用动态场景参数,区分车辆目标与背景。这些传统方法计算量大、处理过程复杂,易造成过分割现象,在复杂环境下分割精准率低且效果差;在基于深度学习方法方面,J. Long等人[7]提出了一种基于全卷积网络(full convolutional network,FCN)的语义分割方法,该方法通过像素级分类实现语义分割;计梦予等人[89]分析了语义分割的常用算法及最新成果;徐国晟等人[1013]对车道线及铁路场景下的语义分割进行研究;高凯珺等人[14]提出使用卷积反卷积神经网络,对无人车夜视图像进行语义分割;V. Badrinarayanan等人[15]通过最大非线性上采样方法实现语义分割。这些基于深度学习的方法,随着解决的问题越来越复杂,网络复杂程度及消耗的计算资源增大,训练时间变长。因此,通过分析比较随机梯度下降法(stochasitc gradient descent,SGD)、monmentum动量法[16]、内斯特罗夫加速梯度(nesterov accelerated gradient,NAG)[17]、Adagrad[18]和Adam(adaptive moment estimaton)[19]等优化算法优缺点后,本文选择使用收敛速度最快的Adam算法训练网络,并基于VGG16Net网络,构建全卷积神经网络。结合大量车辆样本数据集进行训练,提高了在复杂交通环境下车辆图像的分割精度。该研究为智能交通的发展奠定了理论基础。
1 基于全卷积神经网络车辆分割模型
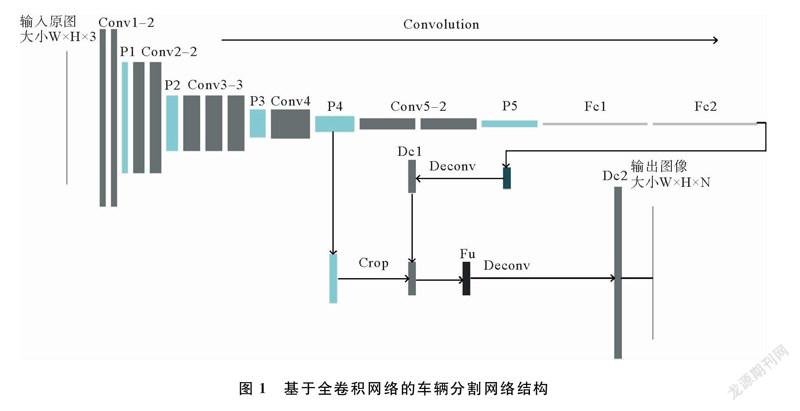
本文以Karen等人[20]提出的VGG16Net模型为基础,构建了复杂环境下的车辆分割全卷积神经网络。本文构建的基于全卷积网络的车辆分割网络结构如图1所示。图1中,Conv表示卷积层,Conv12表示连续两个卷积,P表示池化层,Fc表示全连接层转换成的卷积层,Dc表示反卷积输出层,Fu表示深层特征与浅层特征融合结果。
VGG16Net是典型的卷积神经网络,由13层卷积、5层池化和2层全连接组成,具有很好的自然图像特征空间的表征能力。因此,本文以VGG16Net为基础,按照图1网络结构,构建全卷积神经网络。
将VGG16 Net中的两层全连接层转换为卷积层,直接对最后卷积层输出的特征图反卷积,获得图像的分割结果。但由于转换后的卷积层属于深层卷积层,获得的特征图因卷积次数过多丢失很多细节信息,分割结果粗糙。因此,在此变换基础上,构建跳跃网络结构,融合深层和浅层网络特征(见图1)。因为网络浅层含有更多的细节信息,而深层卷积层的特征含有更抽象的语义信息,适当的将反卷积层的预测结果与浅层网络输出的特征图像进行融合,可以得到更为精确的分割结果。因FCN网络模型[7]是对21种类图像的语义分割,在对基于二分类目标分割时,网络结构复杂,对目标边缘、细节特征的分割效果并不好。因此,减少卷积层数,改变最后输出分类个数,并将21种类别的目标分割问题转换为基于像素的二分类问题,减少其他特征干扰,提高交通环境下车辆图像的分割像素准确率和类平均准确率。采用数据集对搭建好的神经网络训练,训练完成的神经网络可用于对车辆图像的分割。
1.2 全连接层卷积化及网络层的融合
为了将卷积层提取的特征用以实现像素级分类,达到对图像分割的目的,将VGG16Net最后全卷积层换成卷积层。由于全连接层的权重矩阵是固定的,导致输入神经网络的图像大小必须是固定的,将全连接层改为卷积层后,输入图像大小不必固定,在一定程度上保留了目标的特征。实现方式是将全连接层中的每个神经元,改为与其输入维度相同的卷积核卷积操作后的输出。若有N个输出,卷积核的个数也为N,可获得N个不同的输出。N标着输出的类别个数,变换后的网络,通过卷积层的特征图与输入的原图大小并不一致,为使网络的最终输出与输入大小相同,在全连接层转换为卷积层后,需增加一个上采样层,或者反卷积层,这样整个网络只有卷积层和池化层,不存在全连接层,可称为全卷积神经网络。
通过反卷积或者上采样等获得与原图大小相等的输出,细节信息少,直接用于像素级分类的准确率不高,所以最后卷积层输出图像经过反卷积,获得与浅层网络输出的特征图等大的图像,通过跳跃结构与浅层网络相融合,再通过反卷积,获得与输出图像相等的图像。网络层的融合增加了丰富的细节信息,实验证明了提高像素级分类的准确率。
对于机器学习中大多数监督学习模型,使用合适的优化算法得到最小的函数损失值,以此得到最优的权值。目前,Adam算法是训练速度最快,效果最好,并对超参数的选择相当鲁棒的优化算法。在Adam中,动量直接并入梯度一阶矩的估计,并且修正从原点初始化的一阶矩和二阶矩的估计。因此,本文采用Adam优化算法训练网络参数。
2 实验验证
2.1 数据集
本文采用Pascal VOC2012数据集和基于青岛交通监控视频采用的Pascal VOC数据集的格式,制作VehicleDataSet数据集。这是由于Pascal VOC2012数据集中包括的车辆数据集只有约700张,训练时数据量少,交通场景不丰富,为获得更好的训练后的网络模型,本文制作了VehicleDataSet数据集。VehicleDataSet数据集共有1 000张图像,包括光照强烈的白天、光照弱的傍晚、不同角度下的车辆以及车辆稀疏、拥堵等各种不同场景,VehicleDataSet数据集中的车辆图像如图2所示。
本实验采用Ubuntu1404操作系统,深度学习框架采用基于NVIDIA GTX 970 GPU硬件平台上搭建的TensorFlow。网络在训练过程中,首先使用VGG16Net预训练好的网络模型作为实验的微调模型,用于初始化本文构建的网络模型前10层网络参数,即第3次池化层之前的网络参数,同时使用Pascal VOC2012数据集和VehicleDataSet数据集对所有网络进行训练,并使用Adam更新网络权值,直到网络收敛。
对训练好的神经网络进行测试,将1幅任意大小的图像输入已经训练好的网络中,通过前向传递的方式,对图像每个像素点进行预测分类,通过对每个像素的分类,实现对整张图像中的目标分割。
2.2 分割结果评价指标
本文提出的对车辆分割的方法,是对图像进行像素级分类,即对每个像素点进行分类。其性能评估方法包括:像素准确率、类平均准确率和平均区域重合度(mean IU,intersection over union)3种,平均IU表示预测像素正确的交集,除以预测像素和原来像素的并集。各性能评估方式定义如下:
2.3 實验结果及分析
在复杂的交通环境下,基于本文构建的全卷积神经网络,对2分类和21分类的分割结果进行比较。实验结果表明,对于不完整的车辆,21分类网络与2分类网络相比,分割效果并不好,如车辆细节和边缘轮廓分割不准确,且当环境变的复杂,如光照不足、有阴影遮挡车辆、车辆数密集等,2分类网络的分割准确率比21分类网络分割准确率高。不同分割种类的分割结果如图3所示。
对于2分类全卷积神经网络和21分类全卷积神经网络,不同训练数据集车辆分割情况如表1所示。由表1可以看出,在不同训练样本条件下,2分类网络比21分类网络对车辆的分割精度有明显提高,而且随着样本数的增加,像素准确率、类平均准确率和平均IU均有所提高。对于2分类和21分类的分割网络模型,采用2分类分割算法的平均IU可以达到90%,比21分类网络模型对车辆目标的平均IU值提高4%。
使用相同数据集微调各种不同全卷积神经网络,由相同数据集的分割结果可以看出,文献[7]中FCN模型随着融合次数的增加,分割精度在上升,证明进行浅层与深层的融合在一定程度上能提高分割准确率。本文针对交通环境下车辆分割问题,减少深层卷积层,两次融合增加了分割结果中的噪声,导致在车辆边缘部分分割效果并不好,在减少深层网络卷积层的基础上,只进行1次深层特征与浅层特征融合,得到最优分割结果。不同模型分割结果如图4所示。
由图4可以看出,一定程度地增加训练样本的容量,可以提高全卷积神经网络对目标分割的准确率,对网络的中深层特征层与浅层特征层适当融合,提取的特征更多更细,识别的像素更多更准确,对目标分割的准确度也会提高。同时,降低网络分割目标的类别数,一定程度上提高了目标分割的准确率。
使用本文所提出的全卷积神经网络,得到不同环境下车辆分割可视化后的结果,其中,复杂场景分为光照强弱、是否有阴影和拥堵场景等。可视化的车辆分割结果如图5所示。
1) 光照强弱。由于白天到夜晚间的光照不同,且夜间光照弱,车灯具有明显的反光现象,影响车辆分割。以是否有自然光为标准,分为光照弱和一般场景图像。
2) 是否有阴影。由于车道两旁建筑物不同,易对行驶的车辆覆上阴影。以是否覆上阴影为标准,分为有阴影和一般场景图像。
3) 拥堵场景。车辆图像密集,使图像较为复杂,若每幅图像超过10辆车,则将其判定为拥堵场景。
由图5可以看出,本文提出的算法,在复杂交通环境下也能很好实现车辆分割,并且很接近真实的分割图。
将本文FCN结果可视化图和人工标记可视化图进行对比,细节对比图如图6所示。
由图6可以看出,当车辆边缘有轻微凸起时,对后视镜和车轮边缘的分割较平滑,并不理想;当有车辆粘连时,粘连部分的分割效果比较差,但对于整体边缘的分割效果较好。
3 结束语
本文基于VGG16Net构建全卷积神经网络,并将其用于复杂交通环境下的车辆分割。研究了把对图像的分割问题转换成基于像素的二分类问题后对车辆分割结果的影响,同时研究了深层与浅层融合次数对分割结果的影响。实验结果表明,对于复杂环境中的车辆,适当的将深层卷积层与浅层卷积层特征融合,可以提高对车辆的分割准确率,而过多融合和不融合的分割效果都不佳。对于不同的分割目标,应选择合适的融合次数。将目标分割问题转换成对像素的二分类问题后,减少了其他目标特征的干扰,提高了车辆的分割准确率,但对于光照弱场景下的车辆及粘连遮挡过多的车辆,分割效果并不好,以后将对此问题进一步展开研究。
参考文献:
[1] 王晓, 要婷婷, 韩双双, 等. 平行车联网: 基于ACP的智能车辆网联管理与控制[J]. 自动化学报, 2018, 44(8): 13911404.
[2] Li D M, Deng L B, Cai Z M, et al. Intelligent Transportation System in Macao Based on Deep SelfCoding Learning[J]. IEEE Transactions on Industrial Informatics, 2018, 14(7): 32533260.
[3] Yang Z, Lilian S C, Pun C. Vechicle detection in intelligent transportation systems and its applications under varying environments: A review[J]. Image and Vision Computing, 2018, 69(1): 143154.
[4] 吴忻生, 邓军, 戚其丰. 基于最优阈值和随机标号法的多车辆分割[J]. 公路交通科技, 2011, 28(3): 125132.
[5] Cloppet F, Boucher A. Segmentation of overlapping/aggregating nuclei cells in bioimages [C]∥19th International Conference on Pattern Recongnition. Tampa, USA: IEEE, 2008: 14.
[6] MartelBrisson N, Zaccarin A. Kernel Based Learning of Cast Shadows from a Physical Model of Light Sources and Surfaces for Low Level Segmentation[C]∥Proceedings of IEEE Conference on Computer Vision and Pattern Recognition. Anchorage, Alaska, USA: IEEE, 2008: 18.
[7] Long J, Shelhamer E, Darrell T. Fully convolutional networks for semantic segmentation[C]∥IEEE Conference on Computer Vision and Pattern Recognition. Boston, MA, USA: IEEE, 2015: 34313440.
[8] 計梦予, 袭肖明, 于治楼. 基于深度学习的语义分割方法综述[J]. 信息技术与信息化, 2017, 24(10): 137140.
[9] 张新明, 祝晓斌, 蔡强, 等. 图像语义分割深度学习模型综述[J]. 高技术通讯, 2017, 27(9): 808815.
[10] 徐国晟, 张伟伟, 吴训成, 等. 基于卷积神经网络的车道线语义分割算法[J]. 电子测量与仪器学报, 2018, 32(7): 8994.
[11] He Z W, Tang P, Jin W D, et al. Deep semantic segmentation neural networks of railway scene[C]∥37th Chinese Control Conference. Wuhan, China: China Academic Journal Electronic Publishing House, 2018: 90959100.
[12] 吴骏逸, 谷小婧, 顾幸生. 基于可见光/红外图像的夜间道路场景语义分割[J]. 华东理工大学学报, 2018, 44(6): 111.
[13] 李琳辉, 钱波, 连静, 等. 基于卷积神经网络的交通场景语义分割方法研究[J]. 通信学报, 2018, 39(4): 123130.
[14] 高凯珺, 孙韶媛, 姚广顺, 等. 基于深度学习的无人车夜视图像语义分割[J]. 应用光学, 2017, 38(3): 421428.
[15] Badrinarayanan V, Kendall A, Cipolla R. SegNet: a deep convolutional encoderdecoder architecture for image segmentation[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(12): 24812495.
[16] Qian N. On the momentum term in gradient descent learning algorithms. Neural Networks[J]. The Official Journal of the International Neural Network Society, 1999, 12(1): 145151.
[17] Nesterov Y E. A method of solving a convex programming problem with the convergence rate o(1/k2)[J]. Doklady ANSSSR (Translated as Soviet. Math. Docl.), 1983, 27(1): 543547.
[18] John L D, Hazan E, Singer Y.Adaptive subgradient methods for online learning and stochastic optimization[J]. Journal of Machine Learning Research, 2010, 12(7): 257269.
[19] Kingma D P, Ba J L. Adam: a method for stochastic optimization[C]∥International Conference on Learning Representations. California, San Diego, USA: SDRS, 2015.
[20] Simonyan K, Zisserman A. Very deep convolutional networks for largescale image recognition[C]∥ International Conference on Learing Representations. California, San Diego, USA: SDRS, 2014: 11501210.
猜你喜欢
中国教育技术装备(2016年19期)2016-12-27
中国远程教育(2016年11期)2016-12-27
现代商贸工业(2016年25期)2016-12-26
江苏教育·中学教学版(2016年11期)2016-12-21
江苏教育·中学教学版(2016年11期)2016-12-21
现代情报(2016年10期)2016-12-15
考试周刊(2016年94期)2016-12-12
新教育时代·教师版(2016年23期)2016-12-06
法制与社会(2016年32期)2016-12-01
软件导刊(2016年9期)2016-11-07
