
基于优化的CAS算法实现线程安全的HashMap
2019-10-08 06:27吴恩慈
软件 2019年6期
摘 要: HashMap内存数据结构存在相当广泛的应用场景,通过Hash函数的Key直接获取对应的值,能够确保搜索的时间复杂度为O(1)。HashMap数据结构存在哈希冲突与线程安全問题,悲观锁机制实现线程安全的方法存在很大的性能开销。本文提出了基于优化的CAS算法,实现线程安全的哈希映射数据结构,内部采用数组、链表和红黑树实现了高并发环境下读写操作。通过增加版本戳避免CAS算法的ABA问题,CAS算法实现的无锁方式避免了锁竞争的开销,使用红黑树来优化链表,确保大规模数据集的检索时间复杂度保持O(logn)。支持多线程扩容操作,在执行效率方面有良好的表现。通过大规模的并发压力测试,验证了该数据结构在性能上有稳定的提升。
关键词: 无锁机制;分段锁;CAS算法优化;红黑树;线程安全
中图分类号: TP311.12 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.06.043
本文著录格式:吴恩慈. 基于优化的CAS算法实现线程安全的HashMap [J]. 软件,2019,40(6):185190
【Abstract】: HashMap data structure is widely used in the industry. The Hash function directly reads the corresponding value through the input key, which ensures that the time complexity of the search algorithm is O(1). There are hash conflicts and thread safety issues in the HashMap. The pessimistic locking mechanism implements thread safety methods with great performance overhead. This paper proposes a HashMap structure based on optimized CAS algorithm to implement thread safety. The internal use of arrays, linked lists, red-black trees. Achieves read and write efficiency in high-concurrency environments. The CAS algorithm implements lock-free mode to avoid the overhead of lock competition. Red-black trees are used to optimize the linked list, ensuring that the time complexity remains O(logn) when the data set is large. Supports multi-thread expansion operations in a lock-free state, and concurrent processing reduces the time overhead of capacity expansion. Through large-scale concurrent testing, it is verified that the data structure has a stable improvement in performance.
【Key words】: Lock-free; Segment Lock; Optimized CAS; Red-black Tree; Thread-safe
0 引言
随着在线业务规模越来越大,信息系统的并发操作也越来越大,高并发一直是业界面临的问题。Hash函数根据Key直接获取对应的值,能够提供时间复杂度为O(1)的搜索算法,在很大程度上提高了搜索效率,存在非常广泛的应用场景。另外,大规模数据集下HashMap数据结构往往存哈希碰撞,以及高并发环境下的线程安全问题。悲观锁的安全机制存在性能瓶颈,不能充分发挥多核处理器的作用。当大量进程同时访问堆栈时,会竞争读取与更新共享变量,从而导致大量干扰。在各种工作负载下提供良好性能的并发算法,通常不使用锁,并使用各种机制来减少对共享内存的争用,增加并行执行的可能性。本文在研究相关文献与总结实际经验的基础上,主要完成了3个方面的工作。
(1)分析了HashMap内存数据结构存在哈希冲突与线程安全的问题,指出通过悲观锁机制实现线程安全的方法存在很大的性能开销,不适合大规模、高并发操作的应用场景。
(2)研究了并行HashMap算法与数据结构,解析算法实现中的分段锁技术、HashEntry对象的不变性机制。分段锁技术提高了并行度,同时也使得数据结构也变的复杂,降低了数据一致性的要求。
(3)提出了基于CAS(Compare And Swap)算法实现线程安全的哈希映射数据结构,对CAS算法存在的问题提出了有针对性的优化策略,并且提供了算法实现代码。数据结构内部采用数组、链表和红黑树实现了高并发环境下读写操作,该方法有效的减少对锁竞争。通过大规模的并发测试,验证了该数据结构在性能上有稳定的提升。
1 相关工作
文献[1]采用类似于链表的数据结构,增加哈希表中每个相同哈希地址对应存储空间的Value个数,达到是降低哈希冲突的目的[1]。该方法支持的数据集容量有限,很难保证持续稳定的读取速度。文献[2]使用内容寻址存储器作公共溢出缓存区,降低了插入时哈希冲突的概率,改善了哈希表最坏访问时间问题[2]。文献[3]通过引入外部区分表实现完美哈希函数,在查表操作过程中,首先读取外部区分表中当前Key对应的区分位,然后将区分位合并到当前Key后再进行哈希函数求值[3]。该方法缺点是构建外部区分表比较耗时,不支持新的Key动态插入。文献[4]提出了一种存储结构块列表来存储冲哈希突数据的方法,使用缓存机制提高Key的检索效率。该方法在桶数目充足的情况下能够有效降低内存消耗[4]。文献[5]研究了发生哈希冲突的本质原因,数据元素检索的先验概率[5]。提出了一种减少了碰撞期间搜索长度和响应时间的方法。
文献[6]提出了一种基于同步原语CAS的无锁模式,不会导致ABA问题与环绕问题,可为多种数据类型提供无锁功能[6]。在读写对象时轮询不同的位置,通过其位置检查对象的一致性。文献[7]提出了一种多线程环境下的无锁算法,某个进程在尝试应用操作失败时,再次尝试之前等待,减少并发系统中对共享资源的竞争[7]。在许多情况下可以提高吞吐量,采用这种方法来实现可扩展的无锁操作。文献[8]研究了Haskell语言中的基于无锁的同步机制,实现任务池模式的不同实例,通过合成算法与LU分解来检查其的性能[8],结果表明无锁任务池的并行性能存在明显的优势。文献[9]提出了一种无锁的并发堆栈抽象模型,减少了堆栈上的锁争用,允许并行执行多对推送和弹出操作,并行操作可以转换为可线性化的抽象模型[9]。文献[10]提出了基于无锁队列实现并发组合的算法,推导可伸缩堆栈算法,简化了无锁算法实现,且更加易于理解[10]。
2 问题分析
2.1 HashMap线程安全问题
HashMap内部使用数组保存键值对数据,插入一个新的键值对时,根据Key的哈希值对数组的大小取模,计算结果作为数组的下标,把键值对插入到数组的该位置。如果数组的该位置上已经存在元素,表明产生了哈希冲突问题,需要在该位置生成链表数据结构。哈希冲突最严重的情况,所有元素都定位到数组的同一个下标位置,生成一个很大的链表结构,检索某个Key需要遍历链表的所有节点,时间复杂度变成O(N)。
在多线程环境且未作同步的情况下,对同一个HashMap做写入操作,可能导致两个或以上线程同时做Rehash动作,可能导致循环键表出现,一旦出现线程将无法终止。当另外一个线程获取循环链表的Key的时候,Get动作会一直执行,导致越来越多的线程死循环,最后服务器资源被耗尽。另外,插入一个新节点前,需要确定当前内部元素是否达到设定的阈值,如果达到阈值则需要进行扩容操作。链表中的元素是散列分布的,在多线程高并发环境下,扩容操作时可能会引发链表结构循环,引起服务器CPU消耗在短时间内急剧上升。
2.2 悲观锁的性能问题
HashMap数据结构存在线程安全问题,不考虑性能时通过对整个哈希表结构做锁定操作。锁定期间其他线程一直处于阻塞状态。很显然,不适合大规模高并发操作。高效的哈希函数能够在确保计算效率的前提下,使得散列地址相对均匀的分布,当前使用的哈希函数很难达到预期效果。数组初始化时要申请一个连续的固定长度内存空间,哈希函数很难保证生成的哈希值不发生冲突。
悲观锁实际上是将并发请求转变为串行来实现,对系统的响应时间和吞吐量有较大影响,并发控制锁也是阻止线程执行的悲观方法。当一个线程被挂起时就会加入到阻塞队列,在特定条件下通过Notify方法唤醒。共享资源不可用的时,该线程将让渡CPU切换为阻塞状态。等到共享资源可用时,唤醒线程进入Runnable状态等待CPU调度,线程挂起和恢复的执行过程中存在着很大的开销。
3 分段锁算法
3.1 分段锁的数据结构
如图1所示,分段锁实现的线程安全的HashMap数据结构,内部结构包括一个Segment数组和多个Hash Entry对象,通过锁分离的方法提供并发操作,解决线程安全问题。Segment数组把一个大的表切割为多个小的表来进行加锁,降低锁的范围的同时增加了并发度。每一个Segment元素存储的是HashEntry数组和链表。在插入和检索元素时,首先通过哈希算法定位到所在分段,然后使用特定算法对元素的哈希值进行再一次哈希计算,目的是为了减少哈希冲突,使元素能够相对均匀的分布在不同的分段上,从而提高整个数据结构的插入和检索效率。
对整个HashMap进行操作时,首先不加锁循环执行,循环所有的分段获得对应的值。如果连续两次所有分段的返回的值相等,则认为过程中没有发生其他线程修改的情况,返回获得的值。锁分离方法减少了请求同一锁的频率,有效地缩短了锁的持有时间,使得HashMap的并发性能有了质的提高。当循环次数超过预定义值时需要依次锁定所有分段,获取返回值后按順序解锁。加锁过程中强制锁定所有的分段,避免出现其他线程创建分段与插入等操作。
3.2 分段锁的并行度
分段锁保证了锁竞争只存在于同一分段内,不同Segment之间不存在锁竞争。与锁定整表的设计相比,分段锁在高并发环境下,有效的提升了程序的处理能力,但是由于不是对整个数据结构加锁,导致一些需要扫描全表的方法需要使用特殊的实现方式,如Clear方法就降低了对一致性的要求。除了第一个分段锁之外,剩余的分段锁采用的是延迟初始化的机制,在每次插入操作前需要检查Key对应的分段是否存在[11]。如果不存在就创建分段锁,当链表的长度太长时会经常发生哈希冲突,插入和删除链表的操作需要很长的时间。并发度是不产生锁竞争的最大线程数,实际上就是Segment数组长度,默认的并发度为16,同时支持用户自定义并发度。如果并发设置太小,会出现严重的锁争用问题。如果并发性设置得太大,最初位于同一段中的数据访问将扩展到不同的分段锁,命中率会下降引起检索效率下降。
4 CAS算法优化
4.1 CAS算法原子性原理
进行CAS操作时将,首先变量的期望值与当前值进行比较,如果变量的当前值等于预期值,则使用新值替换当前变量的值[12]。采用CAS算法实现并发环境下的无锁策略,检测到线程冲突时协调当前操作。使用没有锁定机制的Volatile原语,保证了线程之间数据的可见性,可以直接读取变量值。Volatile变量的读写与CAS实现线程之间的通信的可见性与有序性,不会阻塞线程,并且比同步锁的响应更好。采用CAS操作每次从内存中读取数据,确保对内存的读改写操作是原子执行。无锁是一种乐观的策略,假设在访问资源时没有冲突,线程不需要阻塞。相对于悲观锁策略,CAS算法使程序设计有明显的优势,无锁方式避免了锁竞争的性能开销,以及在线程间调度的性能开销,提供了更好的并发读写性能,也降低了对读一致性的要求。
CAS使用处理器提供的机器级原子指令,以原子方式对存储器执行读写操作,这是多处理器实现同步的关键。支持原子读写指令的计算机是一个顺序计算图灵机的异步等价机器,多处理器都支持对内存执行原子读写的指令。如果该值在同一时间被另一个线程更新,则写入失败,采用自旋的方式继续进行CAS操作。CPU提供的特殊指令能够自动更新共享数据,排除其他线程的干扰,CPU实现原子操作有以下两种方式。
1)通过总线锁保证原子性。总线锁是处理器提供的Lock#信号,能够阻止其他处理器的请求,确保当前处理器可以独占共享内存。例如多个处理器同时读取与修改共享变量,则必须确保CPU1在读取与写入共享变量时,CPU2无法读取共享变量。通过总线锁定CPU和存储器之间的通信,使得其他处理器在锁定期间,无法操纵该存储器地址的数据,总线锁定开销相对较大。
2)使用缓存锁保证原子性。如果在执行锁定前缀指令期间,要访问的存储区已锁定在处理器的内部高速缓存中,并且存储区完全包含在单个高速缓存行中,处理器将直接执行指令。由于在执行指令期间,始终锁定高速缓存行,其他处理器不能读取与写入指令要访问的存储区域,从而确保指令执行的原子性。缓存锁定将大大降低Lock前缀指令的执行开销,但是当多个处理器之间的竞争程度很高,或指令访问的内存地址未对齐时,总线仍然处于 锁定状态,禁止指令与先前和后续的读写指令重新排序。
4.2 CAS算法优化方法
CAS算法可以有效地解决原子操作问题,但CAS算法存在三个问题,包括ABA问题、长周期的时间开销问题,以及只能保证单个共享变量的原子操作。针对以上三个问题采取以下方法进行优化处理。
(1)增加版本戳避免ABA问题。将版本标记附加到变量的前面,并在每次更新变量时增加版本标记。CAS操作首先检查当前引用值是否等于预期值,并且当前版本标记是否等于预期值,如果全部相等,以原子方式将引用和版本标记的值设置为给定的更新值。Zookeeper中保持数据一致性也是用的这种方式,假设完成操作时不发生冲突。
(2)如果自旋CAS长时间不成功,将给CPU带来非常大的执行开销。如果支持处理器提供的暂停指令,那么效率将得到提高。Pause指令可以延迟管道执行指令,以便CPU不会消耗太多的执行资源。此外,还可以避免在退出循环时,由于存储器序列冲突而清空CPU流水线,提高CPU执行效率。
(3)当对共享变量执行操作时,使用循环CAS方法保证原子操作,但是当对多个共享变量进行操作时,循环CAS不能保证操作的原子性,可以将多个变量放在CAS操作的对象中,实现对多个共享变量的原子操作。
4.3 CAS算法优化实现
如图2所示,CAS算法优化代码实现。创建一个Pair类来保存对象的引用和版本标记。Pair对象是不可变的,所有属性都用Final修饰,并且该方法每次都返回一个新的不可变对象。Volatile类型引用用于指向当前的Pair对象。使用Volatile修改的变量强制将修改后的值立即写入主内存,主内存值的更新使缓存中的值无效。当Set方法设置的对象与当前Pair对象不同时,创建一个新的不可变的Pair对象。在更新方法中,只有期望对象的引用和版本号,与目标对象的引用和版本相同,将创建一个新Pair对象,然后使用新对象和原始对象执行CAS操作。实际上,CAS操作将当前Pair对象与新的Pair对象进行比较,而Pair对象封装了引用和版本标记。
5 无锁的数据结构与扩容方法
5.1 无锁实现的数据结构
如图3所示,链表和红黑树实现的数据结构。基于CAS算法实现并行的HashMap数据结构,内部采用数组、链表和红黑树实现线程安全操作[13]。HashMap的初始化只能由单线程完成,通过控制标识符确保初始化方法的线程安全,控制标识符不同的取值代表不同的含义。如果控制标识符的值小于0,表示其他線程正在进行初始化,当前线程放弃操作。如果获得了初始化权限,控制标识符的值置为–1,防止其他线程进入。
使用Node数组代替Segment存储数据,Node可以是链表或红黑树结构。如果插入的元素键具有相同的哈希值,则键位于Node节点数组中的同一单元格中。如果链表存储的数据超过8个,将链表转换为红黑树结构。即使所有Key的哈希值完全相同,红黑树中查找某个特定元素复杂度仍然是O(logn)。根据哈希值计算表中新插入点的位置索引,如果该位置为空则直接插入,否则判断如果位置是树节点,将新节点作为树节点插入,或将其插入到链表的末尾。
CAS算法能够确保Node操作的原子性,标识符的不同值来代表不同含义起到了控制的作用。采用Node降低锁的粒度,分段锁的粒度是Segment包含多个HashEntry,而CAS算法的锁的粒度就是首节点HashEntry,减低了数据结构实现的复杂度。遍历数据集很大的链表的是非常耗时,使用红黑树来优化链表结构,检索效率上存在一定的优势。
5.2 多线程的扩容方法
容量不足时需要对Table进行扩容操作,支持无锁状态下的多线程扩容,并发处理能够减少扩容的时间开销。扩容涉及数据从一个数组拷贝到另一个数组,并发操作可以在很大程度上提升执行效率,整个扩容操作分为两个部分。
首先,使用单线程构建一个容量是原来两倍的目标表Next Table。根据运算得到需要遍历的次数Index,然后获得Index位置的元素。如果该位置为空就在原Table中的该位置放入Forward节点,作为连接两个Table的节点类,包含一个用于指向下一张表的指针[14]。如果该位置是Node节点,并且是一个链表的头节点就构造一个反序链表,分别插入目标表Next Table的Index和Index + N的位置。
然后,采用多线程将源Table中的数据复制到目标Next Table中。如果被遍历的节点是Forward节点,当前线程继续向后遍历。处理一个节点并将相应的点的值设置为Forward,其他个线程检测到Forward节点就继续向后遍历。如果检测到要插入的节点不是空的或者Forward节点,则锁定该节点以确保线程安全[15]。尽管锁定该节点有性能开销,比起同步锁还是存在一定的性能优势,交叉执行完成数据复制,同时也保证了线程安全。
6 实验和结果分析
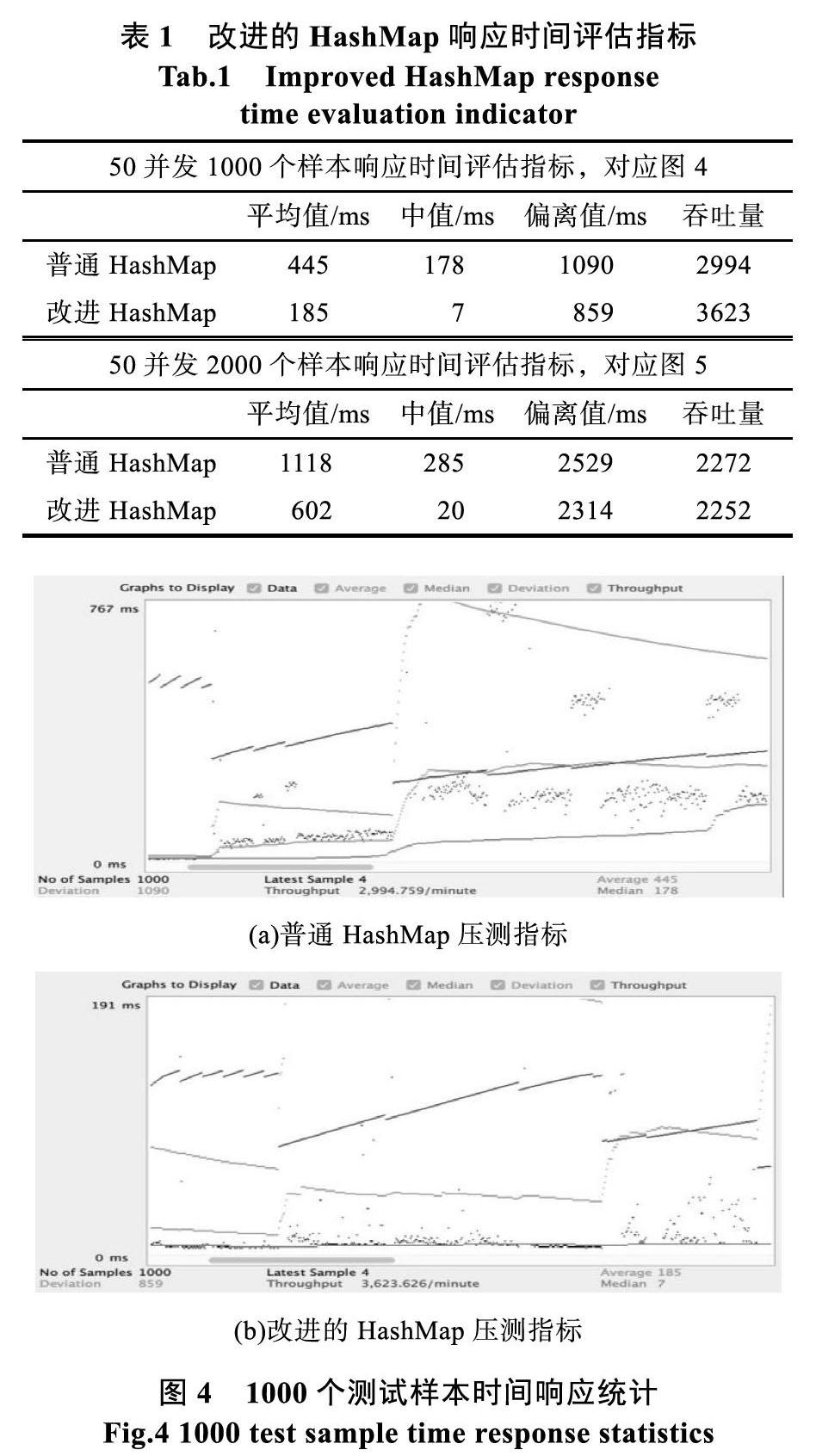
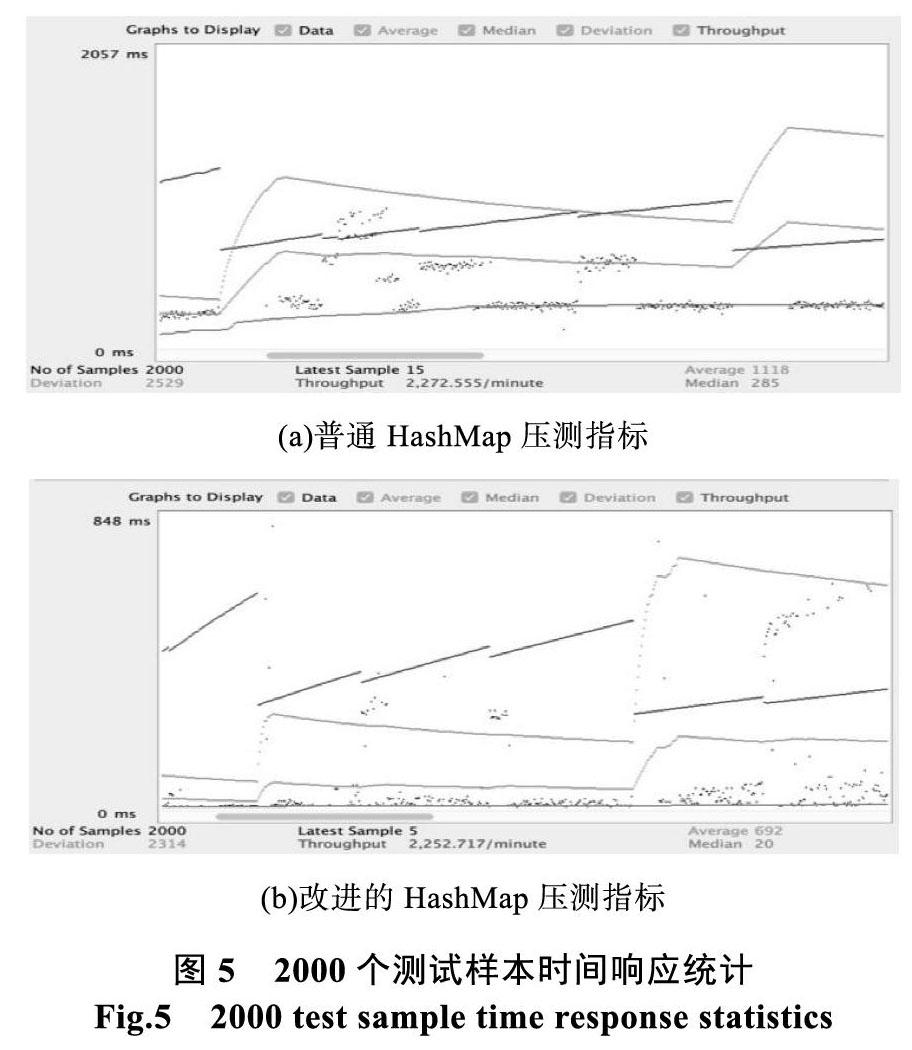
实验运行环境的CPU为8 Core、内存配置16GB的单台服务器,安装64位CentOS 7操作系统。使用并发测试工具模拟大规模并发操作,返回内存数据结构的响应时间。分别测试在两中情况下,单个线程进行10000次相同操作,向哈希映射数据结构中插入一个新键值对,再查询该Key对应的值,并发量设置为50。如表1所示,统计指标包括响应时间的平均值、中值、偏离值和吞吐量,吞吐量单位是每分钟。
如图4所示,1000个测试样本数据响应时间等指标统计,50并发量循环20次,得到1000个测试样本,普通HashMap数据结构的响应时间随并发量增加呈现阶梯状增长。基于CAS算法改进的HashMap数据结构的阶梯幅度明显小于普通的HashMap数据结构,在平均响应时间指标也存在明显的优势。
如图5所示,2000个测试样本数据响应时间等指标统计,50并发量循环40次,得到2000个测试样本呈现相同的规律,改进的HashMap数据结构仍然存在明显的优势。改进的HashMap数据结构主要是为高并发设计,通过数据的弱一致性带来性能上的大幅提升,降低了执行成本和拥有更高的并发性。
7 结语
本文提出了基于CAS算法实现线程安全的哈希映射数据结构,内部采用数组、链表和红黑树实现了高并发环境下读写效率。通过增加版本戳避免CAS算法中的ABA问题,CAS算法实现的无锁方式,避免了锁竞争的开销,使用红黑树来优化链表,确保数据集很大时时间复杂度是O(logn)。在无锁状态下的多线程扩容操作,减少了扩容的时间开销。通过大规模的并发测试,验证了该数据结构在性能上有稳定的提升。
参考文献
[1] Al-Wesabi O,Samsudin A. Fast hashing function based on multi-pipeline hash construction (MPHC)[J]. International Journal of Innovative Computing, Information and Control, 2012, 8(11): 7887-7907.
[2] Li Y T, Xiao D. Parallel Hash function construction based on chaotic maps with changeable parameters[J]. Neural Computing and Applications, 2011, 20(8): 1305-1312.
[3] Kishore N, Kapoor B. An efficient parallel algorithm for hash computation in security and forensics applications[C]//Pro?ceedings on IEEE International Advance Computing Conference, 2014: 873-877.
[4] 徐劲松, 张民选. Merkle-Damgrd Hash结构并行扩展算法[J]. 国防科技大学学报, 2017, 39(06): 59-63.
[5] 张滨, 乐嘉锦. 基于列存储的MapReduce分布式Hash连接算法[J]. 计算機科学, 2018, 45(S1): 471-475+505.
[6] 李涛, 董前琨, 张帅. 基于线程池的GPU任务并行计算模式研究[J]. 计算机学报, 2018, 41(10): 2175-2192.
[7] 吴泉源, 彭灿. 适用于海量数据应用的多维Hash表结构[J]. 清华大学学报(自然科学版), 2017, 57(06): 586-590.
[8] 陈之彦, 李晓杰. 基于Hash结构词典的双向最大匹配分词法[J]. 计算机科学, 2015, 42(S2): 49-54.
[9] 王兴, 鲍志伟. 适用于高速检索的完美Hash函数[J]. 计算机系统应用, 2016, 25(02): 250-256.
[10] 刘志强, 宋君强. 基于线程的MPI通信加速器技术研究[J]. 计算机学报, 2011, 34(01): 154-164.
[11] 吴恩慈. 基于JAVA大规模应用中GC算法和调优技术研究[J]. 电子技术与软件工程, 2016(04): 249.
[12] 钱振江, 卢亮. 微内核架构多线程机制的形式化设计研究[J]. 计算机科学, 2013, 40(04): 136-141+163.
[13] 张良, 刘敬浩. 命名数据网络中基于Hash映射的命名检索. 计算机工程, 2014, 40(4): 108-111.
[14] 母红芬, 李征. HashMap优化及其在列存储数据库查询中的应用[J]. 计算机科学与探索, 2016, 10(09): 1250-1261.
[15] 贾刚勇, 万健, 李曦. 一种结合页分配和组调度的内存功耗优化方法[J]. 软件学报, 2014, 25(07): 1403-1415.
