
两种监督机器学习算法在Fermi BCU分类评估中的应用*
2019-10-10 03:01朱柯睿周瑞鑫康世举毛慰明
云南师范大学学报(自然科学版) 2019年5期
朱柯睿, 周瑞鑫, 康世举, 毛慰明
(1.云南师范大学 物理与电子信息学院,云南 昆明650092;2.六盘水师范学院 电气工程学院,贵州 六盘水 553004)

费米大面积望远镜(Fermi LAT)于2008年发射后长期用于高能伽马射线波段的观测.根据2008年到2016年在50 MeV到1 TeV能段的观测数据,Fermi团队最近发布Fermi-LAT第四期源目录(4FGL),有5 065个伽马射线源,其中3 131个为耀变体[4],包括1 116个蝎虎天体、686个平谱射电类星体和1 329个未知类型的耀变体.4FGL同时给出了很多直接观测数据,例如七个不同波段的流量增加幂律和对数抛物线型谱参数等.与3FGL[5]中被证认的1 420个耀变体中有402个BCUs相比,4FGL样本量大大增加了,同时未确定样本也更多了.对BCU的类型证认是一项有意义的工作,但是由于天文观测的局限性,从观测上直接证认存在很多困难.
近年来,天文学数据急剧膨胀,复杂性快速上升,常规的统计方法在数据挖掘和分析领域存在困难.机器学习作为一种新的数据分析处理手段,主要分为监督机器学习(SML)和非监督机器学习(USML),在分类、回归、模型构建领域有较好运用[6].监督机器学习中,有逻辑回归、贝叶斯网络、决策树、随机森林、支持向量机、人工神经网络和高斯有限混合模型等大量算法可供选择.在天文学领域中,SML分类算法被广泛应用,例如Doert等人将随机森林和神经网络用于在2FGL无相关源中寻找AGN候选体[7],Saz Parkinson P M等人将随机森林和逻辑回归用于3FGL未证认样本的分类[8]等.本文选用监督机器学习领域的高斯混合有限模型(Mclust)和逻辑回归(LR)算法,对4FGL中1 329个Fermi BCUs样本的分类进行评估.
1 监督机器学习分类方法
在监督机器学习领域,数据集包含对象及其特征参量和目标参量.特征参量一般是指可测量且可用来衡量对象特性的参量,而目标参量主要指类型 (在分类算法中,也被称为标签)[6].本文中,对象为4FGL中的耀变体源及其参量;而特征参量为源的各种观测量,如谱特征、流量等;目标参量为其分类,如FSRQ和BL Lac.为了实现分类的目标,数据集中的已知标签的样本将进一步划分为训练集和测试集.训练集将被用来训练算法模型以确定分类评判标准,而测试集将被用来测试算法模型的准确率和稳定性.将未知样本的特征参量代入模型中,即可获得其分类.
为了在算法上实现分类,将在R语言的环境下工作.高斯有限混合模型(Mclust)是R语言提供的一种基于高斯混合模型的聚类算法的程序库,常用于密度估计或判别分析.而逻辑回归(LR)又称logistic回归分析,是使用广义的线性回归模型来进行二元变量分类的一种算法,在数据挖掘、分类判别领域有较好的运用.
2 样本选取
根据费米第四期源目录,样本选取了1 116个蝎虎天体(标签为“bll”)、686个平谱射电类星体(标签为“fsrq”)和1 329个未确定类别耀变体.在4FGL目录给出的观测参量中,除去坐标、误差、历史数据、字符串、缺失数据等无效数据外,共有28个参量.为了评估各个参量在BL Lac和FSRQ两类样本中的分布差异,采用双样本检验中的K-S检验(Kolmogorov-Smirnov test,用以评价两类样本的分布是否存在显著性差异的手段,方法等更多细节可见文献[9]),根据K-S检验结果,按照D≥0.5参数选择标准,选择了8个参数(见表1)作为数据集的特征参量选用.表1中,第一列是测试参数名称;第二列是K-S 检验中的统计值D;第三列是各参数在K-S检验中在两类样本遵从同一分布的概率p.
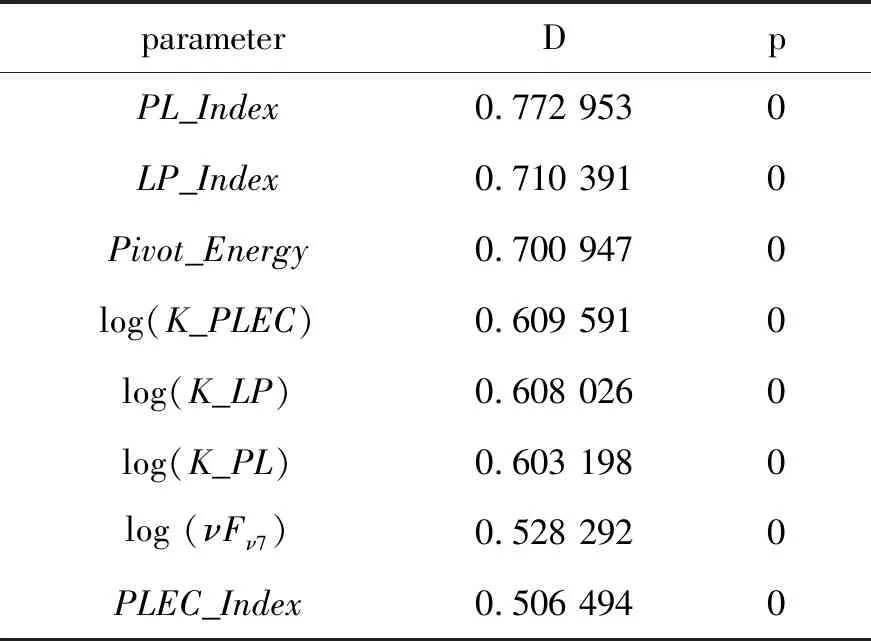
表1 被选用参数K-S检验的结果
3 结 果
在训练集和测试集划分时,为了保证结果的唯一性和可重复性,在数据集随机分类时给定了确定的随机因子(123),以保证样本划分的稳定性,进而保证分类结果的稳定性.1 116个BL Lacs和686个FSRQs将按7∶3的比例随机地(随机因子为123)分为训练集和测试集,1 329个BCU将作为预测集,选定的8个参数将作为特征参量.实现高斯混合有限模型调用“mclust”函数库,模型构建类型为“mclustDA”(算法更多细节见文献[10]).“glm”是R提供关于线性回归模型的函数库,将回归函数模式为“logit”即可实现逻辑回归分类,本文选用的分类阈值为0.5(算法更多细节见文献[11]).根据输入的数据集,分类器算法分别给出了1 329个Fermi BCU样本的分类 (篇幅受限,论文仅给出部分源可能的分类结果,如有需要,请与作者联系),部分分类结果见表2.表2中,第一列是4FGL的源名称;第二列是源的别称;第三列是源在4FGL中的分类;第四、五列分别是两种分类算法给出的分类结果.

表2 部分BCU的分类结果
图1为测试结果的误差分布图,其中左图为Mclust测试结果,右图为LR测试结果(纵坐标为真值,横坐标为预测值,真值与预测值不同即为误判情况).根据测试结果,Mlcust算法的总体准确率达到85.95%,对于BL Lac和FSRQ的准确率分别为88.63%和81.31%;Mclust给出BL Lac型候选体810个,FSRQ型候选体519个(见表3);而LR分类器的总体准确率达到89.46%,对于BL Lac和FSRQ的准确率分别为92.31%和84.72%;LR共给出BL Lac型候选体819个,FSRQ候选体510个,详细结果列在表3中.表3中,第一列是分类算法名称;第二、三列分别是给出BL Lac和FSRQ候选体个数;第四、五、六列分别是针对BL Lac、FSRQ和整体样本的准确率.

图1 误差分布

表3 分类结果及算法模型准确率
为了更直观地看出各个参数在不同耀变体类型上分布的差异,通过“plot mclustDA”函数给出了已知的两类样本在部分不同参数空间中的散点图(图2).图2左图为训练集散点图,右图为测试集散点图,其中蓝色点为BL Lac型样本,红色点为FSRQ型样本.从散点图中可以看出,两类耀变体的相关参数分布不同,在耀变体序列的演化中具有明显差异,即在分类器中,蝎虎天体和平谱射电类星体是可以区分的.

图2 两类样本在部分不同参数空间中的散点图
从结果可见,LR算法的准确率略高于Mclust算法,且两种算法给出的不同类型候选体的数目并没有较大差异.结合两种算法的结果,有731个样本被两种分类器同时认为属于BL Lac类型,而有432个被同时分类为FSRQ类型(详细分类结果如有需要,可以联系作者),在一定程度上,可以认为此结果具有较高的置信度.
4 讨 论
从文中可以看出,BL Lac和FSRQ两类耀变体在很多参数空间的分布都有较大的区别.例如,无论是幂律模型和对数抛物线模型还是指数截断幂律模型,BL Lac显示出了相对FSRQ较小的谱指数,这也意味着BL Lac的谱显得较硬.此外,相对于FSRQs,BL Lacs具有更小的流量、更弱的光变以及更低的峰值频率[12].这也间接说明了BL Lac和FSRQ辐射产生的不同的物理机制[13-16].
本文所用的数据仅为4FGL提供的源及其参量,并没有加入外部数据.本文得到的结果仅为将数据集代入程序所得的结果.训练集和测试集划分不同(不同的比例,不同的随机因子),特征参量的选取不同可能会导致结果的不同.因此,本文的结果仅针对本文中提出的数据和参量.
此外,对于参数的选择,只选用了一种简单的方式给出选择标准,并没有对参数个数对算法准确率的影响进行深入的探讨.而监督机器学习领域有很多算法,本文只使用了其中的高斯混合有限模型和逻辑回归算法,少数几种算法的分类结果可能存在一定的局限性,如果将多种算法(例如神经网络,随机森林,支持向量机等)同时运用,然后对各种分类器的分类结果进行综合考虑,可能会得到具有更高置信度的结果.
猜你喜欢
北京航空航天大学学报(2022年5期)2022-06-06
健康之家(2021年19期)2021-05-23
医学食疗与健康(2021年27期)2021-05-13
农业科技与信息(2021年2期)2021-03-27
空间科学学报(2020年3期)2020-07-24
现代职业教育·高职高专(2020年10期)2020-01-05
物理学报(2019年24期)2019-12-24
成都信息工程大学学报(2019年4期)2019-11-04
中国交通信息化(2018年5期)2018-08-21
计算机系统应用(2017年10期)2017-10-20
