
无穷方差序列均值变点的Ratio检验
2019-10-24 01:26皮林王丹
纯粹数学与应用数学 2019年3期
皮林,王丹
(西北大学数学学院,陕西 西安 710127)
1 引言
统计学中,变点问题一直是一个热点课题,一般认为变点问题的研究始于Page[1]在 Biometrika上发表的一篇关于连续抽样检验的文章.文献[2]指出 “变点τ0是指在一个序列或过程中,在某个未知时刻τ0,序列或过程的某个统计特性发生了变化”.变点问题的统计推断就是依据具体的背景,对这个未知的时刻τ0做出估计,并对估计量的性质进行统计分析.
在现实中,变点问题不但在早期的工业自动控制上有大量应用,而且,随着近年来对变点问题的不断深入研究,变点问题的实际应用现在已经拓展到了许多其他领域.如在经济学上,文献[3]基于Schwarz信息准则的统计变点检测,对影响国际天然铀价格的因素进行了分析;文献[4]基于Copula模型进行变点检测,分析了投资者的情绪传染;在网络安全上,基于变点检测,文献[5]实现了对网络移动目标防御的安全成本和安全收益的实时检测和动态度量;在航空技术上,文献[6]通过顺序双滑窗的航空器轨迹变点检测,实现了对航空器飞行阶段的有效划分;在金融上,文献[7]通过对c-D-Copula模型进行变点检测,对美国次贷危机金融传染的存在性和变化过程进行了研究;文献[8]通过对R藤copula进行变点检验,分析了系统性风险对金砖四国影响的结构性变化;在气候监测上,文献[9]通过建立似然比变点模型和回归变点模型,对当年最大风速序列的变点进行检验和估计.
变点不仅具有广泛的实际应用,而且在理论上也有较大的研究价值,针对变点问题,在理论研究方面涉及了统计学的众多方向,比如结合了质量控制理论,估计理论,假设检验理论,Bayes理论等,所以一直是统计学中的一个热门课题,取得了丰硕的研究成果,如文献[10]研究了正态线性回归模型和独立的Student-t线形回归模型,采用SIC准则定位模型的变点位置;文献[11]利用AIC(Akaike information criterion)信息准则讨论了Gauss分布变点的检测;文献[12]研究了随机误差项为独立同分布序列的变点问题;文献[13]采用CUSUM方法研究独立时间序列的变点估计问题;文献[14]对独立随机序列的变点问题进行了研究.
然而,现有文献对变点的研究主要集中于方差有限及随机误差项为独立同分布序列的统计模型,对无穷方差重尾序列均值变点的研究较少.本文研究的重尾序列{Yt},其特征指数κ满足κ∈(1,2),此时{Yt}序列均值存在,方差不存在,事实上,许多金融资产收益率的分布都具有重尾特性,由于受突发事件的影响,而在某个未知的时刻序列发生突变,从而造成金融资产可能的损失,所以,针对重尾序列变点的检验就显得尤为重要.基于此,本文提出无穷方差序列均值变点的Ratio检验,通过残量累积平方和的比率构造检验统计量,并在原假设下得到了检验统计量的极限分布,在备择假设下证明了检验的相合性,然后通过Monte Carlo模拟说明检验方法的有效性.
2 模型与假设
考虑如下模型:

其中u(t)是非随机函数,{Yt}是满足如下假设的重尾序列.
假设 2.1随机变量序列{Yt}是严平稳序列,尾指数κ∈(1,2)且EYt=0.
引理 2.1若假设2.1成立,则

其中an=inf{x:p(|Yt|>x)6n−1},{U(τ)}是 [0,1]上的κ-稳定 Lévy 过程,符号表示依分布收敛.
注 2.1该结果是文献[15-16]得到的,Lévy过程U(τ)的具体定义在下文中并不需要,但an可表示为
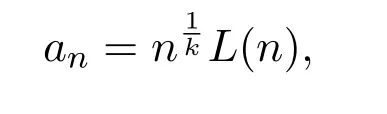
其中L是一个缓慢变化函数.
考虑如下假设检验问题:

其中u1,u2是未知常数且u12,τ0∈(0,1),n是样本容量,[·]表示取整函数.在原假设下,重尾序列{Xt}没有均值变点,在备择假设下,重尾序列{Xt}在[nτ0]处有一个均值变点.
这里,我们为大家介绍四种适合用来处理人像照片的色彩效果——当然了,用来处理任意一种类型的照片也没有问题。这些色彩风格最棒的一点就是它们虽然最适合于人像,但并不局限于此。
3 主要结果
令{U(t)}是 [0,1]上的k-稳定 Lévy过程,并定义如下两个过程
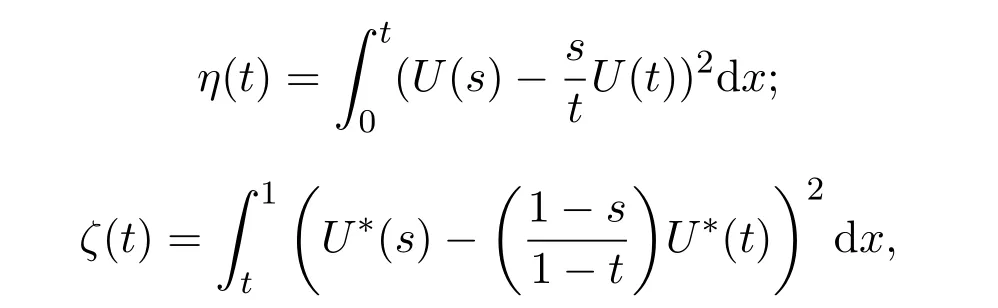
其中U∗(t)=U(1)−U(t).
基于CUSUM函数,构造如下检验统计量:
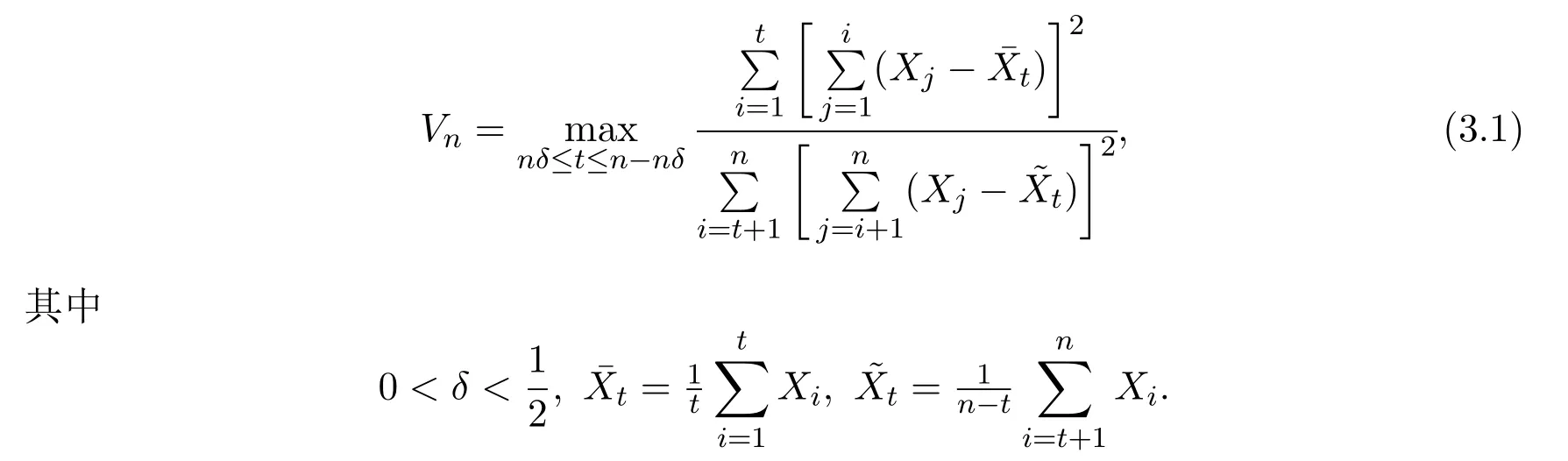
提出如下定理:
定理 3.1若假设2.1成立,则在原假设H0下有
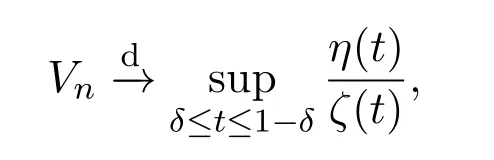
证明不失一般性,假设u1=0,则在原假设H0下,Xt=Yt,其中定义同前文一致,首先考虑检验统计量Vn的分子,有

4 数值模拟
4.1 检验的临界值
用数值模拟研究重尾序列均值变点Ratio检验,其中显著性水平α=0.05,0.10,样本容量n=200,500,1000.重尾序列由Nolan教授程序生成,具体可见Nolan教授个人主页.针对不同的样本容量n,通过把重尾数据带入统计量Vn,分别重复进行2000次得到2000个样本,这些2000个样本的经验分位数可以近似为统计量Vn在原假设下的临界值V,若Vn>V,则拒绝原假设.
4.2 检验的经验水平和经验势函数

假设检验问题:

其中u1=0,u2=0,1,1.5,2,若u2=0,则序列不存在变点,若u2=1,1.5,2,则序列存在结构变点.令τ0=0.48,误差序列{Yt}为

独立同分布序列{Zt}是重尾数据,κ=1.16,1.97,序列{Zt}满足假设 2.1,其中取ϕ1=1,ϕ2=−0.5,在随机变量序列{Yt}为二阶自回归序列AR(2)和独立同分布过程下分别进行模拟.
对样本容量为n=200,500,1000的数据分别重复实验5000次,检验的经验水平和经验势函数值用实验5000次中拒绝原假设的频率来近似.模拟的经验水平和经验势函数值分别见表1、表2、表3和表4.经验水平值是在原假设成立下,拒绝原假设的概率,经验势函数值是在备择假设成立下,拒绝原假设的概率.

表1 H0下的经验水平值,{Yt}=AR(2)

表2 H0下的经验水平值,{Yt}=i.i.d

表3 H1下的势函数值,{Yt}=AR(2)

表4 H1下的势函数值,{Yt}=i.i.d
通过模拟可知的主要结论:
(1)从表1-表 2可以看出,在没有变点的情况下,经验水平值是接近于显著性水平α的.且样本容量n越大,检验水平值越接近于显著性水平α,说明水平失真越小,检验有效.而且,独立同分布序列的经验水平值大于AR(2)序列.
(2)从表3-表4了解到,对于一个固定的数n,随着u2的不断增大,势函数值也相应地不断增大,对于一个固定的u2,势函数值随着样本容量n的增大而增大,随着样本容量n和u2的增加,势函数值逼近1.
(3)结合表1-表4,κ=1.97的结果优于κ=1.16,这是因为特征指数k刻画的是重尾序列的特性:指数k越小,取到“奇异点”的概率越大.
5 结论
本文通过残量累计平方和的比率构造统计量检验无穷方差序列的均值变点.基于CUSUM函数,通过Ratio检验方法,利用残量累计平方和的比率构造出检验统计量,在原假设条件成立时,残量累计平方和比率检验统计量的极限分布是一个Lévy过程函数.均值变点检验方法中的统计量大多为差值形式,数值模拟的结果表明,对于无穷方差序列的均值变点检验问题,基于CUSUM函数,通过残量累计平方和的比率构造出统计量的检验方法势函数表现优良,说明该方法有效.
猜你喜欢
数学理论与应用(2022年1期)2022-04-15
数学物理学报(2021年4期)2021-08-30
宜春学院学报(2020年9期)2020-12-03
湖北第二师范学院学报(2020年8期)2020-10-13
筑路机械与施工机械化(2020年7期)2020-08-20
河南科学(2020年4期)2020-06-03
安徽师范大学学报(自然科学版)(2020年1期)2020-03-28
图学学报(2019年1期)2019-03-02
价值工程(2017年19期)2017-07-12
浙江大学学报(理学版)(2017年3期)2017-05-18
