
基于文学作品的人物关系问答系统设计与实现
2019-11-14 08:17李思彤冀美琪夏欣雨殷复莲
软件 2019年9期
李思彤 冀美琪 夏欣雨 殷复莲


摘 要: 针对文学作品人物关系复杂,无法进行快速准确查询的问题,本文提出基于文学作品的人物关系问答系统设计方案并进行实例验证。本文采用文本表示、实体识别等自然语言处理技术,研究文学作品中人物关系的自动抽取方法,实现了根据用户输入的人物名称快速返回其人物关系的功能。典型案例验证了系统的有效性。
关键词: 人物關系抽取;自动问答系统;文学作品;人物关系三元组
中图分类号: TP391 文献标识码: A DOI:10.3969/j.issn.1003-6970.2019.09.032
本文著录格式:李思彤,冀美琪,夏欣雨,等. 基于文学作品的人物关系问答系统设计与实现[J]. 软件,2019,40(9):139-143
Design and Implementation of Question and Answer System for Personal Relations Based on Literary Works
LI Si-tong, JI Mei-qi, XIA Xin-yu, YIN Fu-lian
(Communication University of China, College of Information and Communication Engineering, Beijing 100024, China)
【Abstract】: Aiming at the problem that the relationship between characters in literary works is complex and can not be queried quickly and accurately, this paper proposes a design scheme of a question-and-answer system based on the relationship between characters in literary works and verifies it with examples. In this paper, we use natural language processing technology such as text representation and entity recognition to study the automatic extraction method of the relationship between characters in literary works, and realize the function of returning the relationship between characters quickly according to the user's input names. Typical cases verify the effectiveness of the system.
【Key words】: Character relation extraction; Automatic question and answer system; Literature works; Character relation triple
0 引言
近年来网络文学蓬勃发展,文学作品的数量和题材层出不穷。一部文学作品的字数通常是超过百万的,这就使得用户仅仅通过自己阅读是很难准确地捕捉到作品中具体的人物关系。如果使用传统的搜索引擎对文学作品中的人物关系进行查询,得到的结果往往都是相对应的大量文字片段的网页链接,无法得到简洁准确的答案[1]。由此,能够弥补上述缺陷的自动问答系统逐渐受到广泛关注,它不仅允许用户以自然语言的方式进行提问,还能够实现针对用户提问返回相应简洁准确答案句的功 能[2],在一定程度上提高了用户的查询效率。
自动问答系统作为人工智能的一个分支,已有了漫长的发展历史。20世纪60年代发展的问答系统,允许用户以自然语言的方式查询数据库中存储的信息。该时期最成功受到人们关注的两个问答系统是BASEBALL[3]和LUNAR[4]。到了20世纪90年代,该时期的问答系统已经可以弥补传统搜索引擎针对用户提问返回一系列相关网页链接的缺陷,最为著名的问答系统是Start系统,该系统根据用户所查询的信息是否存在于已有数据库中设定了两种处理模式,即当用户查询的内容已经存在于知识库中的情况下,系统可以直接将对应的答案返回给用户;如果知识库中没有存储对应的信息,则通过搜索引擎检索并处理后反馈给用户[5]。近年来,随着神经网络技术、深度学习技术等的发展进步,自动问答系统进入了以知识和知识自动化为中心的新阶段。21世纪初期诞生的Watson[6]问答系统,由美国IBM公司研发,通过存储有关影视、新闻等多个领域的海量资料,实现在较短时间内针对用户提问返回相应答案,并由此在知识竞赛中打败人脑一举成名,现已在多个领域广泛使用。
与国际上自动问答系统的发展相比较,我国对其的研究起步较晚。近年来随着科学技术的飞速发展,我国各大高校和研究所也开始对其展开了深入的研究,如复旦大学[7]和中科院都参加了QA Track的竞赛、上海交通大学开发的智能答疑系统[8]以及中科院计算所研究的知识问答系统[9]等。2005年百度公司推出百度知道,这是一个交互式的问答系统,具体实现时主要是将用户查询的问题与数据库中已存在的问题进行比较,若相同则立即返回答案,若不同则根据相似度计算返回与之相似的若干问题及答案供用户参考[10]。整体来看,中文的语法以及语义复杂性等多因素给研究带来了不少挑战,因此针对中文的语句相似度研究、文本理解等知识自动问答系统逐渐成为研究的热点,且有很大的发展空间。
本文提出基于文学作品的人物关系问答系统研究方案,基于共现法进行人物对及亲密度分析,定义并提取人物关系对规则,实现用户以自然语言方式输入,系统实现人物关系自动问答的功能。
1 基于文学作品的人物关系问答系统研究方案
本文提出的基于文学作品的人物关系问答系统研究方案图如图1所示。主要包括数据采集如网络文学小说的采集、近义词词条及反义词词条的收集,数据预处理如对文本数据进行去除停用词等操作,使用文本表示方法将文本数据表示成计算机能够识别的向量模式,再通过实体识别、关键词提取等自然语言处理技术对文学作品的内容进行分析处理,实现当用户针对相关文本的人物关系进行提问时,能够自动对问题答案进行检索,进而将整理好的答案返回给用户,以满足用户快速搜索的需求。
在实现问答系统的人物关系查询功能时,进行了人物关系对及亲密度的提取,将提取到的人物对及人物关系存储成人物关系三元组和对应的答案句,通过定义简单和复杂两种查询答案句的模式,实现了基于文学作品的人物关系问答。
2 人物关系对及亲密度的提取研究
本文在进行人物关系对及亲密度的提取研究中,使用的研究方法流程图如2所示。针对一部文学作品,首先进行基于共现法的人物对及亲密度的提取,然后使用自定义规则进行人物关系的抽取,接着根据提取好的人物关系三元组定义答案句模式,从而实现当用户针对文学作品中的相关人物进行提问时,系统能够返回给用户人物关系答案句的功能。
2.1基于共現法的人物对及亲密度提取
“共现”是指文献中特征项描述的信息共同出现的现象[11]。常见的共现类型包括文献耦合、共词、共链等多种形式,本文主要使用的是于1986年被首次提出的“共词”分析方法。“共词”表示多个词汇在同一篇文献中同时出现。共词分析的原理是通过文献集中某几个词汇共同出现的情况,来反映这些词之间的关联强度,从而确定它们所代表的学科或研究领域的热点及各主题之间的关系[12]。一般认为两个词汇在一篇文献中同时出现的次数越多,那么这两个词汇所代表的主题之间的关系越密切。将共现法应用到分析小说中各个角色之间的人物关系时,则可以认为在一个章节或一篇文章中的同一段共同出现的两个人物之间,具有某种关联。本文设计与实现针对文学作品的人物关系进行自动问答查询功能,因此选用共现法进行人物对及亲密度的提取。
本文具体使用python工具实现人物对及亲密度的提取,主要设计思路为建立姓名字典和亲密度字典。进行人物对及亲密度的提取是分章节进行的,以便为后续的人物关系抽取奠定基础。在每一章节中,首先借助jieba工具对文本数据进行分词和词性标注,接下来使用实体识别技术识别出该章节文本中所有的人物名字,将它们存储在姓名字典中。然后进行每一段落中两个共同出现的人物名字的统计,同时记录人物对共同出现的次数,将次数记录在对应的亲密度字典中。接下来将每一章节得到的人物对和亲密度进行汇总整理,从而得到整部文学作品中人物对和亲密度的数据。如果存在同一人物有多个名字的情况,则采取建立列表的方式,将该人物所有的名字都存储在一个列表中,而该列表最终的值选定为该人物的正式名字,由此实现对包含该人物的人物对合并及对应的亲密度加和,通过上述操作最终实现基于共现法的人物对及亲密度提取。
2.2人物关系对的定义及提取规则
人物关系对,顾名思义,即对两个人物名称及他们之间关系的统称。其中,关于人物对的提取已在上一小节中阐述了具体实现方法,接下来需要说明的就是如何进行人物关系的抽取。人物关系抽取可以看作是实体关系抽取的一个重要分支,主要是将抽取中的命名实体限定为人名。实体关系的存储形式一般为关系三元组,类比到人物关系抽取中,则可以定义人物关系对的存储形式为人物关系三元组
本文是设计实现针对文学作品中人物关系的自动问答,因此人物关系对选择通过人物关系三元组进行存储,其中实体1和实体2代表文学作品中的两个不同人物名称,关系词则是对两个人物之间关系的具体描述词。
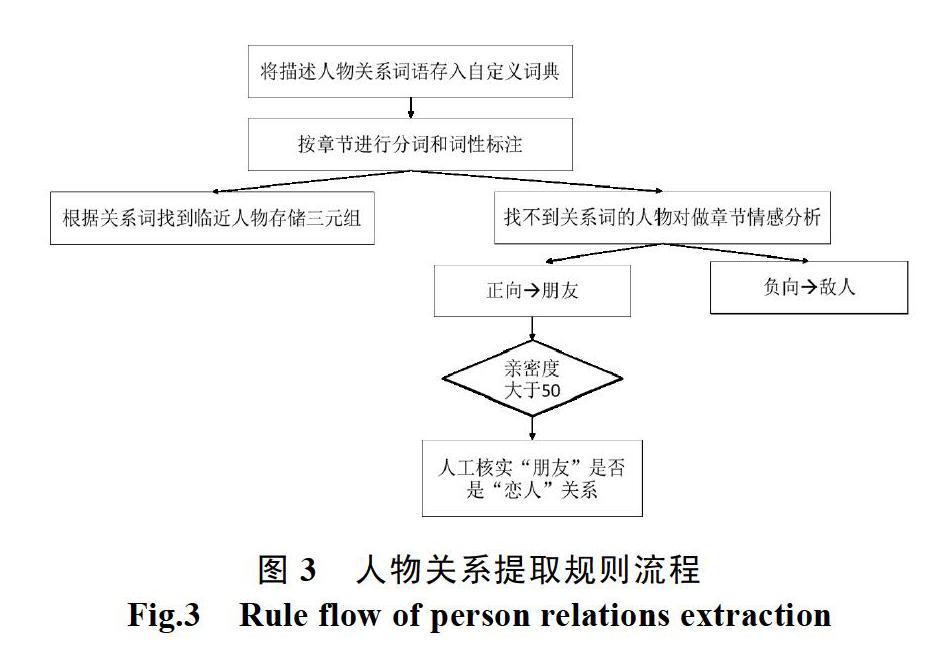
本文定义的人物关系提取规则流程如图3所示。
首先需要对描述人物关系的词语进行收集,将文学作品中经常出现的如“母亲”“父亲”“兄长”“叔父”等词语存入用户自定义词典中,单独标注一种词性。然后对需要分析的文本数据进行分词和词性标注,识别能够表示人物关系的词语,在每一个描述人物关系词语的前后找到距离最近的两个人物名称,将这两个人物名称以及描述关系的词语存成一个人物关系三元组。
按照上述做法提取出来的人物关系三元组与直接利用共现法提取的人物对相比较,在大多情况下数量较少,也就是说极有可能存在没有提取到确切关系词的人物对,针对这种情况,本文选取分析该章情感倾向的方法实现对人物关系提取规则的补充完善。如果该章计算得到的情感倾向为正向,则将人物对关系定义为“朋友”;如果该章计算得到的情感倾向为负向,则将人物对关系定义为“敌人”。
需要说明的是,这里存在有一个特殊情况:如果存在一个人物对,他们的关系实际上是恋人关系,具体体现为两人之间的亲密度极高且章节情感倾向为正向,但是在文章中两人的互动都是直接使用名字,此时无法提取到能够描述两人确切关系的词语,使用上述定义的规则就会将两人的关系错误地归结为“朋友”。对于这种现象,本文采用结合人物对亲密度数值的方法,规定了一个亲密度阈值等于50(一般文学作品的章节数目都超过50章),当亲密度大于50时,可以认为人物对之间有很亲密的关系。对于亲密度大于50且关系被定义为“朋友”的人物对,人工检查此关系是否需要修改为“恋人”关系。
2.3答案句模式设定
本文设计构建的人物关系查询模块,旨在返回给用户简洁准确的答案句。由此,根据已有的人物关系三元组,规定一种答案句子的模式[13],将三元组中的数据转为答案句进行存储,当用户进行提问时,可以根据识别出来的人物名称直接与答案句内包含的人物名称进行匹配,匹配成功后直接返回完整的答案句,由此为该模块的问答功能提供便利,也在一定程度上提高了问答系统的处理效率。由于人物关系三元组
根据存有的人物关系三元组及对应的答案句,本文设计实现的基于文学作品的人物关系查询,拟通过简单和复杂两种处理方式进行体现。简单的查询处理模式,即用户所查询的人物关系对存在于已有的数据库中,系统就可以直接返回给用户相应的答案句,可以实现对用户提问简洁高效的回答。复杂查询处理模式采用基于中间人物的方法,即用户所查询的人物关系对没有存在于已有的数据库中,这时系统无法直接提取到对应的答案句,需要通过寻找中间人物进行答案句组合,继而返回给用户组合答案句。当存在多个中间人物符合条件时,通过引入亲密度数值这一指标,选择亲密度数值最大的人物对进行最终的关系说明。
3 典型案例分析
本文选择网络小说《香蜜沉沉烬如霜》作为典型案例进行分析。在问答系统的人物关系查询模块中,首先利用共現法统计了每一章节中共同出现的人物对以及他们之间的亲密度,然后将整部文学作品的所有章节人物对进行合并整理,对具有不同人物名称的同一人物进行自定义规则的特殊处理,由此得到了小说中包含的全部人物对及他们的亲密度数值。
以《香蜜沉沉烬如霜》中的男主人公旭凤为例,他一个人就拥有很多个不同的名字,比如女主人公锦觅对他特有的称呼“凤凰”、天帝天后对他的称呼“旭凤”、月下仙人对他特有的称呼“凤娃”、其他天兵天将或者仙侍对他的尊称“二殿下”、“火神”,这么多人物名称其实只代表“旭凤”一个人,那么包含这些不同人物名称的人物对也需要进行相应的识别和合并,表1为旭凤的所有名字与锦觅共同出现的次数统计。
由表1中四组数据可以得到,我们最终使用的旭凤和锦觅的亲密度,应该是四组数据中的亲密度加和。按照此方法对所有的人物对及亲密度进行整理,从而得到准确的人物对及其亲密度数值。
接下来利用人物关系抽取的自定义规则提取了作品中的人物关系对,对于能够直接提取到人物关系的人物对,将人物关系和两个人物直接进行人物关系三元组的存储;对于没有提取到确切人物关系的人物对,则对该章进行基于情感词典的情感倾向分析[14],根据得到的“正向”或“负向”的情感,规定人物关系为“朋友”或“敌人”。最终将所有的人物关系三元组,按照特定模式得到的答案句以及相应的亲密度均存储于数据库中,从而实现针对人物关系的自动问答。最终设计了可视化页面对该问答系统的人物关系查询功能进行展示。在问答系统的人物关系查询模块页面中,用户只需要在输入框内输入想要查询人物关系的两个人物名字,点击查询按钮,就能在输入框下方得到相应的答案句。
图4和图5即为使用该问答系统进行人物关系查询的具体示例。
图4即为简单查询功能展示,当用户输入想要查询人物关系的两个名字为“旭凤,锦觅”时,系统根据数据库中已有的数据进行匹配,通过点击查询按钮实现返回答案句“旭凤是锦觅的恋人,锦觅是旭凤的恋人。”
图5即为通过中间人物实现复杂查询功能的展示,当用户输入想要查询人物关系的两个名字为“旭凤,先花神”时,系统在数据库中没有找到相匹配的数据,所以选择查找中间人物的方式进行答案句组合,通过比较最终选取“锦觅”作为两者之间的中间人物进行关系说明,最终点击查询按钮实现返回组合答案句“先花神是锦觅的母亲,旭凤是锦觅的恋人。”
4 结论
本文立足于自然语言处理技术,设计与实现了基于文学作品的人物关系查询自动问答系统,使用了共现法进行文学作品中人物对及亲密度的提取,使用自定义规则进行了人物关系抽取,并通过存储人物关系三元组,设定适当的答案句模式,最终实现了当用户针对文学作品中人物关系进行查询时,该系统能够通过文本分析等相关技术,快速返回给用户简洁的答案句。
参考文献
[1] Wei Z, Xuan Z, Junjie C. Design and implementation of influenza Question Answering System based on multi- strategies[C]. IEEE International Conference on Computer Science & Automation Engineering. IEEE, 2012.
- Belyaev S A, Kuleshov A S, Kholod I I. Solution of the answer formation problem in the question-answering system in Russian[C]. 2017 IEEE Conference of Russian Young Researchers in Electrical and Electronic Engineering (EIConRus). IEEE, 2017.
- Shervin Minaee, Zhu Liu. Automatic Question-Answering Using A Deep Similarity Neural Network[J]. 2017 IEEE Glo bal Conference on Signal and Information Processing, 2017.
- 孫景广. 基于网络的自动问答系统的答案抽取方法研究[D]. 沈阳航空工业学院, 2007.
- Boris Katz, Gregory Marton, Gary Borchardt, et al. The START Natural Language Question Answering System[EB/OL]. [2006-12-16]. http://start.csail.mit.edu.
- 徐海洲. 自动问答系统中问句相似度计算方法研究[D]. 华东交通大学, 2014.
- 黄萱菁. 复旦大学媒体计算与Web智能实验室信息检索和自然语言处理(IRNLP)组 [EB/OL]. http://www.yssnlp.com/ yssnlp2004/report/Fudan-Huangx-uanjing.pdf/.
- 盛艳梅. 自动问答系统中基于WordNet的句子语义相似度研究[D]. 曲阜师范大学, 2016.
- 曹存根. NKI-21世纪的科技热点[J]. 计算机世界报, 1998, 5(2): 1-3.
- 王颖. 基于自适应标签抽取的客服微博自动应答系统[D]. 北京邮电大学, 2014.
- 钟伟金, 李佳, 杨兴菊. 共词分析法研究三——共词聚类分析法的原理与特点[D]. 情报杂志, 2008.
- 廉同辉, 王中晶, 袁勤俭, 张丽霞. 基于共词分析的产业转移博士学位论文分析[D]. 南京大学信息管理学院, 2014.
- 余正涛, 毛存礼, 邓锦辉. 基于模式学习的中文问答系统答案抽取方法[J]. 吉林大学学报(工学版), 2008, 38(01): 142-147.
- 阳爱民. 面向文本情感分析的中文情感词典构建方法[J]. 山东大学学报(工学版), 2013(6): 27-33.
猜你喜欢
计算机与数字工程(2023年5期)2023-08-31
小学生优秀作文(高年级)(2022年3期)2022-03-29
山西大学学报(自然科学版)(2021年1期)2021-04-21
五邑大学学报(自然科学版)(2019年3期)2019-09-06
语文知识(2014年12期)2014-02-28
现代防御技术(2014年6期)2014-02-28
海峡姐妹(2014年5期)2014-02-27
