
基于噪声数据与干净数据的深度置信网络∗
2019-12-11 04:27丁世飞赵星宇
软件学报 2019年11期
张 楠 , 丁世飞,2,3 , 张 健 , 赵星宇
1(中国矿业大学 计算机科学与技术学院,江苏 徐州 221116)
2(矿山数字化教育部工程研究中心(中国矿业大学),江苏 徐州 221116)
3(中国科学院 计算技术研究所 智能信息处理重点实验室,北京 100190)
玻尔兹曼机(Boltzmann machine,简称BM)是一种概率图模型.该模型能够学习到输入数据的统计特性[1].Smolensky 在BM 的基础上提出了受限玻尔兹曼机(restricted Boltzmann machine,简称RBM)[2].RBM 是一种产生式无监督学习方法,它不仅能够从数据中学习到有效的特征,而且能够利用学习到的特征重构出原始数据.2006 年,Hinton 等人在《SCIENCE》上提出一种有效的深度网络学习方法——深度置信网(deep belief network,简称DBN),掀起了深度学习的研究热潮[3].其实,以受限玻尔兹曼机为基石的深度网络模型除了深度置信网以外,还有深度Sigmoid 置信网[4]、深度玻尔兹曼机[5]等.
与RBM 相比,以RBM 为基石的深度网络模型会表现出较好的分类能力.但是在处理噪声图像时,这些深度网络并没有展现出优于RBM 的学习能力.如果数据中存在噪声,那么RBM 学习到的特征也会蕴含噪声信息.特征选择方法可以从蕴含噪声信息的特征中找到与分类有关的特征[6].Sohn 等人结合受限玻尔兹曼机与特征选择方法提出了Point-wise Gated 受限玻尔兹曼机(point-wise gated RBM,简称pgRBM)[7].pgRBM不仅能够得到与分类有关的特征,还能在噪声数据中找到数据中与分类有关的部分.Zhang 等人结合pgRBM 提出了Pointwise Gated 深度置信网(point-wise gated deep belief network,简称pgDBN)和Point-wise Gated 深度玻尔兹曼机[8].这表明以RBM 为基石的深度网络在处理噪声时,传统的RBM 学习到的特征中蕴含的噪声信息影响了深度网络的性能.但是当一组数据中有噪声数据和干净数据时,如何应用干净数据提升pgRBM 在噪声数据中的学习能力,从而进一步提高深度网络模型处理噪声的能力,这是一个重要的研究问题.
本文在传统的pgRBM 基础上提出一种基于随机噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机(pgRBM based on random noisy data and clean data,简称pgrncRBM)方法.它可以利用干净数据提升算法在随机噪声数据上的学习能力.pgRBM 把隐层节点分为与分类有关的和与分类无关的两个部分,其连接权值的初值是用特征选择的方法对RBM 学习的权值处理得到的.pgrncRBM 就是在传统的pgRBM 基础上对pgRBM 学习到的数据二次去噪,其与分类无关的隐层节点相连权值的初值是用特征选择的方法对RBM 对一次降噪的数据学习到的权值处理得到的,但是其与分类有关的隐层节点相连权值的初值是用RBM 对不含噪声的数据学习得到的.这样,pgrncRBM 在处理随机噪声数据时可以学习到更为“干净”的数据.如果噪声是图片时,pgrncRBM 不能很好地去除噪声.传统的RBM 一般只适于处理二值图像.为了更好地处理实值图像,提出了一系列的RBM 的变种算法,如均值与协方差受限玻尔兹曼机(mcRBM)[9]和Spike-and-Slab 受限玻尔兹曼机(ssRBM)[10].mcRBM 和ssRBM 都表现出较好的实质图像数据建模能力,但不同的是,当隐层节点状态保持固定时,mcRBM 求取数据在可见层的联合概率分布用的是混合蒙特卡洛算法(HMC),而ssRBM 采用的是简单而有效的Gibbs 采样方法.因此,本文将ssRBM 与pgRBM 相结合,提出了一种基于图像噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机(pgRBM based on image noisy data and clean data,简称pgincRBM)方法.该方法使用ssRBM 对噪声建模,其在处理图像噪声数据时可以学习到更为“干净”的数据.然后,本文可以在pgrncRBM 和pgincRBM 的基础上堆叠出深度置信网络模型,如基于随机噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机(pgDBN based on random noisy data and clean data,简称pgrncDBN)以及基于图像噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机(pgDBN based on image noisy data and clean data,简称pgincDBN).
训练神经网络时常常会遇到过拟合问题,以RBM 为基石的深度网络也是如此.目前,RBM 中常常用的解决过拟合问题有权值衰减、Dropout[11]、Dropconnect[12,13]、权值不确定性[14-16].Zhang 等人将权值不确定性引入pgRBM 和pgDBN,验证了权值不确定性在这两种网络中的有效性[8].本文将权值不确定性引入pgrncRBM 和pgincRBM 中,把pgrncRBM 和pgincRBM 中与分类有关的权值看作一组符合高斯分布的变量而不是固定值.同样地,本文还将权值不确定性引入以pgrncRBM 和pgincRBM 为基石的深度网络pgrncDBN 和pgincDBN 中,并探究了这几种算法的可行性.
本文第1 节简述受限玻尔兹曼机算法、深度置信网算法和Point-wise Gated 受限玻尔兹曼机算法.第2 节详述本文提出的基于噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机算法和以它们为基石的Pointwise Gated 深度置信网算法.第3 节介绍权值不确定性方法在pgncRBM 和pgncDBN 两种网络模型中的应用.第4 节用含噪声的手写数据集测试本文提出的算法的性能.实验结果表明,pgrncRBM 和pgincRBM 都是有效的神经网络学习方法.
1 相关工作
1.1 受限玻尔兹曼机与深度置信网算法
受限玻尔兹曼机(RBM)是一种生成式随机网络,由可见层和隐层组成.RBM 网络的权值θ由可见层和隐层的连接权值矩阵W=(Wij)∈RD×J、可见层的偏置向量和隐层的偏置向量组成.当给定一组可见层状态和隐层状态时,RBM 的能量函数和似然函数分别表述为

其中,vi∈{0,1};hj∈{0,1};是配分函数;P(v;θ)对应P(v,h;θ)的边缘分布,又称为似然函数.当可见层和隐层其中之一状态固定时,RBM 的条件概率分布可以表述为

深度置信网(DBN)是一个概率生成模型.它是由RBM 堆叠构成的深度网络模型.首先,DBN 通过利用不带标签数据,用RBM 算法自底向上逐层训练得到深度网络的初值.在预训练之后,DBN 通过利用带标签数据,用BP 算法对网络的权值进行调整.
1.2 Point-wise Gated受限玻尔兹曼机算法
与RBM 不同,pgRBM 把隐层节点分为与分类有关的和与分类无关的两个部分.pgRBM 的网络结构如图1所示.此时,pgRBM 的能量函数可表述为

其中,与分类有关的隐层h1对应的权值为{W1,c1,b1},与分类无关的隐层对应的权值为{W2,c2,b2}.

Fig.1 Network structure of pgRBM图1 pgRBM 的网络结构
当可见层、转换层和隐层任意两层状态固定时,pgRBM 的条件概率分布可以表述为

Zhang 等人将权值不确定性引入pgRBM,提出了权值不确定性Point-wise Gated 受限玻尔兹曼机(weight uncertainty pgRBM,简称pgwRBM)算法.与pgRBM 不同的是,pgwRBM 将与分类有关的隐层与可见层、转换层的连接权值W1看作符合高斯分布的变量,其均值和标准差分别是μ1和σ1=log(1+exp(ρ1)).此时,pgwRBM 的能量函数可表述为
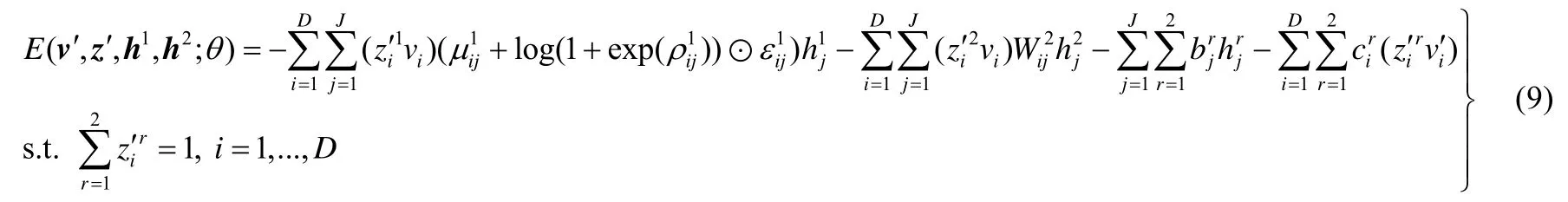
其中,⊙表示矩阵中的元素对位相乘.
pgwRBM 的学习过程详见文献[8].和RBM 一样,pgRBM 和pgwRBM 也可以使用CD 等算法去计算权值的梯度,从而更新网络的权值.
2 基于噪声数据与干净数据的Point-wise Gated 深度置信网络模型
2.1 基于随机噪声数据与干净数据的Point-wise Gated受限玻尔兹曼机算法
当数据中存在少量噪声时,添加噪声在某些情况下可以增加分类器的泛化能力.但是,如果数据中存在大量噪声,噪声的添加就降低了训练数据的分类准确率,并且还不能获得更好的泛化能力.Point-wise Gated 受限玻尔兹曼机就是针对这种情况提出来的.它能够在噪声数据中找到数据中与分类有关的部分,从而提升分类器的分类准确率.但是,当一组训练数据中同时出现噪声数据和干净数据时,如何应用干净数据提升传统的pgRBM 在噪声数据上的学习能力,是一个重要的研究问题.针对这一问题,本文首先在传统的pgRBM 基础上提出一种基于随机噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机方法.它可以利用不含噪声的数据提升算法在噪声数据上的学习能力.和传统的pgRBM 一样,pgrncRBM 的网络结构同样可以用图1 来表示.当给定一组可见层状态和隐层状态时,pgrncRBM 的能量函数也可以表述为
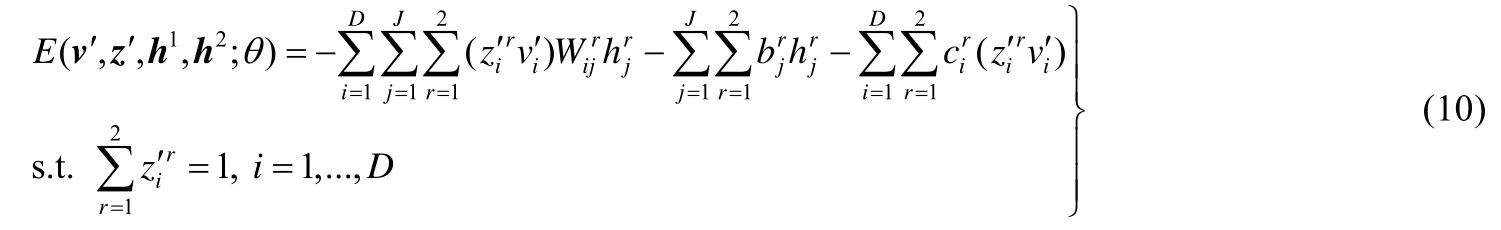
其中,v′是pgRBM 对噪声数据v处理之后得到的与分类有关的数据[7].我们可以看出,pgrncRBM 就是在传统的pgRBM 基础上对pgRBM 学习到的数据二次去噪.并且,pgrncRBM 网络权值的赋初值的方法也与传统的pgRBM 不同.pgncRBM 同样把隐层节点分为与分类有关的和与分类无关的两个部分,那么其与分类有关的隐层相连权值的初值是用RBM 对不含噪声的数据学习得到的,并且其与分类无关的隐层相连权值的初值还是用特征选择的方法对RBM 对一次降噪的数据v′学习到的权值处理得到的.pgrncRBM 预训练完成后,通过利用带标签的噪声数据与BP 算法对网络的权值进行调整.在pgRBM 中,网络的输入数据是pgRBM 对噪声数据v处理之后得到的“干净”数据,输出是与数据对应的标签.同理,在pgrncRBM 中,网络的输入数据是pgrncRBM 对一次降噪的数据v′处理之后得到的更为“干净”的数据,输出是与数据对应的标签.
2.2 基于图像噪声数据与干净数据的Point-wise Gated受限玻尔兹曼机算法
pgrncRBM 在处理随机噪声数据时可以学习到更为“干净”的数据,但当噪声是图片时,它不能很好地去除噪声.针对这一问题,本文又将ssRBM 与pgRBM 相结合,提出一种基于图像噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机方法.该方法使用ssRBM 对噪声建模,其在处理图像噪声数据时可以学习到更为“干净”的数据,可以利用不含噪声的数据,提升算法在图像噪声数据上的学习能力.当给定一组可见层状态和隐层状态时,pgincRBM 的能量函数也可以表述为
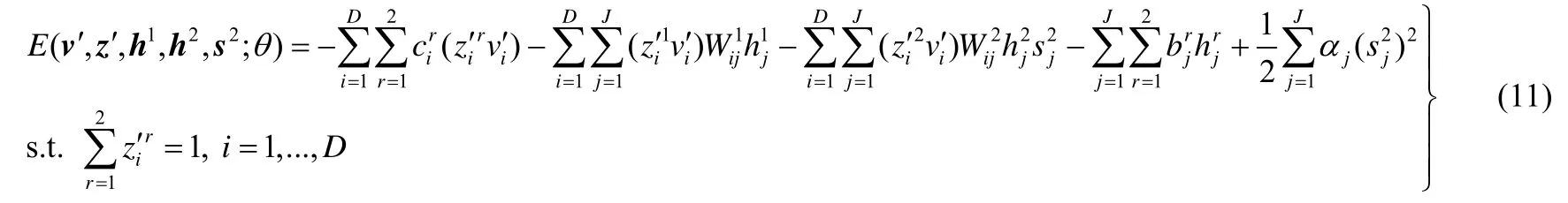
其中,v′是pgRBM 对噪声数据v处理之后得到的与分类有关的数据,αj是对惩罚项的系数.我们可以看出,pgincRBM 中与分类无关的隐层相连的可见层节点并不像ssRBM 那样使用对角矩阵对其加以惩罚,而是使用偏置.这是因为当转换层和隐层两层状态固定时,只能推导出与分类有关的隐层相连的可见层节点被激活的概率,而不能得到其概率分布情况,这样就只能推倒得到与分类无关的隐层相连的可见层节点被激活的概率.这样,当可见层、转换层和隐层任意两层状态固定时,剩余一层节点被激活的概率(或者概率分布)可以表述为


和pgrncRBM 一样,pgincRBM 也可以使用CD 等算法去计算权值的梯度,从而更新网络的权值.pgincRBM预训练完成后,通过利用带标签的噪声数据和BP 算法对网络的权值进行调整.在pgincRBM 中,网络的输入数据是pgincRBM 对一次降噪的数据v′处理之后得到的更为“干净”的数据,输出是与数据对应的标签.
2.3 基于噪声数据与干净数据的Point-wise Gated深度置信网算法
在处理含噪声的图像时,DBN 并没有展现出优于RBM 的学习能力.Zhang 等人结合pgRBM 提出了Pointwise Gated 深度置信网(pgDBN),并且pgDBN 展示出优于pgRBM 的分类能力.我们得出,以传统的RBM 为基石的深度网络在处理噪声时,传统的RBM 学习到的特征中蕴含的噪声信息影响了深度网络的性能.当一组数据中同时出现噪声数据和干净数据时,就可以利用干净数据进一步提高深度网络模型处理噪声的能力.因此,本文堆叠pgrncRBM、pgincRBM、传统的RBM,构建出两种基于噪声数据与干净数据的Point-wise Gated 深度置信网(pgDBN based on noisy data and clean data,简称pgncDBN),包含基于随机噪声数据和干净数据的Point-wise Gated 深度置信网,以及基于图像噪声数据和干净数据的Point-wise Gated 深度置信网.以两隐层pgrncDBN 为例,图2 给出了pgrncDBN 的预训练过程.首先,pgrncDBN 和pgincDBN 分别用pgrncRBM 或者pgincRBM 对一次降噪的数据v′预训练,得到更为“干净”的数据;然后,它们都利用RBM 预训练隐层间的连接权值;最后,它们都随机确定最后一层隐层与输出层的连接权值,随后用BP 算法微调整个网络的权值.

Fig.2 Pre-training process of pgrncDBN图2 pgrncDBN 的预训练过程
3 权值不确定性方法在pgrncDBN 与pgincDBN 深度网络中的应用
权值不确定性方法是一种神经网络中常见的解决过拟合现象的方法.它把神经网络中的每个权值看作一个可能值的概率分布,而不是以前的单一的固定值,这样学习到的特征更为鲁棒.Zhang 等人把权值不确定性方法引入RBM,提出了权值不确定性受限玻尔兹曼机(weight uncertainty RBM,简称wRBM),其将每个可见层与隐层间的连接权值看作一个可能值的概率分布.同时,Zhang 等人将权值不确定性引入pgRBM,提出了权值不确定性受限玻尔兹曼机,其将与分类有关的隐层节点相连的权值看作一个可能值的概率分布.wRBM 能够有效地解决RBM 的过拟合问题,但它在处理含噪声的数据时并不是都能达到理想的效果.权值不确定性中权值的波动也可以理解为训练数据的变化,这种数据中噪声的波动可能在一定程度上影响了算法的性能,因此,pgwRBM 中与分类无关的隐层节点相连的权值还是实值.也就是说,我们可以将pgwRBM 中与分类有关的数据看作是变化的,将与分类无关的噪声看作是不变的.本文同样将权值不确定性引入pgrncRBM 和pgincRBM,提出了基于随机噪声数据与干净数据的 Point-wise Gated 权值不确定性受限玻尔兹曼机(weight uncertainty pgrncRBM,简称pgwrncRBM)以及基于图像噪声数据与干净数据的Point-wise Gated 权值不确定性受限玻尔兹曼机(weight uncertainty pgincRBM,简称pgwincRBM).为了对比两种模型引入权值不确定性前后的性能,pgwrncRBM 和pgwincRBM 也是在传统的pgRBM 基础上对pgRBM 学习到的数据二次去噪.
在pgwrncRBM 算法中,与分类有关的隐层与可见层、转换层的连接权值W1被看作符合高斯分布的变量,其均值和标准差分别表述为μ1和σ1=log(1+exp(ρ1)).与pgwRBM 类似,当给定一组可见层状态和隐层状态时,pgwrncRBM 的能量函数可表述为

其中,与分类有关的隐层h1对应的权值为{μ1,ρ1,c1,b1},与分类无关的隐层对应的权值为{W2,c2,b2}.
pgwrncRBM 与pgwRBM 的不同之处有:一是赋初值的方法不同,二是学习的数据不同.pgwrncRBM 与分类无关的隐层相连权值{W2,c2,b2}的初值还是用特征选择的方法对一次降噪的数据v′学习到的RBM 权值处理得到的,但其与分类有关的隐层相连权值{μ1,c1,b1,ρ1}的初值有两种方式:一是用wRBM 对不含噪声的数据学习得到的,二是权值{μ1,c1,b1}的初值用RBM 对不含噪声的数据学习得到的,权值ρ1的初始值是随机赋值的.pgwrncRBM 是对pgRBM 学习到的数据v′二次去噪,而pgwRBM 是对原始的噪声数据去噪.pgwrncRBM 的连接权值矩阵W1可以表述为W1=μ1+log(1+exp(ρ1))⊙ε1(其中,ε1~N(0,I)),则当可见层、转换层和隐层任意两层状态固定时,pgwrncRBM 的条件概率分布可以用公式(6)~公式(8)表示.当pgwrncRBM 用CD-k算法调整权值时,参数{μ1,ρ1,W2}的梯度分别为
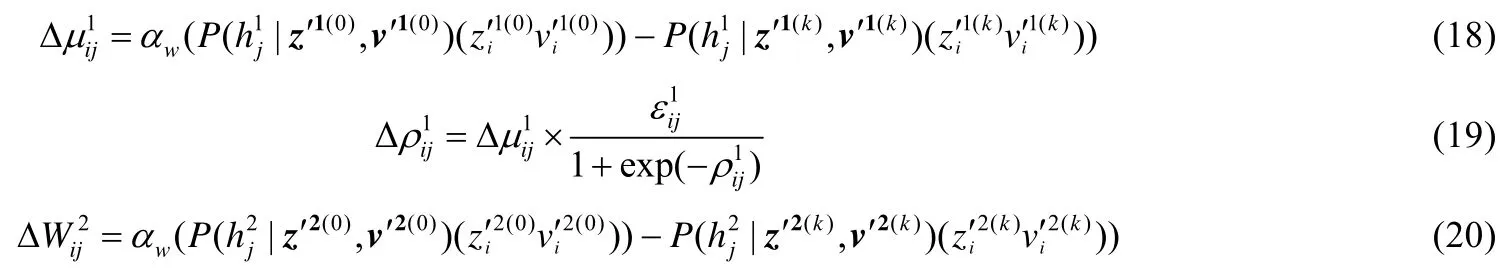
用CD-k算法调整权值时,pgwrncRBM 的{c1,b1,W2,c2,b2}的梯度的计算方法与pgrncRBM 一致.
pgwincRBM 算法的能量函数与pgwrncRBM 和pgwRBM 略有不同,其使用ssRBM 对噪声建模.假设pgwincRBM 与分类有关的隐层与可见层、转换层的连接权值W1是符合高斯分布变量,其均值和标准差同样可表述为μ1和σ1=log(1+exp(ρ1)).当给定一组可见层状态和隐层状态时,pgwincRBM 的能量函数可表述为
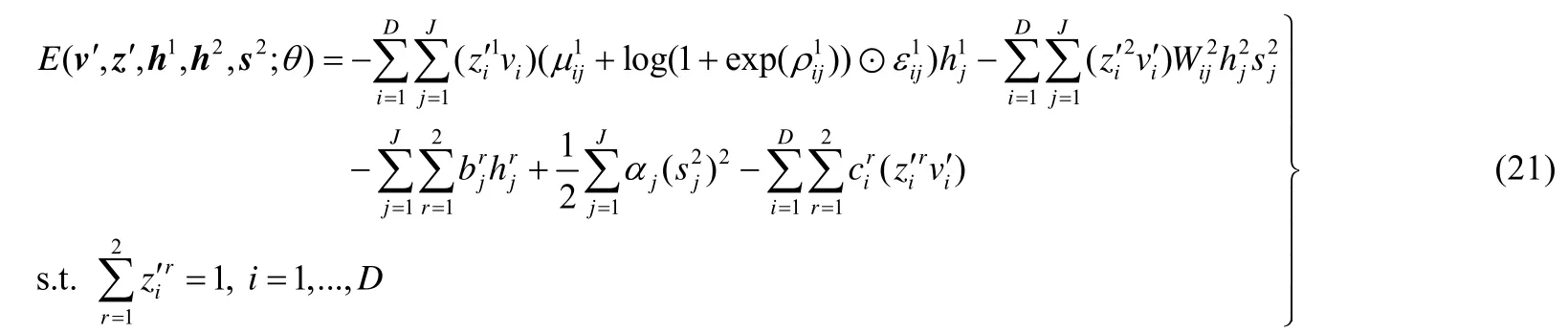
其中,与分类有关的隐层h1对应的权值为{μ1,ρ1,c1,b1},与分类无关的隐层对应的权值为{W2,c2,b2,α}.
与pgincRBM 相比,pgwincRBM 与分类无关的隐层相连权值{W2,c2,b2,α}的初值还是用特征选择的方法对一次降噪的数据v′学习到的ssRBM 权值处理得到的,但其与分类有关的隐层相连权值{μ1,c1,b1,ρ1}的赋初值方式和pgwrncRBM 一样.在pgwincRBM 算法中,当可见层、转换层和隐层任意两层状态固定时,剩余一层节点被激活的概率(或者概率分布)可以用公式(12)~公式(16)表示.当pgwincRBM 用CD-k算法调整权值时,其参数{μ1,ρ1,W2}的梯度分别为
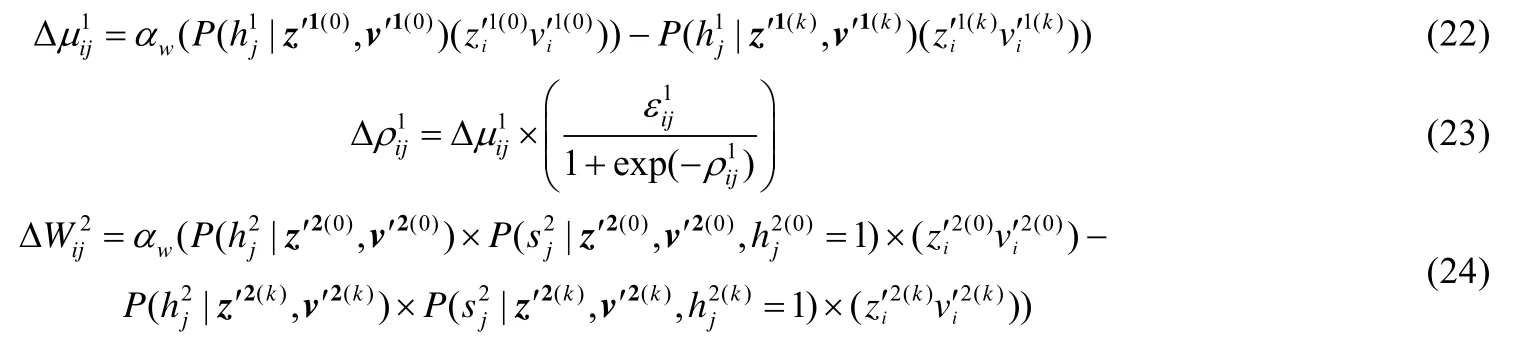
用CD-k算法调整权值时,pgwincRBM 的{c1,b1,W2,c2,b2}的梯度的计算方法与pgincRBM 一致.
和pgrncDBN 与pgincDBN 类似,可以通过堆叠pgwrncRBM、pgwincRBM 和wRBM 分别构造出包含基于随机噪声数据与干净数据的Point-wise Gated 权值不确定性深度置信网(pgwDBN based on random noisy data and clean data,简称pgwrncDBN)以及基于图像噪声数据与干净数据的Point-wise Gated 权值不确定性深度置信网(pgwDBN based on image noisy data and clean data,简称pgwincDBN).pgwrncDBN(pgwincDBN)首先用pgwrncRBM(pgwincRBM)对一次降噪的数据v′预训练,得到更为“干净”的数据.和pgrncDBN(pgincDBN)一样,pgwrncDBN(pgwincDBN)网络的输入层与隐层,以及隐层与隐层间的连接权值的初值也有两种赋初值方式:一是利用pgwrncRBM(pgwincRBM)对一次降噪的数据v′预训练得到转换层、可见层与第1 层隐层的连接权值,随后用wRBM 预训练隐层间的连接权值;二是利用wRBM 通过对不含噪声的数据学习得到转换层、可见层与第1 层隐层的连接权值,随后同样用wRBM 预训练隐层间的连接权值.pgwrncDBN(pgwincDBN)最后随机确定最后一层隐层与输出层的连接权值,随后用BP 算法微调整个网络的权值.
4 实验与分析
4.1 实验设置与数据集
为了测试提出的算法的性能,将其与RBM、wRBM、pgRBM、pgwRBM、DBN、wDBN、pgDBN、pgwDBN和卷积神经网络(convolutional neural network,简称CNN)进行比较.以上几种方法都是在Intel(R)Xeon(R)CPU E4500 0@3.6GHZ 处理器、18GB 内存、Windows 7 64 位操作系统和MATLAB 2015B(其中,CNN 是通过Python3.5+TensorFlow 框架实现的)的环境中运行的.本文实验所用的随机噪声数据集是依据文献[18]的方法对MNIST basic 和MNIST rotated 处理得到的数据集.设置不同邻域相关度值{0,0.2,0.4,0.6,0.8,1},使MNIST basic 中每个像素点的边缘分布在(0,1),可以得到6 种不同的数据集MNIST basic-back-random-a/b/c/d/e/f.同样可以对MNIST rotated 处理得到数据集MNIST rotated-back-random-a/b/c/d/e/f.本文实验所用的图像数据集是文献[18]中的MNIST back-image 和MNIST rotated-back-image.在所有的数据集中,训练样本都有10 000 个噪声数据和10 000 个干净数据,验证和测试样本分别为2 000 个和50 000 个噪声数据,样本维数是784,标签数目为10.图3 给出了若干数据集的部分样本.

Fig.3 Legends of benchmark data sets图3 基准数据集的图例
在本文中,所有算法都采用mini-batch 方法学习,并且批量的大小均为100.RBM 和wRBM 隐层节点数为500 或1 000.pgRBM 和pgwRBM 都是通过特征选择的方法对隐层节点数为1 200 的RBM 学习到的权值处理得到初值,并且它们的与分类有关的隐层和与分类无关的隐层节点数均为500.
pgrncRBM、pgincRBM、pgwrncRBM 和pgwincRBM 都是在传统的pgRBM 基础上对pgRBM 学习到的数据二次去噪,并且它们的与分类有关的隐层和与分类无关的隐层节点数均为500.
pgrncRBM、pgincRBM、pgwrncRBM 和pgwincRBM 与分类有关的隐层相连权值的初值是用RBM 或wRBM 对不含噪声的数据学习得到的,其与分类无关的隐层相连权值的初值都是用特征选择的方法对隐层节点数为1 200 的RBM 或者ssRBM 对一次降噪的数据v′学习到的权值处理得到的.
DBN、wDBN、pgDBN、pgwDBN、pgrncDBN、pgincDBN、pgwrncDBN 和pgwincDBN 的隐层结构均为500-500-2 000.CNN 是五隐层网络结构,依次为卷积层(32 个5×5 卷积核)、池化层(过滤器大小为2×2)、卷积层(64 个5×5 卷积核)、池化层(过滤器大小为2×2)和全连接层(1 024 个隐层节点).所有算法最后均使用梯度下降算法分类,最大迭代次数为200(其中,CNN 的最大的迭代数目为500),并且依据验证数据集的错误率采用提前终止方法.
4.2 算法性能比较与分析
表1 给出了RBM、wRBM、pgRBM、pgwRBM、pgrncRBM 和pgwrncRBM 算法在含随机噪声的手写数据集上的错误率.
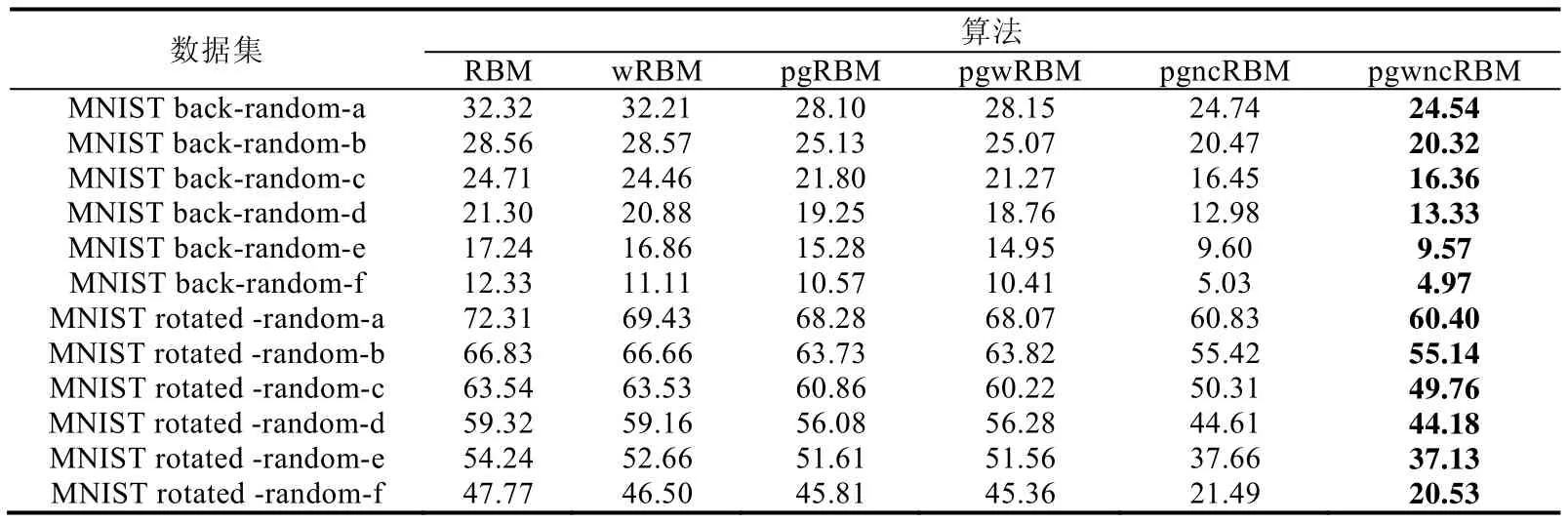
Table 1 Error rates of shallow algorithms on random noisy data sets (%)表1 浅层算法在随机噪声数据集上的错误率 (%)
我们可以看出,pgwrncRBM 在所有数据集上都表现出优于其他浅层学习算法的分类效果.
通过对比pgRBM 和pgrncRBM,我们可以看出,pgrncRBM 在所有数据集上的分类性能都优于pgRBM.这说明利用不含噪声的数据可以提升pgrncRBM在随机噪声数据上的学习能力.通过对比表1 中的算法,我们还可以发现:
1)wRBM 基本上在所有随机噪声数据集上都表现出优于RBM 的分类性能.
2)pgwRBM 仅在MNIST back-random-a、MNIST rotated-back-b 和MNIST rotated-back-d 这3 个数据集上的错误率略高于pgRBM.
3)pgwrncRBM 在所有数据集上都表现出优于pgrncRBM 的分类性能.
4)随机噪声数据中噪声结构越简单,与pgRBM 相比,pgrncRBM 提升的分类效果就越明显.
表2 给出了RBM、wRBM、pgRBM、pgwRBM、pgincRBM 和pgwincRBM 算法在含图像噪声的手写数据集上的错误率.同样地,pgwincRBM 在所有图像噪声数据集上都表现出优于其他浅层学习算法的分类效果.

Table 2 Error rates of shallow algorithms on image noisy data sets (%)表2 浅层算法在图像噪声数据集上的错误率 (%)
通过对比表2 中的算法,我们还可以发现:
1)wRBM 在所有图像噪声数据集上的分类性能略优于RBM.
2)pgwRBM 在MNIST rotated-back-image 数据集上的错误率略高于pgRBM.
3)pgwincRBM 在所有图像噪声数据集上都表现出优于pgncRBM 的分类性能.
从表1 和表2 我们可以得出:1)权值不确定性方法能够有效地解决RBM、pgRBM、pgrncRBM 和pgincRBM在处理含噪声的数据时出现的过拟合问题;2)利用不含噪声的数据,可以提升pgrncRBM 和pgincRBM 在噪声数据上的学习能力.
图4 展示了pgrncRBM 在MNIST back-random-f 上的分类性能随干净样本数目变化曲线.
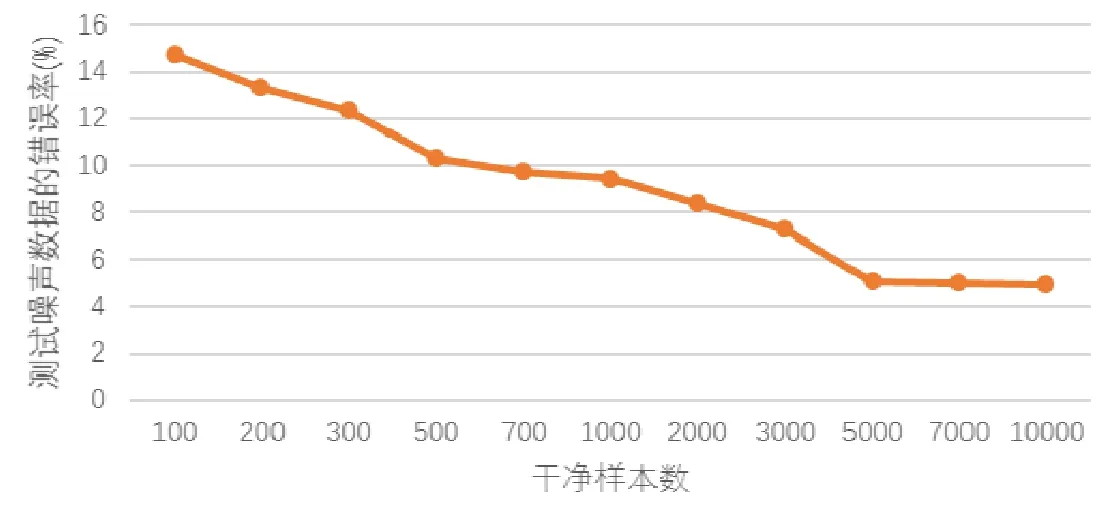
Fig.4 Variations in the performance of pgrncRBM on MNIST back-random-/f,as we increase the number of the clean data图4 pgrncRBM 在MNIST back-random-f 上的分类性能随干净样本数目变化曲线
我们可以从图4 中看出,当干净样本数目增大时,pgrncRBM 分类效果越来越好,这和我们的直观理解是一致的.pgrncRBM 中与分类有关的隐层节点相连权值的初值是用RBM 对不含噪声的数据学习得到的,干净样本越多,RBM 学习到的不含噪声数据的信息就越多,pgrncRBM 也能更好地将噪声数据中与分类有关的信息表示出来.图5 给出了pgRBM 和pgrncRBM 在MNIST back-random-a/f 两种数据集上的学习结果,图6 给出了pgRBM和pgincRBM 在MNIST back-image 数据集上的学习结果.pgRBM、pgrncRBM 和pgincRBM 都把隐层节点分为与分类有关的和与分类无关的两个部分,并且都能在含噪声的数据中自适应找到数据中与分类有关的部分.但是,我们可以从图5 和图6 中看出:
1)pgRBM 学习得到的与分类无关的图像(也就是噪声)中包含的噪声信息很少,pgRBM 学习得到的与分类有关的图像与原始的含噪声图像相差不是很大.
2)pgrncRBM 是在pgRBM 基础上对其学习到的与分类有关的图像二次去噪,但是pgrncRBM 可以很好地把图像中与分类有关的信息(也就是手写数字)和噪声信息分别学习出来,特别是pgncRBM 在MNIST back-random-f 这个数据集上学习得到的与分类有关的图像基本上没有噪声.
3)pgincRBM 是在pgRBM 基础上对其学习到的与分类有关的图像二次去噪,pgncRBM 可以把图像中与分类有关的信息(也就是手写数字)和图像噪声信息分别学习出来,但是有时也只能学习到部分与分类有关的信息,如第1 列中的数字2.

Fig.5 Learing results of pgRBM and pgncRBM on MNIST back-random-a/f data sets图5 pgRBM 和pgncRBM 在MNIST back-random-a/f 数据集上的学习结果

Fig.6 Learing results of pgRBM and pgincRBM on MNIST back-image data set图6 pgRBM 和pgincRBM 在MNIST back-image 数据集上的学习结果
表3 给出了含噪声的原始图像、pgRBM 学习到的与分类有关的图像和pgincRBM/pgrncRBM 学习到的与分类有关的图像与干净数据的信噪比.我们可以得出,pgrncRBM 和pgincRBM 可以在传统的pgRBM 基础上对pgRBM 学习到的数据二次去噪得到蕴含噪声信息较少的图像,从而达到更好的分类效果.pgrncRBM 在MNIST back-random-f 和MNIST rotated-random-f 上的错误率分别是5.03%和21.49%,而pgRBM 在这两个数据集的错误率是pgrncRBM 的2 倍以上.并且,特别是在文献[18]中,RBM 在MNIST basic 和MNIST rotated 的错误率分别是3.94%和14.69%,这与pgrncRBM 在MNIST back-random-f 和MNIST rotated-random-f 上的错误率还是比较接近的.
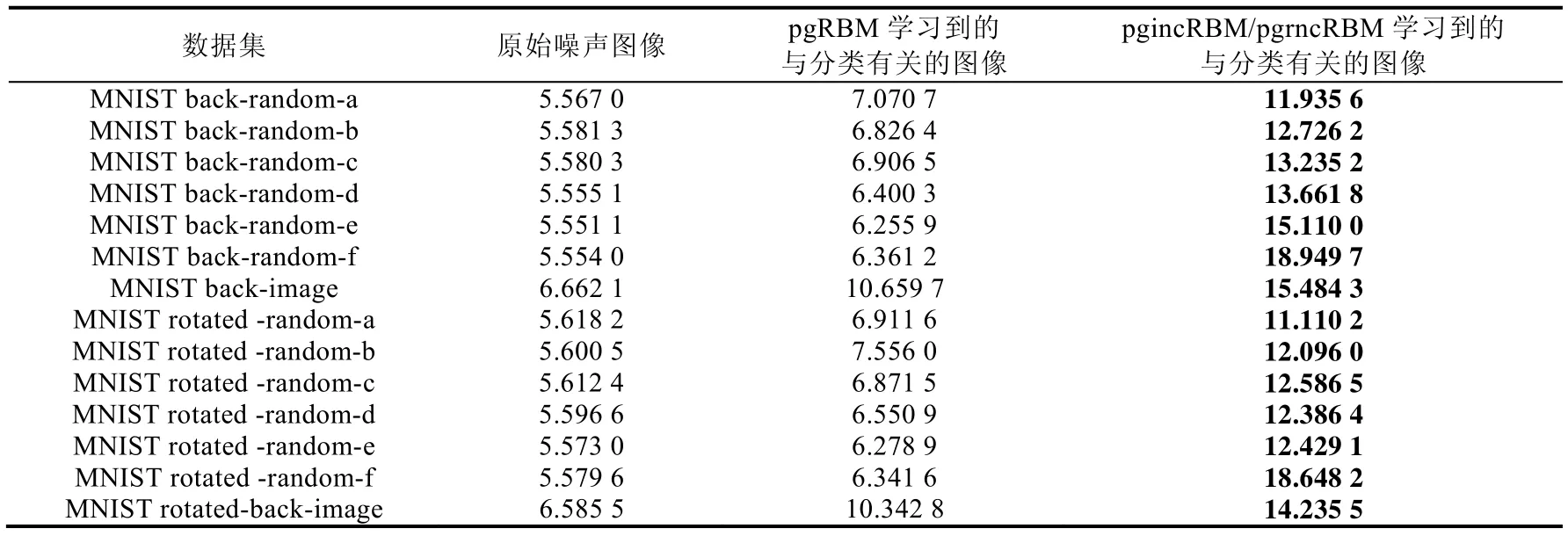
Table 3 Signal-noise ratios of learing results of pgRBM and pgincRBM/pgrncRBM on different valid data sets表3 pgRBM 和pgincRBM/pgrncRBM 学习结果在验证数据集上的信噪比
表4 给出了DBN、wDBN、pgDBN、pgwDBN、pgncDBN、pgwncDBN 和CNN 算法含随机噪声的手写数据集上的错误率.我们从表4 可以看出,pgwrncDBN 在绝大多数数据集上的性能都表现出优于其他深度学习算法的分类效果.通过对比pgDBN 和pgncDBN,我们可以看出,pgrncDBN 在所有随机噪声数据集上的分类性能都优于pgDBN.实验结果表明,pgrncDBN 还是一种有效的神经网络学习算法.我们又可以发现以下结果.
1)wDBN 在所有数据集上都要表现出优于DBN 的分类性能.
2)pgwDBN 在所有数据集上都要表现出优于pgDBN 的分类性能.
3)pgwrncDBN 仅在MNIST rotated-back-f 数据集上的错误率略高于pgrncDBN.
4)CNN 仅在MNIST back-random-a、MNIST back-random-b 和MNIST rotated-random-a 这3 个数据集上的错误率低于pgrncDBN 和pgwrncDBN.

Table 4 Error rates of deep algorithms related to DBN on random noisy data sets (%)表4 与DBN 相关的深度算法在随机噪声数据集上的错误率 (%)
表5 给出了DBN、wDBN、pgDBN、pgwDBN、pgincDBN、pgwincDBN 和CNN 算法在含图像噪声的手写数据集上的错误率.除了在MNIST back-image 上的错误率略高于CNN 以外,pgwincDBN 在所有图像噪声数据集上都表现出优于深度浅层学习算法的分类效果.通过对比表5 中的算法,我们还可以发现:
1)wDBN 在所有图像噪声数据集上的分类性能略优于DBN.
2)pgwDBN 在所有图像数据集上的错误率略高于pgDBN.
3)pgwincRBM 在所有图像噪声数据集上都表现出优于pgncRBM 的分类性能.
4)CNN 仅仅在MNIST back-image 数据集上的错误率略低于pgincDBN 和pgwincDBN.

Table 5 Error rates of deep algorithms related to DBN on image noisy data sets (%)表5 与DBN 相关的深度算法在图像噪声数据集上的错误率 (%)
从表4 和表5 中我们可以得出:1)权值不确定性方法有效地解决了pgrncDBN 和pgincDBN 两种深度网络中出现的过拟合问题;2)pgrncDBN/pgwrncDBN 和pgincDBN/pgwincDBN 可以在绝大多数数据集上的性能超过CNN 的主要原因是pgrncRBM/pgwrncRBM 和pgincRBM/pgwincRBM 可以学习得到更为“干净”的数据.通过对比RBM、DBN 和wDBN,我们可以得出,DBN 在处理含噪声数据时出现过拟合现象,并没有展现出比RBM更好的学习能力,并且权值不确定性方法有效地解决了DBN 深度网络中出现的过拟合问题.通过对比pgRBM与pgDBN、pgrncRBM 与pgrncDBN、pgincRBM 与pgincDBN,我们又可以发现,堆叠pgRBM/pgrncRBM/pgincRBM 和RBM 构造出的深度网络(pgDBN、pgrncDBN 和pgincDBN)展现出优于浅层网络(pgRBM、pgrncRBM 和pgincRBM)的学习能力.
5 结束语
Point-wise Gated 受限玻尔兹曼机是一种针对噪声数据的浅层学习算法.本文在此基础上利用干净数据提升其在噪声数据上的学习能力,提出了两种基于噪声数据与干净数据的Point-wise Gated 受限玻尔兹曼机(pgrncRBM 和pgincRBM)方法,然后将它们学习到的与分类有关的数据子集用到深度置信网中,提出了两种基于噪声数据与干净数据的Point-wise Gated 深度置信网(pgrncDBN 和pgincDBN).pgrncRBM 和pgincRBM 在绝大多数手写数据集上都表现出优于pgRBM 的学习能力.同样,以pgrncRBM 和pgincRBM 为基石的pgrncDBN和pgincDBN 一般都优于pgDBN.然后,本文将权值不确定性方法用在所提出的4 种算法中,并将这几种算法称为基于噪声数据与干净数据的Point-wise Gated 权值不确定性受限玻尔兹曼机(pgwrncRBM 和pgwincRBM)以及基于噪声数据与干净数据的Point-wise Gated 权值不确定性深度置信网(pgwrncDBN 和pgwincDBN).实验结果表明,权值不确定性方法能够有效地解决pgrncRBM、pgincRBM、pgrncDBN 和pgincDBN 在处理含噪声数据时出现的过拟合问题.我们同时发现,pgRBM、pgrncRBM 和pgincRBM 并不能在部分噪声数据集(数据中与分类有关的部分被噪声损坏时)上取得理想的结果.如何把它们应用到更多的噪声数据上,也是我们下一步的研究方向.
猜你喜欢
浙江大学学报(理学版)(2022年4期)2022-07-25
成都信息工程大学学报(2022年3期)2022-07-21
复旦学报(自然科学版)(2022年1期)2022-06-16
计算机研究与发展(2022年1期)2022-01-19
邮电设计技术(2021年2期)2021-03-13
计算机应用(2020年12期)2020-12-31
火力与指挥控制(2020年2期)2020-04-02
计算机与数字工程(2019年11期)2019-11-29
电子技术与软件工程(2019年12期)2019-08-22
计算机测量与控制(2018年3期)2018-03-27
