
基于W-Net的高分辨率遥感卫星图像分割
2020-02-05 09:19范自柱王松张泓石林瑞符进武李争名
华南理工大学学报(自然科学版) 2020年12期
范自柱 王松 张泓 石林瑞 符进武 李争名
(1.华东交通大学 理学院,江西 南昌 330013;2.广东技术师范大学 工业实训中心,广东 广州 510665)
遥感卫星图像是遥感卫星向地球表面发射并接收电磁波,然后通过分析电磁波得到的可视化图像。目前,遥感图像广泛运用于土地测绘、环境监控、智慧农业和灾害预警等领域。随着获取的遥感卫星图像数量越来越多,如何快速、精准地识别图像中的地物成为目前遥感卫星图像领域的研究重点。
遥感卫星图像的识别方法主要分为两类:第1类为使用目标检测的方法[1- 4];第2类为使用图像分割的方法[5- 8]。Arnt[1]使用基于RCNN[9]的方法检测遥感卫星图像中的海豹。首先,检测图像中可能包含海豹的区域,然后使用深度神经网络进行特征提取,最后采用线性支持向量机将检测到的区域分为非海豹、成年海豹和海豹幼崽。基于CNN(卷积神经网络)和SVM(支持向量机)的方法在海豹检测任务中达到了98.2%的准确率。He等[2]使用基于Faster RCNN[10]的方法检测大尺度高分辨率卫星图像中的船舶。在训练过程中,通过输入大量没有任何目标的图像作为负样本图像来避免将陆地上的物体识别成为船舶。该方法可以在不进行海陆分割的情况下,成功识别海陆中的船舶。以上方法都是基于目标检测的方法识别遥感卫星图像中的特定对象。但在实际应用中,遥感卫星图像中的道路、森林、湖泊、建筑物等地物的研究更加重要,这些对象的形态、大小不一,难以使用目标检测的方式进行识别。但使用图像分割的方法能够将这些地物进行分割,以达到识别的结果。Deepika等[5]分别使用了K-均值聚类算法、阈值技术、主动轮廓模型对遥感卫星图像进行分割,通过实验对比得出主动轮廓模型分割效果是3种算法中最好的。但是主动轮廓模型不适用于灰度不均匀的图像,难以反映图像细节,对噪声也相对更敏感。该方法只能用来描述土地类型的边缘,并不能用来区分不同地形。Saha等[6]使用遗传聚类技术自动聚类遥感卫星图像中的每一个像素,来达到图像分割的目的。由于遥感卫星图像存在太多的簇类,其识别速度慢,因此不能达到实时的效果。苏健民等[7]使用改进的U-Net[11]网络对高分辨遥感卫星图像中的地物进行分割。他们将U-Net中RELU激活函数修改为ELU,并统一网络的滤波器数量为64,该方法在地物分割中得到了90%的查准率和88%的查全率,精准分割了遥感图像中的复杂目标。由于遥感卫星图像中的地物为不规则形状,使用图像识别的方法难以得到很好的识别效果,所以选择采用图像分割的方法为图像中的每一个像素分配一个标签,从而识别图像中的物体。传统的语义分割方法在遥感图像分割任务中的准确率较低,达不到实际应用的要求。为了使遥感卫星获取到的图像能够提供实时、可靠的信息,设计一个准确、高效、实时的遥感卫星图像分割方法是十分必要的。
传统的图像分割方法有阈值分割[12]、区域分割[13]、边缘分割[14]等。随着硬件性能的提升和深度学习技术的发展,深度学习在计算机视觉、自然语言处理等领域都取得了非常好的成绩。最初的语义分割方案和最初的目标检测方案相似,都是采用滑动窗体进行分类。但是滑动窗体的方法计算效率非常低,识别精度不高。2015年,加州大学伯克利分校的研究人员提出全卷积神经网络(FCN)[15]进行语义分割。作者将卷积神经网络中的全连接层替换为卷积层,最后输出为分割图像。FCN实现了端到端的训练方式,网络的输入和输出均为图像。全卷积神经网络成为当时在PASCAL VOC数据集中最出色的语义分割网络,对一个典型图像进行推理花费的时间不到0.2 s,该文献的发表成为语义分割领域的重要转折点,后续许多的工作[11]都是使用全卷积的方式。2015年,Ronneberger等[11,16- 17]对FCN进行改进并提出了一种新的网络——U-Net,该网络使用跳跃连接将编码器和解码器中的特征图进行拼接,结合多尺度的特征输出预测图像。作者将这个方法运用到医学图像分割中,在细胞壁分割任务中取得了很好的成绩。不仅在医疗图像分割任务中取得了很好的效果,其他基于U-Net的网络结构[18- 19]在遥感图像中的道路分割、海陆分割也取得了良好的效果。
为了让遥感图像能够更好地为人类服务,提供更实时、更准确的地物信息,本文提出了一种基于卷积神经网络的语义分割方法来对遥感卫星图像中的地物进行分割,设计了名为W-Net的语义分割网络。该方法通过裁剪遥感卫星图像,同时进行数据增强,生成训练和测试数据,然后使用过采样方法解决小样本的问题;接着构建网络结构,调整合适的参数进行网络训练;之后评价网络的分割精准度,并与其他的网络结构进行对比;最后使用训练好的网络进行遥感卫星图像分割。
1 网络结构
本文对U-Net进行改进,并提出新的网络W-Net,来实现遥感卫星图像的语义分割。该网络使用了特征金字塔网络[20]来充分利用网络中的高层特征的语义信息和低层特征的位置、细节信息,并且使用了全局上下文结构[21],在几乎不增加计算量的情况下提升网络的分割效果。相比U-Net,W-Net在减少了网络参数的情况下仍能获得充足的感受野,提高了网络模型的学习能力,使得网络能够在速度和性能中取得很好的平衡。
1.1 特征金字塔
在深度卷积神经网络中,浅层的网络更关注于细节信息,高层的网络更关注于语义信息,而高层的语义信息能够帮助我们准确地检测出目标[20]。大部分的网络都是使用最后一层卷积后的特征图进行预测,与此同时,其他层中的特征被忽视。在特征提取阶段,低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。为了充分利用神经网络中每一层的特征信息,Lin等[20]提出了特征金字塔网络结构(FPN),利用网络中每一层的信息来提升目标检测任务的准确率。该方法不仅仅限于目标检测任务,在其他的任务(图像分割、图像分类等)中也同样能够提升准确率。文中设计的分割网络中也使用了FPN结构,并且使用多尺度的特征进行训练。
1.2 全局上下文
近年来,注意力机制因其能够增强神经网络的表征能力而受到了广泛关注与研究。注意力机制让神经网络能够从大量信息中快速筛选出有价值的信息,提升网络的识别速度和准确率。Cao等[21]提出了一种新的全局上下文建模网络(简称 GCNet),GCNet结合了Non-local Network[22]和Squeeze Excitation Network[23]的优点,在几乎不增加计算量的情况下,显著提升图像分割和目标检测等任务中的识别精准度。本文在设计的网络中使用GCNet中的全局上下文模块(Global Context Block)[21]来增强网络的分割准确率,全局上下文模块结构如图1所示。
1.3 网络结构
本文提出了一种基于U-Net的语义分割网络,该网络通过使用FPN和全局上下文模块来整合高层和低层的特征信息,提升分割能力,因整体结构呈W型,所以网络的名称为W-Net,网络结构见图2。其中,N为类别数,s为卷积的步长,d为卷积核间隔数。

图1 全局上下文模块结构Fig.1 Global context module structure

图2 W-Net网络结构Fig.2 W-Net network structure
如图2所示,W-Net分为编码器和解码器。编码器中所使用的卷积核大小均为3×3,填充策略为补零填充,以保证特征图的大小不变。网络中通常使用两个3×3的卷积来获取与5×5卷积相同的感受野[24]。在两个3×3卷积后,使用步长为2的3×3卷积用来缩小特征图大小,并进行下采样。而U-Net中使用2×2的池化进行下采样。在连接左右分支的通道中,U-Net使用了滤波器数量为1 024的两个3×3卷积连接左右分支。W-Net在3×3卷积之间添加了2个间隔数量为2的3×3空洞卷积[25],滤波器数量为512,以减少网络的参数量和计算量。使用空洞卷积是因为连接左右分支的特征图的大小为原图的1/16,为了减少位置信息的丢失,便使用空洞卷积来增大感受野。U-Net中的图像还原分支类似一个自下而上的FPN结构,在W-Net中自下而上的FPN结构中使用步长为2的反卷积进行上采样,上采样后的特征图与左侧中对应的特征图进行拼接。W-Net在U-Net的右侧添加了一个自上而下的FPN结构。与特征提取分支中相同,自上而下的FPN结构中使用步长为2的卷积进行下采样,下采样后的特征图与左侧对应特征图进行拼接。自上而下的FPN结构中只进行了3次下采样,特征图的大小缩小到原来的1/8。拼接后的特征图使用滤波器数量为256的3×3卷积进行特征提取。自上而下的FPN中,拼接之后的特征图使用1×1的卷积和Softmax输出大小分别为256×256、128×128、64×64、32×32的4个特征图,类似于Google Net[26]的辅助分类器,只用于训练过程,对应的损失函数权重为0.1。解码器中的结构相对简单,首先使用1.2节中提到的全局上下文模块整合全局上下文信息,然后使用8倍的上采样将特征图的大小恢复到原图的尺寸,得到的特征图作为最终的预测结果;再使用Softmax输出分割后在每一类中的概率。W-Net网络结构看起来比U-Net复杂,但是实际上网络参数比U-Net少500 000。
2 实验
2.1 实验数据
文中实验数据来自2017年卫星影像的AI分类与识别竞赛中的“基于深度学习的遥感影像地表覆盖、地表利用分类”主题(https://www.datafountain.cn/competitions/270)。该数据集为2015年某地区的高分辨率遥感影像以及遥感影像人工标注出来的标注图像。其中遥感影像的空间分辨率为亚米级,光谱为可见光波段(R、G、B),标注图像为单通道图像,标签为0-4。数据集中包含5张训练图像及其对应的标注图像和3张测试图像及其对应的标注图像。图像中包含4种典型土地利用类型植被(记为1)、建筑(记为2)、水体(记为3)、道路(记为4)以及其他类别(记为0),实验图像中各类别的分布统计结果如表1所示。
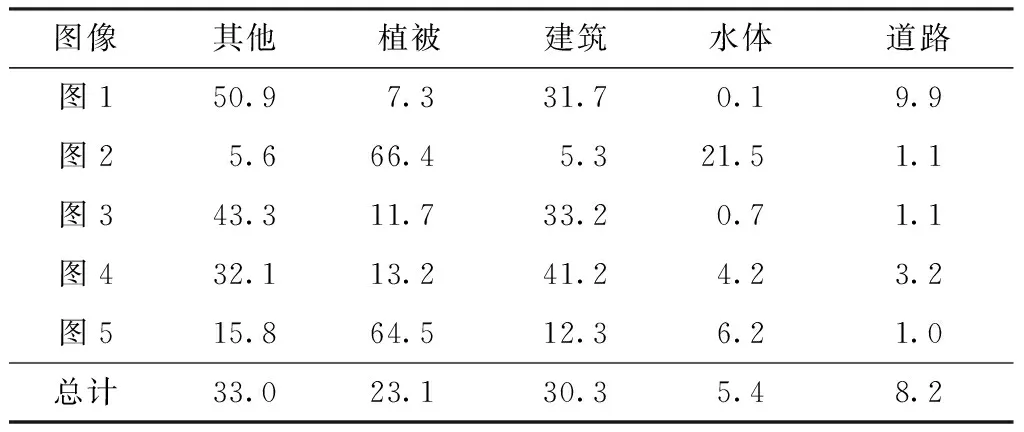
表1 遥感卫星图像中各类别的分布统计
2.2 数据的生成与增强
训练集中的5张训练图像的大小并非一致,其中两张尺寸为7 969像素×7 939像素,其余3张分别为3 357像素×6 116像素、4 011像素×2 470像素和5 664像素×5 142像素。图像尺寸过大则不适合直接作为神经网络的输入,文中设计的网络输入为256像素×256像素,因此将训练数据中的遥感图像和标注数据集裁剪成256像素×256像素大小的图像作为网络的输入和输出,如图3所示。

深度学习相对于传统机器学习的优点就是,能够从大量的数据中学习图像特征达到理想的识别结果。为了增加网络模型的泛化能力和鲁棒性,除了扩充数据集以外,还可以通过数据增强的方式增加训练集的多样性[27]。同时,数据增强也可以增加噪声数据,以提高网络的鲁棒性。常用的数据增强方式主要有翻转、旋转、缩放、裁剪、平移、随机增噪等。在机器学习中,数据增强被分为两类:一类是离线增强;另一类是在线增强。离线增强是直接对数据集进行数据增强,生成更多的训练数据;在线增强为在训练过程中获取图像批次后,对这一批图像进行数据增强。根据表1中的类别统计结果,在训练图像中,道路和水体的占比较少,因此对训练集进行过采样,额外增加包含道路和水体的图片进行训练。
文中实验采取的数据增强方法为随机翻转(将图像和标注图像进行上下翻转、左右翻转)、缩放裁剪(真实裁剪大小为128像素×128像素、256像素×256像素、512像素×512像素,再将裁剪图像大小恢复到256像素×256像素)、噪声扰动(随机添加噪声点),得到图3中的实验图像。图3中已将标记图像变换为RGB 3通道图,植被为暗绿色(0,139,0)、建筑为粉红色(255,106,106)、水体为蓝色(0,0,205)、道路为灰色(205,201,201)以及其他类别为黑色(0,0,0)。
2.3 模型评估
2017年卫星影像的AI分类与识别竞赛采用的评估方案为分类总精度(OA),反映预测值和实际标注值相等的数量(记为TP)占整个样本数量(记为N)的比例。计算公式如下:
(1)
在测试集上对模型的性能进行测试。使用训练好的网络模型预测得到预测图像。计算标注图像和预测图像的重叠度(IoU)[28]。IoU值是语义分割、目标检测等方向的标准度量,计算公式如下:
(2)
式中,IP表示预测图像,IT表示标注图像。
对于多类别的语义分割模型,通常使用平均重叠度(mIoU)来反映模型的识别精准度,即分别计算每一类的IoU,再取平均值。计算公式为
(3)
式中,IoUi表示第i类的IoU分数。
3 实验分析
本文实验代码基于Python3.6实现,使用深度学习框架Keras构建网络模型。网络训练过程中使用的优化器为Adam优化器,初始学习率为0.000 1,β1=0.9,β2=0.999。训练图像为20 000张256像素×256像素的图像,并且使用在线增强。训练过程中每个批次只训练4张图片。训练次数为50,训练过程中只保存最好的模型。网络中Dropout的概率为0.1。损失函数为多分类交叉熵函数[29]:
(4)
式中:n为图像中像素点总数;y为图像中像素点x期望的输出;a为网络实际输出。
3.1 网络对比
实验选取了3个目前流行的语义分割网络和两种遥感卫星图像分割专用的网络与本文提出的语义分割网络进行对比,分别为U-Net[11]、 SegNet[16]、DeeplabV3+[25](其中Deeplab V3+使用的特征提取骨架网络为MobileNet V2[30])、遥感图像分割网络ELU-Net[7]和道路分割网络Deep Res U-Net[19]。每个网络训练50轮,使用50轮中最好的网络模型进行识别,网络分割结果如图4所示。

图4 各种网络模型的分割结果Fig.4 Segmentation results of various network models
从分割结果图中可以发现,W-Net在道路的分割上较其他网络更为优秀,更接近于真实标注,分割细节较其他网络也更加精确。为了获取直观的网络模型对比结果,使用各个网络的最优模型在测试集上进行模型评估,评估图像为1 000张256像素×256像素的测试图像。记录每一类的IoU、mIoU和平均精度,得到的评估数据如表2所示。
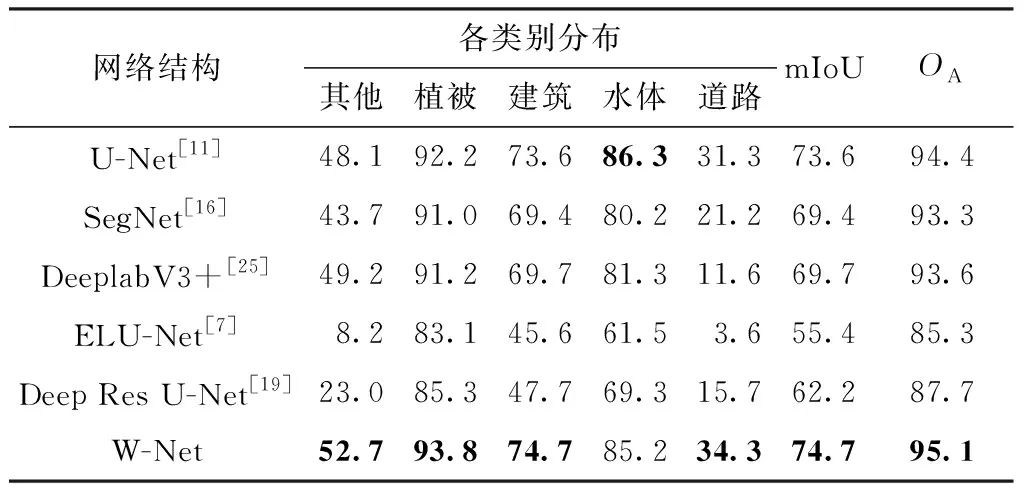
表2 各个模型在测试集上的分割结果对比
由表2可见,本文提出的W-Net网络结构的mIoU和OA均高于其他3种流行的网络结构。相较于U-Net[11]网络,W-Net的mIoU提升了1.1个百分点,分类总精度提升了0.7个百分点。除水体外,其他类别的识别IoU均提升了约1到4个百分点。水体分割的IoU较U-Net低了1.1个百分点。与SegNet[16]和DeeplabV3+[25]相比,W-Net在各类别中的IoU均为最高。W-Net在遥感卫星图像分割任务中的mIoU比SegNet高了5.3个百分点,分类总精度提升了1.8个百分点;与DeeplabV3+相比mIoU提升了5个百分点,分类总精度提升了1.5个百分点。同时,将W-Net与用于遥感图像分割的网络结构进行对比。文中构建了苏健民等[7]提出的网络,并在与本文实验相同的环境下进行试验,发现ELU-Net网络结构较小,只需少量的训练批次,网络的训练结果达到饱和(31次)。通过对比31次的实验结果,W-Net的mIOU为72.1%,分类总精度为94%,均高于ELU-Net。Deep Res U-Net[19]在遥感图像道路分割任务中能够获得很高的精度,但是在遥感卫星图像分割任务中Deep Res U-Net并未取得很好的分割精度。
W-Net在5种网络中除了水体分割的IoU为第2名外,其他指标均为第1。但是从分割图中可见,W-Net对于水体以及其他类别的分割细节更接近标注图像的风格。综上所述,W-Net的学习能力比其他网络更强。
3.2 模型验证
为了验证W-Net中使用的特征金字塔结构和全局上下文模块对分割结果是否有提升,文中尝试分别使用特征金字塔结构和全局上下文模块进行实验,并尝试不使用特征金字塔结构和全局上下文模块进行实验,网络训练次数均为50,选取最好的网络模型进行测试,得到的实验结果如表3所示。

表3 添加FPN和GC模块的可行性验证Table 3 Feasibility verification of adding FPN and GC modules
其中,W-Net中的基础网络结构与U-Net网络结构相似,区别在于为了降低网络的参数量和计算量,W-Net中的基础网络在最底层使用的卷积通道数为512,而U-Net中使用的通道数为1 024。
从表3数据可以发现,使用全局上下文模块对分割效果的提升较大,mIoU提升了约10个百分点,分类总精度提升了5个百分点;使用FPN时mIoU提升了约5个百分点,分类总精度提升了2.5个百分点。U-Net结构类似于一个由下而上的特征金字塔结构,本文设计的网络在U-Net结构右侧添加一个由上而下的特征金字塔结构。我们发现这样的结构在PANet[31]中也使用过,该结构能够充分利用高层和低层的图像特征信息提升网络的分割和检测结果。
3.3 高分辨率图像
由于CPU大小的限制,文中将高分辨率图像的分割转化为分块处理低分辨率图像,然后再重新拼接完成高分辨率图像的分割。
此次实验中使用的图像大小为1 024像素×1 024像素和2 048像素×2 048像素,通过滑动窗口得到256像素×256像素大小的图像,之后通过网络进行分割,然后拼接分割结果得到最终高分辨率图像的分割结果,并将W-Net与经典语义分割网络SegNet、U-Net以及用于遥感图像分割的ELU-Net、Deep Res U-Net对比。实验采用的网络模型为3.1节中训练50次得到的最好的网络模型,得到的实验结果如表4所示。

表4 高分辨率图像分割结果Table 4 High resolution image segmentation results
由表4可见,1 024像素×1 024像素分辨率的遥感卫星图像识别结果中,W-Net取得了47.15%的mIoU和95.06%的分类总精度,在5种网络模型中均为最高。对于2 048像素×2 048像素大小的遥感图像分割,W-Net仍然取得了最高的mIoU和分类总精度。
4 建筑物分割
4.1 实验分析
为了验证模型的通用性,文中在Massachusetts建筑物数据集[32]上进行实验。Massachusetts建筑物数据集是一个用于建筑物分割的大型数据集。该数据集由151组航拍图像和相应的单通道标签图像组成,数据集中图像大小均为1 500像素×1 500像素。其中,训练图像为137张,测试图像为10张,验证图像为4张。标注图像只包含建筑物。通过随机裁剪并进行数据增强生成256像素×256像素大小的实验图像,建筑物图像如图5(a)所示,标注图像如图5(b)所示,其中红色像素代表建筑物区域,黑色像素为背景。
建筑物分割实验细节与遥感卫星图像分割实验相似。建筑物分割实验训练过程中每个批次训练图像数为4张,训练次数为10轮,每一轮训练10 000个批次。测试图像为3 000张256像素×256像素大小的图像。
由于分割对象只包含建筑物,因此建筑物分割任务为二分类任务,识别图像中像素点是否为建筑物。网络训练过程使用的loss函数为二分类交叉熵损失函数[29](BCE loss):
(1-t[i])ln(1-o[i]))
(5)
式中,t[i]为标注图像中像素点i的值(值为0或1),o[i]为预测图像中像素点i的值(为0到1之间的值)。
4.2 模型评估
对于二分类模型,通常使用查全率[33](R)和查准率[33](P)反映模型识别的准确程度和精准程度。
P=Tp/(Tp+Fp)
(6)
R=Tp/(Tp+Fn)
(7)
式中:Tp为识别正确的像素数量;Fp为未识别的像素数量;Fn为识别错误的像素数量。
机器学习中通常使用F1值[33]来综合查全率和查准率反映模型的效率:
F1=2PR/(P+R)
(8)
4.3 实验对比
此次实验选择U-Net[11]、ELU-Net[7]、 Deep Res U-Net[19]与W-Net进行对比。每个网络训练10次,选取最好的模型进行测试。网络的分割结果如图5所示,从图5中可以发现,对于小建筑物(别墅)的分割各网络区别不大;对于大建筑物(厂房、商场)的识别,W-Net的分割结果更加完整、精细。文中对3 000 张256像素×256像素的实验数据集进行了分割实验,实验结果如表5所示,并对10张1 500像素×1 500像素高分辨率的建筑物图像进行实验,得到表6的实验数据。

图5 不同网络在Massachusetts建筑物图像上的分割结果Fig.5 Massachusetts building segmentation results of various network models
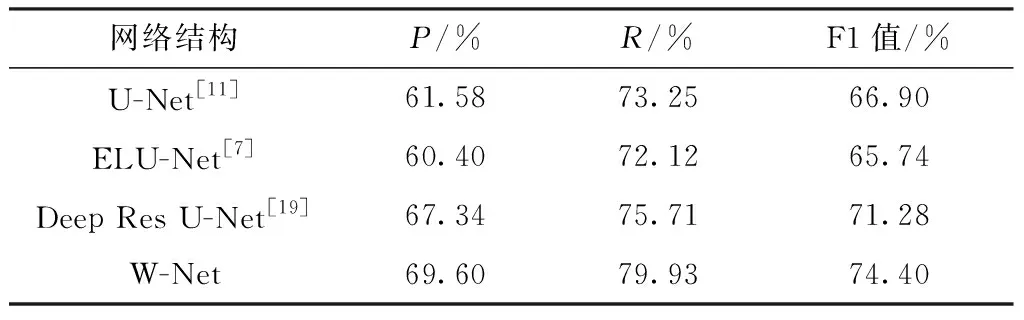
表5 Massachusetts建筑物分割结果Table 5 Massachusetts building image segmentation results
从表5中可见,在3 000张256像素×256像素建筑物图像分割实验中,W-Net取得了69.60%的查准率、79.93%的查全率以及74.40%的F1值,3项评价指标在对比网络中均为最高。
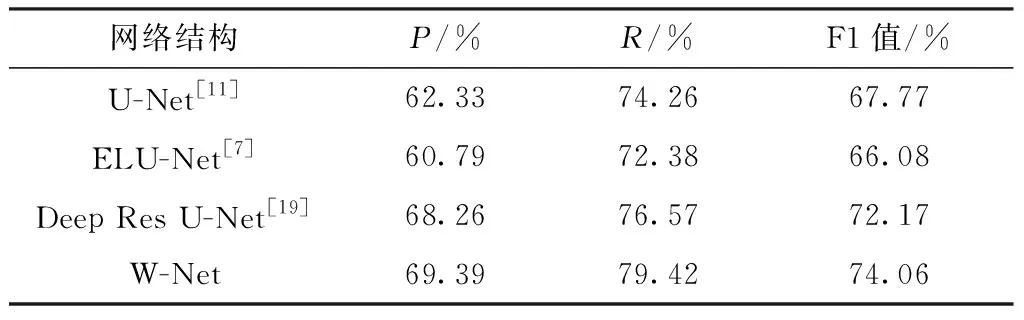
表6 Massachusetts建筑物高分辨率分割结果
由表6可见,在高分辨率建筑物图像的识别实验中,W-Net也取得了最好的分割结果。
5 结论
本文提出了一种基于深度学习的遥感卫星图像分割方法。该方法使用特征金字塔网络和全局上下文模块对U-Net网络进行改进,提出名为W-Net的语义分割网络,并通过裁剪高分辨率的遥感卫星图像,生成实验数据,同时使用过采样降低样本不均衡带来的影响,在网络训练过程中使用随机失活和批标准化提升网络性能和稳定性。在遥感卫星图像分割任务中,W-Net的分类总精度为95.1%,平均重叠度为74.7%。通过实验与3种流行的语义分割网络、两种遥感卫星图像分割专用的网络进行对比,W-Net的分割准确率和平均重叠度在6种网络中均为最高。并且通过实验证明了在W-Net中使用的特征金字塔结构和全局上下文模块可以提升网络的图像分割效率。对于高分辨率的遥感卫星图像,使用影像重叠策略进行识别,可提升整体的识别正确率。在1 024像素×1 024像素、2 048像素×2 048像素大小的高分辨率图像分割中,W-Net取得了最高的分割准确率,并且在建筑物分割任务中W-Net也取得了最优的分割结果,证明了网络模型的通用性。
本文提出的方法能准确分割遥感卫星图像中的地物类别,可行性高。后续研究将尝试继续提升该方法的分割准确率,以及挑战更复杂的数据集。
猜你喜欢
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
北京航空航天大学学报(2021年9期)2021-11-02
电子制作(2019年13期)2020-01-14
红领巾·萌芽(2019年8期)2019-08-27
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
长江学术(2016年4期)2016-03-11
CHIP新电脑(2016年3期)2016-03-10
人间(2015年21期)2015-03-11
