
基于多视图融合的微博垃圾用户检测方法
2020-02-05 12:50杨晓晖梁笑
华南理工大学学报(自然科学版) 2020年12期
杨晓晖 梁笑
(河北大学 网络空间安全与计算机学院,河北 保定 071000)
近年来,在线社交网络(OSN)如Facebook、Twitter、微博的出现满足了互联网用户与朋友、家人以及具有相似兴趣爱好的人保持联系的需求[1]。但微博给人们的生活带来便利的同时也给垃圾用户提供了良好的发展平台。垃圾用户利用微博发布大量垃圾信息或请求,甚至涉及恶意URL链接、虚假广告、网络钓鱼、欺诈、色情等内容,给用户的财产安全带来了巨大的隐患;此外,无用信息占据网络资源,消耗了大量的网络负载。以上问题的存在吸引了大量研究人员致力于消除微博垃圾用户所带来的负面影响,试图维护社交网络的安全和改善用户的使用体验。
早期的研究方法大多基于某一方面的信息即单一视图对用户进行表征,但由于垃圾用户使用的策略多种多样且不断更新,因此仅依靠单一视图的信息越来越难以应对,检测性能十分受限。目前的方法大多基于用户来自不同方面的信息即多视图信息,在一定程度上提高了表征用户的能力。这些方法从不同视图中提取特征,并将它们集成作为分类器的输入以区分垃圾用户和正常用户,但仍存在信息考虑不完整和特征挖掘不充分的问题。它们在提取特征时只注重用户自身而未充分考虑用户粉丝及用户在社交网络中所处的环境,垃圾用户可以通过更新策略避开与其自身活动和属性相关的特征进而逃避检测,但是依赖其粉丝和所处社交环境的特征却难以躲避。此外,目前基于多视图的方法在融合来自不同视图的特征时未考虑各视图的特征所具有的不同的数据特性,并且使用固定的融合策略,无法及时适应垃圾用户的变化。
为了解决上述方法中存在的缺点,本文提出了一种新的基于多视图融合的方法。该方法首先从3个不同视图中提取特征,设计出一套新颖的用户表征策略;接着构建基于线性加权函数的多视图融合决策模型,为每个视图分别学习一个基分类器,将来自各视图的分类结果进行线性加权融合,通过最小化近似误差求得最优融合系数,进而得到最终的分类结果。
1 相关工作
为解决社交网络中垃圾用户这一复杂并且不断演化的问题,研究者们提出了很多方法。张宇翔等[2]对微博中垃圾用户的检测方法进行了深入的研究,通过将不同的特征选择方法与不同的分类器组合得出,特征组的选择较分类器的改进更为重要;LEE等[3]和Stringhini等[4]在社交网络上创建并部署蜜罐账户来观察垃圾用户的行为,并提取特征集用以区分正常用户和垃圾用户;Cresci等[5]受到生物学对应物的启发,将社交网络中的用户行为以字符序列编码的形式呈现出来,然后定义这种数字DNA序列的相似性度量,以对一组正常用户和垃圾用户进行区分;Amleshwaram等[6]新提出了15项基于消息内容的特征来检测Twitter中的垃圾用户,并对这些垃圾用户进行聚类来检测垃圾用户的活动;Tan等[7]提出了一种方法,该方法更加重视被攻击者入侵并在其发布的内容中注入恶意链接的被攻击用户的原始内容。另外,一些研究者使用基于交互或社交网络图的方法检测社交网络中的垃圾用户。Hu等[8]利用用户的网络结构来训练优化模型,比传统方法能更准确地识别垃圾用户;Thomas等[9]指出,现在的垃圾用户大多不参与或很少参与正常的社交活动,但会通过主动关注别人和在热门话题下发表垃圾评论来吸引普通用户点击;Bindu等[10]针对垃圾用户利用社区结构向正常用户传播垃圾信息的问题,提出一种名为SpamCom的无监督方法来检测Twitter中由垃圾用户所组成的社区。以上方法多基于单一视图的信息对用户进行表征,在逐渐复杂化的垃圾用户活动中,方法所覆盖的信息不够全面,容易形成识别漏洞。
目前,基于多视图的方法结合了用户来自不同方面的信息,且取得了一定程度上的成功。Zheng等[11]从爬取到的微博数据集中研究与消息内容和用户行为相关的主要特征,并将其应用于基于SVM分类器的方法中;Yu等[12]引入半监督矩阵分解模型,利用微博内容矩阵、社交关系矩阵对垃圾用户进行过滤;Shen等[13]将来自微博内容的信息和社交网络信息结合,集成到分类模型中,设计出一种广义的社交网络垃圾用户检测模型;Liu等[14]通过对用户行为、微博内容、关注网络和转发网络的综合建模,提出了一种新的学习框架,用于协同检测垃圾微博和垃圾用户;Li等[15]提出了一种基于半监督的深度学习方法,将用户个人信息和微博内容信息一起嵌入到神经网络的输入层,采用半监督的方法对网络进行训练,降低了标注数据的成本。上述多视图方法在表征用户时,虽考虑了来自不同视图的信息,但其关注的焦点仍多集中于用户自身。 Fazil等[16]发现垃圾用户可以通过调整自身的行为以模仿正常用户,进而逃避检测,但与其粉丝行为和其在社交网络图中的邻域(社区)相关联的特征却难以逃避。文本在提取特征时着重分析了用户粉丝和其所在的社区的特点,引入了粉丝比率、粉丝平均双向连接率、基于社区的双向连接率、基于社区的集群系数等新特征。此外,为更有效地融合来自各视图的信息,文中构建了基于线性加权函数的融合决策模型,其中用于融合各视图分类结果的权重不是固定的,能够随着垃圾用户所用的策略变化而及时调整。
2 特征提取
通过研究现有文献的观点,结合近几年垃圾用户特征的变化,本文选取了13个特征,其中包括6个新定义的特征和7个在现有方法中广泛使用并证明有效的特征。特征集由来自3个视图的4类特征构成:即基于用户行为的特征、基于微博内容的特征、基于社交关系的交互特征和社区特征。表1中简要介绍了这些特征的来源及其类别,其中来源列的“新”指本文新引入的特征,这些特征在现有微博垃圾用户检测的文献中未见应用。
2.1 基于用户行为的特征
基于用户行为的特征有3个,首先是发博间隔标准差Psd。微博中的普通用户发布微博的时间是随机的,而由程序控制的垃圾用户发布微博的时间具有高度的规律性[4],故Psd值也应明显低于正常用户。Psd由式(2)表示,其中N(u)表示观测时间内用户发布的微博数量,Bi表示第i条微博发布的时刻,I(u)表示用户在观测时间内发布微博的平均间隔。

表1 所用特征及其类别和来源Table 1 Features used and their categories and sources
(1)
(2)
其次是转发比率rR。为了以较低的成本维持账号的活跃,垃圾用户的微博通常倾向于转发别人的内容而非原创[19]。衡量用户已发布的微博中转发微博所占比例的特征rR可由式(3)表示,其中R(u)表示观测时间内用户转发微博的数量。通常情况下,垃圾用户的转发比率很高,而正常用户的转发比率较低。
(3)
第3个特征是阳光信用Yc。阳光信用等级是为了评价用户的信用度而新增的一个用户属性。根据官方的定义,这一属性能够全面评价用户的发言历史、活跃度、违规记录等用户使用微博的行为,因此将其作为区分垃圾用户和正常用户的重要依据是十分合理的。微博将用户“阳光信用”等级由低到高分为5个级别,在本文中将其映射为1-5的整数值。
2.2 基于社交关系的特征
将社交网络中用户之间的关注和被关注关系构造成有向图G={V,E},顶点集V对应用户集U,vi∈V对应社交用户ui∈U,边集E对应用户间的关系,eij∈E表示ui是uj的粉丝。
2.2.1 交互特征
第1个交互特征是粉丝比率rF。不同于正常用户,垃圾用户很难吸引他人的关注,为了快速建立起社交影响力,其不得不大量关注其他用户。定义rF用于衡量用户在信任网络中的粉丝比率,rF可由式(4)表示,其中UF代表用户u的粉丝集合,UL代表u关注的人的集合。
(4)
第2个交互特征是双向连接率rB。如果两个用户相互关注,从社交网络图的角度看,即二者之间存在双向连接。用户的双向连接率反映了用户在社交网络中的受信任程度,通常情况下垃圾用户的双向连接率很低而正常用户的双向连接率较高[14]。rB可由式(5)表示:
(5)
(6)
第4个交互特征是集群系数C。与垃圾用户相关联的用户之间大多互不相识,反映在社交网络图里即垃圾用户所对应的节点的局部聚类系数通常较低[17]。在社交网络图中一个顶点vi的邻域Ni被定义为Ni={vj:eij∈E∨eji∈E}。假定Ki是用户在社交网络图中所对应的节点vi的出入度之和,则用户的集群系数C可由式(7)表示:
(7)
2.2.2 社区特征
在社交网络中具有相似品味、喜好、地理位置等共同点的人之间具有更加紧密的交互关系,进而自动形成社交网络中的虚拟集群或社区[10]。从形式上讲,社区结构可以定义为一组紧密的顶点,它们具有较高的组内边缘密度和较低的组间边缘密度。图1展示了一个示例性的用户社交网络,其中Community1和Community2分别表示两个可能的社区结构。本文使用Python语言用于社区发现的函数包Networkx构建用户社交网络并检测社区,并提取了两个基于社区的特征。
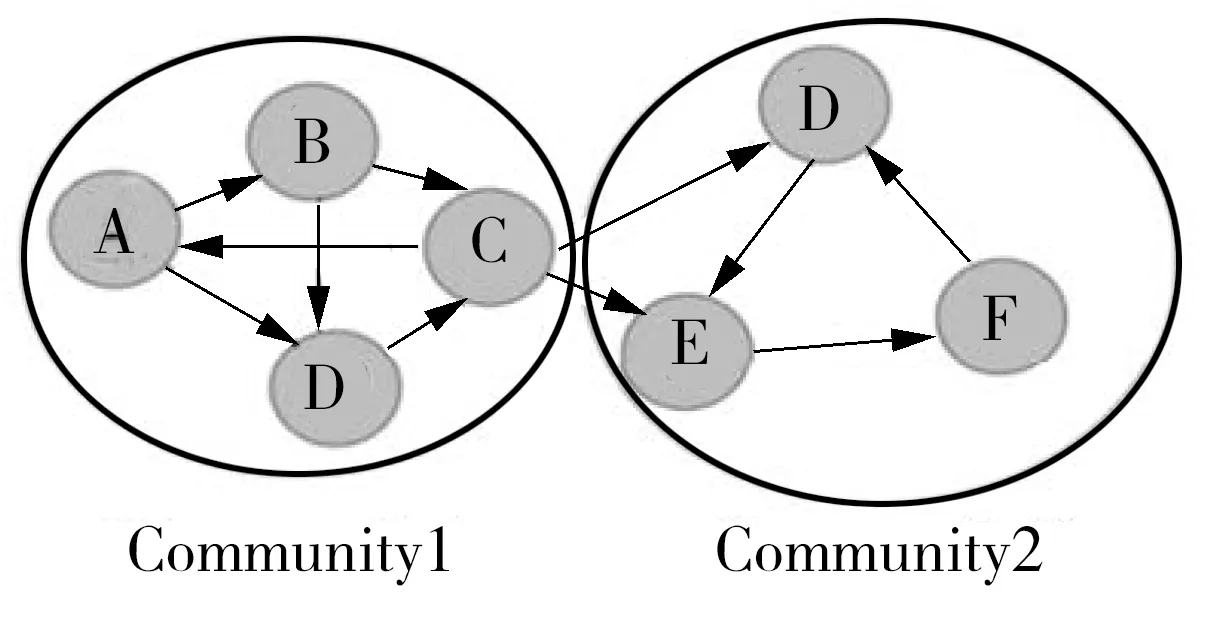
图1 社交网络示例图Fig.1 Sample graph of social network
第1个社区特征是基于社区的双向连接率rCB。同一社区内的成员通常具有相似的特性,用户的信任等级与其在社区中其他用户的信任等级相关联。用户所处社区中的其他成员的信任等级较高,最终也提高了该用户的受信任程度,反之亦然。基于以上事实,定义用户的基于社区的双向连接率rCB用于衡量用户在社区层面的受信任程度。rCB可由式(8)表示,其中M表示用户所在社区的个数,|gm|表示第m个社区中的成员总数,rB(gm(q))表示用户所在的第m个社区的第q个成员的rB值。
(8)
第2个社区特征是基于社区的集群系数CC。垃圾用户和正常用户所在的社区通常是不同的,垃圾用户所在社区的成员往往也为垃圾用户,他们彼此之间的联系很稀疏。定义用户基于社区的集群系数CC用于衡量用户所处社区内成员之间联系的紧密程度的平均值。CC可由式(9)表示,Cm为第m个社区的集群系数。
(9)
2.3 基于微博内容的特征
第1个基于微博内容的特征是平均标签数Ta。在微博中标签代表主题,其形式为#Topic#。垃圾用户频繁地在其微博中添加当下最热门的标签,使自己发布的内容被更多用户浏览,增加了欺骗的可能性[6]。Ta可由式(10)表示,其中T(u)表示所发微博中使用标签的总数。
(10)
第2个基于微博内容的特征是内容标签相似度SCT。“微博热搜”按热度实时更新当前微博标签的排名,进入热搜榜的主题在当下具有最高的关注度和浏览量。在分析数据时发现垃圾用户发布的微博中通常带有与内容完全不相关的标签。垃圾用户为增加内容的受众,在内容中添加受关注度高的标签是最简单、成本最低的方式。基于以上事实,定义内容标签相似度函数SCT,SCT可由式(12)表示,其中Si(由式(11)表示)用于衡量用户发布的第i条微博的内容与这条微博中所添加标签的相似程度。SCT的具体计算方法如下:
步骤1 提取每条微博正文中的主题标签t1,t2,…,tW;
步骤2 利用典型的概率主题模型LDA[21]计算每条微博文本中Top3的3个主题词w1、w2、w3及其对应的概率值p1、p2、p3;
步骤3 计算每条微博的内容标签相似程度:
(11)
其中Sjk表示第j个主题词与第k个标签在内容上的相似度;
步骤4 计算用户的内容标签相似度:
(12)
第3个基于微博内容的特征是平均URL数A。垃圾用户在发布的微博中频繁添加URL链接,以实现欺骗用户的目的[7]。这些链接通常会重定向到一些特定的第三方软件,以“淘宝”、“京东”等购物平台居多。衡量用户微博中使用URL链接频繁程度的特征A由式(13)表示,其中A′(u)表示用户观测时间内发布的微博中使用URL链接的总数。
(13)
第4个基于微博内容的特征是单一提及率rM。在微博中提及符“@”可用来提及用户,但该功能却被垃圾用户滥用。垃圾用户在其微博中使用“@”提及无辜用户使其成为潜在的受害者。正常用户的互动绝大多数限定在熟人之间,而垃圾用户则随机提及用户[6]。rM可由如式(14)表示,其中M(u)表示在观测时间内所发微博中使用提及符的总数,O(u)表示只被提及过一次的用户的数量。rM值越接近1证明该用户为垃圾用户的嫌疑越大。
(14)
3 多视图融合的垃圾用户检测方法
3.1 方法概述
基于多视图融合的垃圾用户检测方法(MVFM)的整体框架如图2所示。首先,按照第2部分中介绍的方法从用户行为、社交关系、微博内容3个视图中提取特征,并分别构造特征集。然后,应用多视图融合决策模型,将提取到的来自3个视图的特征分别用于训练相应的基分类器Classifier1、Classifier2、Classifier3,将输出转化为概率型,并对各基分类器的输出进行融合得到最终的分类结果。
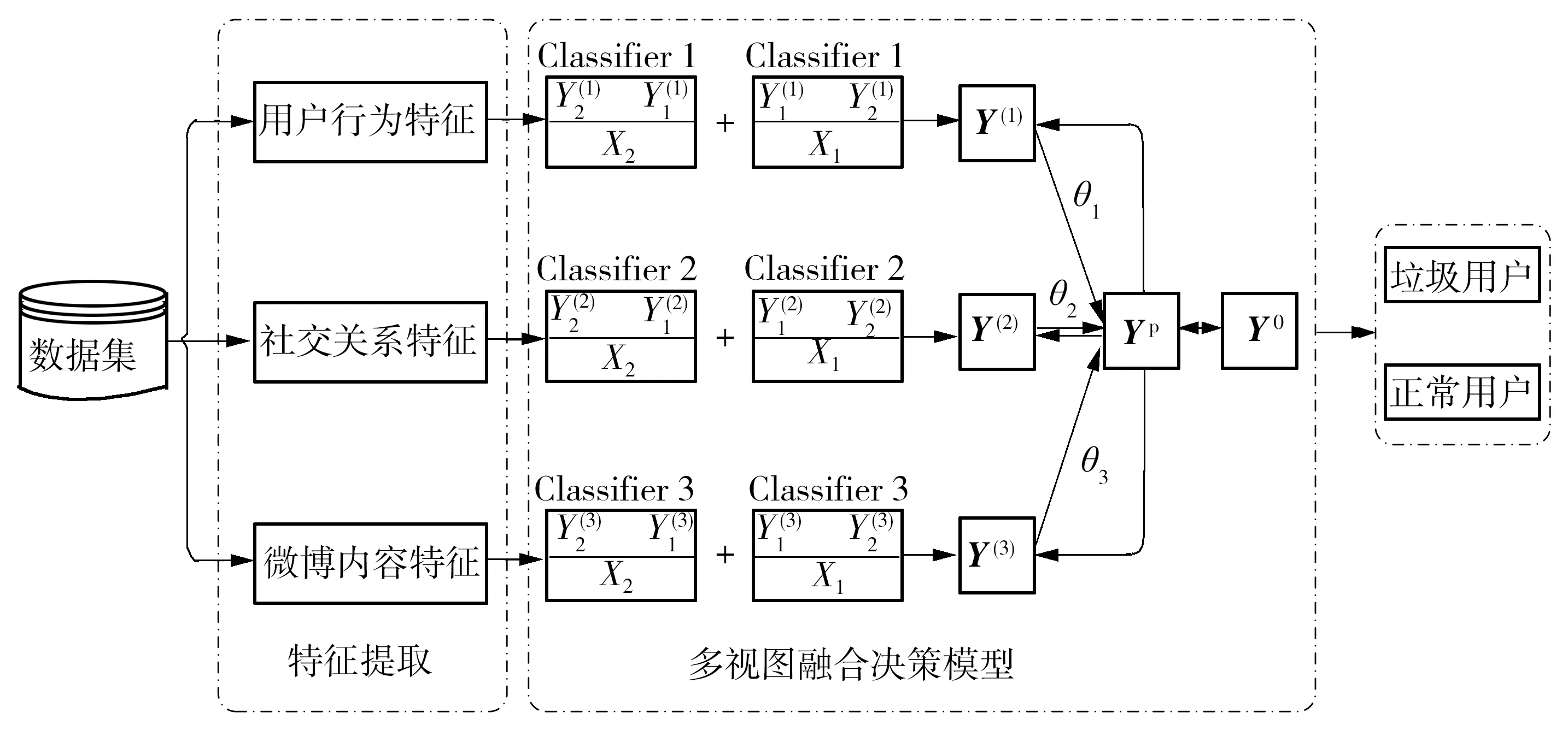
图2 基于多视图融合的垃圾用户检测方法整体框架图Fig.2 Overall framework of spammer detection method based on multi-view fusion
3.2 多视图融合决策模型
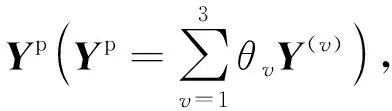

定义基于融合的函数,以获取最终的分类结果:
(15)
(16)
则θ的求解问题转化为
argθminL(θ)
(17)
令
P=[p1p2…pn]∈Rn×3,
则上述优化问题可表示为
于是式(17)可转化为
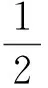
(18)
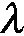
在上述分析的基础上将融合系数向量θ学习过程总结到算法1中。
算法1
输入:经过预处理的数据集X;X的真实标签Y0;3个不同视图对应的基分类器Classifier1、Classifier2、Classifier3。
输出:融合系数向量θ。
1)将X分割为X1和X2
2)for ∀Classifier do
6)End for
7)Initialization:
10)Updateθ
11)Returnθ
4 实验
4.1 数据集的获取
为了更加准确地验证本文所提方法的有效性,准备了2套数据集,具体情况如下。
(1)爬虫数据集
新浪微博官方API仅允许下载授权账户的近期信息,为收集足够的研究所需数据,本文设计了爬虫程序,主要步骤如下:
步骤1 构建一个包含200个账号的种子用户集。其中,100个正常用户来自生活中的同学、亲人和朋友;另购买100个垃圾用户,并且统一关注了指定的账号。
步骤2 依次爬取种子用户的粉丝列表和关注列表,将获取到的23 269个用户ID连同种子用户一同存入用户ID列表。
步骤3 对用户ID列表中的每个账号爬取其粉丝列表、关注列表、用户基本信息;此外,抓取其在2019年5月1日至5月31日所发布的全部微博。
步骤4 邀请10名计算机领域的研究生对爬取到的数据进行人工标注,标注过程中综合考虑每个账号来自各方面的信息,且仅保留来自10名标注者标注结果一致的账号数据。结果得到14 620个正常用户和4 105个垃圾用户,为了实验数据的平衡,从标注结果中随机选取4 100条正常用户数据,称采用此方法得到的数据集为数据集1。
(2)公共数据集
社交网络研究领域的公共数据集[22]包含了170万个账号的用户信息、微博信息以及社交关系信息,但该数据集不包含用户的“阳光信用”这一信息。该数据集在原文献中被用来进行转发行为预测,故并未对用户的属性进行标注。从原数据集中随机选择1万条用户数据按照数据集1构造过程中步骤4的方法进行人工标注,结果得到5 543个正常用户和1 817个垃圾用户,为了保持数据的平衡,从标注结果中随机选取1 800条正常用户数据,称采用此方法得到的数据集为数据集2。
4.2 特征分析
为分析新定义特征对正常用户和垃圾用户的区分能力,设计了如下两个实验,以从定性和定量两个角度证明引入6个新定义特征的合理性。考虑到数据的完整性,选择4.1节中的数据集1(正常用户4 100个、垃圾用户4 105个)作为特征分析实验的数据来源。
对本文新增的特征进行显著性检验:分别对新定义的特征进行双尾t检验(平均值差异性检验的方法)[23],在t检验的零假设中,假设正常用户和垃圾用户在新定义的特征上的总体均值没有明显差异;而在备选假设中,假设两者在新定义的特征上的总体均值差异明显。计算本文新定义的6个特征的t检验值,并与5%的显著性水平的t检验的临界值进行比较(查表知该值为1.96),结果如表2所示。
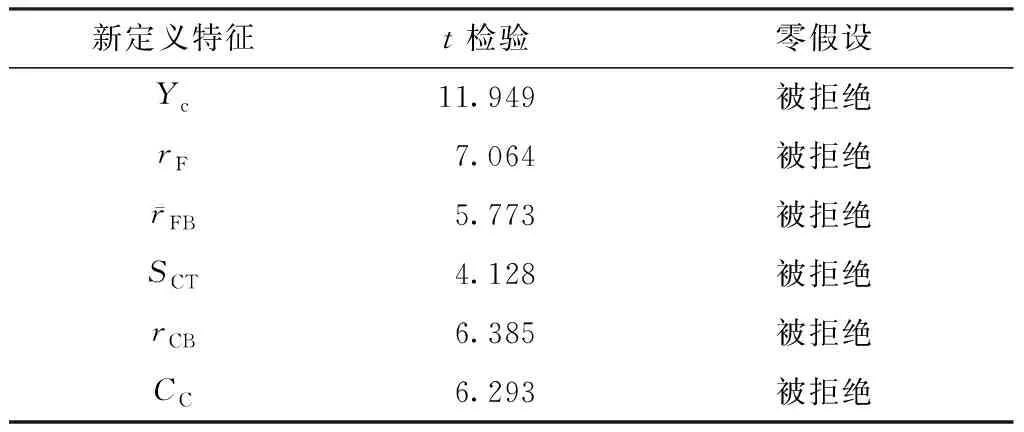
表2 显著性检验Table 2 Significance test
分析表2可知,本文提出的6个新特征的零假设均为被拒绝,因此可以得出结论:正常用户与垃圾用户在新提出的6个特征上的平均值的差别显著。
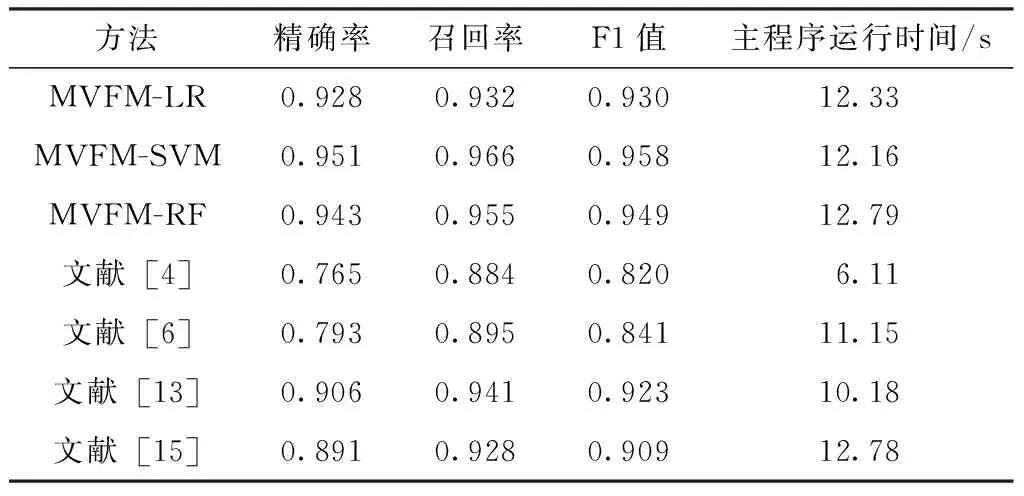
累积分布函数(CDF)能够完整描述一个随机变量X的概率分布,定义为:FX(x)=P(X 各评估实验均在Pycharm上利用Python语言实现,实验运行环境为Windows 10操作系统,英特尔酷睿i5-10210U@4.2 GHz处理器,12 GB内存。 4.3.1 评价指标选取 借鉴相关研究,选取精确率(P)、 召回率(R)和F1值对方法的性能进行评估,并着重分析垃圾用户的识别情况。其中精确率和召回率是机器学习领域中用来评价准确性的指标,F1值是精确率和召回率综合表现的评价指标,各指标定义如下。 精确率表示垃圾用户被正确分类的比例,由式(19)定义,其中TP为垃圾用户被正确分类的个数,FP为被错误分类为垃圾用户的正常用户个数。 (19) 召回率表示全部垃圾用户中被检测到的比例,由式(20)定义,其中FN为被错误分类为正常用户的垃圾用户个数。 (20) F1值表示精确率和召回率的调和平均值,由式(21)定义: (21) 4.3.2 有效性及对比 为了验证文中所提方法的效果设置了如下实验:分别选择Logistic Regression、SVM、Random Forest作为本文所提方法(MVFM)中的基分类器。此外设置了4组对比实验:两个传统的基于单视图的方法[4,6]、一个基于多视图的有监督检测方法[13]和一个基于多视图的半监督检测方法[15]。使用4.1节中的两个数据集作为上述实验组和对比组的数据来源,采用10折交叉验证的方法对数据集进行划分,以保证每个实例在训练和测试过程中都能参与。每组实验独立重复进行10次,取数据的平均值,实验结果列于表3和表4中,其中MVFM-SVM、MVFM-LR和MVFM-RF分别为选择SVM、Logistic Regression、Random Forest为文中所提方法基分类器的方法。 表3 来自数据集1的实验结果Table 3 Experimental results from dataset 1 如表3所示,使用SVM作为基分类器的实验组在精确率、召回率和综合评价指标F1值上均在3个实验组中位列第一,且较对比组有较大的优势;使用Random Forest作为基分类器的实验组在各评价指标上略低于MVFM-SVM,但明显优于其他组,其F1值排在第2位;使用Logistic Regression作为基分类器的实验组在召回率上低于文献[13]的方法,但在精确率上仍高于全部对比组,其F1值排在第3位。对比组方面,基于单视图方法的整体性能明显低于其他方法,说明当前随着微博上垃圾用户所用技术的提高,其逃避检测的能力越来越强,传统方法中仅依靠一个视图的信息对用户进行表征的方法已经很难适应。基于多视图方法的对比组的检测性能较传统单视图方法有了很大的提升,但与本文方法仍有差距。文献[13]方法仅将基于微博文本和社交关系的信息单独处理再进行串联拼接,没有考虑用户行为的信息;文献[15]中方法虽然仅需要极少量的标注数据就能够完成检测,但半监督的方法难免会引入标记错误的数据,影响算法的精度。 表4 来自数据集2的实验结果Table 4 Experimental results from dataset 2 如表4所示,除3个实验组外其余各对比组的结果较表3中的结果均有一定提升,其原因为数据集1中的数据为最新的数据,新型的垃圾用户所用的技术更为先进,逃避检测的能力更强。此外,由于数据集2中缺少微博官方提供的“阳光信用”这一重要的特征,实验组的性能受到了一定程度的影响,但MVFM-SVM、MVFM-RF、MVFM-LR的综合评价指标F1值仍然排在前3位。基于多视图的文献[13]和[15]中方法的F1值分别达到了0.923和0.909,略低于本文方法,而基于单视图的方法的表现仍然最差。 综上所述,实验证明本文提出的基于多视图融合的微博垃圾用户检测方法能够对垃圾用户进行有效检测,且与之前的方法相比拥有更高的精确率和F1值。此外,对比3个选用不同基分类器的实验组的结果,可知基于SVM算法的性能最优,故在后述实验中均使用SVM作为所提方法的基分类器。 4.3.3 稳定性测试 为验证所提方法的稳定性,设置了如下实验:在最新的爬虫数据集上随机选择垃圾用户和正常用户,按照1∶1、1∶2、1∶5、1∶10的比例构造实验数据。选择SVM算法作为本文方法中的基分类器,对比组的设置和4.3.2节相同。此外,为了更直观地进行对比,使用F1值作为实验的评价指标,结果见表5。 表5 不平衡数据集上的实验结果Table 5 Experimental results on unbalanced data 分析表5可知,当降低实验数据中垃圾用户的比例时F1值也会随之降低,这种现象在基于单视图的方法中表现得最为明显。本文方法在各组数据上的表现均为最优;另外还对比了不同方法在各组数据上F1值的变化情况,通过计算标准差可知本文方法在处理不平衡数据集时的性能表现更加稳定。 4.3.4 消除测试 为评估不同视图特征对所提方法性能的影响,文中进行了消除测试[24]。分别在多视图融合决策模块中移除一个视图,观察结果的变化情况。实验在最新的爬虫数据集上进行,选取SVM算法作为本文方法中的基分类器。运行程序3次,结果如图4所示。其中,Ⅰ表示从完整模型中去掉来自行为视图的信息,Ⅱ表示从完整模型中去掉来自社交关系视图的信息,Ⅲ表示从完整模型中去掉来自微博内容视图的信息。 分析图4可知,基于用户行为视图的特征对检测性能的影响最小,说明机器控制的垃圾用户使用各种算法模仿正常用户的日常使用行为,并取得了相当不错的效果,但由于“阳光信用”这一特征的缺失,F1值也下降了7.6%;基于微博内容视图的特征对整体性能的影响大于用户行为视图,因为部分垃圾用户为了实现推广内容或捕获用户的目的,不可避免地在其所发微博中添加垃圾内容;基于社交关系视图的特征对检测性能的影响最显著,该视图包含2个新定义的交互特征和2个新定义的社区特征,反映了用户的粉丝以及用户所处社交环境对于检测垃圾用户的重要性。 图4 消除对应视图后的检测结果Fig.4 Detection result after eliminating the corresponding view 本文提出了一种新的基于多视图融合的微博垃圾用户检测方法。该方法在提取特征时更加注重用户的粉丝及其在社交网络中所处的环境。此外,不同于传统基于多视图的方法,本文从3个视图中提取特征,并将提取到的特征分别用于学习一个基分类器,然后将来自不同视图的分类结果通过线性加权进行融合以检测垃圾用户,保证了融合策略能够随着垃圾用户所用策略的变化而及时更新。实验表明,与当前的方法相比本文方法具有明显的优势。为对比不同视图特征对分类结果的影响,文中还设计了消除测试,结果显示基于用户社交关系视图的特征对检测性能的影响最显著。然而,垃圾用户会不断改变其行为模式或更新技术以逃脱检测机制,基于批处理的方法存在滞后性,因此,接下来的工作中我们拟将文中的方法扩展到在线模式,以提高该方法的实时性和有效性。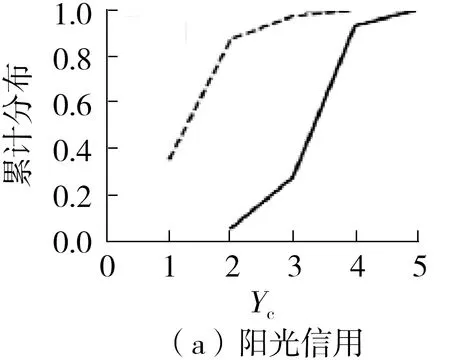

4.3 性能评估


5 结语
猜你喜欢
意林彩版(2022年2期)2022-05-03
电子产品世界(2022年4期)2022-04-21
好日子(2021年8期)2021-11-04
计算机系统应用(2021年2期)2021-02-23
第一财经(2020年4期)2020-04-14
电子技术与软件工程(2019年18期)2019-11-18
文苑(2018年17期)2018-11-09
非公有制企业党建(2017年10期)2017-11-03
电子技术与软件工程(2017年14期)2017-09-08
现代兵器(2017年4期)2017-06-02
