
一种持久性内存文件系统数据页的混合管理机制
2020-02-19 03:35陈游旻朱博弘韩银俊屠要峰舒继武
计算机研究与发展 2020年2期
陈游旻 朱博弘 韩银俊 屠要峰 舒继武
1(清华大学计算机科学与技术系 北京 100084)2(中兴通讯股份有限公司 南京 210012)
新型的非易失内存(non-volatile memory, NVM),例如相变存储器(phase change memory, PCM)[1-3]、阻变存储器(resistive random-access memory, ReRAM)[4]、3D-Xpoint等,能够提供与DRAM相近的访问性能,同时还能像磁盘一样持久性地存储数据.其中,通过内存接口与CPU相连,从而具有字节可寻址能力的非易失内存被称作持久性内存(persistent memory, PM).2019年4月,英特尔公司正式发布了基于3D-Xpoint技术的傲腾持久性内存(Optane DC persistent memory)[5],这是迄今为止全球首款大规模商用的持久性内存器件,其单条最高容量可达512 GB,访问带宽及延迟相比于固态硬盘具有一到多个数量级的提升.
持久性内存为构建高效的存储系统提供了性能保障.然而,现有的持久性内存存储系统软件或直接从传统软件改进而来[6-7],或依旧借鉴了面向传统磁盘或固态硬盘的设计思想[8-10],从而导致持久性内存的硬件特性没能被很好地利用,其硬件性能很难得到充分发挥.例如,传统硬盘和固态硬盘的最小访问粒度分别为扇区(512 B)和页(4 KB),因此,传统文件系统通常以4 KB的数据页为最小粒度管理文件数据.然而,现有的持久性内存文件系统依旧沿用了该设计,以4 KB为最小粒度管理文件数据读写,并通过写时复制机制(copy-on-write, CoW)保证数据写入的原子性[9-10],使持久性内存的字节寻址特性未能得到充分发挥.通过应用负载分析,发现大量应用有一定比例的写操作具有“不对齐”、“小写”等特性,页粒度的写时复制机制将引入严重的数据写放大效果,从而影响文件系统的整体性能.
本文提出了一种数据页混合管理机制(hybrid data page management, HDPM),通过选择性使用写时复制机制和日志结构(log-structure)管理文件数据,从而避免非对齐写或者小写造成的写放大问题.具体地,HDPM通过同时维护一个固定粒度的持久性内存块和一个日志结构管理各文件数据页:其将对齐的写操作数据直接存入固定粒度的持久性内存块中,而将非对齐的写操作数据以日志项的形式追加到日志结构末尾,从而避免了传统写时复制机制引入的额外拷贝操作,消除了写放大问题.为避免影响读性能,HDPM引入逆向扫描机制,从日志结构末尾逆向扫描,从而保证在数据页重构过程中不引入额外的数据拷贝.为避免日志结构无限增长,HDPM提出一种多重垃圾回收机制,在单个日志结构过大时,通过读操作在重构数据页时主动回收日志结构,当持久性内存空间受限时,则通过后台线程使用免锁机制异步释放日志空间,从而消除垃圾回收对系统整体性能的影响.
本文的主要贡献有3个方面:
1) 提出了一种数据页混合管理机制HDPM,通过选择性地将对齐和不对齐的数据存放到持久性内存块和日志结构,避免了额外的数据拷贝开销.
2) 提出逆向扫描机制降低文件读取时的拷贝开销;提出多重垃圾回收机制,高效回收日志空间.
3) 通过微观和宏观的实验分析,HDPM相比于传统途径能显著提升写入性能.其中,小粒度写入操作负载下,HDPM的写入延迟比NOVA低58%;Filebench多线程测试显示,HDPM相比于NOVA提升吞吐率33%.
1 背景介绍与研究动机
本节主要介绍持久性内存的基本硬件特性、文件系统中常见的原子性更新机制的基本工作原理,以及典型的应用负载分析.
1.1 持久性内存
持久性内存通过内存总线直接与CPU相连,CPU可通过内存指令直接读写持久性内存.持久性内存的出现彻底颠覆了传统的存储体系结构,从“内存+外存”的2级结构变成了内存级存储的单层结构[11].持久性内存还带来了2个层面的变化:1)读写不对称性,持久性内存的写性能往往不及读性能,例如,傲腾持久性内存的读带宽最高可达39.4 GBs,而写带宽最高只有13.9 GBs[12];2)持久性-易失性边界发生变化,传统情况下需要通过软件方式将数据从易失性内存(dynamic random-access memory, DRAM)搬运到持久性的磁盘或固态硬盘,而在持久性内存架构下,该边界位于CPU缓存和持久性内存之间,且数据到达持久性内存的过程完全由硬件控制.CPU会通过打乱内存读写操作来提升访存性能,因此,数据到达持久性内存的顺序往往并不能按照程序写入的次序进行,彼此有依赖关系的数据写入会因为乱序执行导致掉电故障时出现不一致的情况.为此,需要额外执行强制缓存刷新指令(如clflushopt,clwb等)将数据主动逐出缓存.然而,这些缓存刷写指令开销大,对系统性能影响十分严重.
1.2 文件原子性更新机制
为保证文件数据在发生系统崩溃或断电故障时要么写入完成,要么未执行,文件系统需要额外的机制来保证其原子执行.常见的原子性更新机制包括日志(journal)、写时复制、日志结构(log-structure)等.
其中,日志方式将存储空间分成数据区和日志区,在更新数据前,先将旧版本或新版本数据写入日志,待持久化完毕后再原地更新数据.若在此过程中发生故障,可根据日志状态重做或撤回写入操作,实现数据更新的原子性.日志机制的缺陷是所有的数据均需写2次,对写性能影响严重.图1展示了写时复制机制的过程,该方案需将原数据页中未修改的数据先拷贝到新的数据页中,然后再将新写入的数据写到新数据页中.该方案在对齐写场景下性能优异,避免了所有的拷贝开销;然而,针对非对齐写,其额外拷贝开销甚至可能比日志方式还高.日志结构与日志机制完全不同:日志结构将整个存储空间组建成一个日志,而不是像日志机制一样将存储空间划分为数据区和日志区;进而,所有的更新数据都被追加到日志末尾,并借助相应的索引结构引导数据读取.为防止日志任意增长,还需要垃圾回收机制消除日志中的旧版本数据.在基于磁盘的日志结构文件系统中,每次追加日志项时仍需要按页对齐,额外拷贝无法完全消除;然而,在字节可寻址的持久性内存中无需再按页对齐日志项,日志结构可以紧凑地排布在持久性内存中,因而避免任何额外拷贝.
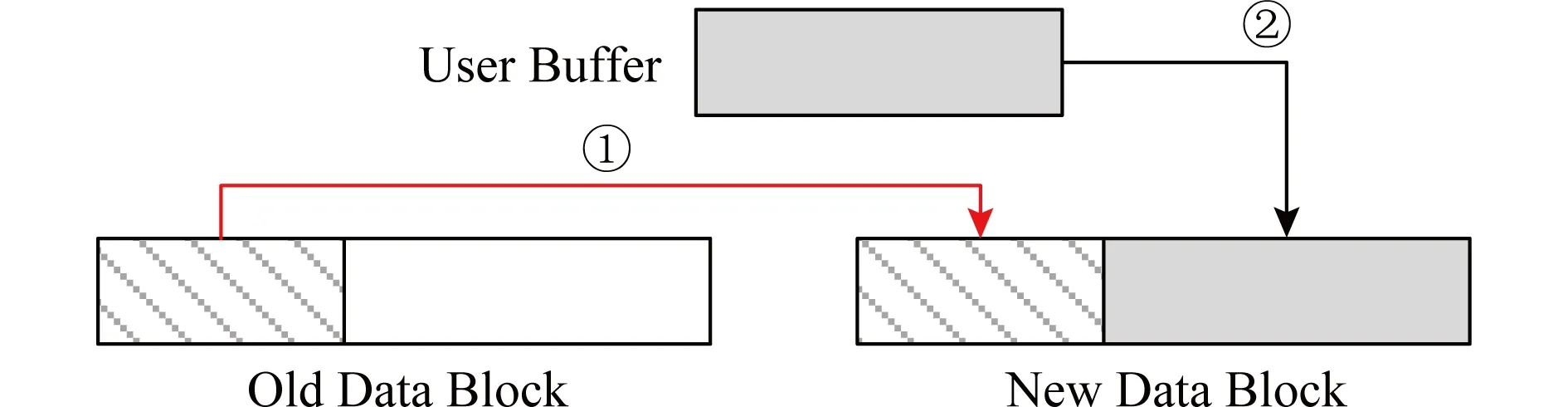
Fig. 1 Copy-on-write mechanism图1 写时复制机制
1.3 负载分析
为理解写时复制机制在真实应用中造成的影响,我们进一步分析了多个真实负载的数据写入特性.如图2所示,其横坐标代表对一个4 KB数据页实际更新的数据量大小,纵坐标代表其累计分布(CDF).观察可见,Iphoto,Usr1,Usr2等负载具有超过30%的写操作为非对齐写,而Facebook和Twitter也具有10%左右的非对齐写操作,仅TPCC表现出良好的对齐写特性.通过一定的真实负载分析,我们发现真实负载均不同程度地存在非对齐写操作,现有的写时复制机制将引入额外的拷贝开销.
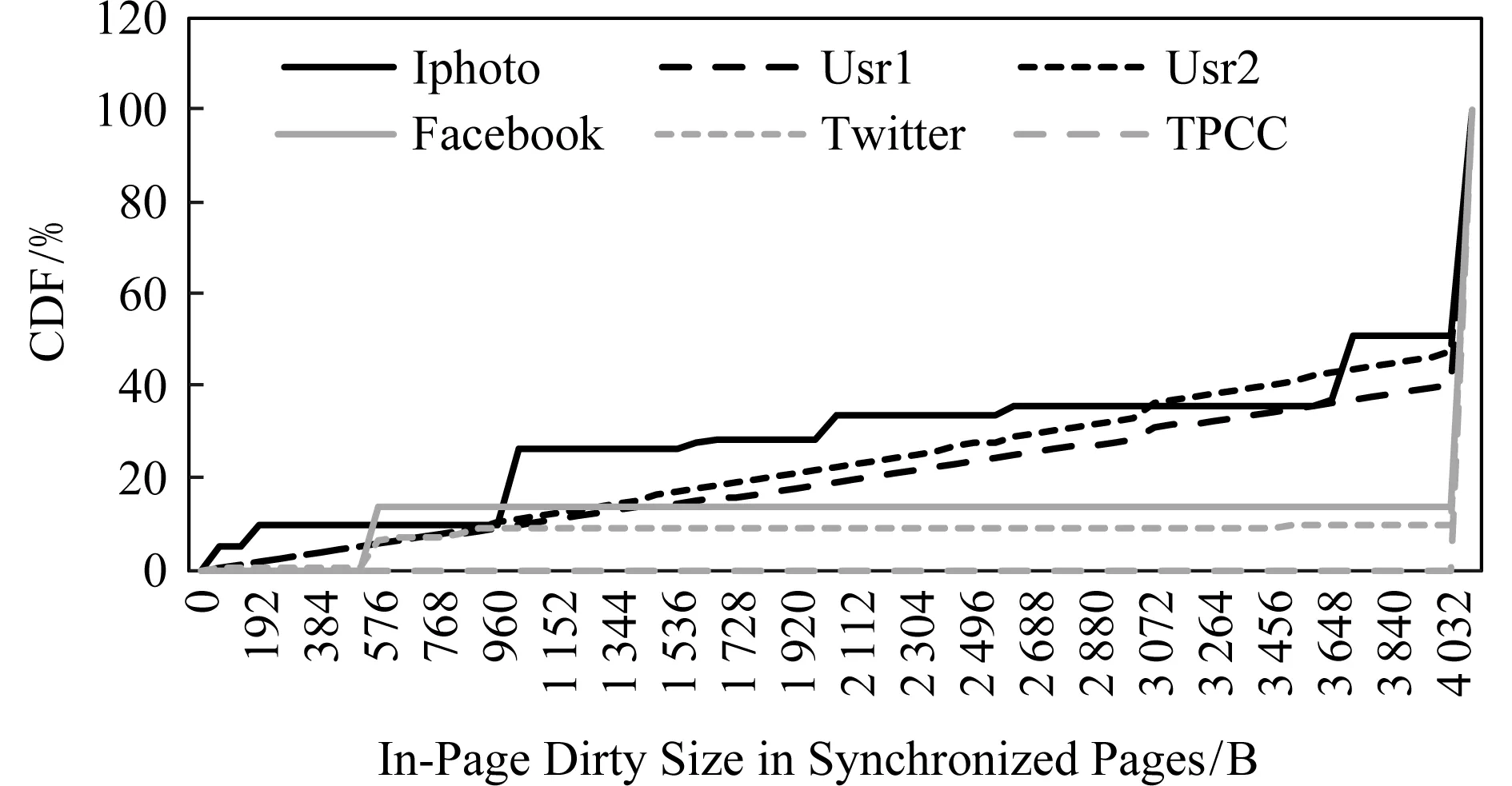
Fig. 2 CDF of in-page update size图2 页内更新数据大小累积分布图
2 HDPM设计
本节首先描述HDPM的系统整体架构,然后逐一介绍HDPM的设计细节,具体包括混合数据页管理机制,基于逆向扫描的文件读取流程,以及高效的多重垃圾回收机制.
2.1 系统架构
图3上半部分展示了HDPM的系统总体架构:应用程序通过POSIX标准读写接口访问文件系统,其中,混合数据页管理模块(2.2节)用于处理文件写入流程,逆向扫描读取模块(2.3节)用于处理文件读取流程.持久性内存空间被切分成固定大小的持久性内存块,用于存放数据页和元数据.为方便实现,文件的inode采用了块映射机制,即为每个数据页存放一个映射条目(如图3下部分).与传统的块映射机制不同的是,每个映射条目包含2个指针,分别指向一个写时复制页和一个日志结构,用于支持混合的数据页管理.当然,HDPM不局限于使用块映射机制进行数据块索引,广泛使用的范围索引(extent)方式同样适用于HDPM,本文将不再赘述.上述日志结构由一个或多个持久性内存块串接而成,当日志结构空间不足时,将分配一个新的内存块串接到日志尾部,用于存放新的数据.当日志结构的长度超过阈值,或剩余空间不足时,将触发多重垃圾回收机制(2.4节),选择性地在前台或后台清除日志结构引入的旧版本数据.
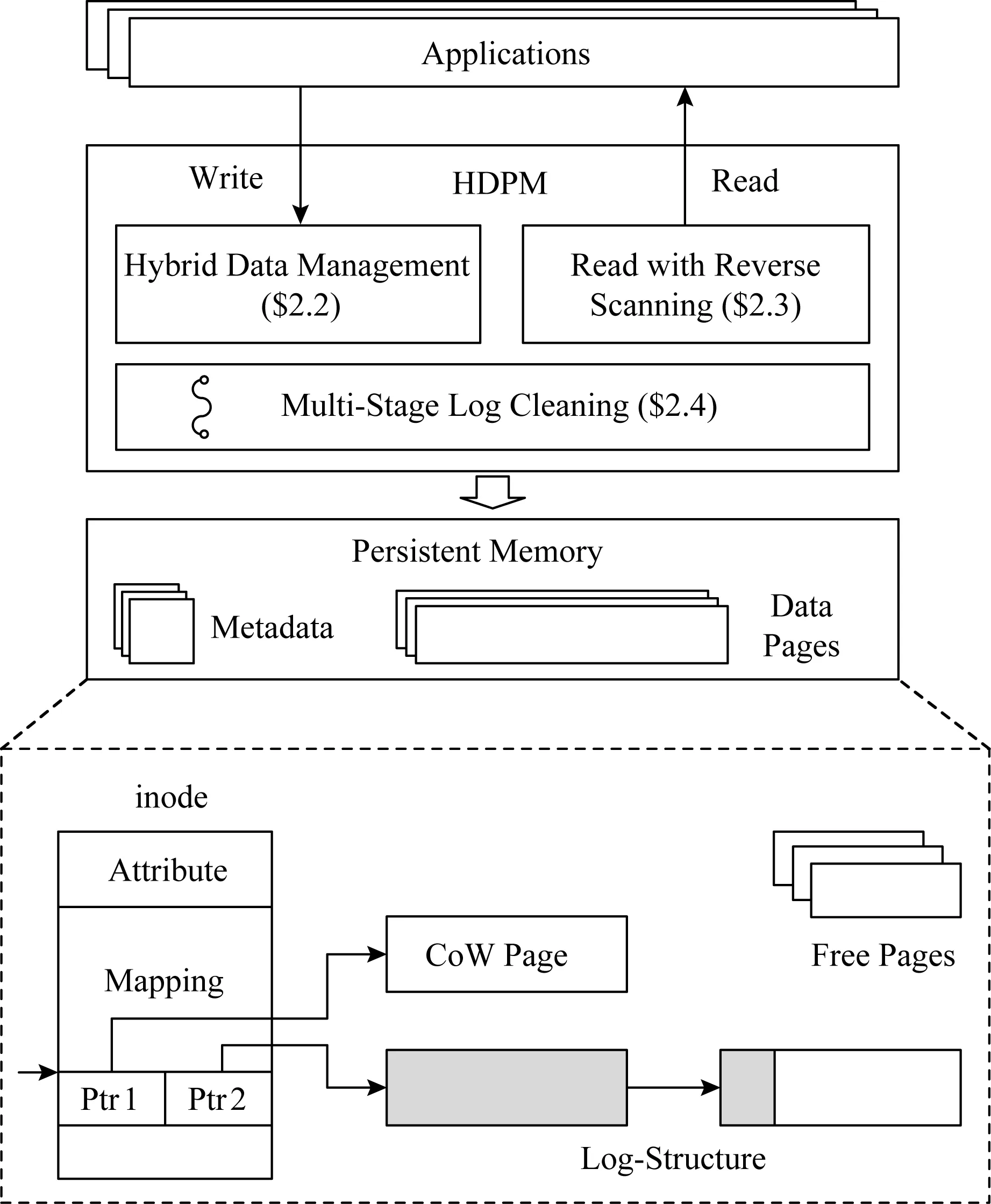
Fig. 3 Overall architecture of HDPM图3 HDPM总体架构
2.2 混合数据页管理
混合数据页管理旨在选择性利用写时复制页和日志结构存储写入数据,从而避免额外的冗余拷贝开销.
当写入的数据恰好整页对齐,HDPM直接通过写时复制机制存储数据:首先从空闲空间中分配1个新的数据页,将数据写入新数据页,并通过硬件指令将所写数据从CPU缓存逐出,从而实现数据的持久化存储;然后将映射表对应映射条目的第1个指针指向新的数据页,使得新写入数据可以被其他读者读取到;最后将旧数据页释放回收.可以注意到,该过程未发生任何额外的拷贝开销,且数据可原子地从旧版本切换到新版本(原子地修改指针),崩溃一致性得到保障.
当写入数据不能整页对齐,HDPM则将数据追加到日志结构中.图4描述了日志结构的布局,它是由若干个持久性内存块串接而成.每个日志结构的起始位置预留了一个日志头指针,用于指向最后一个有效日志项.特别地,日志项使用了倒序排布方式,即元数据放置在数据之后,用于支持逆向扫描文件读取(2.3节).每个日志项的元数据包含2个字段,分别为日志项包含的数据在文件数据块中对应的偏移和大小.向日志结构追加数据时,首先在日志末尾初始化一个日志项,将数据、元数据拷贝到该日志项,然后更新日志头指针指向最新的位置.当日志空间不够时,则重新申请一个新的内存块,并链接到日志尾部.通过引入该日志结构,在发生非对齐写操作时依旧无需执行额外的拷贝操作,且更新原子性得到保证.值得注意的是,当一个数据页发生过一次或多次非对齐写之后,如果紧接着执行一次整页对齐的写操作,则整个日志空间将变为旧数据,因此日志空间可以被释放回收.
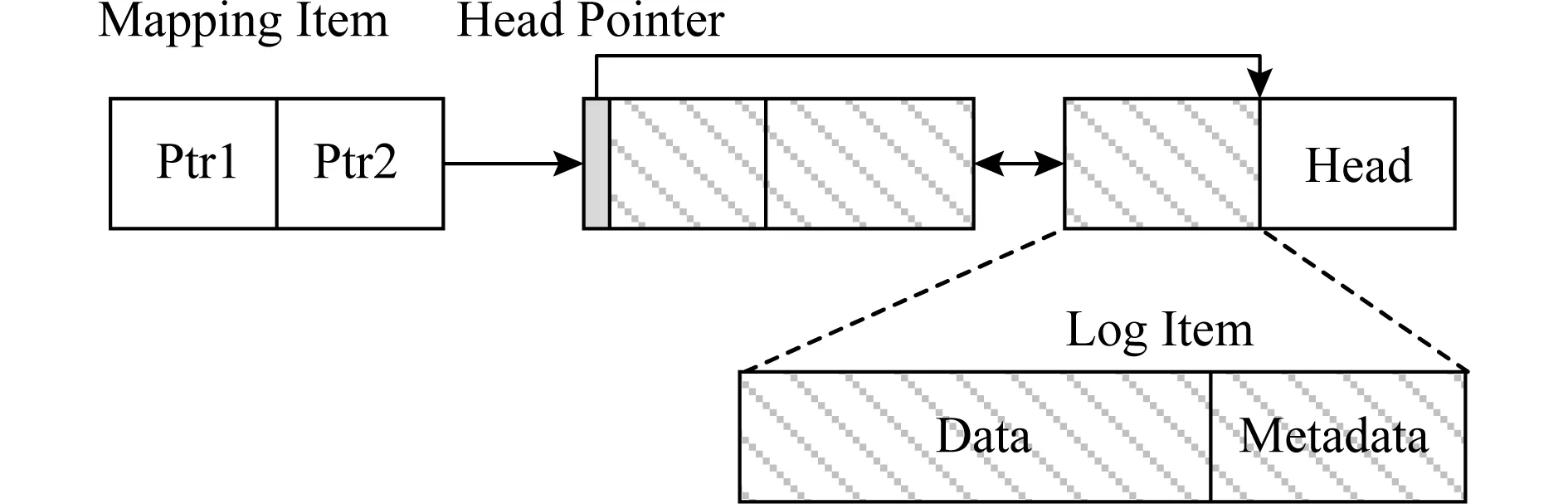
Fig. 4 Layout of log-structure图4 日志结构布局图
HDPM引入的日志结构与传统日志式文件系统(log-structured file system, LFS)[13]完全不同:LFS将整个磁盘组织成一个全局大日志,所有文件数据均追加到日志末尾,相反,HDPM将每个数据页组织成一个小日志.在未对某数据页发生非对齐写时,其对应的日志结构为空,因此,HDPM不引入额外的空间浪费.该设计具有3方面的优势:
1) 多核并发.传统的全局大日志在慢速磁盘场景下可以工作得很好,这是因为磁盘内部的旋转式机械部件天然地支持顺序访问,这与顺序地将数据追加到日志尾部的访问模式完全吻合.然而,持久性内存可以支持更高的并发,且随机和顺序访问性能差异不明显,如果依旧使用全局大日志抽象持久性内存空间,多个线程将从同一个日志头部竞争存储空间,严重影响扩展性.相反,HDPM为每个数据页配备一个日志结构,多个线程之间的竞争概率将大幅降低,能够更好地利用持久性内存高带宽特性.
2) 文件读取性能影响小.传统日志式文件系统或需要在内存中构建复杂的索引结构,用于辅助查找日志中的目标数据,或需要多次日志跳跃查找,这极大地限制了文件读取的性能.HDPM的混合数据页管理机制无需额外的索引机制,且避免了大量的日志扫描,仅需从一个小日志中便可拼合出最新数据.
3) 垃圾回收.传统的日志式文件系统需要全局扫描磁盘检测盘内垃圾占比,并挑选垃圾比例最高的数据块进行合并整理,以腾出空闲空间.此过程将引入大量的扫描操作,垃圾回收开销较高,且影响前台应用的运行.相比之下,为每个数据页配备一个日志结构具有更好的数据局部性:执行垃圾回收时只需挑选出最长的日志,将内部有效数据合并,并写到写时复制页即可,无需额外的腾挪过程,垃圾回收的过程将更加简洁高效(2.4节).
2.3 基于逆向扫描的文件读取
HDPM的另一个设计原则是在引入日志结构后不影响正常的文件读取性能.根据2.2节所述,数据页在写时复制页和日志结构中的新旧程度具有如下关系:日志结构尾部的数据比日志结构头部的数据要新,且日志结构头部的数据比写时复制页中的数据要新.因此,一种直观的数据读取方案为:首先将写时复制页中的数据拷贝到用户缓冲区,然后在日志中从头至尾扫描,将相关的日志项拷贝到缓冲区,直至日志末尾.然而,当该数据页发生大量的重复写入时,日志结构中将有多个日志项的数据彼此重叠,从而造成额外的拷贝开销,降低文件读取性能.
为解决该问题,HDPM引入一种逆向扫描的文件读取方案.HDPM将日志结构的内存块链接方式设计为双向链表,并将日志项进行倒序排布,用于支持文件读取时从日志尾部向头部扫描,从而避免上述的额外拷贝开销.具体而言,首先根据读请求的大小及偏移确定是否包含当前日志项,如果包含,则将其拷贝到用户缓冲区,并记录已读取区间;否则,从日志结构前移一个日志项并重复判断.若当前日志项在读取区间内,且之前已经记录该区间已经被成功读取,则直接忽略该日志项,这是因为日志尾部的数据是最新的版本,无需额外拷贝旧版本数据.当记录的已读取区间完全覆盖了读请求的覆盖区间,则停止扫描并返回数据.若扫描完整个日志结构依旧无法覆盖整个读区间,则进一步从写时复制页中读取相应数据.
2.4 多重垃圾回收机制
为避免各数据页对应的日志结构增长过快,占用过多的持久性内存空间,需要及时将日志结构进行合并整理,消除文件旧版本数据,并回收持久性内存空间.然而,传统的日志清理机制需要通过扫描存储设备探测垃圾数据,并通过锁机制强制阻塞前台服务,从而实现安全的垃圾回收过程,该过程会严重影响系统性能.为此,HDPM提出一种多重垃圾回收机制,其包括在正常读写流程中的机会性垃圾回收和后台免锁模式的垃圾回收.
如2.2节所述,在正常写操作过程中,当发生整页对齐写操作时,可直接将对应日志空间进行回收,这将一定程度上缓解日志的空间占用.进一步,HDPM还在读操作中引入机会性垃圾回收流程.在HDPM执行正常的数据页读取时,首先检查其对应的日志结构长度,若该日志结构超过某阈值,则对该数据页进行完整的逆向读取,整理出最新版本的数据页信息,并写回到写时复制页,同时回收相应的日志空间.此过程会一定程度影响当前读操作的性能,然而,通过定期整理过长的日志结构,有助于提升后续的数据读取性能.
上述前台垃圾回收机制只能回收部分的持久性内存空间,因此还需要专门的后台垃圾回收机制.为避免传统垃圾回收机制阻塞文件系统正常读写流程,HDPM引入一种基于Epoch技术[14]的免锁垃圾回收方法.如2.2节所述,HDPM在更新文件时,可以通过修改指针将数据从旧版本原子地切换到新版本,因此,后台垃圾回收机制同样可以使用原子指令修改指针,用于日志结构的合并整理及回收.然而,后台的垃圾回收机制使用免锁机制回收持久性内存块,而不阻塞文件系统读写流程,有可能前台的读线程正在读取已经被回收的持久性内存区域.此过程中如果已被回收的内存块迅速被重新分配,并用于服务新的数据写入,则读线程可能读到错误的数据.Epoch技术正是用于避免上述问题,其具体实现流程如下.
HDPM引入一个全局的Epoch计数器,其初始值为0,同时为每个正在访问文件系统的进程分配一个本地计数器.每当各进程发起系统调用开始访问文件系统之前,首先将全局计数器与本地计数器的值进行比对,如果不相等,则将本地计数器设置为与全局计数器相等.后台垃圾回收线程将所有的空闲持久性内存块通过2个空闲链表进行管理,分别对应到当前的Epoch值和上一个Epoch值.后台线程定期执行垃圾回收:每次执行垃圾回收时,首先将全局寄存器加1,然后将回收的空闲块增加到当前活跃的空闲链表中.当所有进程的本地计数器都为最新值时,上一次活跃的空闲链表内所包含的数据页将不再有进程访问,此时可以安全地被重新分配并使用.在实际回收过程中,后台线程根据各日志结构的长度确定回收的优先级别,即优先回收长度较大的日志结构.
通过上述Epoch机制,垃圾回收过程完全无锁化,因而不会阻塞前台系统执行,其对系统性能影响极小.
2.5 讨 论
HDPM引入了混合数据页管理、基于逆向扫描的文件读取机制以及多重垃圾回收机制.这些技术一定程度给文件系统带来了额外的计算开销,但是,这些开销相比于其带来的性能提升十分微小.例如,引入的混合数据页管理只需要CPU通过写入的尺寸和偏移进行一次额外的逻辑判断(纳秒量级);同时,维护一个日志结构的开销与维护传统的CoW机制的开销相当,而这种做法的效果却是有效降低持久性内存的数据写入量(微妙量级).同样,逆向读取避免数据的额外拷贝(微妙量级),而反向扫描的开销所占总体执行时间(纳秒量级)的比例很小.多重垃圾回收机制是HDPM相比于NOVA额外引入的开销.然而,多重垃圾回收能够同时在前台和后台进行.其中,大量的垃圾回收操作能够直接被读操作吸收,即在读取文件数据页的过程中自然地完成垃圾回收操作,而非常少的一部分垃圾数据留给了后台进行回收.同时,HDPM仅在空闲(系统负载低)的情形下执行后台回收.综上,多重垃圾回收技术基本不影响文件系统的前台处理性能.
3 系统实现
HDPM包含的技术可以广泛地应用到现有的持久性内存文件系统中.作为示例,本文基于NOVA[10]实现了HDPM的各技术细节.
NOVA将每一个inode组织为一个日志结构,因此,HDPM依然沿用NOVA的设计,仅将映射表的每个条目改为使用2个指针.NOVA在常规情况下并不会扫描inode的日志结构进行元数据查询,而是同时在DRAM中为每个文件构建一棵Radix树,用于映射表的索引查询.因此,HDPM也同时在每个Radix树的叶子节点额外增加一个指针,用于指向各数据页的日志结构.
为保证文件系统崩溃一致性,HDPM需要严格按照顺序持久化已经更新的数据.与NOVA相似,HDPM使用Non-temporal指令持久化数据,使用clflushopt指令持久化指针.其中,Non-temporal指令可以绕过CPU缓存,实现数据的即时持久.在更新数据和更新指针之间,添加mfence指令,用于强制执行持久化的顺序性,保证数据的一致性更新.
4 实 验
本节将从微观测试、宏观测试、关键技术3个方面对比HDPM和现有系统,并详细分析其性能差异.
4.1 实验平台
本实验使用的实验平台配置信息如表1所示.特别地,本实验使用了Intel最近推出的Optane DC持久性内存作为非易失内存存储介质,其单条容量为256 GB,总容量达768 GB.为兼容持久性内存设备,相应的CPU、主板、BIOS均为专门配备.Optane可配置为2种工作模式,分别为APP-Direct模式和内存模式.由于文件系统需直接管理持久性内存空间,因此本实验采用APP-Direct模式.HDPM基于NOVA进行改造,因此本实验将重点与NOVA[10]进行性能对比.作为参考,HDPM同时也与Ext4,Ext4-DAX[6]等传统的文件系统进行了对比.

Table 1 Platform Configuration表1 实验平台配置信息
4.2 微观测试
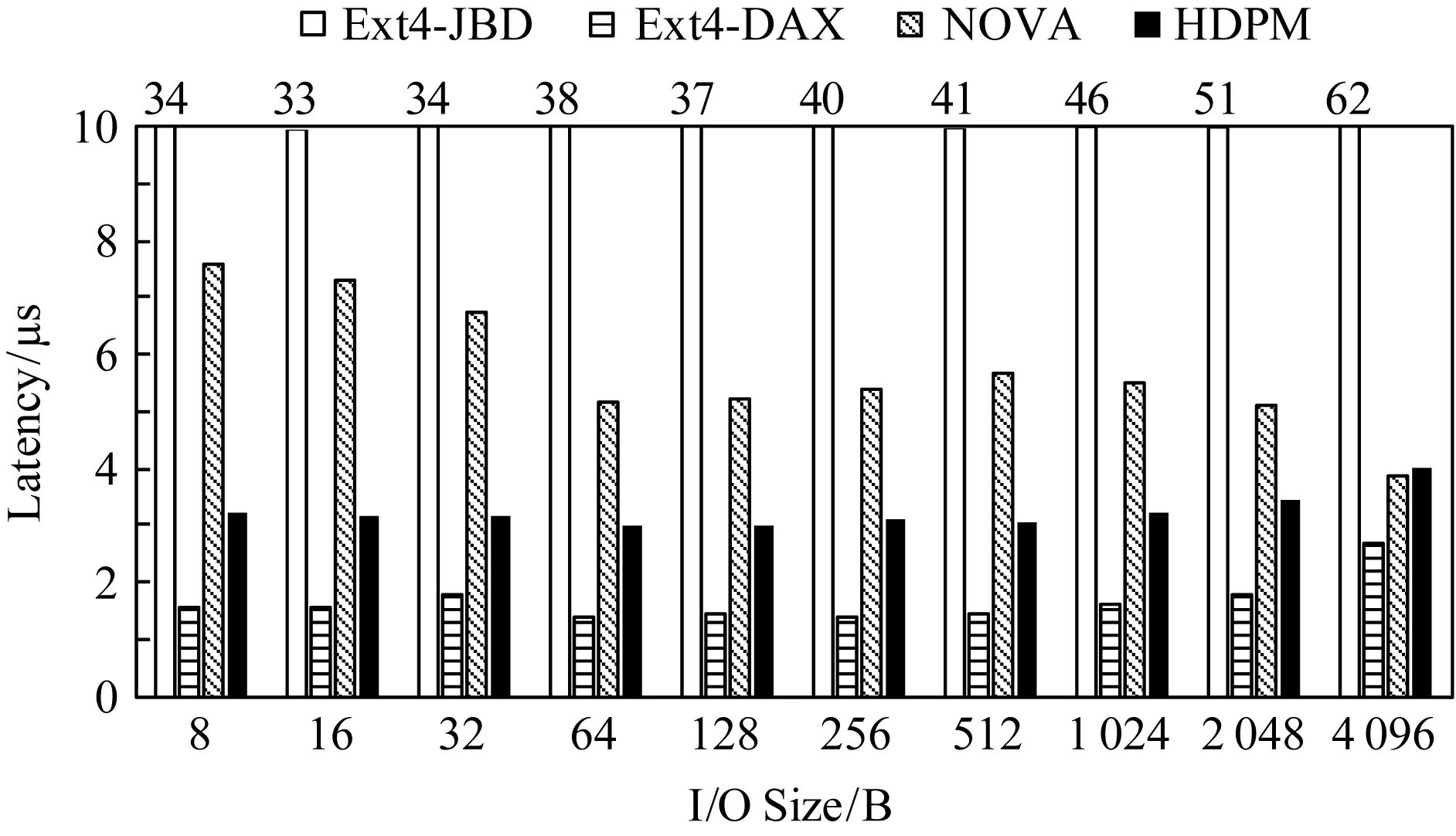
Fig. 5 Latency of write syscall with varying IO sizes图5 写系统调用在不同IO尺寸下的延迟
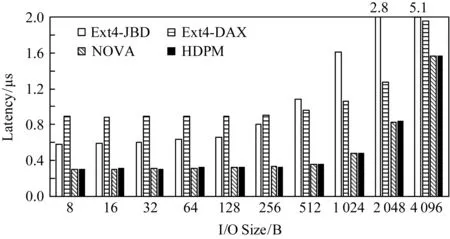
Fig. 6 Latency of read syscall with varying IO sizes图6 读系统调用在不同IO尺寸下的延迟
4.3 Filebench
为测试HDPM在真实负载下的性能表现,本文选取了Filebench[15]中的2个代表性负载Webproxy和Varmail进行测试.本文采用了与文献[10]中相同的配置参数进行测试:Webproxy负载的文件平均大小为64 KB,读操作平均IO大小为1 MB,写操作为16 KB,读写比例为5∶1,总文件数量为10万个.Varmail负载的文件平均大小为32 KB,读操作平均IO大小为1 MB,写操作为16 KB,读写比例为1∶1,总文件数量为10万个.可见,Webproxy为读密集型负载,而Varmail则包含大量小尺寸同步写操作.在测试过程中,通过逐渐增加客户端线程数量来测试Filebench的总体吞吐.我们发现,当线程增加到10之后,总性能不再上升,这一方面是因为Optane持久性内存的写入带宽有限,在10个线程后其带宽趋于饱和;另一方面,Filebench原本针对磁盘设计,其内部同于性能统计、数据测试的模块本身设计扩展性不好.因此,本实验未给出10个线程之后的实验数据.
从图7中可见,Ext4-JBD的性能最差,而其他3个系统的总体吞吐十分接近,这主要是因为Webproxy为读密集负载,系统间性能差异不明显.
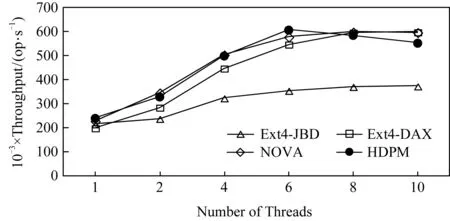
Fig. 7 Webproxy throughput with varying number of threads图7 不同线程下Webproxy吞吐
同时,从图8中可以发现,在写密集应用下,NOVA的总体吞吐远高于Ext4-DAX和Ext4-JBD,这主要是因为NOVA专门针对持久性内存重新设计了软件栈以及数据管理策略.而HDPM则表现出最好的性能,在10个线程下HDPM的总体吞吐比NOVA高33%.这主要是因为Varmail包含了较多非对齐写入操作,HDPM有效降低了非对齐写入操作引入的拷贝开销.同时可以注意到,在线程数量增大时,HDPM相比于NOVA的性能优势更加明显.这主要受Optane DC带宽的影响.在线程数量较少情况下,Optane DC的带宽不是瓶颈,HDPM与NOVA之间的性能差异完全取决于各操作延迟.由于Filebench本身具有较大的软件开销,文件系统层次的操作延迟占比不高,HDPM优化技术带来的延迟降低归结到系统层面效果不明显.但当线程数量上升之后,HDPM与NOVA之间的性能差异变大.HDPM通过混合的数据页管理能够更加高效地处理非对齐小写,从而有效降低了数据总写入量,节省了Optane DC的写入带宽,此时Optane DC的带宽决定了总吞吐,因而HPDM拥有更加明显的性能优势.
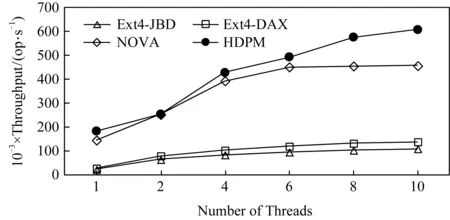
Fig. 8 Varmail throughput with varying number of threads图8 不同线程下Varmail吞吐
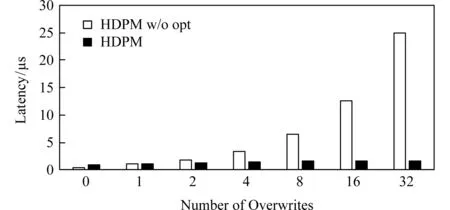
Fig. 9 Read latency with varying number of overwrites图9 不同重复写次数下的读取延迟
4.4 关键技术分析
为理解在读操作中引入的逆向扫描技术带来的性能优势,我们关闭了这一技术,并实现了HDPM wo opt版本,该方案将之前的逆向扫描改为顺序扫描,该扫描过程在遇到多次重复写时,会依次将目标数据拷贝到用户缓冲区,从而造成额外开销.本实验中,依次对文件中的某数据块重复写入N次,然后测试2个版本的系统的读取性能,其评测结果如图9所示.可发现,在重复写入次数变化时,HDPM的读取延迟基本不发生变化,而HDPM wo opt的读取延迟显著上升.因此,在数据读取中,有效降低额外的拷贝次数对提升系统整体读取性能有极大的帮助.
5 相关工作
持久性内存直接通过内存总线接入处理器,存储访问延迟极低,且处理器可以按照字节粒度访问持久性内存.这些硬件上的差异促使了新的文件系统设计.
1) 一致性保障.微软研究院于2019年提出的字节寻址的持久性内存文件系统BPFS[8],通过短路影子页(short-circuit shadow paging)方式提供数据的原子性更新,同时提出一种硬件Epoch提交策略降低缓存刷新的开销.英特尔公司于2014年提出的NVM直写文件系统PMFS[9],采用原子的原地更新及细粒度日志机制保证元数据更新的原子性,通过undo日志和写时复制的混合方式保证数据的一致性.加州大学圣地亚哥分校将传统日志结构文件系统进行重新设计和扩展,研制出日志结构持久性内存文件系统NOVA[10].NOVA将每个文件inode组织为一个日志,因此,其对单个inode的修改操作可以直接在日志尾部原子追加;重命名等操作通常涉及对多个日志结构的更新,因此NOVA还采用轻量级的日志技术保证多操作的原子性.与PMFS相同,NOVA对文件数据使用写时复制技术.虽然上述系统在不同程度上结合了持久性内存的字节寻址特性,并通过不同的手段解决了文件系统一致性管理.然而,上述所有系统均使用了基于页粒度的写时复制技术,这会造成额外的拷贝开销.北京航空航天大学提出的noseFS[16]则通过构建额外的B+树维护更细粒度的持久性内存页,从而降低写时复制机制引入的拷贝开销,然而,B+树的维护管理同样造成额外的时间及空间开销.
2) 降低软件开销.操作系统管理的页缓存在持久性内存中将造成冗余的数据拷贝,严重影响性能.因而,Ext4,BtrFS等传统文件系统均兼容了直接访问模式(direct access, DAX).通过这种方法,应用程序可以直接访问非易失内存中存储的文件数据,而不需要将数据额外拷贝到页缓存中.PMFS,NOVA等专门为持久性内存设计的文件系统则通过内存映射的方式绕开了文件系统页缓存.然而,操作系统本身依旧十分笨重,其系统调用引入的现场切换开销,虚拟文件系统(virtual file system, VFS)引入的软件开销等在面向持久性内存时也变得愈发严重.因此,维斯康星大学麦迪逊分校于2014年提出一种用户态的持久性内存文件系统Aerie[17],从而使得应用程序可以直接在用户态访问文件数据,而不引入额外的操作系统开销.Strata[18]同样也是一个用户态文件系统,不同的是,Strata同时管理多种存储设备(硬盘、固态硬盘、持久性内存等),通过合理的调度,Strata在性能、容量等方面均表现优异.
3) 多核扩展性.在多核场景下,如何设计可扩展的文件系统以充分利用持久性内存的高吞吐特性变得十分重要.NOVA在改造传统日志式文件系统时,重点考虑了多核扩展性.NOVA将每个inode组织为一个日志,而不是仿造传统方式构建一个全局大日志,通过这种方式,有效避免了并发向单个日志追加记录难扩展的问题.另外,NOVA仅将元数据放入日志结构,而数据部分则单独管理,这有效降低了垃圾回收的开销.最后,NOVA将空闲空间切分到不同的处理器核心,不同线程在分配内存空间时,仅从本地空闲空间进行分配,从而避免了额外的全局锁开销.通过上述设计,NOVA具有极强的扩展性.HDPM也采用了类似的设计理念,通过多个日志结构降低竞争.
6 结 论
持久性内存展现出与传统存储设备(如硬盘、固态硬盘)完全不同的硬件特性,这为构建高效的持久性内存存储系统提出了新的挑战.本文提出一种混合数据页管理机制HDPM,通过选择性使用写时复制机制和日志结构管理文件数据,充分发挥持久性内存字节可寻址特性,从而避免了传统单一模式在遇到非对齐写或者小写造成的写放大问题.为保持读性能不受影响,HDPM引入逆向扫描机制,在重构数据页时不引入额外数据拷贝.HDPM还提出一种多重垃圾回收机制,在不同阶段、不同时机进行高效的日志合并整理.实验显示,HDPM能够显著提升写入性能.
猜你喜欢
计算机应用与软件(2022年9期)2022-10-10
现代电子技术(2022年8期)2022-04-13
体育科技文献通报(2022年1期)2022-01-15
今日中国(2017年8期)2017-09-03
今日中国·中文版(2017年8期)2017-08-14
山东工业技术(2017年7期)2017-04-10
科技经济市场(2016年5期)2017-02-05
商(2016年20期)2016-07-04
诗歌月刊(2014年12期)2015-04-14
计算机教育(2006年4期)2006-04-19
