
基于文本语义分析的个性化旅游偏好研究
2020-02-25 07:53张艳荣周婉婷赵志杰
哈尔滨商业大学学报(自然科学版) 2020年1期
刘 岩,张艳荣,周婉婷,赵志杰
(1.哈尔滨商业大学 计算机与信息工程学院, 哈尔滨 150028;2.哈尔滨商业大学 黑龙江省电子商务与信息处理重点实验室, 哈尔滨 150028)
根据《2017年上半年旅游统计数据报告》显示:2017年上半年我国国内旅游市场份额超额增长,旅游人数约25.37亿人次,相比2016年猛增13.5%,旅游收入达到了2.17万亿元[1].数据表明我国旅游业正处于一个快速发展的阶段,具有较大的经济效益.
大数据时代,信息是一切事物发展的必然来源.在互联网海量数据存在的情况下,用户难以快速获取自己感兴趣的信息,导致“信息过载”现象的出现[2].互联网上的旅游信息在电商行业的推动下呈几何级数增长.随着国民经济的提高,人们不再仅仅满足于目前的物质生活,而更关注和追求精神生活的质量和幸福.越来越多的人选择在空闲时间外出旅游,使得国内旅游业迅速崛起,为迎合游客的喜好以及提高旅游景点的声誉,个性化旅游偏好逐渐得到广泛深入的研究[3].Huan Yuan等通过对旅游博客进行频繁模式的挖掘,将文本内容转化为一系列单词向量,后将旅游活动之间的顺序共现用来识别城市的热门位置,提出了一种基于最大可信度的网络旅行路线检测方法[4].Hsiu-Sen Chiang等开发了一种个性化的旅行计划系统,该系统同时考虑了所有类别的用户需求,并为用户提供了近似于自动化的旅行计划规划服务[5].近年来,随着个性化旅游在国内的快速发展,不少学者将目光锁定在游客旅游偏好等问题上,葛学峰等研究了人口统计学等六个基本特征与人均日消费的关系,并根据六个基本特征总结出五类旅游产品的游客偏好[6].宋涛等通过分析旅游市场的目的地偏好、要素改善偏好、景区偏好和产品偏好四个偏好,总结了这四个偏好对旅游市场的影响,并对这四个偏好提出了改进建议[7].Junge Shen等通过利用明确的用户交互和多模态旅行信息提出了一种新颖的个性化旅行推荐框架,拟解决信息过载的问题,根据用户喜好推荐合适的景点[8].S·Kotiloglu等基于“协同过滤”法讨论了复杂的选择和旅游问题,并提出了一个“过滤优先,旅游第二”的框架,用于根据社交媒体和其他在线数据源的信息为游客提供个性化的旅游建议[9].
从个性化旅游偏好研究现状所采用的数据可以看出,国内外收集的数据逐渐从传统的问卷调查慢慢地转化为互联网上更具真实性、准确性的文本数据[10].基于文本数据的挖掘,大多数学者仅仅局限于对文本词频的统计,没有深入研究词与词之间的复杂关系,而本文在借鉴国内外关于旅游偏好的文本挖掘技术基础上,参考中国十大品牌旅游网站排名,根据研究目的,选择出游类型分类明确的专业旅游游记分享网站携程网为样本来源,运用文本挖掘技术与复杂语义网络方法研究基于不同类型的游客对于乌镇的个性化旅游偏好.
1 研究方案与数据预处理
1.1 研究方案
本文利用数据挖掘中的文本挖掘及大数据分析技术以实现准确的、有针对性的数据获取,然后将获取到的基础数据按照一定的筛选标准和规则进行清洗,以形成干净的数据.综合考虑各种因素,采用文本挖掘、内容分析以及复杂语义网络分析不同出游类型游客对旅游产品的个性化偏好.基于文本语义分析的个性化旅游偏好研究过程包括利用网络爬虫工具进行数据采集、自定义的数据分类、运用Rost CM6的数据预处理、复杂语义网络研究及不同出游类型游客的偏好推荐等步骤,总体技术路线如图1所示.
1.2 数据来源
通过网络爬虫工具爬取乌镇旅游游记从2018年4月~2018年9月的100篇游记作为初始数据.去除无实际意义的游记后,根据不同出游类型拟取每种类型的10篇游记作为每种出游类型的基础数据.遵循有用性、实时性的原则筛选数据[11],建立各种出游类型的Word文本数据库和总体的Word文本数据库,最终得到个人出游类型游记文本13 800字;朋友出游类型游记文本15 000字;亲子出游类型游记文本17 000字;全家出游类型游记文本16 000字;情侣出游类型游记文本19 000字,总计乌镇5种出游类型的总体Word文本数据共80 000字.
1.3 数据预处理
将爬取到的100篇浙江乌镇游记作为研究的基础数据,由于游记书写的方式没有统一的格式和规范,且采集到的游记数据存在缺失或冗余等现象,若将未处理过的初始数据直接进行分析处理,则会浪费大量的计算资源且得不到有效的结论.基于此,需对这些最初收集到的数据进行数据预处理,处理的过程包括对所有类型的脏数据进行清理,如:填写缺失值、光滑噪声、识别或删除离群点以解决数据不一致性的问题,从而使脏数据变成无噪、平滑、干净的数据.
1.3.1 数据清洗
为去除不必要的噪声干扰,需先对最初采集到用户生成内容数据进行清洗,针对非规范对象进行规范化转换,如去除文本中的空格、去除字数较少的评论以及去除标点符号等.
1.3.2 基于ROST CM6的文本预处理
通过阅读大量已有的研究文献,得知分词是数据预处理的关键步骤.分词是将评论文本中的每一句话都分成有意义的词语和字.游记中除了评论的客观目标词(如“姿态”)和主观意见词(如“漂亮”)之外,还存在大量没有意义的词汇,但是这些词汇本身是具有一定结构的,如:连接词、数词、感叹词等,因此通过建立词表过滤停用词及对研究无意义的词汇,在此基础上应用ROST CM6软件对文本进行分词, 将分类后的初始数据形成各自的文本文档格式, 导入到Rost CM6软件,具体步骤如下:
1) 建立归并词群表,保持景区的景点以及旅游活动等的一致性.在乌镇自助游游记分析文本中,将“巷子”、“小巷”等统一替换成“巷子”;将“遮阳”、“烈日”等统一换成“晴天”.
2) 建立过滤词表,分词后的文本中含有名词、助词、代词等一系列词性的词,本文将与研究目标无关的字词以及一些本身就无意义的语气词(啊、呀、吧)、连词(和、与)、数词(一次、两次)等字词添加到过滤词表中形成过滤词表的文本文档.在初步提取了游记的文本高频词后,将一些虽然是高词频但对目标研究毫无意义的词汇放入过滤词表中(如“时间”、“人数”、“地方”等)进行过滤处理并保存其文本文档.
3) 建立自定义词表,建立乌镇的主要景点(东栅、西栅、南栅、北栅等)、自然资源(晴天、下雨、刮风等)、住宿条件(酒店、民宿、客栈等)等一级影响因素的自定义词表,其中每个表中包含了各自的二级影响因素,并将其保存为乌镇自定义词表的文本文档,来保证词频分析的可靠性与准确性,使本文的研究更具针对性.
2 个性化旅游偏好特征属性分析
词语出现越频繁就代表游客对该词语的认知度越大,且越感兴趣,是旅游者在旅途中的特殊记忆点.游客通过在社交网站上汲取相关景点信息,根据自身的个体特征自发地考虑其旅游方式(如:自助游、跟团游等,其中自助游包括一日游、自驾游等).随着大众对幸福感知的提升,人们越来越向往自由、没有拘束和固定行程的自助游.基于此,本文对ROST CM6预处理后的数据进行进一步的处理以获取游客的特征属性.
2.1 基于TF-IDF的属性获取
Tzu-KuangHsu等提出了可以将高频词汇的影响因素分为有形因素和无形因素两种的理论,其中有形因素为旅游途中可以切身感受的因素,经过划分得出以下几种:交通工具、住宿环境、安全保障、购物市场、天气情况、价格高低、文化与历史;无形因素可以划分为:目的地的形象和预期的效益[12].本文将词频统计后的数据进行分类处理后,对于不同出游类型的游记数据进行高频词汇的有形因素分类,然后基于TF-IDF算法得出每类中有形因素的权重,结果如图2所示:自助游的游客并不看重交通设施、食物以及自然条件,反而更注重的是乌镇的历史与文化,从侧面反映出乌镇是一个历史文化底蕴非常浓厚的景点.

图2 有形因素分类
2.2 基于语义网络分析的属性获取
基于权重算法得出的属性分类不能直观地反映出每类游客的个性化偏好,因此本文将分类后的数据导入Rost CM6软件的语义网络和社会网络生成工具中,得出乌镇高频词语义网络图,如图3所示.在语义网络图中,线条的疏密程度表示高频词之间共现频率的高低.通过观察复杂语义网络图可以判断出词与词之间内在的联系是否密切,其中线条越密集,表示共现频率越高,两者的关系也就越密不可分[13].高频词语义网络的出现将高频词所代表的内容之间存在的内在相关性图像化、具体化.图中线条最密集的核心词汇是“乌镇”“江南”“景区”“酒店”等,从侧面说明来乌镇旅游的游客大多数喜欢江南水乡,在传统的旅游六要素购、娱、游、行、食、住中[14],游客更关注于“游”和“住”.
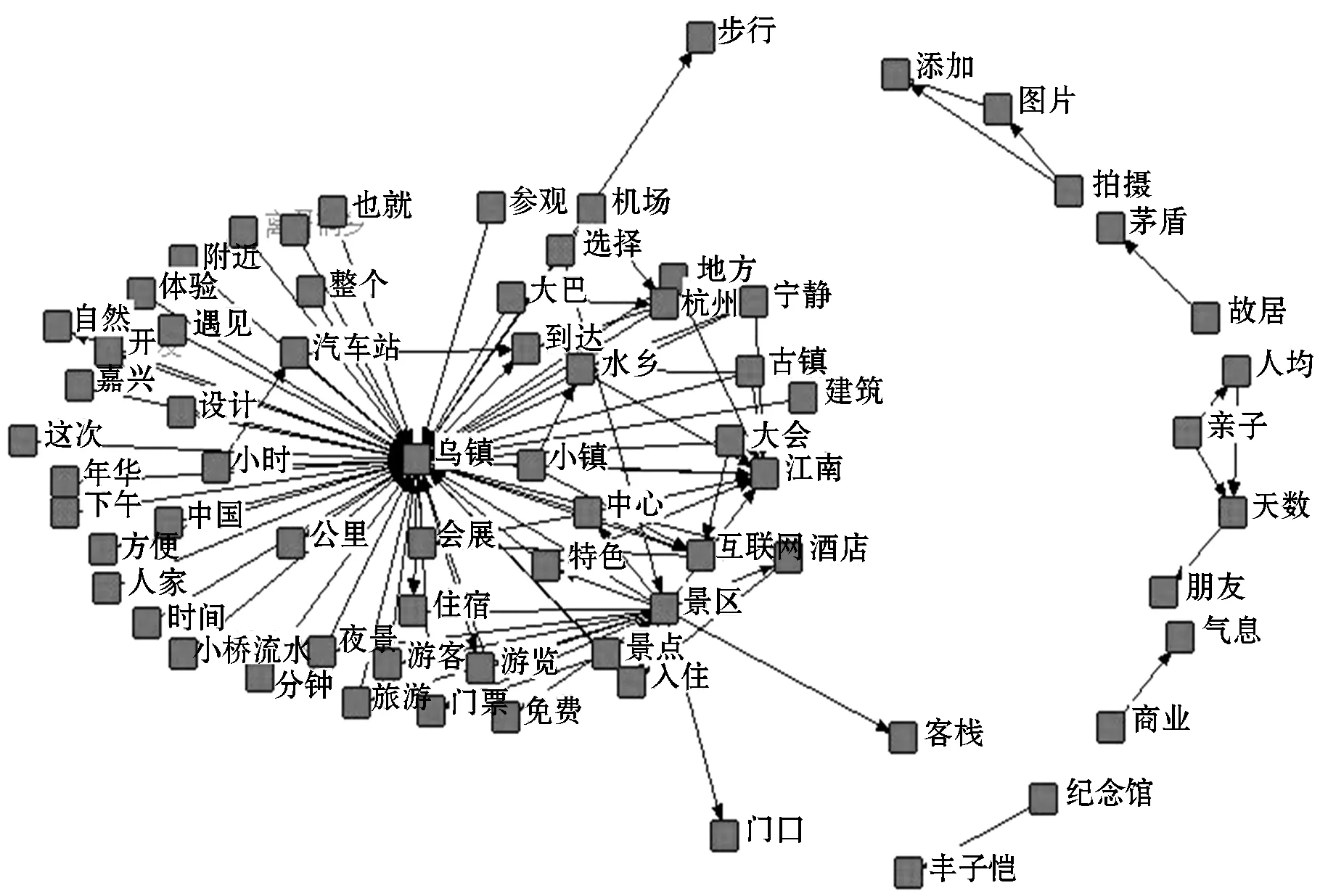
图3 乌镇高频词语义网络
由于高频词语义网络分析图中线条太过纷杂,因此利用Rost CM6软件的可视化标签云对乌镇自助游游记进行可视化云分析,如图4所示.在样本标签云图中,可以通过观察文本的大小程度来判断字词的频率,文本越大,则表示游客对这个词的特殊记忆越深.标签云将高频词语义网络分析图更清晰明了地展示出来,但却忽视了高频词之间的关联.在Rost CM6中的样本标签云图中(图4)可以看出依旧存在为数不多的与研究无关的词汇,软件的标签云图中对于无关词汇的清理不够全面,并且不能看出词与词之间的密切联系,虽然图中词的频率用字体大小表现出来,但却不直观,因此本文将原始数据导入图悦软件中.图悦是基于TF-IDF算法提取高频词,并得到每个高频词的权重,然后根据高频词的权重聚类出词云的软件,能够根据不同的颜色、不同的字体清晰地分辨出乌镇旅游高频词之间的权重大小与密切关系,如图5所示.

图4 乌镇高频词标签云

图5 乌镇图悦高频词云
结合高频词语义网络与标签云了解到乌镇旅游的属性偏好以及不同出游类型游客对于属性偏好的关系.从标签云中可以直观地体现出游客对于乌镇的属性偏好排序为:历史与文化>景点>住宿>吃食;而从高频词语义网络图中可以得出不同出游类型的游客对于旅游产品的选择千差万别,导致网络图中的线条相对分散,相互之间的联系较弱.
3 结 语
在信息爆炸时期,个性化旅游偏好信息的收集以及旅游个性化推荐存在着信息来源的复杂性、信息形式的不一致性以及个性化推荐系统的不完善性等问题.在此前提下运用文本挖掘技术以及复杂语义网络等方法分析不同类型的自助游游客(朋友出游、个人出游、亲子出游、情侣出游与全家出游)的个性化旅游偏好(包括:吃、购、住、游等)[15],通过在游记中挖掘特征属性信息了解用户偏好,运用词云图对得出的特征属性信息进行改进,清晰地反映出词与词之间的密切关系及重要程度,从而得出个性化旅游偏好特征.本文将文本挖掘技术与复杂语义网络方法运用至乌镇游记的个性化旅游偏好研究中,结果表明:在同一旅游景点,同一类型的游客偏好频率基本一致.基于此,商家一方面应加强文化的建设与传承,策划出不同领域文化的短途游玩路线,建造别具风格的民宿与客栈,让用户更了解旅游景点的历史与文化,进而使用户能够更加深入的享受旅途;另一方面应加强网络口碑建设,利用社交媒体平台进行推广和宣传,从而为用户在社交媒体上提供更具特色、便捷的行程推荐以及智慧化的出行选择.
猜你喜欢
小康(2022年7期)2022-03-10
小康(2022年7期)2022-03-10
小康(2021年7期)2021-03-15
小康(2021年7期)2021-03-15
现代装饰(2020年3期)2020-04-13
金桥(2018年2期)2018-12-06
小溪流(画刊)(2018年7期)2018-11-28
Coco薇(2016年7期)2016-06-28
Coco薇(2015年5期)2016-03-29
扬子江诗刊(2015年2期)2015-11-14
